

Apache Kyuubi [1] 是一个分布式多租户的 SQL 网关,主要功能为接受用户的通过 JDBC/REST 等协议提交的 SQL 并根据多租户隔离策略路由给其管理的 SQL 引擎执行。在最新的 Kyuubi 1.8 版本,Kyuubi Flink Engine 迁移到 Flink SQL Gateway(下简称 FSG) API 之上并支持 Flink Application 模式,这让我们能借助 Kyuubi 快速部署生产可用的分布式 Flink SQL 网关。
为什么需要 Kyuubi
相信不少读者首先会想到的问题是,Flink 已经提供 SQL Gateway,为什么还需要引入 Kyuubi 呢?其实关键答案就在 Kyuubi 描述中: 一是分布式,二是多租户,两者相辅相成。网关负载能力需要水平拓展,那么自然会演进到分布式;在分布式环境下需要保证会话的亲和性,那么自然产生多租户路由的需求;而多租户对隔离性有较高要求,因此反过来也会促进分布式架构的发展。
SQL Gateway 和 SQL Client 的组合能开箱即用并帮助我们快速跑通 demo,然而在企业生产环境,单个实例往往难以满足用户请求,此外不同业务用户对于 Flink 版本、内置依赖、资源配置常有不同需求,这导致我们不得不维护多个 SQL Gateway 实例。更令人头疼的是,一个实例可能在多个小用户间共享,也可能被一个大用户独占,用户与 SQL Gateway 实例间成多对多的映射关系。除此以外,高可用和负载均衡也是不得不面对的难题。种种问题造成 SQL Gateway 的运维管理成本居高不下,而 Kyuubi 的出现则很大程度地解决了这个问题。
Kyuubi 基本原理
Kyuubi 主要有 Client、Server 和 Engine 三个模块。
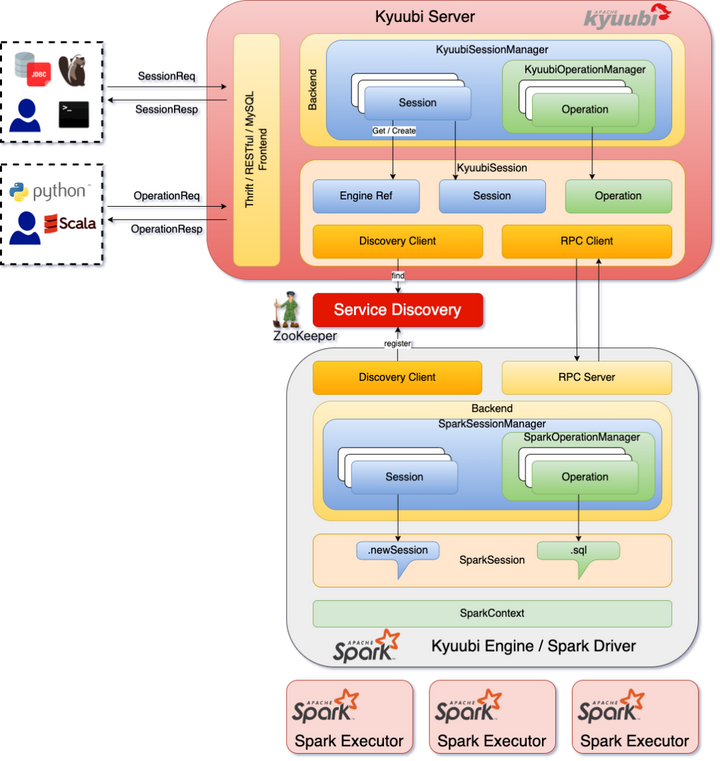
图1. Kyuubi 架构
- Kyuubi Client 比较简单,既有
kyuubi-beeline这样开箱即用的客户端,也可选择 DBeaver 或 JDBC/REST 之类的开放工具或协议。 - Kyuubi Server 是最为核心的模块,主要职责为:
- 为 Client 提供包括 多种协议的 Frontend,接受 Connection。
- 管控 Engine 的生命周期并将用户请求路由到合适的 Engine。
- 管理 Session / Operation 状态。
- Kyuubi Engine 是承载实际计算负载的模块,负责将 Kyuubi Server 的请求翻译为引擎原生操作,支持 Spark / Flink / Trino 等多种计算引擎。
不少读者可能已经发现,FSG 的定位类似于 Kyuubi 的 Flink Engine (实际上 Kyuubi Flink Engine 的确内嵌一个 FSG),而 Kyuubi Server 这层抽象正是解决分布式和多租户问题的关键。
Kyuubi 架构中 Client 与 Server、Server 与 Engine 之间的通信均有服务发现和负载均衡,这意味着不同模块之间是非常松耦合的。Client 可以连到任意一个相同 Namespace 的 Kyuubi Server 上,Kyuubi Server 也能访问同个 Namespace 下的任意 Engine。对于 Batch 场景的有状态短连接,Kyuubi 会持久化相关状态到数据库并通过 Server 间转发确保连接总是能落到同个 Server。这样的设计使得 Kyuubi 具有优秀的水平拓展能力。
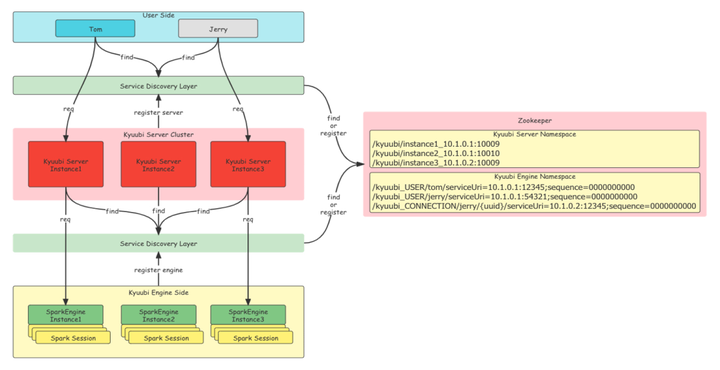
图2. Kyuubi 会话路由
如上文所说,多租户请求的路由是 Kyuubi Server 的核心功能。Kyuubi Server 提供不同程度的 Engine Share Level 以满足多租户的隔离需求,同时根据 Engine Share Level 来选取请求对应的 Engine。
| Share Level | 描述 | 共享性 | 隔离性 | 适合场景 |
|---|---|---|---|---|
| CONNECTION | 每个连接独占一个 Engine | 最低 | 最高 | 大数据量 ETL 或 Ad-hoc 查询或实时作业 |
| USER | 每个用户独占一个 Engine | 中等 | 中等 | 普通 ETL 或者 Ad-hoc 查询或实时作业 |
| GROUP | 每个用户组共享一个 Engine | 高 | 低 | 普通 ETL 或者 Ad-hoc 查询或实时作业 |
| SERVER | 全部用户共享一个 Engine | 最高 | 最低 | 管理员操作 |
此外,Engine 的生命周期由 Server 自动管控。如果当前没有合适的 Engine,那么 Server 就会启动一个 Engine;而如果有 Engine 空闲超过一定时间, Engine 会自动关闭来节省资源。
额外好处
Kyuubi 除了上述最基础的优势以外,对比直接使用 FSG 还会有额外的好处。其中有因为开发进度不同而导致的短期差异,也有因为项目定位不同而可能存在的长期差异。
Application 部署模式
Kyuubi 在最新的 1.8 版本支持了 Flink on YARN Application 模式,而目前 FSG 的 Application 模式尚在讨论阶段(见 FLIP-316 [2])。值得关注的是,长期来说两者对于 Application 模式的实现方式并不相同。
要理解背后的差异,首先简单回顾 Flink SQL 的基础。我们执行一条 Flink SQL 会经历如下几个阶段:
- 解析: 用户提交的 SQL 首先会被 Parser 解析为逻辑执行计划
- 优化: 逻辑执行计划经过 Planner Optimizer 优化,会生成物理执行计划
- 编译: 物理执行计划再通过 Planner CodeGen 代码生成 Java 代码(DataStream Transformation),构建 JobGraph
- 执行: 将 JobGraph 提交给 JobManager,后者申请 TaskManager 执行作业
对于 Flink Session 模式或者 Per-Job 模式而言,前 3 个步骤均在 Flink Client 端的 TableEnvironment 完成,而且编译产出的 JobGraph 可序列化并包含全部作业信息,因此十分适合用于划分 SQL 网关和 Flink 集群的界限。换句话说,网关完成 SQL 解析、优化、编译之后,将 JobGraph 以 REST 或提交到 HDFS/S3 等分布式存储即可。
然而,Application 模式对架构提出了新挑战。Application 模式下 JobGraph 的构建必须在 JobManager 端进行,这意味着编译也需要在 JobManager 端进行。为此,我们需要将步骤 2 产生的物理执行计划序列化后并上传到 JobManager 端,而这个序列化对象便是 Json Plan [3]。
Json Plan 在 Flink 1.14 引入,是 Flink 物理执行计划 ExecNodeGraph 的序列化表示,原本主要是为 Flink SQL 的跨版本升级设计,现在用于 FSG 与 JobManager 的通信也是开箱即用十分方便。而 FSG 支持 Application 模式的议案 FLIP-316 正是基于 Json Plan 来设计。
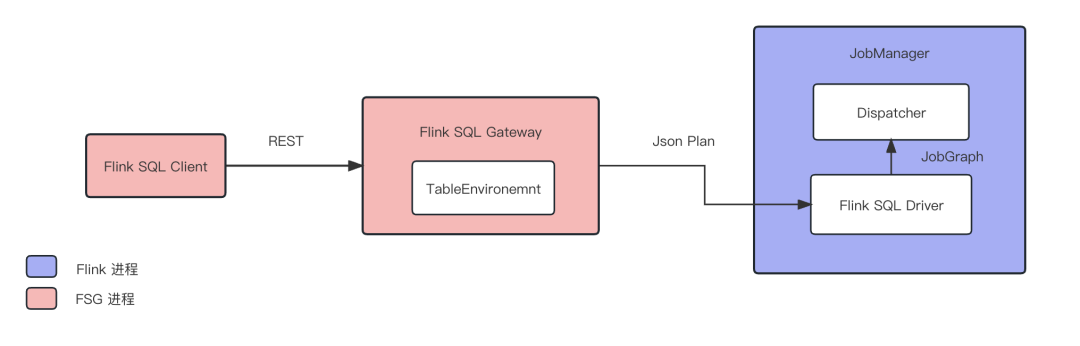
图3. FSG Application Mode 架构
然而 Json Plan 当前还是有一定的局限性,其中最大的限制是 Json Plan 只支持 Streaming 模式的 INSERT 语句和 STATEMENT SET 语句,这导致 Application 模式暂时无法支持 Batch 模式和 SELECT,限制了数据探索的场景。
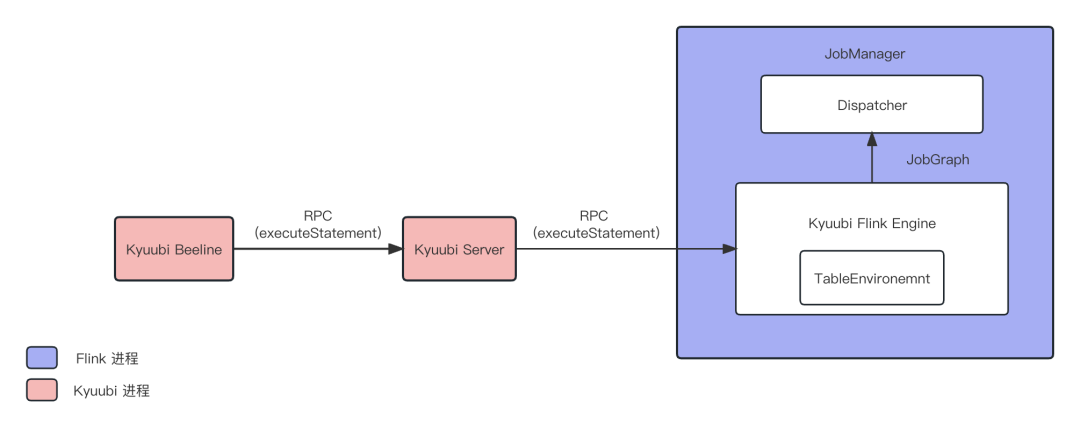
图4. Kyuubi Application Mode 架构
相对地,Kyuubi Flink Engine 的 Application 模式采用类似 Spark Cluster 模式的架构,直接在 JobManager 端的 TableEnvironment 完成 SQL 的解析、优化、编译和执行,作业信息无需跨进程传递,故不受 Json Plan 的限制。通过 Kyuubi,我们可以像使用 Spark 一样使用 Flink 做任意的数据探索。
可观测性
在企业级应用中,可观测性无疑是重要的基础需求。Kyuubi 提供丰富的 Metric 和 Reporter,并且提供内嵌在 Kyuubi Server 的 Web UI,让我们随时掌握网关的负载情况。
图5. Kyuubi Web UI
在 Metric 方面,Kyuubi Metric 可以分为几大类:
- Connection Metric: 监控不同状态的 Connection 数目
- Operation Metric: 监控不同状态的 Operation 数目以及执行时长
- 线程池 Metric: 监控 Kyuubi Server 服务线程池是否充裕
- Engine Metric: 监控不同用户的不同状态的 Engine 数目
- RPC 调用 Metric: 监控 Kyuubi Server 与 Engine 之前不同 RPC 调用的频率及时间
在 Report 方面,Kyuubi 提供最流行的 Prometheus Reporter 和 JMX Reporter,如果需要基于日志的 Metric 也可选择 SLF4J Reporter、JSON Reporter 或 Console Reporter。
未来展望
从 Spark 专用到多引擎支持,Kyuubi 正一步步地往 “SQL Gateway 的标准解决方案” 的目标迈进。而在 Flink Engine 支持上,未来 Kyuubi 将进一步重点补齐 on K8s 和伪装认证能力,完善用户在不同的环境下使用 Flink SQL 体验。
10月28日 14:00,网易杭州研究院、网易数帆将于服务器托管网网易杭州园区举办“数咖说5大 Committer 畅聊湖仓新未来”技术沙龙,邀请数据技术领域领军企业Databricks、网易数帆及携程的实战大咖襄助,包括网易数帆大数据技术专家、Apache Kyuubi PMC Chair / Apache Spark Committer 姚琴,Databricks 开源组技术主管、Apache Spark PMC Member 范文臣,网易数帆大数据技术专家、Apache Spark Committer 尤夕多,携程离线计算平台负责人、Apache Kyuubi PMC Member 陈少云,网易大数据技术专家、Apache Kudu Committer 何李夫等,共计5 位 Apache 明星项目 PMC/Committer齐聚一堂,畅谈Spark、Kyuubi、ClickHouse等热门湖仓技术新发展、新实践、新价值。了解详情:数咖说 | 5 大 Apache Committer 畅聊湖仓新未来
参考
- Apache Kyuubi Github Repo
- FLIP-316: Introduce SQL Driver
- FLIP-190: Support Version Upgrades for Table API & SQL Programs
作者介绍
林小铂,Apache Kyuubi Committer,目前就职于网易游戏,技术中心数据与平台服务部,负责 Flink 基础组件及 Streamfly 实时计算平台。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
导语 | 在云原生时代,研发效能治理面临新的挑战,同时也获得了新的视角。如何更好地利用云原生技术的优势,从而在根本上提升研发效能,已成为许多企业数字化转型过程中的“必答题”。今天,我们特别邀请了 Thoughtworks 创新技术总经理、腾讯云 TVP 肖然老…
