
| paper | code |
|---|---|
| https://arxiv.org/pdf/2210.10542.pdf | https://europe.naverlabs.com/research/computer-vision/posegpt/ |
方法 1.将动作压缩到离散空间。2.使用GPT类的模型预测未来动作的离散索引。3.使用解码器解码动作得到输出。
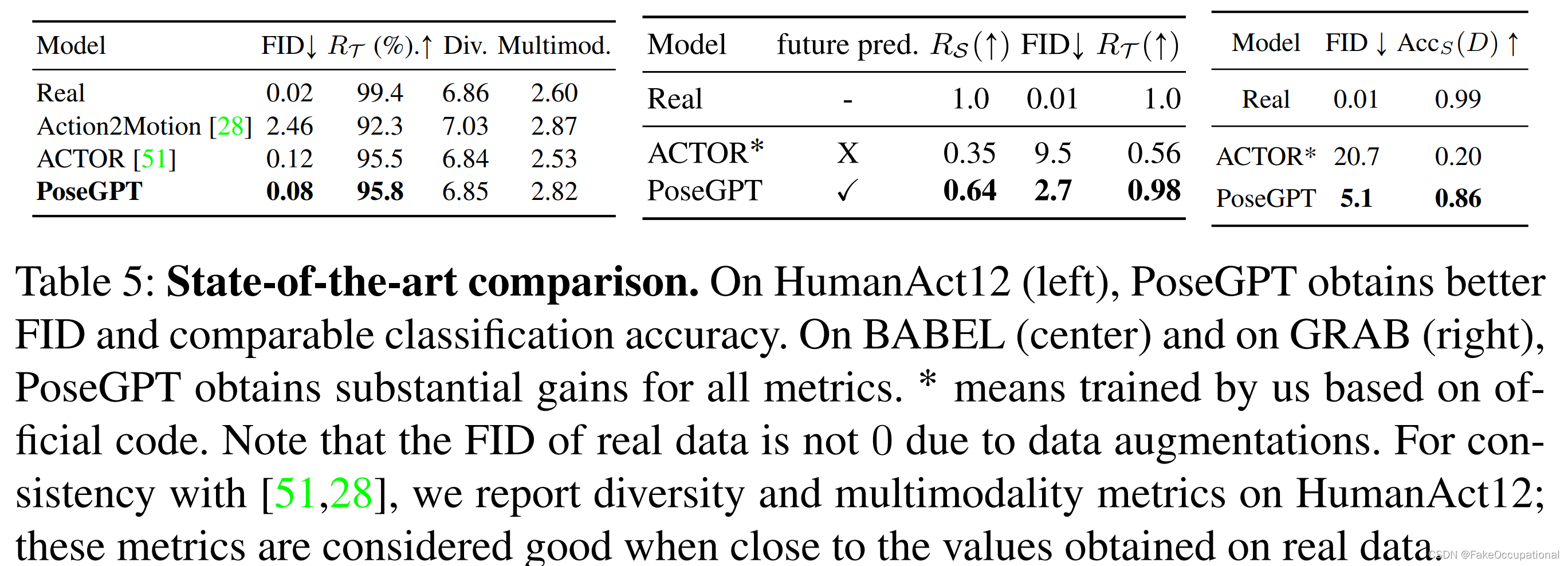
效果 提出的方法在HumanAct12(一个标准但小规模的数据集)以及BABEL(最近的大规模MoCap数据集)和GRAB(人-服务器托管网物体交互数据集)上取得了最先进的结果。
方法总览
PoseGPT 生成一个人体运动序列,以动作标签、持续时间
T
T
T 为条件(观察到的过去人类运动为可选条件)。类似GPT[54]的模型G按顺序预测离散的潜在指数,这些指数使用解码器D解码为生成的人体运动。当也对过去的人体运动进行调节时,输入的人体运动用 E 编码,并使用
q
(
⋅
)
q(cdot)
q(⋅) 量化到离散潜在空间中。

实现细节
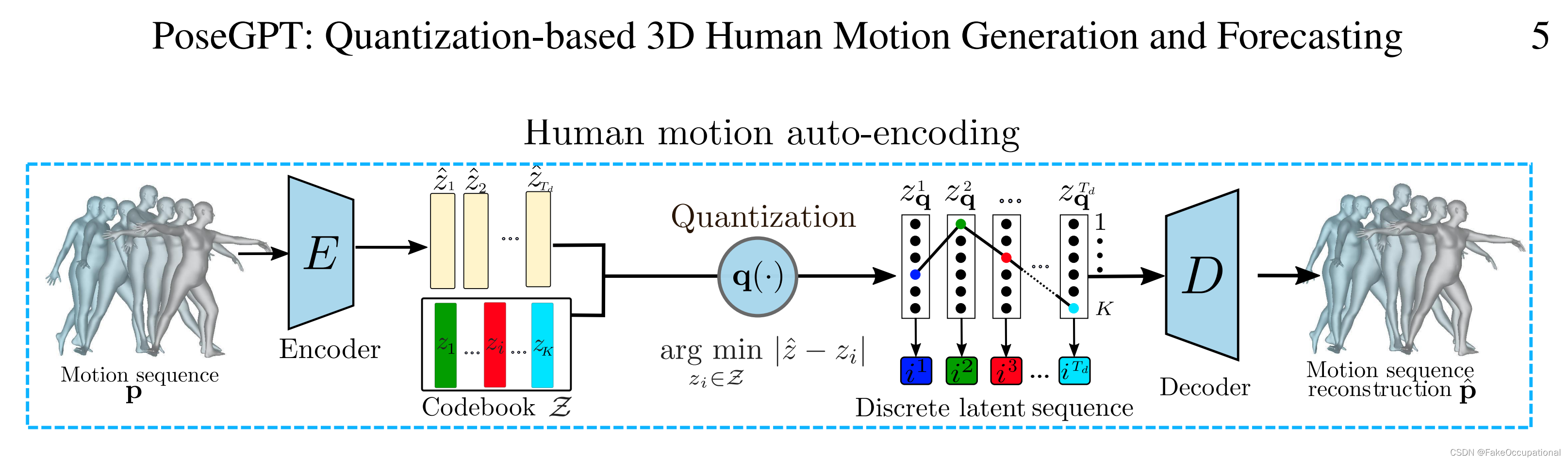
VQVAE
潜在空间的离散性和压缩性使类似 GPT 的模型能够专注于长距离信号,因为它消除了输入信号中的低级冗余。编码器 E 将人体运动 p 映射到潜在表示
z
^
hat z
z^,然后使用码本
Z
mathcal Z
Z 对其进行量化。解码器 D 从量化的潜在序列
z
q
z_q
zq 重建人体运动
p
^
hat p
p^。
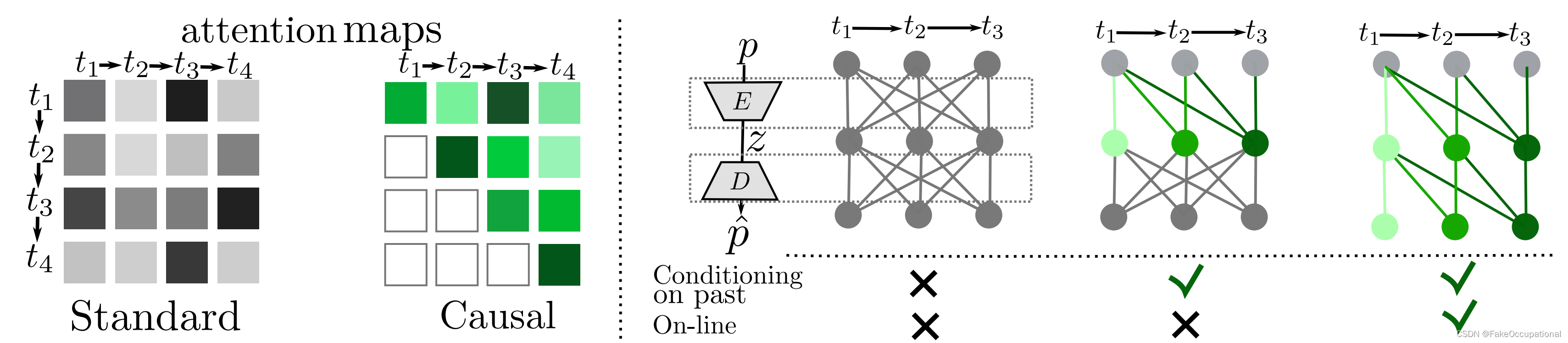
Attention
屏服务器托管网蔽注意力图 :在编码器中屏蔽注意力图会导致模型可以根据过去的观察结果进行调节。在解码器中屏蔽注意力图也允许模型进行在线预测。
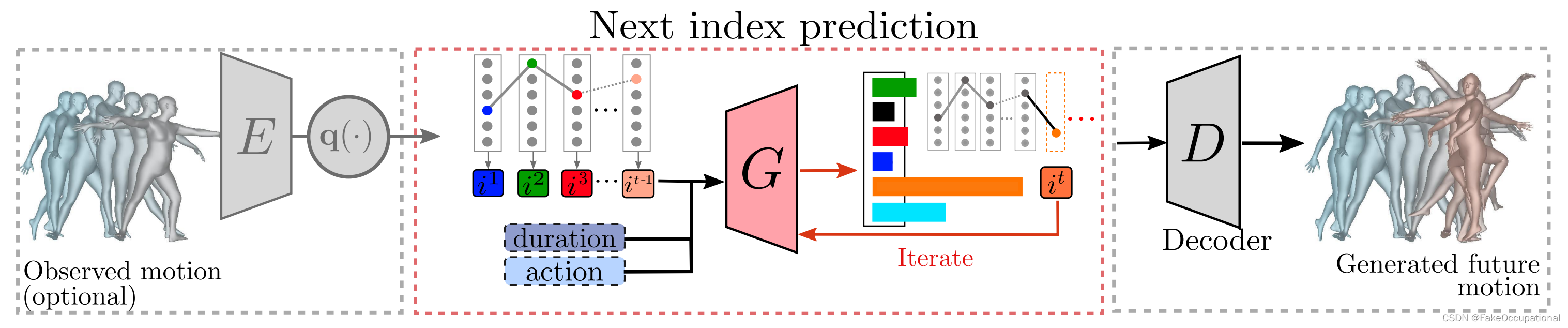
未来运动预测
在离散潜在空间中,自回归转换器模型 G 根据前一个潜在指数预测下一个潜在指数。我们以人体动作标签、序列持续时间和观察到的运动为条件。
结果
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
先说一下自己的情况,本科生生,19年通过校招进入广州某软件服务器托管网公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试,已经让我变得不思进取,谈了2年的女朋友也因为…
