
目录
- 症状数据
- 创建节点
- 附学习
电子病历中,患者主诉对应的相关检查,得出的诊断以及最后的用药情况。症状一般可以从主诉中提取。
症状数据
symptom_data.csv
CSV 中,没有直接一行一个症状,主要想后面将 症状 => 疾病 做关联,最后会在一个 Excel 中表达
所以每行实际对应一个症病,但在创建节点时,会转化成 N个节点(每个 | 号一个节点)
症状
"上下楼梯疼,不能久站,感觉有点肿"
"眼睛胀痛,干涩,畏光,眼胀,眼痛,看东西有时候清楚有时候不清楚"
创建节点
参考 创建药品 节点。
import logging
impo服务器托管网rt csv
fr服务器托管网om utils.neo4j_provider import driver
import pandas as pd
logging.root.setLevel(logging.INFO)
# 并生成 CQL
def generate_cql() -> str:
# cql = """
# CREATE (symptom1:Symptom {name: "膝盖疼"}),
# (symptom2:Symptom {name: "眼睛酸胀"})
# """
df = pd.read_csv('symptom_data.csv')
symptoms = []
for each in df['症状']:
symptoms.extend(each.split(',')) # 按,号分割成数组,并将每行数据到一个队列里面
symptoms = set(symptoms) # 去除重复项
# 拼接 CQL
cql = ""
for idx, item in enumerate(symptoms):
cql += """(symptom%s:Symptom {name: "%s"}),rn"""
% (idx, item)
return "CREATE %s" % (cql.rstrip(",rn")) # 删除最后一个节点的 逗号
# 执行写的命令
def execute_write(cql):
with driver.session() as session:
session.execute_write(execute_cql, cql)
driver.close()
# 执行 CQL 语句
def execute_cql(tx, cql):
tx.run(cql)
# 清除 Symptom 标签数据
def clear_data():
cql = "MATCH (n:Symptom) DETACH DELETE n"
execute_write(cql)
if __name__ == "__main__":
clear_data()
cql = generate_cql()
print(cql)
execute_write(cql)
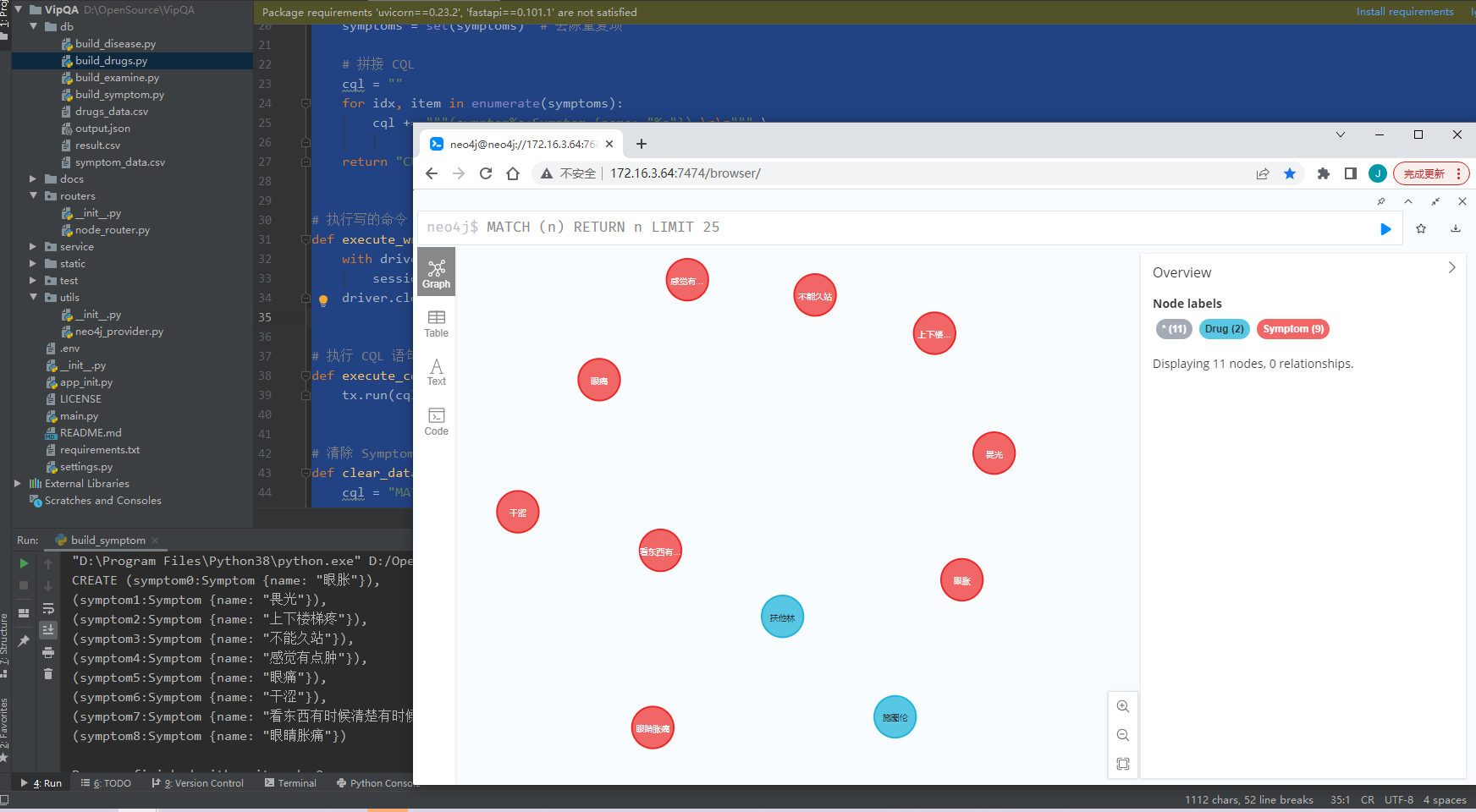
附学习
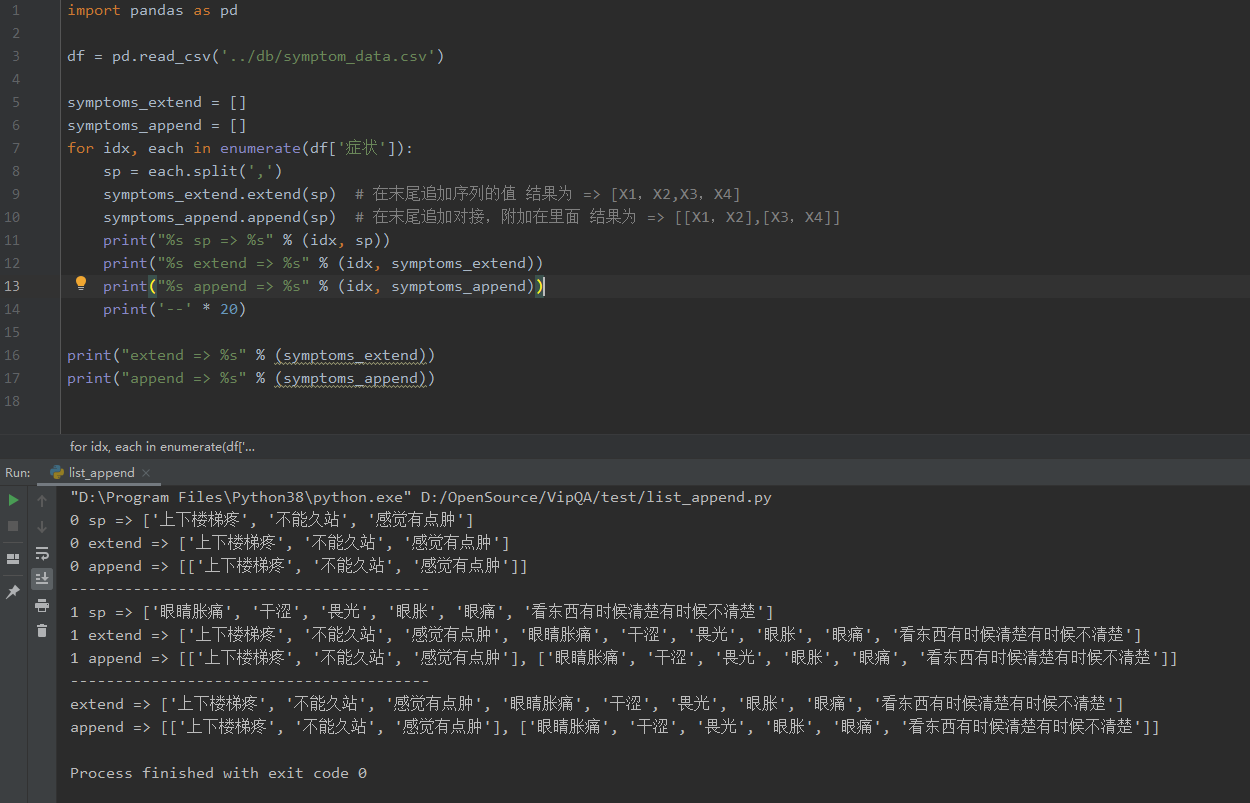
数组 append、extend 区别
import pandas as pd
df = pd.read_csv('../db/symptom_data.csv')
symptoms_extend = []
symptoms_append = []
for idx, each in enumerate(df['症状']):
sp = each.split(',')
symptoms_extend.extend(sp) # 在末尾追加序列的值 结果为 => [X1,X2,X3,X4]
symptoms_append.append(sp) # 在末尾追加对接,附加在里面 结果为 => [[X1,X2],[X3,X4]]
print("%s sp => %s" % (idx, sp))
print("%s extend => %s" % (idx, symptoms_extend))
print("%s append => %s" % (idx, symptoms_append))
print('--' * 20)
print("extend => %s" % (symptoms_extend))
print("append => %s" % (symptoms_append))
源代码地址:https://gitee.com/VipSoft/VipQA
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
by emanjusaka from https://www.emanjusaka.top/archives/4 彼岸花开可奈何 本文欢迎分享与聚合,全文转载请留下原文地址。 前言 Reactor 是一个响应式编程的基础类库,其中有两个很关键的类:Flux…
