

原创/朱季谦
一、案例说明
以前刚开始学习Spark的时候,在练习排序算子sortBy的时候,曾发现一个有趣的现象是,在使用排序算子sortBy后直接打印的话,发现打印的结果是乱序的,并没有出现完整排序。
例如,有一个包含多个(姓名,金额)结构的List数据,将这些数据按照金额降序排序时,代码及打印效果如下:
val money = ss.sparkContext.parallelize(
List(("Alice", 9973),
("Bob", 6084),
("Charlie", 3160),
("David", 8588),
("Emma", 8241),
("Frank", 117),
("Grace", 5217),
("Hannah", 5811),
("Ivy", 4355),
("Jack", 2106))
)
money.sortBy(x =>x._2, false).foreach(println)
打印结果——
(Ivy,4355)
(Grace,5217)
(Jack,2106)
(Frank,117)
(Emma,8241)
(Alice,9973)
(Charlie,3160)
(Bob,6084)
(Hannah,5811)
(David,8588)
可见,这样的执行结果并没有按照金额进行降序排序。但是,如果使用collect或者重新将分区设置为1以及直接将结果进行save保存时,发现结果都是能够按照金额进行降序排序。(注意一点,服务器托管网按照save保存结果,虽然可能生成很多part-00000 ~part-00005的文件,但从part-00000到part-00005,内部数据其实也按照金额进行了降序排序)。
money.sortBy(x =>x._2, false).collect().foreach(println)
或者
money.repartition(1).sortBy(x =>x._2, false).foreach(println)
或者
money.sortBy(x =>x._2, false).saveAsTextFile("result")
最后结果——
(Alice,9973)
(David,8588)
(Emma,8241)
(Bob,6084)
(Hannah,5811)
(Grace,5217)
(Ivy,4355)
(Charlie,3160)
(Jack,2106)
(Frank,117)
二、sortBy源码分析
为何单独通过sortBy后对数据打印,是乱序的,而在sortBy之后通过collect、save或者重分区为1个分区repartition(1),数据就是有序的呢?
带着这个疑问,去看一下sortBy底层源码——
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
可以看到,核心源码是 this.keyBy[K](f).sortByKey(ascending, numPartitions).values,我会将该源码分成this.keyBy[K](f) , sortByKey(ascending, numPartitions)以及values三部分讲解——
2.1、逐节分析sortBy源码之一:this.keyByK
this.keyBy[K](f)这行代码是基于_.sortBy(x =>x._2, false)传进来的x =>x._2重新生成一个新RDD数据,可以进入到其底层源码看一下——
def keyBy[K](f: T => K): RDD[(K, T)] = withScope {
val cleanedF = sc.clean(f)
map(x => (cleanedF(x), x))
}
若执行的是_.sortBy(x =>x._2, false),那么f: T => K匿名函数就是x =>x._2,因此,keyBy函数的里面代码真面目是这样——
map(x => (sc.clean(x =>x._2), x))
sc.clean(x =>x._2)这个clean相当是对传入的函数做序列化,因为最后会将这个函数得到结果当作排序key分发到不同分区节点做排序,故而涉及到网络传输,因此做序列化后就方便在分布式计算中在不同节点之间传递和执行函数,clean最终底层实现是这行代码SparkEnv.get.closureSerializer.newInstance().serialize(func),感兴趣可以深入研究。
keyBy最终会生成一个新的RDD,至于这个结构是怎样的,通过原先的测试数据调用keyBy打印一下就一目了然——
val money = ss.sparkContext.parallelize(
List(("Alice", 9973),
("Bob", 6084),
("Charlie", 3160),
("David", 8588),
("Emma", 8241),
("Frank", 117),
("Grace", 5217),
("Hannah", 5811),
("Ivy", 4355),
("Jack", 2106))
)
money.keyBy(x =>x._2).foreach(println)
打印结果——
(5217,(Grace,5217))
(5811,(Hannah,5811))
(8588,(David,8588))
(8241,(Emma,8241))
(9973,(Alice,9973))
(3160,(Charlie,3160))
(4355,(Ivy,4355))
(2106,(Jack,2106))
(117,(Frank,117))
(6084,(Bob,6084))
由此可知,原先这样(“Alice”, 9973)结构的RDD,通过keyBy源码里的map(x => (sc.clean(x =>x._2), x))代码,最终会生成这样结构的数据(x._2,x)也就是,(9973,(Alice,9973)), 就是重新将需要排序的字段金额当作了新RDD的key。

2.2、逐节分析sortBy源码之二:sortByKey
通过 this.keyBy[K](f)得到结构为(x._2,x)的RDD后,可以看到,虽然我们前面调用money.sortBy(x =>x._2, false)来排序,但底层本质还是调服务器托管网用了另一个排序算子sortByKey,它有两个参数,一个是布尔值的ascending,true表示按升序排序,false表示按降序排序,我们这里传进来的是false。另一个参数numPartitions,表示分区数,可以通过定义的rdd.partitions.size知道所在环境分区数。
进入到sortByKey源码里,通过以下函数注释,就可以知道sortByKey函数都做了什么事情——
/**
* Sort the RDD by key, so that each partition contains a sorted range of the elements. Calling
* `collect` or `save` on the resulting RDD will return or output an ordered list of records
* (in the `save` case, they will be written to multiple `part-X` files in the filesystem, in
* order of the keys).
*
*按键对RDD进行排序,以便每个分区包含一个已排序的元素范围。
在结果RDD上调用collect或save将返回或输出一个有序的记录列表
(在save情况下,它们将按照键的顺序写入文件系统中的多个part-X文件)。
*/
// TODO: this currently doesn't work on P other than Tuple2!
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
到这里,基于注解就可以知道sortByKey做了什么事情了——
第一步,每个分区按键对RDD进行shuffle洗牌后将相同Key划分到同一个分区,进行排序。
第二步,在调用collect或save后,会对各个已经排序好的各个分区进行合并,最终得到一个完整的排序结果。
这就意味着,若没有调用collect或save将各个分区结果进行汇总返回给master驱动进程话,虽然分区内的数据是排序的,但分区间就不一定是有序的。这时若直接foreach打印,因为打印是并行执行的,即使分区内有序,但并行一块打印就乱七八糟了。
可以写段代码验证一下,各个分区内是不是有序的——
money.sortBy(x => x._2, false).foreachPartition(x => {
val partitionId = TaskContext.get.partitionId
//val index = UUID.randomUUID()
x.foreach(x => {
println("分区号" + partitionId + ": " + x)
})
})
打印结果——
分区号2: (Ivy,4355)
分区号2: (Charlie,3160)
分区号2: (Jack,2106)
分区号2: (Frank,117)
分区号1: (Bob,6084)
分区号1: (Hannah,5811)
分区号1: (Grace,5217)
分区号0: (Alice,9973)
分区号0: (David,8588)
分区号0: (Emma,8241)
设置环境为3个分区,可见每个分区里的数据已经是降序排序了。
若是只有一个分区的话,该分区里的数据也会变成降序排序,这就是为何money.repartition(1).sortBy(x =>x._2, false).foreach(println)得到的数据也是排序结果。
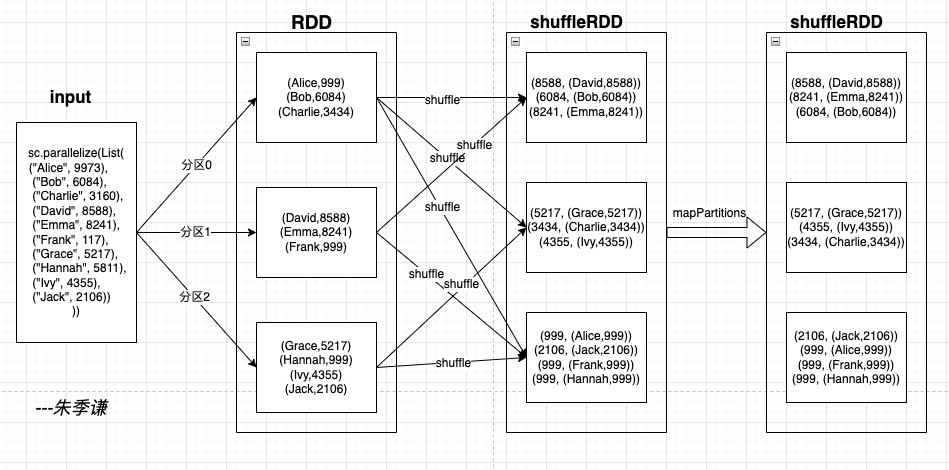
sortBy主要流程如下,假设运行环境有3个分区,读取的数据去创建一个RDD的时候,会按照默认Hash分区器将数据分到3个分区里。
在调用sortBy后,RDD会通过 this.keyBy[K](f)重新生成一个新的RDD,例如结构如(8588, (David,8588)),接着进行shuffle操作,把RDD数据洗牌打散,将相应范围的key重新分到同一个分区里,意味着,同key值的数据就会分发到了同一个分区,例如下图的(2106, (Jack,2106)),(999, (Alice,999)),(999, (Frank,999)),(999, (Hannah,999))含同一个Key都在一起了。
shuffleRDD中,使用mapPartitions会对每个分区的数据按照key进行相应的升序或者降序排序,得到分区内有序的结果集。
2.3、逐节分析sortBy源码之三:.values
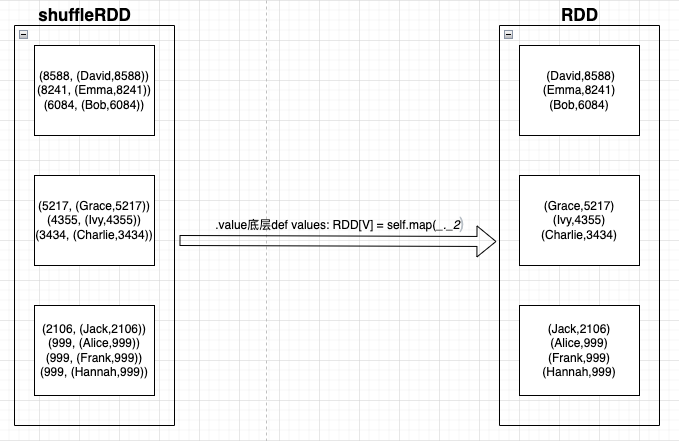
sortBy底层源码里 this.keyBy[K](f).sortByKey(ascending, numPartitions).values,在sortByKey之后,最后调用了.values。源码.values里面是def values: RDD[V] = self.map(_._2),就意味着,排序完成后,只返回x._2的数据,用于排序生成的RDD。类似排序过程中RDD是(5217,(Grace,5217))这样结构,排序后,若只返回x._2,就只返回(Grace,5217)这样结构的RDD即可。
可以看到,shuffleRDD将相应范围的key重新分到同一个分区里,例如,0~100划到分区0,101~200划分到分区1,201~300划分到分区2,这样还有一个好处——当0,1,2分区内部的数据已经有序时,这时从整体按照0,1,2分区全局来看,其实就已经是全局有序了,当然,若要实现全局有序,还需要将其合并返回给驱动程序。
三、合并各个分区的排序,返回全局排序
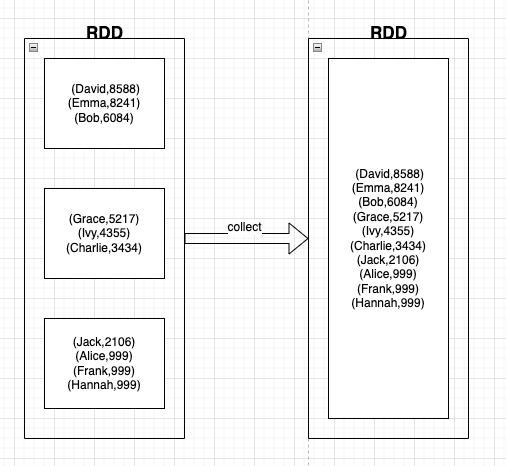
调用collect或save就是把各个分区结果进行汇总,相当做了一个归并排序操作——
以上,就是关于sortBy核心源码的讲解。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
核技巧使用核函数直接计算两个向量映射到高维后的内积,从而避免了高维映射这一步。本文用矩阵的概念介绍核函数$K(x,y)$的充分必要条件:对称(半)正定。 对称正定看起来像是矩阵的条件。实际上,对于函数$K(x,y):R^ntimes R^mrighta…
