
2023年12月6日李天鸿、卡塔比、何开明编辑社交预览
本文提出了表示条件图像生成(RCG),这是一种简单而有效的图像生成框架,为类无条件图像生成提供了新的基准。RCG不以任何人工注释为条件。相反,它以自监督表示分布为条件,该分布使用预训练的编码器从图像分布映射而来。在生成期间,RCG使用表示扩散模型(RDM)从这种表示分布中进行采样,并使用像素生成器来处理以采样的表示为条件的图像像素。这样的设计在生成过程中提供了实质性的指导,从而产生高质量的图像生成。在图像网络256256上测试,RCG的Frechet起始距离(FID)为3.31,起始得分(IS)为253.4。这些结果不仅显著提高了类无条件图像生成的技术水平,而且可以与当前类条件图像生成中的领先方法相媲美,弥补了这两项任务之间长期存在的性能差距。代码位于https://github.com/lth14/rcg.
通过生成表示来进行的自助图像生成天宏Li1 Dina Katabi1开明氦二聚体1MIT CSAIL 2FAIR,Meta
摘要本文提出了表示条件图像生成(RCG),一种简单而有效的图像生成框架,为类无条件图像生成设置了一个新的基准。RCG不需要提供任何人工注释。相反,它的条件是一个自监督的表示分布,这是映射从图像分布使用一个预先训练的编码器。在生成过程中,使用表示扩散模型(RDM)从这种表示分布中提取RCG样本,并使用像素生成器来制作基于采样表示条件的图像像素。这种设计在生成过程中提供了实质性的指导,从而产生高质量的图像生成。在ImageNet256256上测试,RCG获得了弗雷切特初始距离(FID)为3.31,初始分数(IS)为253.4。这些结果不仅显著提高了类无条件图像生成的技术水平,而且可以与目前类条件图像生成的领先方法相媲美,弥合了这两个任务之间长期存在的性能差距。代码可在https://github.com/LTH14/rcg上找到。 1.I1.条件图像生成的最新进展已经取得了令人印象深刻的结果,利用人工注释,如类标签或文本描述来指导生成过程[11,12,18,22,47,52]。相比之下,忽略这些条件元素的无条件图像生成在历史上一直是一项更具挑战性的任务,往往产生不那么令人印象深刻的结果[3,18,19,39,43]。这种二分法反映了有监督学习和无监督学习之间的情况。从历史上看,无监督学习在性能上落后于有监督的学习。随着自监督学习(SSL)的出现,这种差距已经缩小。SSL从数据本身产生监督信号,与监督学习相比,获得了具有竞争力或更优越的结果[9,13,25-27]。利用这个类比,我们将自条件图像生成问题作为图像生成领域中自监督学习的对应问题。这种方法不同于传统的无条件图像生成,它将像素生成过程限制在来自数据分布的表示分布上
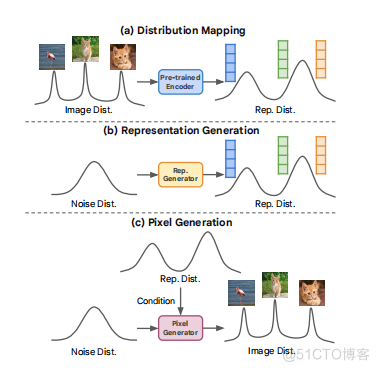
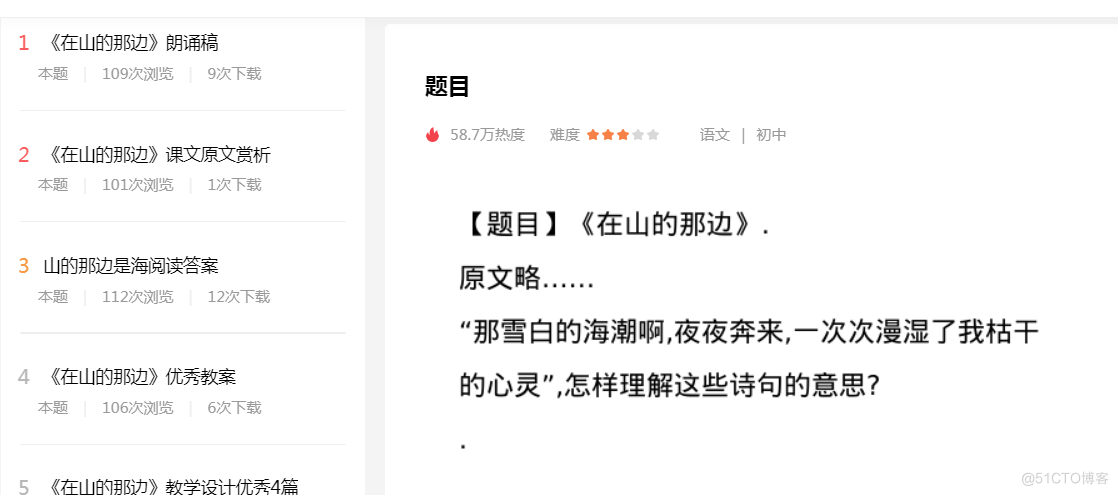
图1.自调节的图像生成框架。与传统的无条件图像生成方法简单地将噪声分布映射到图像分布不同,自条件图像生成由三部分组成: (a)它使用图像编码器(如Moco v3)将原始图像分布映射到低维表示分布;(b)它学习表示生成器将噪声分布映射到表示分布;(c)它学习像素生成器(如LDM [52]或MAGE [39])将噪声分布映射到基于表示分布的图像分布。它本身,如图1c所示。自条件的图像生成很重要,有几个原因。首先,对表示的自我调节是一种更直观的无条件图像生成方法,反映了艺术家在将抽象概念翻译到画布上之前将其概念化的过程。其次,与自监督学习如何超越监督学习类似,利用大量的未标记数据集的自条件图像生成有可能超过cond的性能
从一个图像表示分布中进行精确的建模和采样(图1b)。这种图像表示还应保留足够的信息来指导像素生成过程。为了实现这一点,我们开发了一个表示扩散模型(RDM)来生成低维的自监督图像表示。这个分布是使用一个自监督的图像编码器从图像分布中映射出来的(图1a)。我们的方法有两个显著的好处。首先,RDM可以捕获表示空间的底层分布的多样性,使其能够生成各种表示,以促进图像的生成。其次,这种自监督的表示空间既是结构化的,又是低维的,这简化了一个简单的神经网络结构的表示生成任务。因此,与像素生成过程相比,生成表示的计算开销最小的。利用RDM,我们提出了表示条件图像生成(RCG),这是一个简单而有效的自条件图像生成框架。RCG由
RCG展示了出色的图像生成能力。在ImageNet256256上进行评估,RCG实现了FID为3.56,初始分数为186.9,显著优于之前所有的类无条件生成方法(最先进的结果是7.04 FID和123.5初始分数[39])。在无分类器的指导下,这些结果可以进一步提高到3.31分FID和253.4分。值得注意的是,我们的结果可以与现有的类条件生成基准测试相媲美,甚至超过它们。这些结果强调了自我调节图像生成的巨大潜力,可能预示着这一领域的一个新时代。 2.相关的工作,自我监督的学习。在相当长的一段时间里,在各种计算机视觉任务[8,28,29,64]中,监督学习主要优于无监督学习。然而,自我监督学习的出现已经极大地缩小了这一表现差距。自我监督学习的最初努力主要集中在创建借口任务和训练网络来预测相关的伪标签[23,44,46]。生成模型也显示了异常
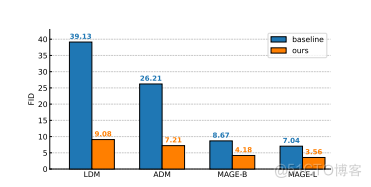
图2.使用不同像素生成器在ImageNet256256上的类无条件图像生成性能。我们的方法提高了类无条件的生成质量,无论选择像素生成器基线。tic编码器。这种语义编码器与扩散模型一起从头开始训练,使DiffAE能够学习一个有意义的和可解码的图像表示,从而促进图像操作。最近,对比学习[14,15,38,45]已被证明是一种稳健的和系统的方法来学习有效的表示,取得的结果几乎与那些监督学习相同。研究人员还发现,掩蔽图像建模(MIM)在自监督学习[4,26,35,39,48]中是非常有效的。自我监督学习的进步促使我们服务器托管网探索自我条件图像生成的概念。我们提出的框架,RCG,利用尖端的自监督学习方法,将图像分布映射到一个紧凑的表示分布。图像生成。近年来,深层生成模式取得了巨大的进展
最近,对比学习[14,15,38,45]已被证明是一种稳健的和系统的方法来学习有效的表示,取得的结果几乎与那些监督学习相同。研究人员还发现,掩蔽图像建模(MIM)在自监督学习[4,26,35,39,48]中是非常有效的。自我监督学习的进步促使我们探索自我条件图像生成的概念。我们提出的框架,RCG,利用尖端的自监督学习方法,将图像分布映射到一个紧凑的表示分布。图像生成。近年来,图像合成的深度生成模型取得了巨大的进展。生成模型的一个主要流是建立在生成对抗网络(GANs)[7,24,36,62,63]之上的。另一种流是基于两阶段方案[11,12,37,39,51,60,61]:首先将图像标记化为一个潜在空间,然后在潜在空间中应用最大似然估计和采样。近年来,扩散模型[18,31,50,52,56]在图像合成方面也取得了优越的效果。一个相关的工作,DALLE 2 [50]
生成基于CLIP文本嵌入和图像标题的CLIP图像嵌入,并生成基于生成的图像嵌入的图像,在文本到图像生成方面表现出优越的性能。尽管它们的性能令人印象深刻,但在条件和无条件生成能力[3,18,19,39,43]之间存在着显著的差距。之前的努力是将这个间隙组图像缩小为表示空间中的簇,并使用这些簇作为自我调节或自我引导[3,34,40]的底层类标签。然而,这隐式地假设,本应该是未标记的数据集是一个分类数据集,并且最优的集群数量接近于类的数量。此外,这些方法还不能产生不同的抑制剂-
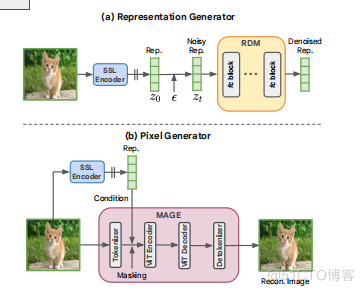
图3. RCG培训框架。预先训练好的SSL图像编码器从图像中提取表示形式,并在训练过程中进行固定处理。为了训练RDM,我们在表示法中加入标准高斯噪声,并要求网络对其进行去噪。为了训练MAGE像素生成器,我们在标记化的图像中添加随机掩蔽,并要求网络根据从同一图像中提取的表示来重建缺失的标记。它们不能在同一集群或相同的底层类中产生不同的表示。另外两个相关的作品是RCDM [5]和IC-GAN [10],其中的图像是基于从现有图像中提取的表示来生成的。尽管如此,这些方法依赖于地面真实图像在生成过程中提供表示,这在许多生成应用程序中是不切实际的。RCG的条件作用不同于之前所有的作品。与之前的自条件反射方法不同,RCG产生了一组离散的预计算聚类作为条件反射,RCG学习了一个表示扩散模型来建模表示空间的底层分布,并生成以th为条件的图像
RCG的条件作用不同于之前所有的作品。与之前的自条件方法不同,RCG产生了一组离散的预计算簇作为条件,RCG学习了一个表示扩散模型来建模表示空间的底层分布,并生成基于这个表示分布条件的图像。这种SSL表示的生成是通过一个简单而有效的表示扩散模型来实现的。据我们所知,这是生成低维SSL表示并将其作为图像生成的条件反射的第一个探索和解决方案。这种从这种表示分布中建模和采样的能力允许像素生成过程以对图像的全面理解为指导,而不需要人工注释。因此,这导致了在无条件图像生成方面比以前的方法有显著更好的性能。 3.方法RCG包括三个关键组件:预先训练的自监督图像编码器、表示生成器和
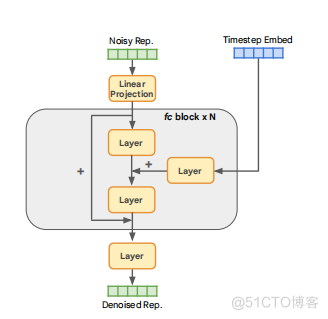
图4.RDM的主干架构。每个“层”由一个层规范层[1]、一个SiLU层[21]和一个线性层组成。主干包括一个将表示投射到隐藏维度的输入层,然后是全连接(fc)块,以及一个将隐藏的潜在维度投射到原始表示维度的输出层。一个像素生成器。每个组件的设计都被详细阐述如下:图像编码器。RCG使用了一个预先训练好的图像编码器来将图像分布传输到一个表示分布。这种分布具有两个基本特性:通过表示扩散模型进行建模的简单性,以及用于指导像素生成的高级语义内容的丰富性。我们使用使用自监督对比学习方法(Moco v3 [16])预训练的图像编码器,该方法在超球上规范表示,同时在ImageNet上实现最先进的表示学习性能。我们取投影头(256-暗淡)之后的表示,每个表示都用它自己的平均值和标准差进行归一化。
表示生成器。RCG使用一个简单而有效的表示扩散模型(RDM)从表示空间中进行采样。RDM采用了一个以多个残差块为骨干的全连接网络,如图4所示。每个块由一个输入层、一个时间步长嵌入投影层和一个输出层组成,其中每个层由一个LayerNorm [1]、一个SiLU [21]和一个线性层组成。这种体系结构由两个参数控制:残差块的数量和隐藏维数. RDM遵循去噪扩散隐式模型(DDIM)[55]进行训练和推理。如图3a所示,在训练过程中,图像表示0与标准高斯噪声变量:=√0+√1−混合。然后训练RDM主干,使去噪回0。在推理过程中,RDM根据DDIM采样过程[55]从高斯噪声中生成表示。
由于RDM在高度压缩的表示上进行操作,因此它为训练和生成带来了边际计算开销(表7)。像素生成器。RCG中的像素生成器制作了基于图像表示的图像像素。从概念上讲,这样的像素生成器可以是任何现代的条件图像生成模型,通过用SSL表示替换其原始的条件反射(如类标签或文本)。在图3b中,我们以并行解码生成模型MAGE [39]为例。像素生成器被训练从一个掩蔽版本的图像,以表示相同的图像重建原始图像。在推理过程中,像素生成器从完全掩蔽的图像生成图像,根据表示生成器生成表示。我们实验了三种具有代表性的生成模型: ADM [18]和LDM [52],它们都是基于扩散的框架,以及MAGE [39],一个并行解码框架。我们的实验表明,在高级表示的条件下,所有三种生成模型都获得了更好的性能(图2和表6b)。无分类器的G
这两者都是基于扩散的框架,以及并行解码框架MAGE [39],一个并行解码框架。我们的实验表明,在高级表示的条件下,所有三种生成模型都获得了更好的性能(图2和表6b)。无分类器的指导。RCG的一个优点是,它无缝地促进了对无条件生成任务的无分类器指导。以提高生成模型性能而闻名,传统上不适用于无条件生成框架[33,39]。这是因为无分类器的指导被设计成为通过无条件生成的条件图像的生成提供指导。虽然RCG也是为无条件生成任务设计的,但RCG的像素生成器是基于自监督表示的,因此可以无缝集成无分类器指导,进一步提高其生成性能。RCG遵循Muse [11],在其MAGE像素生成器中实现了无分类器的指导。在训练过程中,MAGE像素生成器的训练不需要10%概率的SSL表示RCG遵循Muse [11],在其MAGE像素生成器中实现无分类器引导。在训练过程中,MAGE像素生成器的训练不需要10%概率的SSL表示。在每个推理步骤中,MAGE预测一个基于SSL表示的logit,以及针对每个掩码标记的无条件logit。最终的日志是由离开,通过引导量表:=+(−)形成的。然后,MAGE根据进行取样,以填充剩余的蒙面标记。在附录B中提供了RCG的无分类器指导的其他实现细节。 4.结果第4.1节。我们在ImageNet256256[17]上评估RCG,这是一个用于图像生成的通用基准数据集。我们生成了50K图像,并报告弗雷切特初始距离(FID)[30]和初始评分(IS)[53]作为标准指标,以衡量生成图像的保真度和多样性。
RCG遵循Muse [11],在其MAGE像素生成器中实现无分类器引导。在训练过程中,MAGE像素生成器的训练不需要10%概率的SSL表示。在每个推理步骤中,MAGE预测一个基于SSL表示的logit,以及针对每个掩码标记的无条件logit。最终的日志是由离开,通过引导量表:=+(−)形成的。然后,MAGE根据进行取样,以填充剩余的蒙面标记。在附录B中提供了RCG的无分类器指导的其他实现细节。 4.结果第4.1节。我们在ImageNet256256[17]上评估RCG,这是一个用于图像生成的通用基准数据集。我们生成了50K图像,并报告弗雷切特初始距离(FID)[30]和初始评分(IS)[53]作为标准指标,以衡量生成图像的保真度和多样性。
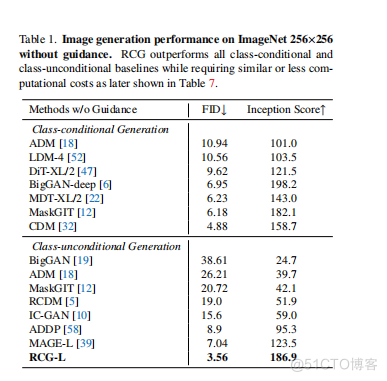
FID将根据ImageNet验证集进行测量。在训练RCG的像素生成器的过程中,图像被调整大小,使较小的一侧的长度为256,然后随机翻转和裁剪到256256。对SSL编码器的输入被进一步调整到224224,以与其位置嵌入大小兼容。对于我们的主要结果,RCG-L使用用Moco v3 [16]预训练的视觉变压器(ViT-L)[20]作为图像编码器,一个有12个块和1536个隐藏维度的网络作为RDM的主干,和MA服务器托管网GE-L [39]作为图像生成器。RDM以恒定的学习速率训练200个时代,MAGE-L以余弦学习速率调度训练800个时代。在附录B中提供了更多的实现细节和超参数。4.2.在表1的类无条件生成中,我们将RCG与ImageNet256256上最先进的生成模型进行了比较。由于传统的类无条件生成既不支持分类器也不支持无分类器指导[18,33],表1中的所有结果都没有这样的指导而报告。如图5和表1所示,RCG可以生成高保真度和多样化的图像,实现
表1中的所有结果都是在没有提供这些指导的情况下报告的。如图5和表1所示,RCG可以生成高保真度和多样性的图像,达到3.56 FID和186.9分,明显优于以往最先进的类无条件图像生成方法。此外,这一结果也优于之前最先进的类条件生成方法(由CDM[32]实现的4.88FID),弥合了类条件生成和类无条件生成之间的历史差距。我们在附录A中进一步表明,我们的表示扩散模型可以毫不费力地实现fa-

图5. RCG在没有无分类器指导的情况下,在ImageNet256256上的无条件图像生成结果。RCG可以生成具有高保真度和多样性的图像,而不需要基于任何人工注释。表2.在ImageNet256256上的图像生成性能。RCG无缝地实现了无条件图像生成的无分类器指导,实现了与最先进的类条件生成模型相同的结果。
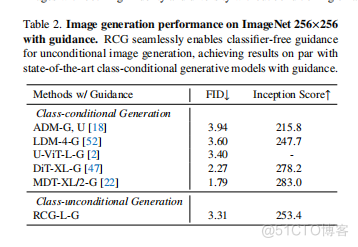
利用类条件表示生成,从而使RCG也能够熟练地执行类条件图像生成。这一结果证明了RCG的有效性,并进一步突出了自助图像生成的巨大潜力。4.3.传统的类无条件图像生成框架缺乏在没有类标签的情况下使用分类器引导[18]的能力。此外,它们也与无分类器指导不兼容,因为指导本身来自无条件生成。RCG的一个显著优势在于它能够将无分类器引导集成到其像素生成器中。如表2所示,RCG的每
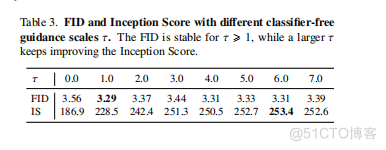
通过无分类器的引导,性能显著提高,达到了可与利用引导的领先的类条件图像生成方法相媲美的水平。我们还取消了我们的无分类器指导量表,如表3所示。=1可以改善FID和IS,一个更大的不断提高初始评分。4.4.本节提供了对RCG的三个核心成分的全面消融研究。我们的默认设置使用Moco v3 ViT-B作为预先训练的图像编码器,一个RDM有12块,1536维隐藏骨干训练100个ch,和一个训练200个ch的MAGE-B像素生成器。默认设置在表4到表6中用灰色标记。除非另有说明,在每个组件的单独消融期间,所有其他属性和模块都被设置为默认设置。预先训练好的编码器。我们在表4中探讨了不同的预训练图像编码器设置。表4a比较了通过不同的SSL方法(Moco v3、DINO、
和iBOT),突出了它们比无条件基线的实质性改进。此外,使用DeiT [59]以监督方式训练的编码器也表现出令人印象深刻的性能(5.51 FID和211.7 IS),表明RCG对监督和自我监督的预训练方法的适应性。表4b评估了模型大小对预训练的编码器的影响。虽然较小的ViT-S模型(22M参数)仍然取得了良好的结果(5.77 FID和120.8 IS),但具有较好线性探测精度的大型模型能够持续提高生成性能。我们进一步分析了图像表示维数的影响,使用Moco v3 ViT-B模型训练与不同的输出维数从他们的投影头。表4c显示,过低和高维表示都不是理想的-过低维
失去重要的图像信息,而过高的维度会对表示生成器带来挑战。表示生成器。表5消除了表示扩散模型。RDM的体系结构由完全连接的块组成,网络的深度和宽度由块的数量和隐藏的维度决定。表5a和表5b消除了这些参数,表明了12个块和1536个隐藏维度的最佳平衡。此外,表5c和表5d表明,RDM的表现在大约200个训练阶段和250个扩散步长中达到饱和。尽管只产生边际计算成本,但RDM被证明在生成SSL表示方面非常有效,如表6a所示。像素发生器。表6消融了RCG的像素生成器。表6a使用类无条件、类条件和自条件MAGE-B的实验,评估dif-
在世代过程中,强烈的条件反射。在没有任何条件反射的情况下,训练了200个epoch的类无条件MAGE-B只产生14.23 FID和57.7 IS。另一方面,在生成的表示条件下,MAGE-B达到了5.07 FID和142.5 IS,显著超过了类无条件基线,并进一步优于FID中的类条件基线。这表明表示可以比类标签提供更多的指导。它也非常接近于在像素生成过程中基于ImageNet真实图像的预言表示的“上界”,证明了RDM在生成真实的SSL表示方面的有效性。先前关于自条件图像生成的工作主要集中在在表示空间内将图像分类为聚类,使用这些聚类作为伪类条件反射[3,34,40]。我们还评估了这种基于聚类的条件反射的性能,在Moco v3 ViT-B表示空间中使用-means形成1000个集群。该条件反射达到6.60 FID和121.9 IS,低于
4.5.计算成本在表7中,我们提供了对RCG的计算成本的详细评估,包括参数的数量、训练成本和生成吞吐量。训练成本使用64v100gpu的集群进行测量。生成吞吐量是在一个V100 GPU上测量的。由于LDM和ADM测量了它们在单个NVIDIA A100 [52]上的生成吞吐量,我们通过假设A100比V100 [54]的2.2加速,将其转换为V100吞吐量。RCG-L使用了一个预先训练过的Moco v3 ViT-L编码器,一个有12个块和1536个隐藏维度的RDM,以及一个MAGE-L像素生成器。训练阶段包括RDM的200个阶段和MAGE-L. Dur的800个阶段
在生成过程中,RDM经历了250个扩散步骤,而MAGE-L执行了20个并行解码步骤。我们还报告了RCG-B的计算成本和FID,它们具有更少的训练成本和更少的参数数量(Moco v3 ViT-B作为图像编码器,MAGE-B作为像素生成器)。考虑到Moco v3 ViT编码器是经过预先训练的,不需要生成,因此不包括其参数和训练成本。如表中所示,与像素生成器相比,RDM模块只增加了少量的成本。这证明了RCG与现代生成模型的兼容性,突出了它以最小的计算负担提高生成性能的能力。4.6.定性结果表示重建。图6说明了RCG生成与给定表示进行语义对齐的图像的能力。我们使用来自ImageNet256256中的示例提取SSL表示。对于每个表示法,我们通过改变生成过程中的随机种子来生成各种图像。RCG生成的图像,虽然具体细节不同,但始终能捕捉到原始图像的语义本质。这个结果
表示插值。利用RCG对表示的依赖性,我们可以通过线性插值两个图像各自的表示来在两个图像之间进行语义转换。图7显示了ImageNet图像对之间的这种插值。插值图像在不同的插值率下保持逼真,其语义内容平滑地从一幅图像过渡到另一幅图像。这说明RCG的表示空间既平滑且语义丰富。这也展示了RCG在低维表示空间中操纵图像语义方面的潜力,为控制图像生成提供了新的可能性。


5.计算机视觉已经进入了一个新的时代,从广泛的、未标记的数据集中学习正变得越来越普遍。尽管有这种趋势,但图像生成模型的训练仍然主要依赖于标记数据集,这可能是由于条件图像生成和无条件图像生成之间的性能差距很大。我们的论文通过探索自条件图像生成来解决这个问题,我们提出它作为条件和无条件图像生成之间的联系。我们证明了通过生成基于SSL表示的图像,可以有效地弥合长期存在的性能差距
并利用一个表示扩散模型来对这个表示空间进行建模和采样。我们相信,这种方法有潜力将图像生成从人类注释的约束中解放出来,使其能够充分利用大量的未标记的数据,甚至泛化到超出人类注释能力范围的模式。致谢我们感谢张惠文、谢世敏、刘庄、陈欣蕾、拉巴特迈克的讨论和反馈。我们也感谢陈欣蕾对MoCo v3的支持。
参考[1]吉米雷巴,杰米瑞安基罗斯,和杰弗里E辛顿。层规范化arXiv预印本,arXiv:1607.06450,2016年。[2]范宝,李崇轩,曹越越,朱军。所有这些都是值得一说的:一个基于分数的扩散模型的vit主干。在NeurIPS 2022年关于基于分数的方法的研讨会上,2022年。[3]范宝、李崇轩、孙嘉成、朱军。为什么条件生成模型比无条件生成模型更好?arXiv预印本arXiv:2212.00362,2022年。[4]、李东和富伟。伯特:图像变压器的预训练。arXiv预印本arXiv:2106.08254,2021年。[5]弗洛里安博德斯,兰德尔巴利斯特里罗,和帕斯卡文森特。你的自我监督表示所知道的高保真可视化。arXiv预印本arXiv:2112.09164,2021年。[6]安德鲁布洛克,杰夫多纳休,和凯伦西蒙尼扬。大规模的高保真自然图像合成训练。arXiv预印本,arXiv:1809.11096,2018年。[7]安德鲁布洛克,杰夫多纳休,和凯伦西蒙尼扬。用于高保真自然图像合成的大规模GAN训练。在Int。会议关于学习表征(ICLR),2019年。[8]马蒂尔德卡隆,彼得博亚诺夫斯基,阿尔芒朱林,
计算机视觉会议(ICCV),第9640-9649,2021页。[17]贾邓、魏东、苏彻、李佳、李凯、李飞飞。一个大规模的分层图像数据库。2009年IEEE计算机视觉和模式识别会议,第248-255页。Ieee, 2009.[18]普拉弗拉达里瓦尔和亚历山大尼科尔。扩散模型在图像合成上超过了甘斯。神经信息处理系统的进展,34:8780-8794,2021。[19]的杰夫多纳休和凯伦西蒙尼扬。大规模的对抗性表征学习。神经信息处理系统的进展,2019年32日。[20]阿列克谢多索维茨基、卢卡斯拜尔、亚历山大科列斯尼科夫、德克韦森伯恩、翟晓华、托马斯昂特西纳、穆斯塔法德加尼、马蒂亚斯明德尔、格奥尔格海戈尔德、西尔万盖利等。一张图像值16×16个字:用于按比例进行图像识别的变形金刚。在Int。会议关于学习表征(ICLR),2021年。[21] Stefan,内内英二和多雅健二。强化学习中神经网络函数逼近的sg加权线性单位。神经网络,2018年107:3-11日。[22]上华、潘、程明明、水雅https://arxiv.org/pdf/2312.03701v2.pdf
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
不学习底层知识可能不会阻碍你成为一个称职的程序员,但也许会阻碍你成为一个优秀的程序员。我所理解的底层知识,是指编程或开发所依赖的平台(或者框架、工具)的知识。对于 Java 开发者来说,虚拟机、字节码就是其底层知识。 这篇文章我们以输出 “Hello, Wor…
