
一、关于ECI
背景从2018年正式发布,ECI已经打磨了整整4个年头,如今也已经快速成长为了阿里云serverless容器的基础设施,服务着阿里内外众多的公有云客户与云产品,每天承接着数百万的弹性容器创建。
然而,ECI这些年却未参与到集团双十一大促,双十一可以说是阿里技术人的阅兵,能不能承接住双十一的流量成为了检验一个产品是否稳定可靠的重要标准。但一切都是水到渠成,就在今年,ASI开始与ECI对接,尝试让ECI承接双十一大促的弹性的30W核算力,我们都知道双十一大促对于整个阿里集团的意义,使命将至,我们必将全身心地投入到对接、压测、护航的工作中。经过长达两个多月的业务适配、压测、备战,最终完成了双十一大促的弹性容器的圆满交付。这背后,离不开ASI、ECI以及参与到其中的每一位脚踏实地、用心钻研、保驾护航的同学的努力。ECI今年首次作为集团大促弹性基础设施,根据线上数据统计,大促期间ECI弹性资源使用共计约400W核,从资源的瞬时弹性、保有规模、系统稳定性等多方面对云原生系统都是一次巨大的考验。作为底层的计算单元,ECI此次也成功顶住了双十一弹性流量洪峰的考验,在感叹serverless、容器这些技术发展迅猛的同时,对于全新的系统架构稳定性的考验也不小。
如今再回过头来看ECI的第一次双十一,我们有必要做一次全面的总结,我们为集团弹性保障做了哪些工作,哪些是将来可以复用的工作,哪些是可以给其他的团队作为借鉴的技术和经验,以及哪些地方还可以做的更好,为下一次大促做准备。
本文我们将为大家介绍,ECI这些年在稳定性方面做了哪些工作,以及是如何来为集团双十一保驾护航的。
二、遇到的挑战
大规模并发带来的稳定性挑战遇到的最大挑战首先是大规模并发带来的。容器保有量增多之后,从容器实例生产方面来看对于云管控系统是不小的考验,尤其是对于弹性场景来讲,需要在极短的时间进行实例的生产,镜像的大规模拉取,进而保障容器的成功启动。
如何能保障实例的大规模成功生产,如何先于线上发现问题,以及即使出现了问题如何第一时间止血并进行故障恢复,这对于集团双十一期间的业务重保都是尤为重要的。除此之外,对于公有云环境来讲,不能影响到其他的公有云客户也是需要重点关注的,因此需要具备一套完整的稳定性保障体系以及故障应对方案以确保双十一期间的业务能够顺利进行。实例生产系统稳定性ECI和ECS共用一套资源调度系统,相对于ECS容忍度为分钟级别的应用来讲,ECI实例频繁的创建删除对调度系统的要求更为苛刻,对系统容量以及稳定性保障方面提了更高的要求。服务可用性保障ECI安全沙箱由于某种原因异常(OOM/物理机宕机/kernel panic),导致不健康情况。这种情况下,k8s层面如果不从endpoint上摘除这个ECI Pod,会导致请求通过负载均衡依然可以路由到这台不健康的ECI上,会导致业务请求成功率下降,因此对于集团业务服务可用性保障也是尤为重要的。
三、ECI稳定性技术建设
稳定性保障从需求收集准备阶段开始,双十一大促持续两个月之久,为了配合集团全链路验收,ECI自身的稳定性服务器托管网保障工作也随之紧锣密鼓地进行。

稳定性的保障贯穿了整个大促过程,大促前慎重/减少系统变更以排除人为因素的干扰,敬畏发布,多次压测演预案确保系统稳定性,不断提升系统抵抗力稳定性和系统恢复力稳定性,以保障大促的顺利进行,最后通过问题复盘沉淀出可复制的大客户重保策略,这对于未经过双十一实战演练具有积极的意义。
因此我们梳理出了整个大促期间围绕稳定性方面做的主要工作,主要包括风险控制、关键业务依赖梳理、技术保障、压测预案、运行时保障、故障运维能力、以及最后的复盘优化,希望以此能对今后的大促工作作为指导,并沉淀出稳定性治理的经验。接下来我们对此次大促涉及到的主要稳定性保障方法以及如何应用进行介绍。
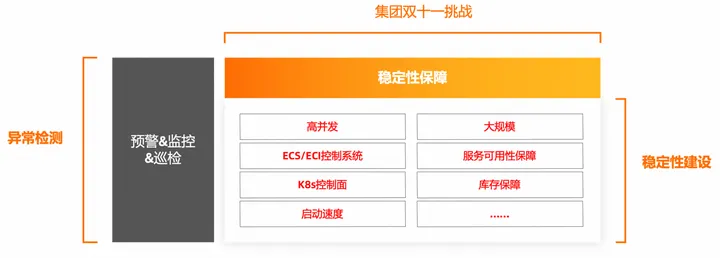
实例生产保障VM复用技术实例生产行为的保障是集团弹性使用ECI的重中之重。一个典型的实例生产过程如图所示,ECS和ECI在控制面共用一套管控系统,ECI管控侧调用资源调度系统之后会分配计算资源之后会调用pync(阿里云单机管控组件),进而调用avs(阿里云单机网络组件)和tdc(阿里云单机存储组件)分别生产网卡与磁盘。在此过程中,对于调用ECS依赖的open api接口较重,在大规模创建删除场景很快成为系统瓶颈,此前我们专门针对容器实例高频创建删除场景开发了VM复用功能,对于高频场景删除容器实例的场景,延迟vm的回收,并复用容器实例的网卡、镜像、计算资源,降低对管控系统整体的冲击,以此来保障实例生产系统服务器托管网的稳定性,从此次双十一的实战演练效果来看,vm复用取得了很好的效果,管控系统容量整体处于正常水位,保障了集团双十一实例稳定的弹性能力。
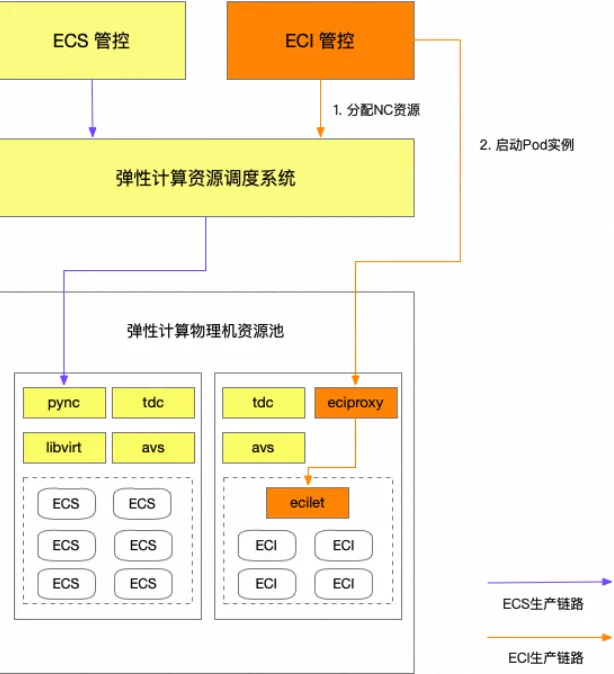
重调度机制对于库存不足或者远程服务调用超时等情况,为了保障实例生产的最终一致性,对于ECI实例生产我们设计了相应的故障处理策略策略,取值如下:fail-back:失败自动恢复。即Pod创建失败后自动尝试重新创建fail-over:失败转移。效果等同于fail-backfail-fast:快速失败。即Pod创建失败后直接报错故障处理策略本质上是一种重调度的策略。原生的k8s调度支持重调度,即调度失败后会将pod重新放入调度队列等待下次调度,类比k8s的重调度行为,当eci管控系统收到创建请求的时候,首先会进入一个队列,然后有个异步定时任务会将创建从队列中捞起,提交到异步工作流进行实际的资源生产、以及容器的启动等。即便是结合了多可用区和多规格的优化,异步工作流依然有可能失败的,比如资源的争抢、内网ip不足、启动失败等,这时候就需要将创建请求再次重回队列,等待被重新调度生产。
我们目前对于故障处理策略:
1、失败的任务会一直重试,但是我们会计算每个任务的执行周期,重试次数越多,执行周期越长,以达到退避效果。
2、优先级策略会考虑用户级别、任务类型、任务上次失败的原因等因素,优先级高的任务优先提交执行。
3、每次调度失败的原因都会以标准事件的方式通知到k8s集群。队列里的任务的整个执行流程的状态机如下:
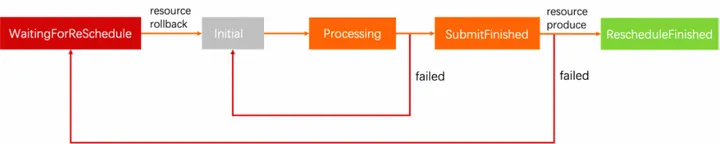
所有执行失败的任务都会重新进入队列,等待被再次调度。由于任务会在任何一步失败,所以所有生产出来的资源都会回滚,回滚结束后,进入初始状态。初始状态的任务会被拉起执行,然后提交到异步生产。如果生产失败,就会再次回到等待调度的状态。如果生产成功,任务就结束,到达终态。基于我们的重调度机制,可以极大的减少由于生产系统抖动造成实例生产失败的情况,对于容器启动成功率要求高的场景可以保障实例生产的最终一致性,对于容器启动成功率要求不那么严格的场景可以快速失败,由上层业务进行处理。
服务容错降级对于故障场景,系统依赖服务的降级也是十分重要的。大多数进行限流降级的方案主要关注点在服务的稳定性,当调用链路中某个资源依赖出现异常,例如,表现为 timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败或返回预设静态值,避免影响到其它的资源,最终产生雪崩的效果。ECI目前实现了基于历史日志自学习进行无损降级、本地cache降级、流控降级3级降级机制框架,ECS/ECI openapi 全面接入,内部依赖200+接口接入,根据每个接口的调用频率、RT分布、超时时间设置来单独分析,选择合适的降级策略,设置合理的阀值,能让系统出问题时,智能降级从而进行系统保护。一个典型的降级机制实现过程如图:
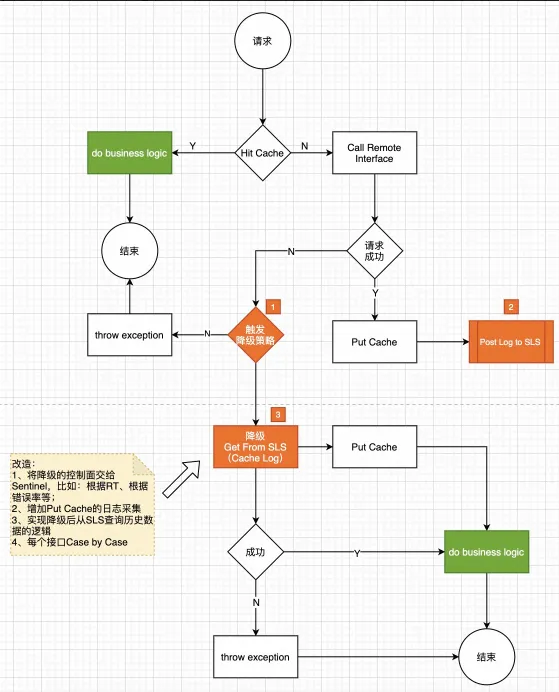
当有非资源类核心API新请求进入,如果历史缓存数据未过期则直接返回缓存数据,结束业务逻辑反之则请求远程接口。如果请求成功,返回数据,对数据进行缓存,同时将缓存数据以日志方式存入sls cache log日志用于未来降级,结束业务逻辑当远程请求失败时触发降级策略:如果失败指标(例如指定时间内异常比例)在预设时间窗口内未达到配置的降级策略阈值,则直接抛出相应业务异常,结束业务逻辑如达到降级策略阈值则按以下顺序实行降级策略:从sls 缓存日志查找历史日志数据作为降级返回值,同时将返回值重新写入缓存,结束业务逻辑如果sls缓存日志没有相应日志则返回:预设静态值或空值,结束业务逻辑对于一些跟用户资源无关,更新少,属于全局参数的服务/接口,以上通用降级策略和方案可能因为降级规则阈值难以界定而无法有效执行。
针对这些接口采用dubbo异常直接降级的策略涉及到降级或熔断的条件:自动降级(可选利用Sentinal进行自动降级): 超时 异常 限流手动开关支持核心非资源api直接进行openapi 本地降级cache 对于严重的系统故障,可以将核心几个describe api进行openapi本地cache,发生故障,或有雪崩出现时,全部切到openapi本地cache,在降级影响面的同时,也能减轻对下层服务的调用压力来赢取恢复时间。
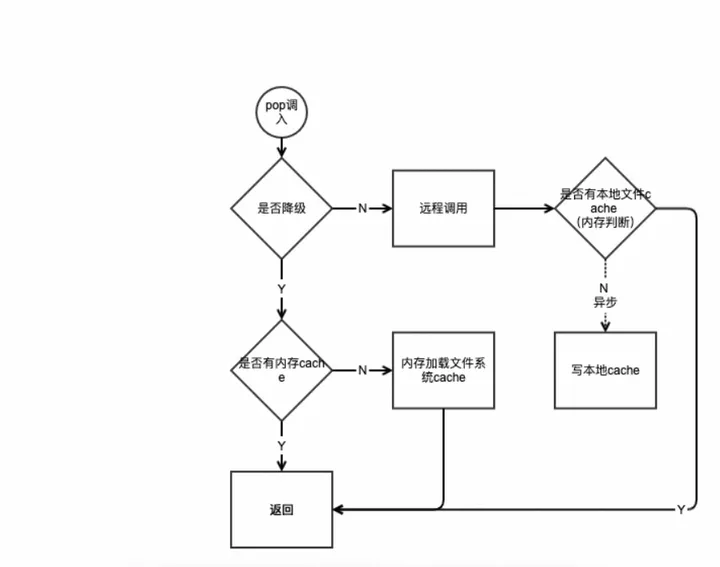
依赖服务非创建链路dubbo或http请求进行本地moc对于几乎不会频繁变化的依赖服务,通过每日sls分析进行kv的存储,当故障发生时,降级为备用,让降级影响面趋向于0。其他服务降级机制大分页流控cache创建类api进行依赖dubbo或http服务降级,异步补偿操作类api进行链路降级,取消非必需依赖数据库降级ro库流量降级隔离 用户级别流量切到灰度 api级别流量切到灰度/独立线程池日志debug及调用链路跟踪使用apicontext实现详细日志debug及调用全链路跟踪能力核心api debug日志建设,支持按用户开启debug日志打印requestId贯穿到dao,支持随时采样,及时发现dao异常调用服务依赖降级容错机制可以在保障服务稳定性的前提上,利用相关接口的历史缓存数据,基于SLS日志无损降级,当SLS无数据的时候也可以采用本地静态数据兜底,构建有效返回值,在服务触发流控降级熔断后,大部分用户不会感知到服务异常。
在内部的多次故障演练中,服务降级机制可以有效保护系统由于发生故障带来的系统瘫痪。服务可用性保障在传统的 Kubernetes 集群中,如果 Node 变得不可用且达到时间阈值,那么会将 Node 上的 Pod 进行驱逐,重新在其他 Node 上拉起新的 Pod。而在 Serverless 场景下,ECI管控会通过异步检测机制检测不健康ECI,修改状态为不可用,同时增加导致不可用的事件,告知ECI用户,之后ECI会通过主动运维的手段治愈不健康ECI,之后触发控制面将ECI恢复为Ready状态,主要过程如图所示:
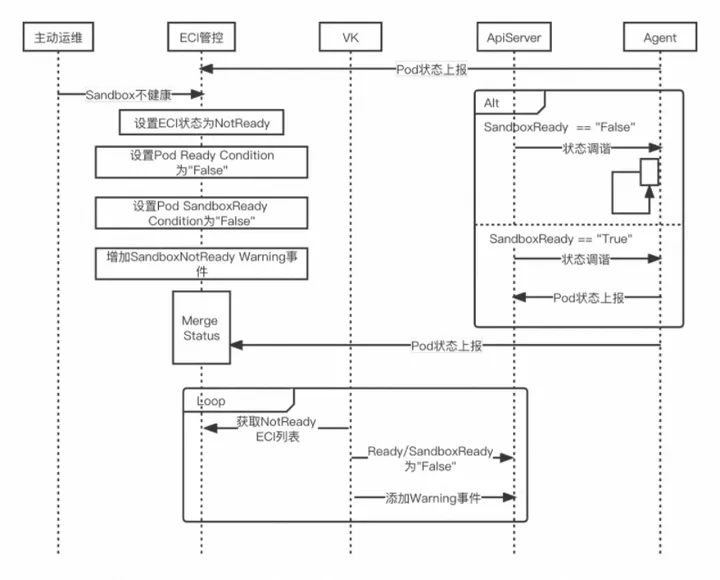
处理不健康 ECI 的流程:
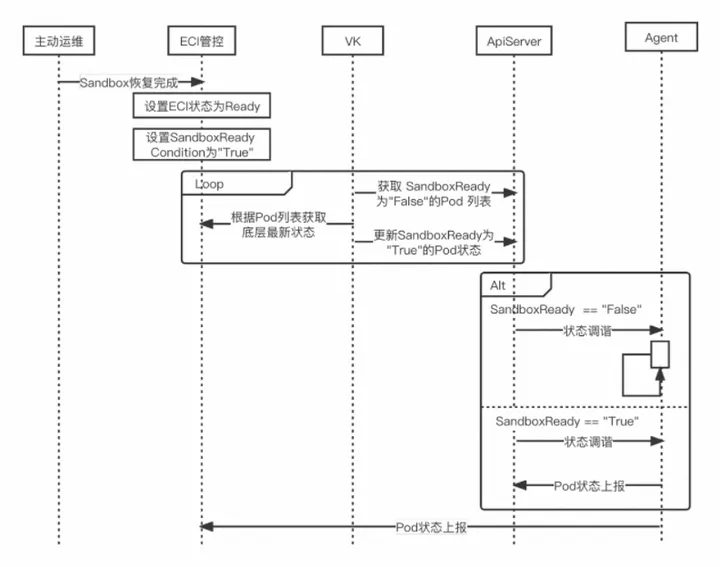
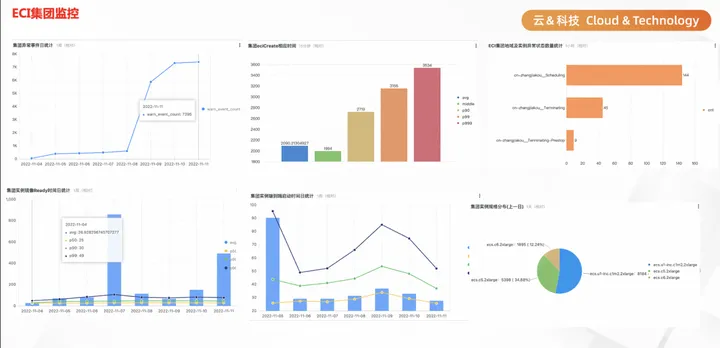
恢复 Ready ECI 流程预案&压测除了技术方面的保障,故障注入、应急预案、压测演练在稳定性建设中也尤为重要。在双十一活动期间我们内部进行了多次压测演练,对系统中常见的性能瓶颈进行故障注入,用以模拟故障的发生,同时制定应急预案,以此应对故障已经发生时的场景。通过多次的压测摸高,一方面可以评估系统容量的承载上限,另一方面可以借此机会进行大规模压测演练,验证系统降级方案并对系统稳定性进行评估。预警&监控大促进行时,预警和监控是保证系统运行时稳定性的重要措施。通过监控和预警可以及时发现系统故障,进而快速进行恢复。
四、系统的健壮性
思考沉淀一个健壮的系统不仅需要减少问题的发生,同时要具备故障发现以及故障快速恢复的能力。除了预警和监控,运维能力建设也十分重要。
一个系统的健壮性体现在系统的容量,系统的容错能力以及系统依赖的各个资源的sla,尤其是在云上复杂的资源环境下,由于“木桶效应”,某一项依赖资源的很可能造成整个系统的直接不可用。因此,随着系统不断完善,我们需要通过混沌工程等方法来找出当前系统的“弱点”进而对其进行专项优化,进而提升整个系统的健壮性;其二对于系统的故障恢复以及降级能力也很重要,历史上ECS/ECI管控多次由于单用户或系统某个环节变慢,导致系统全链路雪崩,最终导致P1P2故障,ECS/ECI管控是阿里云最复杂的管控系统,复杂的业务逻辑,内部系统依赖,非常多的环节出问题都有可能导致全链路某个应用雪崩进而全局不可用,因此,对于故障已经来临时,依赖降级能力能非常有效的保护我们的系统,这也是稳定性建设的一个十分重要的方向。
五、总结
未来展望随着双十一最后一波流量高峰结束,ECI顺利通过了对阿里人最严苛的技术考验–双十一,本文围绕此次参与双十一活动的经历做出总结,希望可以为今后ECI稳定性方面的建设积累经验,当然,这对ECI来说也仅仅是一步试金石,作为云原生时代的基础设施,ECI任重而道远,共勉!
本文出品及鸣谢: 柳密、羽云、景奇、存诚、 煜枫、景止、皓瑜、月悬、佐井、尚哲、涌泉、十刀、 木名、秉辰、易观、冬岛、不物、潇洛、 怀欢、 尝君、寒亭、伯琰。
原文链接
本文为阿里云原创内容,未经允许不得转载。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: vue中使用axios请求post接口为什么先发起OPTIONS请求再发起post请求?
在使用Axios进行跨域POST请求时,浏览器会先发起一个OPTIONS请求,这是因为浏览器执行了跨域请求时的预检请求(Preflight Request)。这是一个安全性措施,旨在确保跨域请求不会导致安全风险。 1、跨域请求的安全性: 当前端应用和后端API…
