
作者:华钟明
文章摘要:
本文整理自有赞中间件技术专家、Apache Dubbo PMC 华钟明的分享。本篇内容主要分为五个部分:
-GraalVM直面 Java 应用在云时代的挑战
-Dubbo享受AOT带来的技术红利
-Dubbo Native Image的实践和示例
-Dubbo集成Native Image的原理和思考
-Dubbo在Native Image技术的未来规划
GraalVM 直面 Java 应用在云时代的挑战
云计算时代比较显著的特点包括:
- 基于云计算的基础设施,我们的应用能够在云上快速、轻松且高效地做到弹性。尤其是无状态的应用,能够轻易地基于同一个镜像构建实例,当然也能轻易地收缩多余的实例,实现弹性伸缩容。
- 基于容器化技术,系统资源被切分的更细,资源的利用也变得更优。
- 基于云计算的开发平台,应用部署更加容易,应用开发更加敏捷。
那么在云计算时代,Java 应用存在哪些问题呢?
- 冷启动速度较慢。 Java 应用启动需要经历包括 JVM 的初始化、类加载等过程,导致启动速度相较于其他语言来说是处于劣势的。
- 应用预热时间过长,无法立即达到性能峰值。 比如如果没有对应用做一些预热机制,并且对 RT 又比较敏感的应用,会导致发布时有一定的接口超时情况。
- 内存、CPU 等系统资源占用高。 当占用过高时,不得不为 Java 应用提供更高规格的实例,而切分大规格的实例,这也会导致切分后造成的碎片更大,从而导致资源的浪费。
- Java 构建的应用程序繁重, 执行还需要具备 JDK 环境。

在云计算的时代中,Java 应用存在劣势,最明显的就是在 Serverless 场景。因为 Serverless 除了能够简化应用的开发外,最关键的就是能够做到让开发者的应用服务做的秒级弹性扩容。除了容器调度和新的 Pod 创建的时间损耗以外,镜像下载耗时、应用冷启动耗时、以及应用服务预热所需的耗时,都是影响弹性扩容的因素。
上图是 Datadog 统计了 FaaS 产品 AWS lambda 在各语言的使用程度,可以看出来即使 Java 依旧是最流行的编程语言,Java 与 Node.js 和 Python 的差距还是非常明显。Java 语言虽然更流行,但相较于 Python 和 Node.js,它的占比还是比较低的。

而面对 Java 语言的这些问题,GraalVM 也是应运而生。这里引用官网对 GraalVM 的介绍,GraalVM 能够提前将 Java 应用程序编译成独立的二进制文件。与在 Java 虚拟机上运行的应用程序相比,这些二进制文件更小,启动速度快 100 倍,在没有预热的情况下提供峰值性能,并且使用更少的内存和 CPU。是不是发现它解决的正是刚刚所提到的所有问题。包括冷启动速度问题、启动后需要预热、内存占用和 CPU 使用率也相对较高,甚至能够降低二进制文件的大小。二进制文件大小的降低更有利于容器镜像大小的缩减,减少镜像下载所需的时间。
GraalVM 可以理解为是 OpenJDK 的一个“超集”,它不但包含了完整的 JDK 发行版本,还包含 GraalVM Compiler、Native image、Truffle 等组件, 并且支持多语言混编等能力。这就意味着在使用这些新的能力的同时,Java 应用程序也能够按照原有的形式在 Graalvm 环境下正常的运行。
而在这个介绍中我们能够看到一个关键的的技术点,那就是 ahead of time,AOT 技术。传统的 Java 开发中,我们采用的都是 JIT,JIT 即为将我们编写的 Java 源代码编译为 .class 文件,并在运行期间将 JVM 认为是热点的字节码转化为机器码,加快程序运行速度。而 AOT 则是在编译期间就将字节码转化为了机器码,它将不再会有运行期还在持续将热点的字节码转化为机器码的操作。GraalVM 本身就包含了 JIT 和 AOT 这两部分。
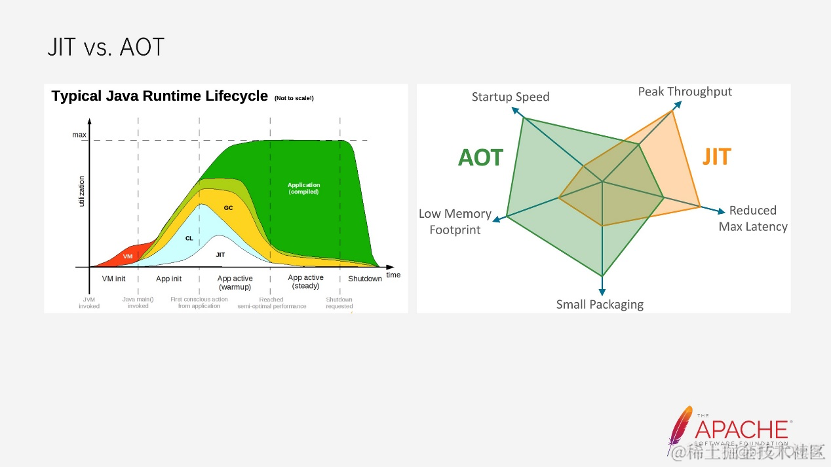
看左边的这张图,它就是一个标准的 Java 应用完整的生命周期。首先是 JVM 的启动初始化,然后到 Java main 函数的启动和调用,然后是应用预热的阶段,然后才是到达应用稳定运行的阶段,最后是应用销毁,至此整个 Java 应用的生命周期完结。可以看到在 Java 的整个生命周期中,如果是传统的 JIT 模式,从启动到达到应用平稳的阶段,需要经过 JVM 的初始化,类加载,解释器执行、即时编译、GC,并且即使到达了应用的稳定阶段,JIT、解释器依旧还在运行。
而对于 GraalVM 中的 AOT 技术而言,首先省去了 JVM 的启动,也就是红色区域的时间,第二是省去看解释器和编译器所占用的时间。那么既然 AOT 这么多优点,是否能替代 JIT,从目前来看还是没有办法替代的,右边这张图就说明了虽然现在 AOT 具备非常客观的启动速度提升,非常低的资源消耗,以及包的大小更小等优点,但是在吞吐量的峰值和最大延迟上还是 JIT 更优一些。
Dubbo 享受 AOT 带来的技术红利
1. 多产物形态
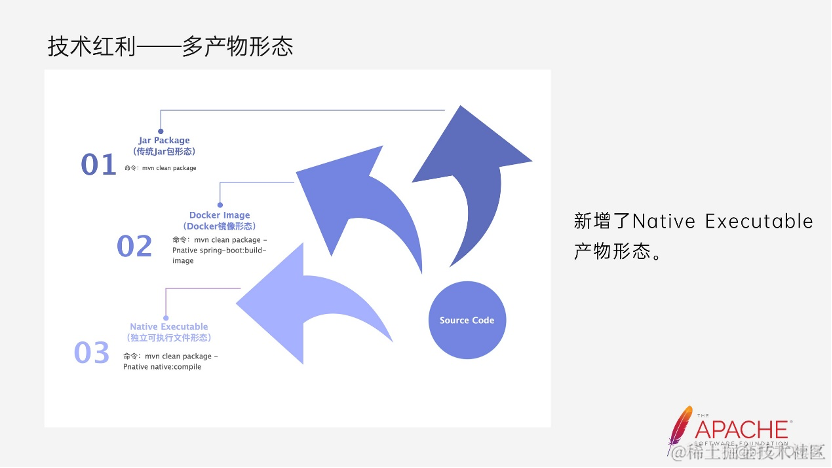
当我们编写完程序的源代码后,需要对源码进行编译打包,生成能够启动 Dubbo 应用程序的目标产物,目前还是以第一种 Jar 包的形态居多。
而第二种则是引入 Spring Boot 后支持的产物形态,采用 Spring Boot 的插件,能够快速的生成容器镜像,而无需自己写比如 Docker file,手动把 Jar 打包到镜像中。方便了 Dubbo 应用的容器化部署。
而第三种则是 Dubbo 支持 GraalVM 后所新增的产物形态:Native Executable。
这三种产物的打包命令也有所区别,传统的 Jar 包形态,是最常见的 mvn clean package,第二种则是执行了 SpringBoot 的插件,第三种则是在编译阶段执行了 native 相关的插件。这种新的产物 Native Executable 能够做到无需安装 JDK 环境即可启动应用程序。
2. 启动耗时大幅降低
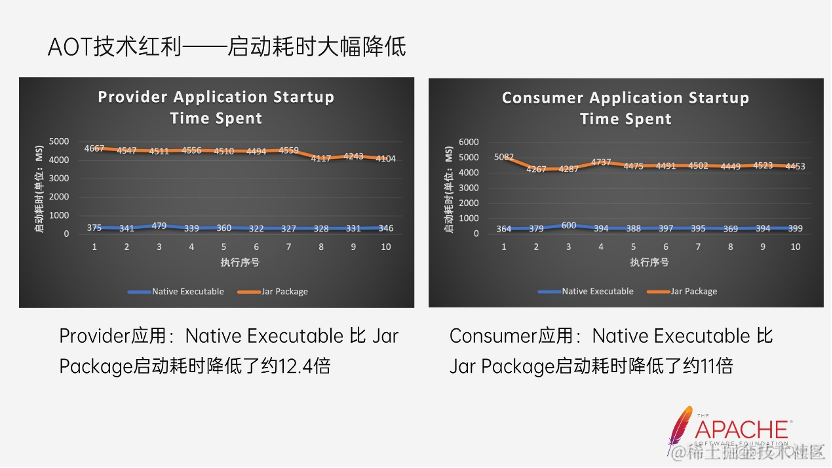
Dubbo 框架发展有近十年,提供的能力也越来越强大,同时 Dubbo 应用的启动速度一直也是令我们比较头疼的事情,但是随着集成 GraalVM Native Image 后,这个问题也让我们看到了希望。
这上面展示了两张图,第一张图描述的是分别在 Native Executable 和 Jar package 的场景下,仅提供一个 Dubbo 服务的应用启动耗时对比。这里的数据都统计与 4c16g 的 macOS 系统下,并且每个场景都跑了 10 组数据。这里的启动耗时也将 JVM 启动耗时考虑进去,比如 Jar package 场景下的耗时计算的是从 java -jar 启动 Java 应用直到应用启动就绪,所需的耗时。
从对比图可以看出,Native Executable 比 Jar package 的启动耗时降低了 12.4 倍,也就是启动速度提升了 12.4 倍。第二张图则是仅存在一个 Dubbo 服务 Consumer 的应用启动耗时对比,从对比图可以看出,Native Executable 比 Jar package 的启动快了 11 倍。由此看出集成 GraalVM Native Image 后,Dubbo 应用真正的能够实现毫秒级启动。
3. 启动后立即达到性能峰值
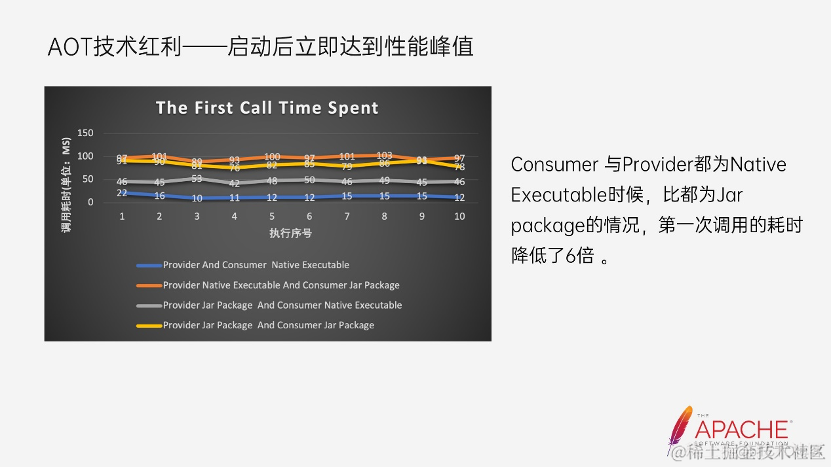
从统计图表上看,当 Consumer 和 Provider 都为 Native Executable 时,比他两都是 Jar package 的情况第一次调用的耗时足足减少了 6 倍。使 Dubbo 应用能够在启动后立即达到性能巅峰。启动耗时和启动即达到性能巅峰,这两个技术红利也让 Dubbo 有机会拓展在 Serverless 或者说是 Faas 技术场景的应用范围。
4. 内存损耗大幅降低
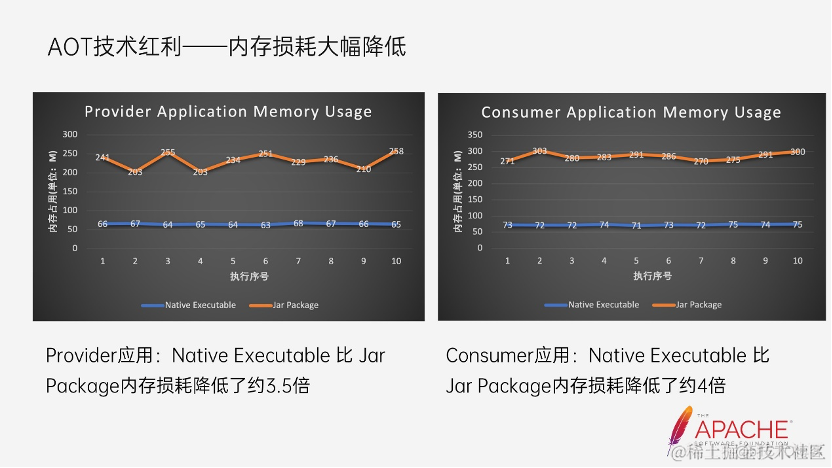
在这里同样给出了 Provider 与 Consumer 应用在 Native Executable 与 Jar Package 两个场景下的内存对比统计图,拿第一张图,可以看到,Jar Package 启动后,所需的内存是 200 多兆,而 Native Executable 仅占了 60M 左右,在内存损耗上整整降低了 3.5 倍,在如今降本的大环境下,使得我们能够对 Java 应用降低内存使用,节省系统资源充满了更多的想象空间。

除了以上四个技术红利以外,Dubbo 在集成 GraalVM Native Image 技术的同时,也在不断完善相关的内容。
首先是在易用性上得到了增强, 在 RPC 框架中,服务接口的定义是由业务决定的,而这些服务接口同样需要配置对应的可达性元数据,才能实现 RPC 调用,Dubbo 在注解和 XML 的配置方式中实现了自动生成可达性元数据,无需应用的开发者自行配置 Reachability Metadata 配置。
第二点是可维护性增强, 对于 Dubbo 的开发者和贡献者,也无需再有意识地维护这些 Dubbo 框架所需的Reachability Metadata 和Adaptive source code。举个例子,比如Dubbo 新增了一块新的功能,Dubbo 的贡献者新增了一个 SPI 接口,而他无需考虑在 native image 场景下生成 Adaptive source code。
第三点是对多平台的支持, 包括我们所熟知的 Linux、MacOS、Windows 操作系统。最后一个是 Dubbo 内的多种能力都能在 native image 场景下能够正常使用,比如 Dubbo 协议以及 Dubbo3.x 中的Triple协议。
##vDubbo Native Image 的实践和示例

首先需要安装 Dubbo Native Image,这里就不过多介绍了,大家可以根据官方的文档进行下载。
然后安装插件,可以看到上图中有三个插件需要安装,但和 Dubbo 相关的只有一个,是 Dubbo Maven Plugin。
第一张图就是 Dubbo 新版本提供的用于适配 GraalVM Native Image 的 maven 插件。第二张图则是 SpringBoot 的 maven 插件,用于处理 Spring Boot 的 AOT 处理逻辑。如果采用的是 Dubbo 的 API 接入方式,则无需配置 SpringBoot 的 maven 插件。第三张图则是 GraalVM 官方提供的 maven 插件,它集成了打包编译 Native Executable 的逻辑。

接下来是配置所需的依赖,Dubbo 集成 Native 还需要额外配置两个依赖,也就是 dubbo-native 和 dubbo-config-spring6,其中 dubbo-config-spring6 也与前面的 SpringBoot 插件一样,如果不采用 xml 或者注解的方式接入,则无需配置该依赖。它主要用于适配 Spring6,因为目前 Dubbo 还兼容着低版本的 Spring 和 Springboot,并且还兼容着 JDK8 和 JDK11,而 Springboot3.0 和 spring6 以上的版本将最低的 JDK 版本调整为了 JDK17,所以目前使用该模块来适配和兼容高版本的 Spring。
dubbo-native 中集成了 dubbo 所有的 source code 和 Reachability Metadata 生成的逻辑。以保证 Dubbo 应用能够正常被编译打包成 Native Executable,并用 Native Executable 形态正常运行。
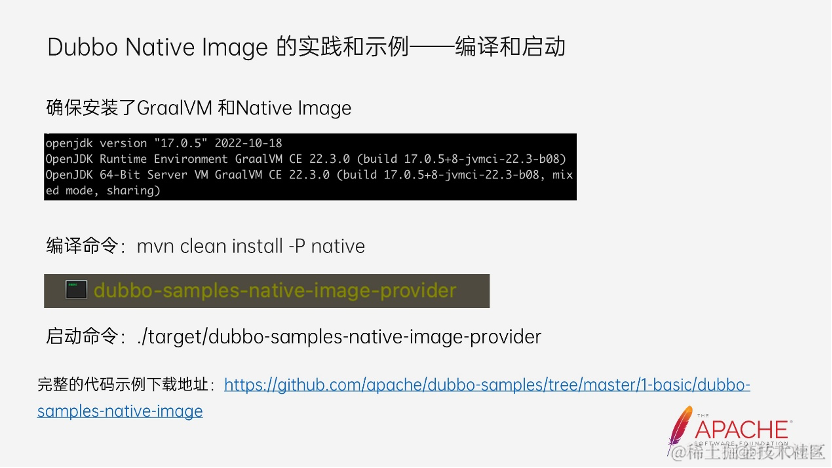
除此上述的配置以外,其他的使用方式都没有任何变化,开发者就可以把一个应用打包成 Native Executable。这里罗列了编译的命令,编译是需要 GraalVM 的环境和 native-image 工具,所以在编译前先检查环境是否正常。编译完后,在工程的根目录下就会出现一个 Native Executable,直接启动它,即可完成应用的启动。完整的示例代码在 dubbo-samples 下,感兴趣的朋友也可以自行去体验。
最下面是完整的代码示例,大家感兴趣的话,可以尝试一下编译打包,看一下执行的效果。
Dubbo 集成 Native Image 的原理和思考
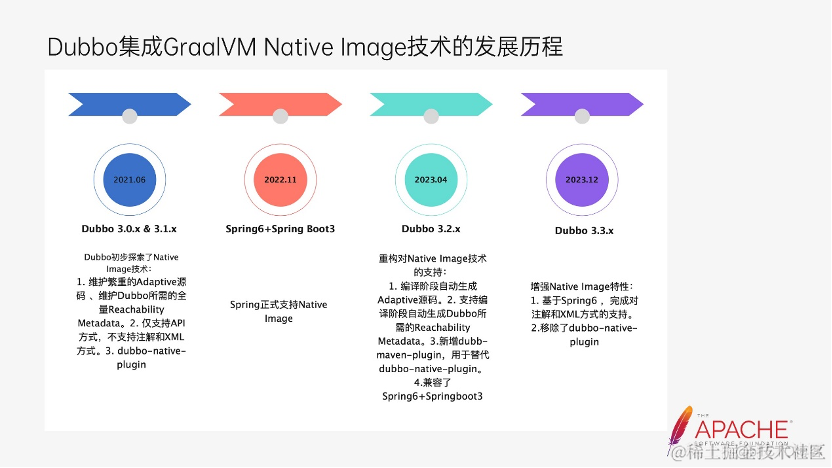
Dubbo 在 21 年 6 月份正式发布 Dubbo3.0,Dubbo 社区的成员初步调研了 GraalVM Native Image 技术,并在 3.0 的其中一个迭代版本中初步支持了 Native Image,但当时仅仅是以实验性 Demo 呈现,并没有过多的考虑生产环境的用户如何使用、Dubbo 的贡献者的维护成本等问题。初版的支持存在以下四个比较严重的问题:
1. Dubbo 核心仓库内需要维护 Adaptive Source code
当时应该是提供了一个生成 Adaptive Source code 的工具,提供给用户自行通过工具为 SPI 接口生成 Adaptive Source code。并且它会被直接生成在应用工程目前下,而并不是生成在 target 目录下,则对开发者应用程序源码有一定的侵入。
2. Dubbo 需要维护全量的 Reachability Metadata
如果 Dubbo 核心的仓库,举个例子,Dubbo 的注册中心支持 Zookeeper 和 Nacos,假如应用仅仅采用了 Zookeeper,没有用到 Nacos,但是因为 Dubbo 维护着全量的 Reachability Metadata,所以在打包时,也会把这些全部打包进入 Native Executable 中,导致可执行文件的大小膨胀,并且编译打包时间也变久了。除此之外,Dubbo 的贡献者如果新增了什么功能,也需要手动在对应的配置中维护 Reachability Metadata,如果忘记了,则会导致这块功能将无法在 native image 下使用,甚至可能导致打包编译的失败。
3. 仅仅支持 API 接入的方式,而不支持 XML 和注解的接入方式
我们知道,Dubbo 的大部分用户采用的还是 XML 和注解的接入方式,这就导致觉大多是的用户都无法使用该项能力。
4. dubbo-native-plugin 的内容过于聚焦
当时新增加了一个 dubbo-native-plugin 的 maven 插件,用于 native 相关的编译打包处理,这个插件的内容过于聚焦,后续将会导致 Dubbo 的用户每接入一个新的 Dubbo 功能,就需要接入一个新的插件,它并不利于后续 Dubbo maven plugin 的迭代和特性增强。并且会给 Dubbo 的用户带来使用和维护 Maven 插件的困扰。
随着这个实验性的 Native Image 技术支持后,在后续的 3.1 版本,也再没有更多的的更新迭代。
随着 2022 年 11 月份,Spring6 和 Spring boot 3.0 的发布,并伴随着 GraalVM Native Image 作为新版本一个非常具有亮点的特性亮相后,Dubbo 社区也意识到,Dubbo 集成 GraalVM Native Image 应该需要跨出一个新的阶段了。
我们会发现,人工去维护这些内容实在非常耗费精力,并且它给 code review 也带来了比较大的压力,需要提前判别出这部分改动可能会存在 Reachability Metadata。而经过几个版本的迭代,我们发现在 coding 和 code review 阶段遗漏了是普遍存在的。在 2023 年 4 月,发布的 3.2 版本中,我们重新思考并且重构了对 GraalVM Native Image 技术的支持,解决了之前实验性版本的问题:
- 编译阶段自动识别所需的 SPI 接口,并自动生成 Adaptive Source code。并且按照标准的 Java 编译产物目录结构,这些 Source Code 被生成在 target 目录下。并且这部分的 Source code 也不再 dubbo 核心仓库内维护,它是编译阶段动态生成的。
- 支持编译阶段自动生成 Dubbo 框架所需的 Reachability Metadata。同样无需开发者再维护这部分的配置信息。
- 除此之外,新增了 dubbo-maven-plugin,希望能够替代 dubbo-native-plugin。我们认为 dubbo-maven-plugin 应该作为 dubbo 框架对开发者输出的唯一一个 maven plugin,而所有需要借助 maven plugin 构建出来的新特性,都应该迁移到该 maven plugin 中。这样能够降低开发者的心智负担。
在 Dubbo 3.2 版本还有一个重要的迭代,那就是支持并且兼服务器托管网容了 Spring6 和 Spring Boot3,这也为 Dubbo 能够在 xml 和注解的接入姿势上提供 native image 能力打下了基础。在今年年底即将发布的 dubbo 3.3 版本中,将在支持 xml 和注解的接入方式上支持 native image。

在前面的介绍中多次提到一个词,那就是 Reachability Metadata,Dubbo 在集成GraalVM Native Image 也主要是围绕着 Reachability Metadata 的处理。
那么它到底是什么?AOT 也存在自己的局限性,那就是它遵循封闭世界假设原则。也就是需要依赖于能够“看到全部的字节码”才能正确工作,这将导致 AOT 无法支持动态语言的功能,比如 JNI、Java 反射、动态代理、 ClassPath 资源的获取等能力。
在 Java 开发过程中,这些 Java 的动态能力被运用在各种场景中,它们早已经是 Java 开发者非常熟练的编码手段。所以 GraalVM 同样也考虑到了这个情况。在既不打破“封闭时间假设”原则的前提下,通过 Reachability Metadata 来解决这类问题。既然需要在编译器中能够确定所有的字节码和资源,那么就让开发者在编码阶段就确定这些元数据信息。
这张图中罗列了 Reachability Metadata 目前主要用到五种:分别是与JNI Metadata、Resource Metadata、Dynamic Proxy Metadata、Serialization Metadata、Reflection Metadata。官网上还有上还有第六种 Predefined Classes Metadata,因为它需要配置完整的类字节码 hash 值,它更多是配合 Tracing agent 配使用。对于开发者比较关心的问题就是,如何获取并提供这些 Reachability Metadata,从而达到 Native Executable 成功构建和执行的目的。
首先,GraalVM 提供了 Tracing Agent,来辅助开发者在运行时采集对应的Reachability Metadata。但是通过 Tracing Agent 采集的元数据并不能保障能够采集完整,原因是 Tracing Agent 只跟踪和采集执行的代码,而程序输入没有覆盖的代码路径,将无法采集到。GraalVM官网也建议采集后还需要手动 check 元数据。
第二个是 GraalVM 提供了 Reachability Metadata Repository,Java 发展这么多年,诞生出了非常多的组件库,业务开发可以非常轻松地使用这些组件来完成业务功能。纯粹的业务逻辑运用到 Java 动态语言特性的场景并不多,反而是这些组件库使用这些特性更加频繁,所以 GraalVM 提供了这 个Reachability Metadata Repository,吸纳来自不同的组件的 Reachability Metadata。
举个例子,Netty 是使用较为频繁的网络通信框架,Netty 内部用到了反射。而在这个仓库内,能够找到Netty的Reachability Metadata。那么这个仓库内的 Reachability Metadata 如何才能被应用使用,答案是使用 GraalVM 官方提供的 native-maven-plugin。
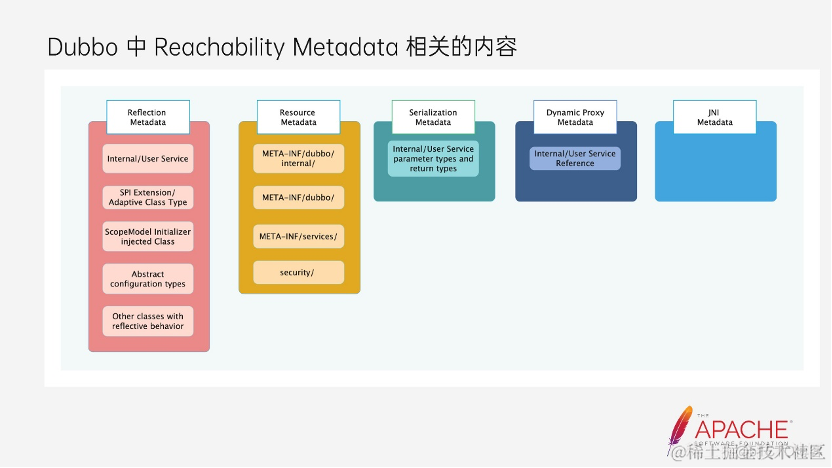
了解了 Reachability Metadata,与 Dubbo 相关的 Reachability服务器托管网 Metadata 有哪些?这张图列举了 Dubbo 对应的一些元数据场景,Dubbo 使用最多的就是反射。
第一个场景就是服务,Dubbo 是一个 RPC 框架,定义服务接口是最基本的需求,同时运行时通过反射获取接口的方法等操作非常频繁。这里区分了内外部的服务接口,原因是 Dubbo 框架内还有一些内建的服务,比如 MetricService、MetadataService 等。
第二个 SPI Extension 类和 Adaptive 类,我们知道 Dubbo 强大且灵活的扩展性得益于它自有的一套 SPI 机制,其中定义为 SPI 接口的实现类,以及 Adaptive 类都需要用到反射。当然这里的 SPI 扩展实现类,也包含业务自己实现的类,比如大家最熟悉和应用最广泛的 Dubbo 执行链中的 Filter,即使业务有自己的实现类,Dubbo aot 也能扫描到并且加载。
第三类是多实例的启动时候需要提前加载一些相关的类。
第四类是 Dubbo 核心的配置类,有通过 API 接入的方式使用经验的朋友应该清楚,比如 ServiceConfig、RegistryConfig 等。
最后是一些其他反射行为,这里包括的是 Dubbo 依赖的组件,存在一些反射行为,比如 ZK 中有反射。第二种是 Resource Metadata,Dubbo 相关的就以下四个资源文件,META-INF 下的这三个资源文件大家都比较熟悉,我们在使用 Dubbo 的 SPI 时,必须配置扩展实现的配置。才能保证 SPI 的实现被加载到。
第四个安全的资源文件, 包含了序列化所需的黑白名单。它能够防范一些序列化的 RCE 漏洞问题,这是 Dubbo3 版本新增的,为了加强服务的安全性。序列化相关的 Metadata。与 Dubbo 相关的主要是内外部服务方法的返回类型和请求参数类型。Dubbo 作为一个 RPC 框架,基本能力就是实现 RPC 调用。在调用过程中无论是请求还是响应,都需要被序列化和反序列化。
第四个就是到动态代理的元数据,在 Dubbo 中主要是在 Consumer 需要有生成动态代理类,用于代理远程的服务接口。屏蔽掉一些网络传输、序列化等行为的细节,让调用方能够像本地方法调用一样使用。而最后一个 JNI 目前 Dubbo 内还没有相关的元数据信息。

这是 Dubbo 相关的 Reachability Metadata 总结和处理策略,我们把它分为了四类。
1. 规律性的内容: 是具备一定规律且需要被可生成的内容,比如刚刚提到的 Adaptive Source Code 的生成。
2. 确定性资源和行为: 确定的是 Dubbo 内自身在 Native 场景所需的的资源,比如 SPI 的配置文件等。
3. 不确定性的资源和行为: 是业务基于 Dubbo 的能力所添加的资源或行为,这部分被称为不确定性的资源和行为,比如业务自定义的 SPI 扩展实现以及定义的服务等。
4. 集成和依赖的组件: 比如刚刚提到 Zookeeper 等涉及到的元数据信息。
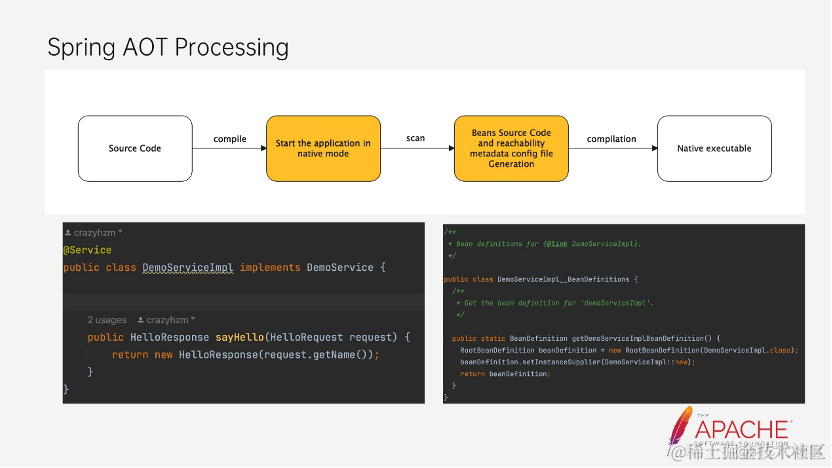
Spring 和 Dubbo 都有自己的 AOT 处理逻辑,但是它们之间的处理又有些不同,这是 Spring Aot 的处理逻辑,可以看到从源码编译开始,Spring 会直接从 main 函数启动应用程序,并且会将 Spring bean 生成的 source code 生成,以及对应的 Reachability Metadata 生成。对于 Spring 而言,在启动和扫描过程已经能够完成所有 Metadata 的扫描。
下面这个就是通过 Spring AOT 生成的 Bean Source code,当我们简单的用一个 Spring 的 Service 注解时。这个 DemoService 的实现类就被定义为一个 Spring 内的 Bean,而经过 AOT 处理后,会生成右边这个与 DemoService 有个的 BeanDefinition 的提供类。用于在加载 Bean 时候获取相关的信息。
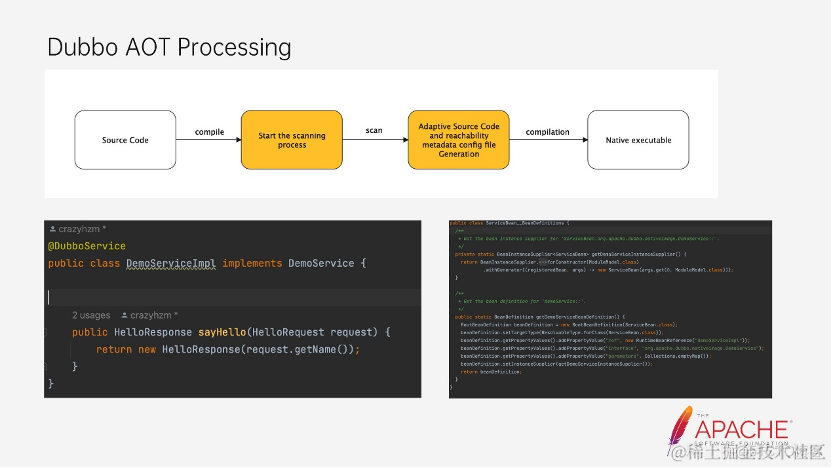
而 Dubbo 的 AOT 则是在源码开始编译后,会启动一个扫描的进程,来完成刚刚列举的与 Dubbo 有关的 Reachability Metadata 和对应的 Source code。可以看到,我们将 Spring 的 Service 注解换成 Dubbo 的 DubboService 注解后,同样也会得到一个与 DemoService 有个的 BeanDefinition 的提供类,但是里面的内容是 Dubbo 提供的。包括拼接 interface 等参数。这里就是 Spring AOT 处理和 Dubbo AOT 的处理结果,可以看到分别在 spring-aot 和 dubbo-aot 下生成了 GraalVM 所需的 Reachability Metadata,以及他们各自的 Source code。
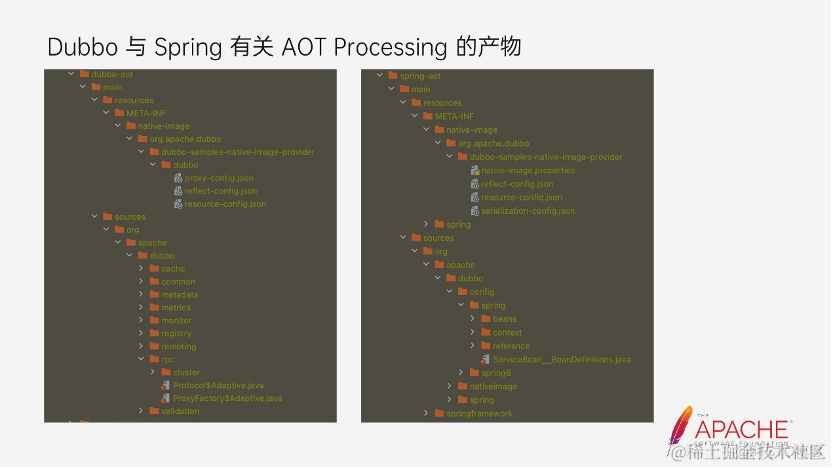
上图是 Spring 本身提供的一个产物的内容以及 Dubbo 的 AOT 产物的内容。可以看到 Dubbo 下面是 Adaptive 的一些 source code。最后 Native 在执行的时候会读取到这里所有的配置。
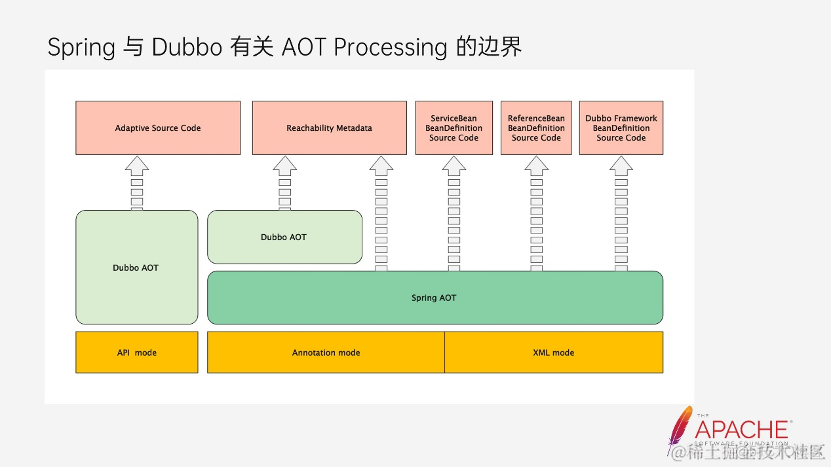
这是后续 Dubbo 在 AOT 演进上与 Spring AOT 的边界,首先在 API 接入的方式中,Dubbo 不依赖于 Spring,所以它能够完成所有的内容,包括所需的 Adaptive Source code 和 Reachability Metadata。其次因为 XML 和注解都依赖于 Spring,所以 Dubbo 内的 Bean 都将会依托于 Spring AOT 的能力来实现,包括 ServiceBean、ReferenceBean 以及 Dubbo 框架内的与 Spring Bean 有关的内容。除此之外,Spring 也会生成所需的 Reachability Metadata。
Dubbo 在 Native Image技术的未来规划
1. 提升开发者体验&开发效率
第一点就是提升开发者体验和开发效率。Dubbo 在 3.0 之后提供了 CTL、脚手架、IDEA 插件,Dubbo Native Image 目前还在建设中,之后也会将 Native Image 加入其中。此外,还有关于一些 Dubbo Native 的文档建设也会逐步开展。
2. 性能优化与提升
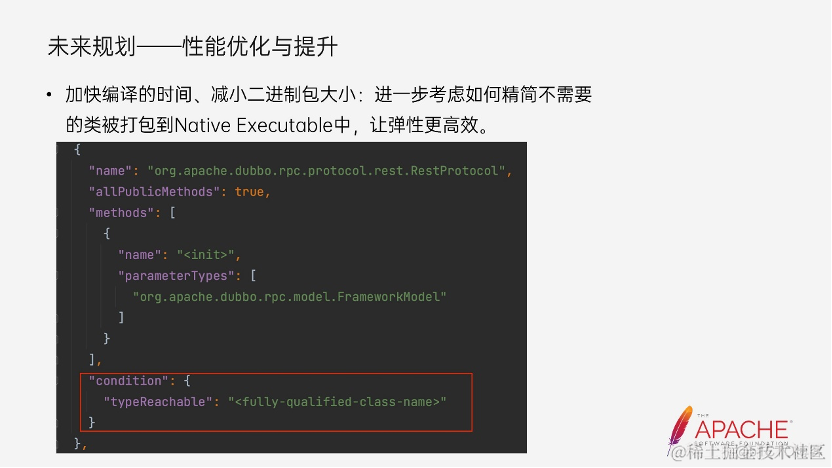
第二点是性能优化和提升。在 GraalVM 提供的能力上,我们还可以把一些类相关的可达性的配置加上去,产生作用之后能让最后打出来的二进制包更小,编译时间更短。
###v3. 覆盖更多的组件

第三点则是覆盖更多的组件。因为目前很多组件都还不支持,所以我们现在的主要思路是把 Dubbo 主仓库的扩展性支持完成,然后再往 dubbo-spi-exntensions 的扩展上做相应的支持。另外,内核所需要的可达性的元数据,我们会把它推到 GraalVM 的可达性的元数据的仓库上面去,让业务开发能够正常使用 Dubbo 内核所需的元数据信息。
最后是我们覆盖更多组件的思路:我们会优先考虑 GraalVM 官方的支持,但是因为 GraalVM 发布周期不可控,推进的时间可能也会比较长,所以我们也会为一些通用且必要的组件优先支持元数据,让 Dubbo 用户能够提前享受到 Native Image 所带来的技术红利。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 大数据Spark “蘑菇云”行动第93课:Hive中的内置函数、UDF、UDAF实战
大数据Spark “蘑菇云”行动第93课:Hive中的内置函数、UDF、UDAF实战 select sum_all(age) from … hive> use default; show tables; select * from employee…
