
一.模型介绍
图像扩展是突破了模型界限,极大地促进了计算机视觉基础模型的发展。
图像扩展是一个提示型模型,其在1100万张图像上训练了超过10亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是CV的GPT-3时刻,因为图像扩展已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为CV基本模型的巨大潜力。
图像扩展模型概览
2023年4月6号,Meta AI公开了Segment Anything Model(图像扩展),使用了有史以来最大的分割数据集Segment Anything服务器托管网 1-Billion mask dataset(SA-1B),其内包含了1100万张图像,总计超过10亿张掩码图,模型在训练时被设计为交互性的可提示模型,因此可以通过零样本学习转移到新的图像分布和任务中。在其中他们提出一个用于图像分割的基础模型,名为图像扩展。该模型被发现在NL服务器托管网P和CV领域中表现出较强的性能,研究人员试图建立一个类似的模型来统一整个图像分割任务。
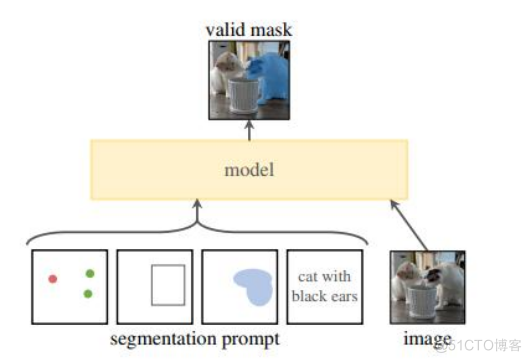
图像扩展架构主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。
Meta AI提出一个大规模多样化的图像分割数据集:SA-1B(包含1100万张图片以及10亿个Mask图)
在这项工作中,图像扩展的目标是建立一个图像分割的基础模型(Foundation Models)。其目标是在给定任何分割提示下返回一个有效的分割掩码,并在一个大规模且支持强大泛化能力的数据集上对其进行预训练,然后用提示工程解决一系列新的数据分布上的下游分割问题。
项目关键的三部分包括组件:任务、模型、数据。
任务:在NLP和CV中,基础模型是一个很有前途的发展,受到启发,研究者提出了提示分割任务,其目标是在给定任何分割提示下返回一个有效的分割掩码。
二.模型架构
三.我的工作
1.准备数据集:为了微调图像扩展模型,我需要准备一个包含标注数据的数据集。
2.def__init__(self, root, split=‘train’, mode=‘fine’, target_type=‘semantic’, transform=None):
self.root = os.path.expanduser(root)
self.mode = ‘gtFine’
self.target_type = target_type
self.images_dir = os.path.join(self.root, ‘leftImg8bit’, split)
self.targets_dir = os.path.join(self.root, self.mode, split)
self.transform = transform
self.split = split
self.images = []
self.targets = []
ifsplit not in [‘train’, ‘test’, ‘val’]:
raiseValueError(‘Invalid split for mode! Please use split=”train”, split=”test”‘
‘ or split=”val”‘)
ifnot os.path.isdir(self.images_dir) or not os.path.isdir(self.targets_dir):
raiseRuntimeError(‘Dataset not found or incomplete. Please make sure all required folders for the’
‘ specified “split” and “mode” are inside the “root” directory’)
forcity inos.listdir(self.images_dir):
img_dir = os.path.join(self.images_dir, city)
target_dir = os.path.join(self.targets_dir, city)
forfile_name inos.listdir(img_dir):
self.images.append(os.path.join(img_dir, file_name))
target_name = ‘{}_{}‘.format(file_name.split(‘_leftImg8bit’)[0],
self._get_target_suffix(self.mode, self.target_type))
self.targets.append(os.path.join(target_dir, target_name))
@classmethod
defencode_target(cls, target):
returncls.id_to_train_id[np.array(target)]
@classmethod
defdecode_target(cls, target):
target[target == 255] = 19
#target = target.astype(‘uint8’) + 1
returncls.train_id_to_color[target]
def__getitem__(self, index):
“””
Args:
index (int): Index
Returns:
tuple: (image, target) where target is a tuple of all target types if target_type is a list with more
than one item. Otherwise target is a json object if target_type=”polygon”, else the image segmentation.
“””
image = Image.open(self.images[index]).convert(‘RGB’)
target = Image.open(self.targets[index])
ifself.transform:
image, target = self.transform(image, target)
target = self.encode_target(target)
returnimage, target
def__len__(self):
returnlen(self.images)
def_load_json(self, path):
withopen(path, ‘r’) asfile:
data = json.load(file)
returndata
def_get_target_suffix(self, mode, target_type):
iftarget_type == ‘instance’:
return‘{}_instanceIds.png’.format(mode)
eliftarget_type == ‘semantic’:
return‘{}_labelIds.png’.format(mode)
eliftarget_type == ‘color’:
return‘{}_color.png’.format(mode)
eliftarget_type == ‘polygon’:
return‘{}_polygons.json’.format(mode)
eliftarget_type == ‘depth’:
return‘{}_disparity.png’.format(mode)
2.加载预训练模型:需要加载已经预训练好的图像扩展模型。
3. 冻结层:为了防止在微调过程中破坏预训练模型的权重,我需要冻结一些层。这些层的权重将不会被更新。
4. 添加自定义层:我添加了自定义层来适应自动驾驶分割的任务。这些层可以是全连接层、卷积层、池化层等。
5. 训练模型:通过反向传播算法,训练图像扩展模型。在训练过程中,可以调整学习率和批次大小等参数。
6.评估模型:在训练完成后,评估图像扩展模型的性能。
defvalidate(opts, model, loader, device, metrics, ret_图像扩展ples_ids=None):
“””Do validation and return specified 图像扩展ples”””
metrics.reset()
ret_图像扩展ples = []
ifopts.save_val_results:
ifnot os.path.exists(‘results’):
os.mkdir(‘results’)
denorm = utils.Denormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
img_id = 0
withtorch.no_grad():
fori, (images, labels) intqdm(enumerate(loader)):
images = images.to(device, dtype=torch.float32)
labels = labels.to(device, dtype=torch.long)
7.微调模型:如果模型性能不够好,我通过Intel的架构One API微调它。微调包括调整超参数、修改网络结构等操作。最后得到了较好的效果。
四.测试
一开始测试效果很糟糕,各个物体的边缘都不大清晰,怀疑是损失函数的问题,多次尝试不同损失函数之后,得到了最好的效果如下:


五.总结
在这次比赛中,我收获匪浅,不仅仅得到了比赛的相关经验和经历,还利用了最先进的Intel架构和相关的图像分割顶尖模型,能够让我学到更多并且走得更远!正如我标题所说,站在巨人的肩膀上!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: SSE图像算法优化系列三十一:RGB2HSL/RGB2HSV及HSL2RGB/HSV2RGB的指令集优化-上。
RGB和HSL/HSV颜色空间的相互转换在我们的图像处理中是有着非常广泛的应用的,无论是是图像调节,还是做一些肤色算法,HSL/HSV颜色空间都非常有用,他提供了RGB颜色空间不具有的一些独特的特性,但是由于HSL/HSV颜色空间的复杂性,他们之…
