

原创/朱季谦
在Java编程当中,Iterator迭代器是一种用于遍历如List、Set、Map等集合的工具。这类集合部分存在线程安全的问题,例如ArrayList,若在多线程环境下,迭代遍历过程中存在其他线程对这类集合进行修改的话,就可能导致不一致或者修改异常问题,因此,针对这种情况,迭代器提供了两种处理策略:Fail-Fast(快速失败)和Fail-Safe(安全失败)。
先简单介绍下这两种策略——
1. Fail-Fast(快速失败)机制
快速失败机制是指集合在迭代遍历过程中,其他多线程或者当前线程对该集合进行增加或者删除元素等操作,当前线程迭代器读取集合时会立马抛出一个ConcurrentModificationException异常,避免数据不一致。实现原理是迭代器在创建时,会获取集合的计数变量当作一个标记,迭代过程中,若发现该标记大小与计数变量不一致了,就以为集合做了新增或者删除等操作,就会抛出快速失败的异常。在ArrayList默认启用该机制。
2. Fail-Safe(安全失败)机制
安全失败机制是指集合在迭代遍历过程中,若其他多线程或者当前线程对该集合进行修改(增加、删除等元素)操作,当前线程迭代器仍然可以正常继续读取集合遍历,而不会抛出异常。该机制的实现,是通过迭代器在创建时,对集合进行了快照操作,即迭代器遍历的是原集合的数组快照副本,若在这个过程,集合进行修改操作,会将原有的数组内容复制到新数组上,并在新数组上进行修改,修改完成后,再将集合数组的引用指向新数组,,而读取操作仍然是访问旧的快照副本,故而实现读写分离,保证读取操作的线程安全性。在CopyOnWriteArrayList默认启用该机制。
基于这两个策略,分别写一个案例来说明。
一、迭代器的Fail-Fast(快速失败)机制原理
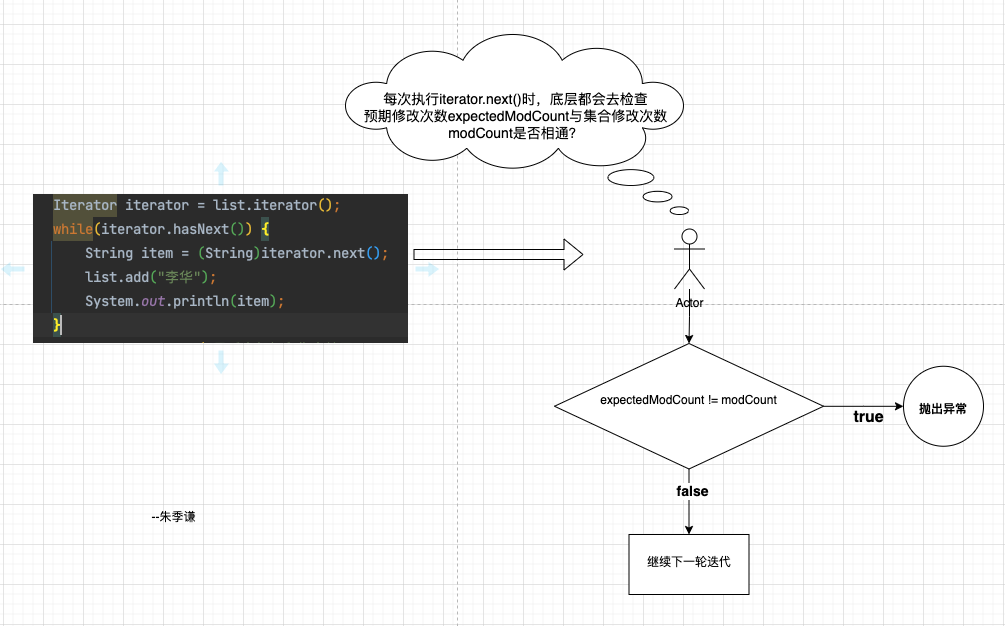
Fail-Fast(快速失败)机制案例,用集合ArrayList来说明,这里用一个线程就能模拟出该机制——
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
Iterator iterator = list.iterator();
while(iterator.hasNext()) {
//第一次遍历到这里,能正常打印,第二次遍历到这里,因上一次遍历做了list.add("李华")操作,集合已经改变,故而出现Fail-Fast(快速失败)异常
String item = (String)iterator.next();
list.add("李华");
System.out.println(item);
}
System.out.println(list);
}
执行这段代码,打印日志出现异常ConcurrentModificationException,说明在遍历过程当中,操作 list.add(“李华”)对集合做新增操作后,就会出现Fail-Fast(快速失败)机制,抛出异常,阻止继续进行遍历——
张三
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:911)
at java.util.ArrayList$Itr.next(ArrayList.java:861)
at ListExample.IteratorTest.main(IteratorTest.java:23)
这里面是怎么实现该Fail-Fast(快速失败)机制的呢?
先来看案例里创建迭代器的这行代码Iterator iterator = list.iterator(),底层是这样的——
public Iterator iterator() {
return new Itr();
}
Itr类是ArrayList内部类,实现了Iterator 接口,说明它本质是ArrayList内部一个迭代器。这里省略部分暂时无关紧要的代码,只需关注hasNext()和next()即可——
private class Itr implements Iterator {
int cursor; // 迭代计数器
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
//判断是否已经迭代到最后一位
public boolean hasNext() {
return cursor != size;
}
//取出当前遍历到集合元素
public E next() {
//判断集合是否有做新增或者删除操作
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
......
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
再进入案例里的这行代码 String item = (String)iterator.next()底层,也就是Itr类的public E next() {……}方法。
注意next()里的这个方法 checkForComodification(),进入到方法里,可以看到,ConcurrentModificationException异常正是在这个方法里抛出来的,它做了一个判断,判断modCount是否等于expectedModCount,若不等于,就抛出快速失败异常。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
那么,问题就简单了,研究ArrayList快速失败机制,本质只需要看modCount和expectedModCount是什么,就知道ArrayList的Fail-Fast(快速失败)机制是怎么处理的了。
在内部类Itr中,定义int expectedModCount = modCount,说明expectedModCount是在迭代器new Itr()创建时,就将此时的modCount数值赋值给变量expectedModCount,意味着,在整个迭代器生命周期内,这个expectedModCount是固定的了,从变量名就可以看出,它表示集合预期修改的次数,而modCount应该就是表示列表修改次数。假如迭代器创建时,modCount修改次数是5,那么整个迭代器生命周期内,预期的修改次数expectedModCount就只能等于5。
请注意最为关键的一个地方,modCount是可以变的。
先看一下在ArrayList里,这个modCount是什么?
这个modCount是定义在ArrayList的父类AbstractList里的——
/**
*这个列表在结构上被修改的次数。结构修改是指改变列表,或者以其他方式扰乱它,使其迭代进步可能产生不正确的结果。
*
*该字段由迭代器和列表迭代器实现使用,由{@code迭代器}和{@code listtiterator}方法返回。
*如果该字段的值发生了意外变化,迭代器(或列表)将返回该字段迭代器)将抛出{@code ConcurrentModificationException}
*在响应{@服务器托管网code next}, {@code remove}, {@code previous},{@code set}或{@code add}操作。这提供了快速故障行为。
*
*/
protected transient int modCount = 0;
根据注释,可以得知,这是一个专门记录列表被修改的次数,在ArrayList当中,涉及到add新增、remove删除、fastRemove、clear等涉及列表结构改动的操作,,都会通过modCount++形式,增加列表在结构上被修改的次数。
modCount表示列表被修改的次数。
我们在案例代码里,做了add操作——
while(iterator.hasNext()) {
String item = (String)iterator.next();
list.add("李华");
System.out.println(item);
}
进入到ArrayList的add方法源码里,可以看到,在add新增过程中,按照ensureCapacityInternal =》ensureExplicitCapacity执行顺序,最后通过modCount++修改了变量modCount——
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
总结一下,迭代器创建时,变量expectedModCount是被modCount赋值,在整个迭代器等生命周期中,变量expectedModCount值是固定的了,但在第一轮遍历过程中,通过list.add(“李华”)操作,导致modCount++,最终就会出现expectedModCount != modCount。因此,在迭代器进行第二轮遍历时,执行到 String item = (String)iterator.next(),在next()里调用checkForComodification() 判断expectedModCount是否还等于modCount,这时已经不等于,故而就会抛出ConcurrentModificationException异常,立刻结束迭代器遍历,避免数据不一致。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
以上,就是集合迭代器的Fail-Fast机制原理。
二、迭代器的Fail-Safe(安全失败)机制原理
Fail-Fast(快速失败)机制案例,用集合CopyOnWriteArrayList来说明,这里用一个线程就能模拟出该机制——
public static void main(String[] args) {
CopyOnWriteArrayList list = new CopyOnWriteArrayList();
list.add("张三");
list.add("李四");
list.add("王五");
Iterator iterator = list.iterator();
while(iterator.hasNext()) {
String item = (String)iterator.next();
list.add("李华");
System.out.println(item);
}
System.out.println("最后全部打印集合结果:" + list);
}
执行这段代码,正常打印结果,说明在迭代器遍历过程中,对集合做了新增元素操作,并不影响迭代器遍历,新增的元素不会出现在迭代器遍历当中,但是,在迭代器遍历完成后,再一次打印集合,可以看到新增的元素已经在集合里了——
张三
李四
王五
最后全部打印集合结果:[张三, 李四, 王五, 李华, 李华, 李华]
Fail-Safe(安全失败)机制在CopyOnWriteArrayList体现,可以理解成,这是一种读写分离的机制。
下面就看一下CopyOnWriteArrayList是如何实现读写分离的。
先来看迭代器的创建Iterator iterator = list.iterator(),进入到list.iterator()底层源码——
public Iterator iterator() {
return new COWIterator(getArray(), 0);
}
这里的COWIterator是一个迭代器,关键有一个地方,在创建迭代器对象,调用其构造器时传入两个参数,分别是getArray()和0。
这里的getArray()方法,获取到一个array数组,它是CopyOnWriteArrayList集合真正存储数据的地方。
final Object[] getArray() {
return array;
}
另一个参数0,表示迭代器遍历的索引值,刚开始,肯定是从数组下标0开始。
明白getArray()和0这两个参数后,看一下迭代器创建new COWIterator(getArray(), 0)的情况,只需关注与本文有关的代码即可,其他暂时省略——
static final class COWIterator implements ListIterator {
//列表快照
private final Object[] snapshot;
//调用next返回的元素的索引
private int cursor;
服务器托管网 private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor 在代码案例中,迭代器遍历过程时,通过hasNext()判断集合是否遍历完成,若还有没遍历的元素,就会调用 String item = (String)iterator.next()取出集合对应索引的元素。
从COWIterator类的next()方法中,可以看到,其元素是根据索引cursor从数组snapshot中取出来的。
这个snapshot就相当一个快照副本,在创建迭代器时,即new COWIterator(getArray(), 0),通过getArray()将此时CopyOnWriteArrayList集合的array数组引用复制给COWIterator的数组snapshot,那么snapshot引用和array引用都将指向同一个数组地址了。
只需保证snapshot指向的数组地址元素不变,那么整个迭代器读取集合数组就不会受影响。
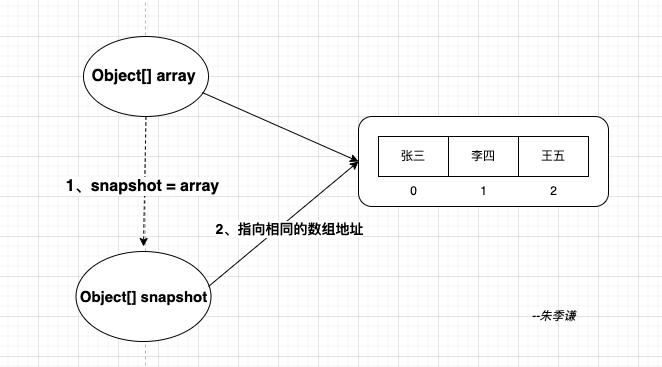
如何做到snapshot指向的数组地址元素不变,但是又需要同时能满足CopyOnWriteArrayList集合的新增或者删除操作呢?
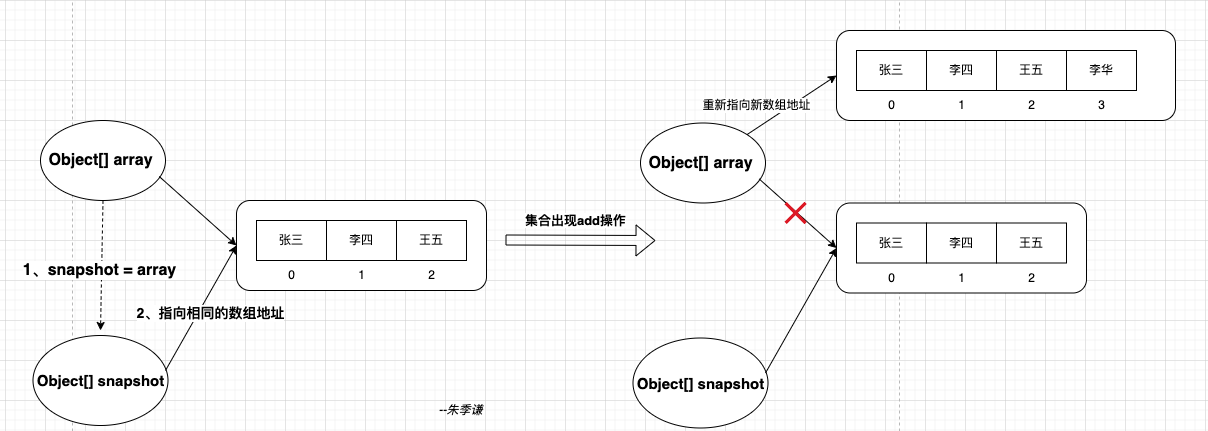
先来看一下CopyOnWriteArrayList的 list.add(“李华”)操作,具体实现能够在这块源码里看到,主要以下步骤:
1、add方法用到了ReentrantLock锁,在进行新增过程中,通过lock锁保证线程安全。
2、Object[] elements = getArray()这里的getArray()方法,和创建迭代器传的参数getArray()是同一个,都是获取到CopyOnWriteArrayList的array数组。取出array数组以及计算其长度后,创建一个比array数组长度大1的新数组,通过Arrays.copyOf(elements, len + 1)将array数组元素全部复制到新数组newElements。
3、在新数组newElements进行新增元素操作。
4、将CopyOnWriteArrayList的array数组引用指向新数组newElements,这样array=newElements,完成新增操作。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//获取到CopyOnWriteArrayList的array数组
Object[] elements = getArray();
//获取array数组长度
int len = elements.length;
//将array数组数据,全部复制到一个长度比旧数组多1的新数组里
Object[] newElements = Arrays.copyOf(elements, len + 1);
//在新数组里,新增一个元素
newElements[len] = e;
//将CopyOnWriteArrayList的array数组引用指向新数组newElements
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
可见,CopyOnWriteArrayList实现读写分离的原理,就是在COWIterator迭代器创建时,将此时的array数组指向的地址复制给snapshot,相当做了一次快照,迭代器遍历该快照数组地址元素。
后续涉及到列表修改相关的操作,会将原始array数组全部元素复制到一个新数组上,在新数组里面进行修改操作,这样就不会影响到迭代器遍历原来的数组地址里的数据了。(这也表明,这种读写分离只适合读多写少,在写多情况下,会出现性能问题)
新数组修改完毕后,只需将array数组引用指向新数组地址,就能完成修改操作了。
整个过程就能完成读写分离机制,即迭代器的Fail-Safe(安全失败)机制。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
自stable diffusion开源之后AIGC绘画方向定制化百花齐放百家争鸣。而c站 https://civitai.com/ 也聚集了全球爱好者的各种微调训练模型分享。 其中以lora为首,应用最广泛。 而这些模型是怎么训练出来的,细节到底是什么样的,没…
