

作者 | 小萱
导读
基于实际业务需求,介绍了自定义Wasm截帧方案的实现原理和实现方案。解决传统的基于canvas的截帧方案所存在的问题,更高效灵活的实现截帧能力。
全文10103字,预计阅读时间26分钟。
01 项目背景
在视频编辑器里常见这样的功能,在用户上传完视频后抽取关键帧 ,提供给用户以便快捷选取封面,如下图:

在本文中,我们将探讨一种使用FFmpeg和WebAssembly(Wasm)的Web端视频截帧方案,以解决传统的基于canvas的截帧方案所存在的问题。通过采用这种新方法,我们可以克服video标签的限制,实现更高效、更灵活的视频截帧功能。
首先,我们需要了解一下传统的Web截帧方案的局限性。虽然该方案在处理一些常见的视频格式(如MP4、WebM和OGG)时表现良好,但其存在以下缺陷:
-
类型有限:video标签支持的视频格式十分有限,无法处理一些其他常见的视频格式,如FLV、MKV和AVI等。
-
DOM依赖:该方案依赖于DOM,只能在主线程中完成。这意味着在处理大量截帧任务时,可能会对页面性能产生负面影响。
-
抽帧策略局限:传统方案无法精确控制抽帧策只能传递时间交给浏览器,设置currentTime时会解码寻找最接近的帧,而非关键帧。
为解决上述问题,选取FFmpeg+Wasm的方案,通过自定义编译FFmpeg,在web-worker里执行rgb24格式数据到ImageData的运算,再传递结果给主线程,实现。
02 Wasm核心原理
2.1 Wasm是什么
用官网的话说,WebAssembly(缩写为Wasm)是一种用于基于堆栈的虚拟机的二进制指令格式。
WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications.
— https://webassembly.org/
Wasm 可以看作一种容器技术,它定义了一种独立的、可移植的虚拟机,可以在各种平台上执行,类比于docker,但更为轻量。WebAssembly 于2017年粉墨登场,2019年12月正式认证为Web标准之一并被推荐,拥有高性能、跨平台、安全性、多语言高可移植等优势。
业界有很多Wasm虚拟机的实现,包含解释器,单层/多层AOT、JIT模式。
2.2 chrome如何运行Wasm
浏览器内置JIT引擎,V8使用了分层编译模式(Tiered)来编译和优化 WASM 代码。分层编译模式包括两个主要的编译器:
-
基线编译器(Baseline compiler) Liftoff编译器
-
优化编译器(Optimizing compiler) TurboFun编译器
2.2.1 Liftoff 编译器
当 WASM 代码首次加载时,V8 使用 Liftoff 编译器进行快速编译。Liftoff 是一个线性时间编译器,它可以在极短的时间内为每个 WASM 指令生成机器代码。这意味着,它可以尽快地生成可执行代码,从而缩短代码加载时间。
然而,Liftoff 编译器的优化空间有限。它采用一种简单的一对一映射策略,将 WASM 指令独立地转换为机器代码,而不进行任何高级优化。这使得生成的代码性能较低。
2.2.2 TurboFan 编译器
对于那些被频繁调用的热函数(Hot Functions),V8 会使用 TurboFan 编译器进行优化编译。TurboFan 是一个更高级的编译器,能够执行各种复杂的优化技术,如内联缓存(Inline Caching)、死代码消除(Dead Code Elimination)、循环展开(Loop Unrolling)和常量折叠(Constant Folding)等,从而显著提高代码的运行效率。
V8 会监控 WASM 函数的调用频率。一旦一个函数达到特定的阈值,它就会被认为是Hot,并在后台线程中触发重新编译。在优化编译完成后,新生成的 TurboFan 代码会替换原有的 Liftoff 代码。之后对该函数的任何新调用都将使用 TurboFan 生成的新的优化代码,而不是 Liftoff 代码。
2.2.3 流式编译与代码缓存
V8 引擎支持流式编译(Streaming Compilation),这意味着 WASM 代码可以在下载的同时进行编译。这大大缩短了从加载到可执行的总时间。流式编译在基线编译阶段(Liftoff 编译器)尤为重要,因为它可以确保 WASM 代码在最短的时间内变得可运行。
为了进一步提高性能和加载速度,V8 引擎支持代码缓存(Code Caching)机制。代码缓存可以将编译后的 WASM 代码存储在缓存中,以便在将来需要时直接从缓存中加载,而无需重新编译。这大大缩短了页面加载时间,提高了用户体验。目前WebAssembly 缓存仅针对流式 API 调用, compileStreaming 和 instantiateStreaming 这两个API,使用流式API拥有更好的性能。对于缓存的工作原理:
-
当TurboFan完成编译后,如果.wasm资源足够大(128 kb),Chrome 会将编译后的代码写入 WebAssembly 代码缓存。
-
当.wasm第二次请求资源时(hot run),Chrome.wasm从资源缓存中加载资源,同时查询代码缓存。如果缓存命中,编译后的module bytes将发送到渲染器进程并传递给 V8,V8将其进行反序列化,与编译相比,反序列化速度更快,占用的 CPU 更少。
-
如果.wasm资源发生了变化或是 V8 发生了变化,缓存会失效,缓存的本地代码会从缓存中清除,编译会像步骤 1 一样继续进行。
2.2.6 编译管道(Compilation Pipeline)

△频效果V8编译Wasm的流程图
V8 编译 WASM 代码的整个过程可以概括为以下几个步骤:
-
解码(Decoding):首先,将 WASM 模块解码为二进制可执行代码,并验证其是否符合 WASM 标准。
-
基线编译(Baseline Compilation):接下来,使用 Liftoff 编译器进行快速编译。这一阶段生成的代码性能较低,但编译速度快。流式编译在这个阶段发挥作用,使得代码在下载过程中就能进行编译。
-
热点分析(Hotspot Analysis):V8 引擎会持续监控 WASM 函数的调用频率,以识别 Hot Function。
-
优化编译(Optimizing Compilation):对于被标记为热门函数的代码,使用 TurboFan 编译器进行优化编译。编译完成后,优化后的代码会替换原有的 Liftoff 代码。这一过程称为分层升级(Tier-up)。
-
执行(Execution):在优化编译完成后,代码将在 V8 引擎中运行。
对比V8执行js的流程,省去了Parser生成ast,Ignition生成字节码的的过程,因此有更高的性能和执行效率。
03 FFmpeg的介绍
FFmpeg作为一个开源的强大的音视频处理工具,实现视频和音频的录制、转换、编辑等多种功能。FFmpeg包含了众多的编码库和工具,可以处理各种格式的音视频文件,例如MPEG、AVI、FLV、WMV、MP4等等。
FFmpeg最初是由Fabrice Bellard于2000年创立的,现在它是由一个庞大的社区维护的开源软件项目。FFmpeg支持各种操作系统,包括Windows、macOS、Linux等,也支持各种硬件平台,例如x86、ARM等。
FFmpeg的功能非常强大,可以进行很多复杂的音视频处理操作,例如视频转码、视频合并、音频剪辑、音频混合等等。FFmpeg支持众多编码格式和协议,包括H.264、HEVC、VP9、AAC、MP3等等。同时,它还可以进行流媒体的处理,例如将视频流推送到RTMP服务器、从RTSP服务器拉取视频流等等。
04 截帧策略的制定
4.1 I、B、P帧是什么
这个概念来源于视频编码,为描述视频压缩编码中的帧类型。
I帧(Intra-coded frame),也叫关键帧(keyframe),它是视频序列中的一种独立帧,也就是说,它不需要参考其它帧进行解码。I帧通常用来作为视频序列的参考点,后续的B帧和P帧都会参考它进行编码。I帧通常具有较高的压缩比和较大的文件大小,但是它也提供了最高的图像质量。
P帧(Predictive-coded frame) 是通过对前面的I帧或P帧进行运动预测得到的帧,也就是说,P帧需要参考前面的一个或多个帧进行解码。P帧通常比I帧小一些,但是它的压缩比比I帧高。
B帧(Bidirectionally-predictive-coded frame) 是通过对前面和后面的帧进行运动预测得到的帧,也就是说,B帧需要参考前面和后面的帧进行解码。B帧通常比P帧更小,因为它可以更充分地利用前后两个参考帧之间的冗余信息进行编码。
因此,视频编码中通常会使用一种叫做“三合一”编码的方式,即将一个I帧和它前面的若干个P帧以及后面的若干个B帧组成一个GOP(Group of Pictures)。这样的编码方式既可以提高编码的效率,也可以提供高质量的图像。
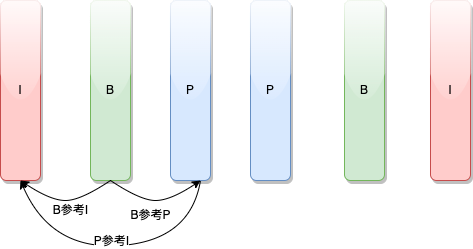
△I、B、P帧关系示例图
4.2 关键帧生成策略
视频编辑器抽帧的目的是为用户提供有效的封面图选取,因此我们希望抽出来包含较大信息量质量较高的图作为抽帧产物,从上面的介绍可知,一般情况下关键帧是包含信息量较大的帧,因此理想状态是只产出关键帧。
按照需求场景,我们需要对每个视频提取12张图片。若使用canvas抽帧方案,就意味着这12张图片只能根据时间间隔进行抽取,无法使用视频本身的关键帧信息,图片可能是关键帧,也可能是BP帧。非关键帧的图片往往质量较差不适合作为封面图。且浏览器也需要基于I帧进行逐帧的解码,这会耗费较长的时间。因此我们决定借助FFmpeg库的能力,生成关键帧。
为什么不直接使用FFmpeg的命令生成关键帧呢,一个视频具体有多少张关键帧这是不一定的,可能多于12张也可能少于12张,因此只用FFmpeg的命令生成关键帧一把梭生成全部关键帧这是不够的。
对于少于12张关键帧的视频,采取补齐的策略,在两关键帧之间,以2s为时间间隔进行补齐。如果两帧间隔时间不足2s间隔分配,那就按照两关键帧间隔时间/在此间隔需要补的帧数,计算出需要补齐的帧的所在时间。
FFmpeg在获取关键帧是很快的,因为关键帧的时间信息是可以直接从视频里获取到的,可以直接调用av_seek_frame 跳到关键帧位置,然后解一帧即可,对于指定时间的非关键帧的寻找,需要跳到最近的关键帧,再一帧帧的解包寻找,知道寻找的指定的时间,进行输出。
对于超出12帧关键帧的视频,按照相等的间隔进行选取,比如有24张,那么选取0、2、…23索引的帧为输出帧。
其他的优化点,第一帧一定是I帧,因此在第一时间读取第一帧并返回,让用户瞬间看到一帧,减少视觉等待时间,其他帧每确定一帧是符合输出帧就立即输出,用户看到的是一帧帧输出的,而不是等到全部抽帧任务完成再输出。

△百家号wasm抽帧效果图
05 定义编译FFmpeg
5.1 环境准备
Emscripten、LLVM、Clang都可以将c、cpp代码编译成Wasm,我们使用 Emscripten 编译。Emscripten会帮你生成胶水代码(.js文件)和Wasm文件。
首先下载emsdk,执行以下命令配置并激活已安装的Emscripten。
git clone https://github.com/emscripten-core/emsdk.git
cd emsdk
git pull
./emsdk install latest
./emsdk activate latest
source ./emsdk_env.sh
最后source环境变量,配置Emscripten各个组件的PATH等环境变量。
5.2 编译FFmpeg
为了产出能在以在浏览器中运行的WebAssembly版本的FFmpeg,我们禁用了大部分针对特定平台或体系结构的优化,以便生成尽可能兼容的WebAssembly代码。
使用Emscripten的emconfigure命令运行FFmpeg的configure脚本,传入自定义参数以便完成兼容。下面是自定义参数:
CFLAGS="-s USE_PTHREADS"
LDFLAGS="$CFLAGS -s INITIAL_MEMORY=33554432" # 33554432 bytes = 32 MB
CONFIG_ARGS=(
--prefix=$WEB_CAPTURE_PATH/lib2/ffmpeg-emcc
--target-os=none # use none to prevent any os specific configurations
--arch=x86_32 # use x86_32 to achieve minimal architectural optimization
--enable-cross-compile # enable cross compile
--disable-x86asm # disable x86 asm
--disable-inline-asm # disable inline asm
--disable-stripping # disable stripping
--disable-programs # disable programs build (incl. ffplay, ffprobe & ffmpeg)
--disable-doc # disable doc
--extra-cflags="$CFLAGS"
--extra-cxxflags="$CFLAGS"
--extra-ldflags="$LDFLAGS"
--nm="llvm-nm-12"
--ar=emar
--ranlib=emranlib
--cc=emcc
--cxx=em++
--objcc=emcc
--dep-cc=emcc
)
cd $FFMPEG_PATH
emconfigure ./configure "${CONFIG_ARGS[@]}"
PS:上面我们允许了C++使用pthread,但因为在浏览器使用pthread多线程需要SharedArrayBuffer 允许多个Web Workers或WebAssembly线程访问和操作相同的内存区域,而SharedArrayBuffer的兼容性较差,并且要求https,因此我们在接下来产出wasm时禁用pthread。
FFmpeg包含了很多库,若直接使用@ffmpeg/ffmpeg @ffmpeg/core便是全量的库的wasm版本。
-
libavformat:负责多媒体文件和流的格式处理。这个库可以帮助你读取和写入多种音频和视频文件格式,以及网络流。
-
libavcodec:负责音视频编解码。这个库包含了众多的音频和视频编解码器,可以处理多种格式的音频和视频。
-
libavutil:提供一些实用功能,例如内存管理、数学运算、时间处理等。这个库被 libavformat 和 libavcodec 等其他库所使用,用于辅助处理各种任务。
-
libswscale:负责图像的缩放和颜色空间转换。这个库可以帮助你将视频帧从一种像素格式转换为另一种,或者对图像进行缩放。
-
libswresample:负责音频重采样、混合和格式转换。这个库用于处理音频数据,例如改变采样率、改变声道数等。
-
libavfilter:负责音视频滤镜处理。这个库提供了一系列音视频滤镜,用于处理音频和视频,例如调整色彩、裁剪、添加水印等。
-
libavdevice:负责获取和输出设备相关的操作。这个库提供了对各种设备的支持,例如摄像头、麦克风、屏幕捕捉等。
而我们抽帧只需要读取视频文件或流、解码、对产生的像素格式转换以及通用工具函数,也就是libavformat、libavcodec、libswscale和libavutil这几个库, 在接下来产出wasm我们便选取这几个库作为编译的输入文件,可以大幅减少产出的wasm资源体积。

5.3 编译产出.wasm、.js
Emscripten支持产出多种格式文件,我们这里使用他为我们准备的胶水代码,故生成.wasm和.js文件,
使用emcc命令编译cpp代码,首先通过Clang编译为LLVM字节码,然后根据不同的目标编译为asm.js或Wasm。由于内部调用Clang,因此emcc支持绝大多数的Clang编译选项,比如-s OPTIONS=VALUE、-O、-g等。除此之外,为了适应Web环境,emcc增加了一些特有的选项,如–pre-js
emcc $WEB_CAPTURE_PATH/src/capture.c $FFMPEG_PATH/lib/libavformat.a $FFMPEG_PATH/lib/libavcodec.a $FFMPEG_PATH/lib/libswscale.a $FFMPEG_PATH/lib/libavutil.a
-O0
# 使用workerfs文件系统
-lworkerfs.js
# 讲这个文件内连到胶水js里面 共享上下文
--pre-js $WEB_CAPTURE_PATH/dist/capture.worker.js
# 指定编译入口路径
-I "$FFMPEG_PATH/include"
# 声明编译目标是wasm
-s WASM=1
-s TOTAL_MEMORY=$TOTAL_MEMORY
# 告诉编译器我们希望从编译后的代码中访问哪些内容(如果不使用,内容可能会被删除)
-s EXPORTED_RUNTIME_METHODS='["ccall", "cwrap"]'
# 告诉编译器需要塞到Module里的方法
-s EXPORTED_FUNCTIONS='["_main", "_free", "_captureByMs", "_captureByCount"]'
-s ASSERTIONS=0
# 允许wasm的内存增长
-s ALLOW_MEMORY_GROWTH=1
# 产出路径
-o $WEB_CAPTURE_PATH/dist/capture.worker.js
Emscripten提供了四种文件系统,默认是MEMFS(memory fs),其他都需要在编译时候添加进来,-lnodefs.js ( NODEFS ), -lidbfs.js ( IDBFS ), -lworkerfs.js ( WORKERFS ), or -lproxyfs.js ( PROXYFS )。我们在worker中运行wasm,选取workerfs文件系统,它提供了在worker中的file和Blob对象的只读访问,而不需要将整个数据复制到内存中,可能用于巨大的文件,防止了文件过大导致的浏览器crash。
生成的js里面,Module是全局 JavaScript 对象,Module里固有的方法,可以参考文档 Module object documentation ,同时,你也可以通过–pre-js往Module里添加方法,没有塞入Module的方法可以通过EXPORTED_FUNCTIONS添加。

△Module内方法的定义
5.4 Js和C的通信
5.4.1 Js调用C
JavaScript调用C只能使用Number作为参数,因此如果参数是数组、对象等非Number类型,就麻烦了,使用Module._malloc()分配内存,拿到栈指针地址,将数组拷贝到栈空间,将指针作为参数调用c的方法。Emscripten的cwrap方法可以轻松解决。
crap(函数名,返回值,传入c的参数类型数组)
// example ts:captureByMs(info: 'string', path:'string', id:'number'):number
this.cCaptureByMs = Module.cwrap('captureByMs', 'number', ['string', 'string', 'number']);
5.4.2 C调用Js
可以通过emscripten_run_scriptapi在c里调用js,接受参数是拼接成字符串的要执行的js内容,用起来很像eval。
emscripten_run_script("console.log('hi')");
如果传参是指针,js的方法里接受到的是c的指针地址,在当前版本的Emscripten中,指针地址类型为int32,Wasm中js的内存空间均为ArrayBuffer,Emscripten提供的访问对象是Module.buffer,但是js中的ArrayBuffer无法直接访问,Emscripten提供TypedArray对象进行访问。
比如需要传递给js是结构体指针,是这样定义的。
typedef struct
{
uint32_t width;
uint32_t height;
uint32_t duration;
uint8_t *data;
} ImageData;
结构体的内存对齐,所以选取最长的就是uint32_t,uint32_t对应的TypedArray数组是Module.HEAPU32,由于是4字节无符号整数,因此js拿到的ptr需除以4(既右移2位)获得正确的索引。按此类比,8字节无符号整数就需要右移3位。

虽然看起来c调用js很简单,但你不应该做频繁的调用,这会导致较大的开销抵消掉Wasm本身的物理优势。这也是为什么dom操作相关的框架不会选用Wasm进行优化,Wasm还无法直接操作dom,频繁的js和Wasm的上下文的开销也带来不可忽视的性能缺失,他的目的从不是替代js, 类比react,reconciler部分是可以用rust/go 重写,社区也有人做过此尝试,但是并没有带来显著性能优势,社区也有用go/rust编写web应用的框架,比如( yew ),他们为跨端带来更多的可能。
5.5 FFmpeg api介绍
对整体抽帧流程使用到的关键api做简单的介绍,包含对视频的解码、编码以及处理等操作。
-
av_register_all 注册全部解码器,在使用FFmpeg的其他函数之前调用,以确保Ffmpeg可以正确地加载和初始化。
-
avformat_open_input 根据路径读取文件,并将其解析为一个AVFormatContext结构体,其中包含了文件的格式信息和媒体流的信息。
-
avformat_find_stream_info 获取视频的媒体信息 类比ffplay file获取的信息,包含编码格式、视频长度、fps、分辨率等。
-
avcodec_find_decoder 寻找视频对应的解码器。
-
av_read_frame 大量耗时在解码环节,在解码前,可以通过读取压缩的帧信息,获取关键帧队列,AVPacket结构体里的flag等于1,标志该帧是关键帧。
-
av_seek_frame 快速定位到某个时间戳的视频帧,在这里使用它定位到关键帧。
-
基于关键帧进行解包,先调用av_read_frame读取压缩帧,avcodec_send_packet发送压缩包到FFmpeg的解码队列(如果成功,则返回0),avcodec_receive_frame从解码队列里成功取出,判断pts(位于的时间),符合条件的frame信息被存储。
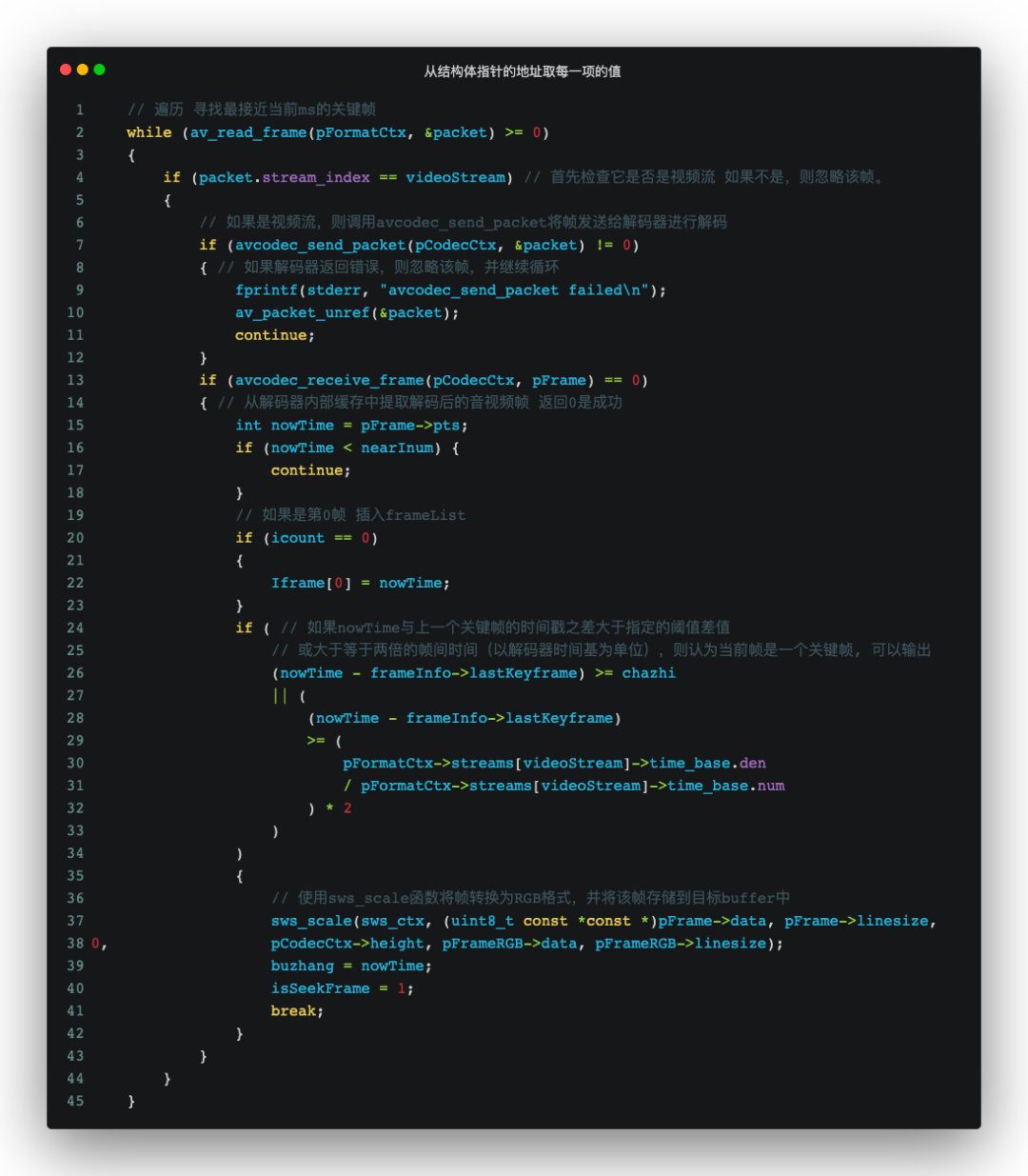
△抽帧的关键代码及解释
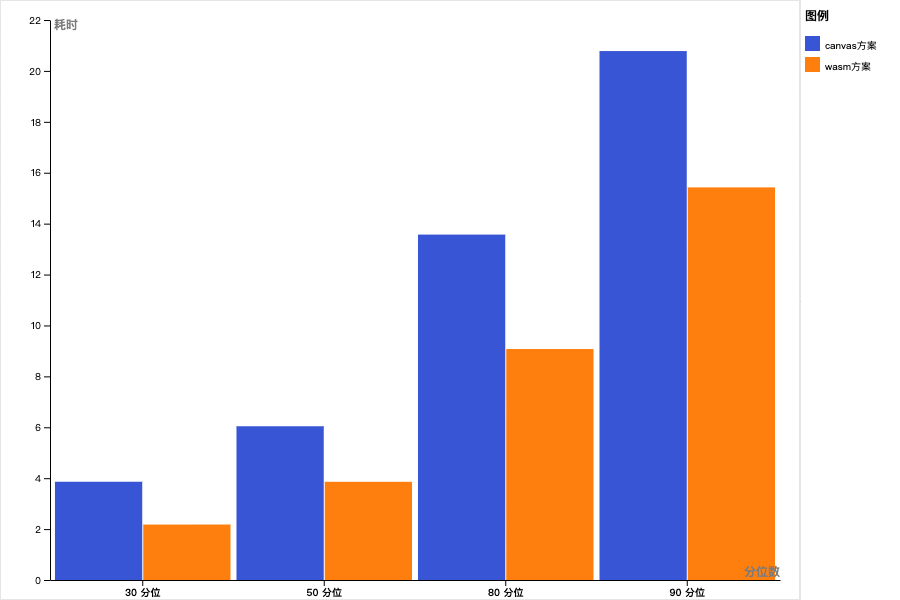
5.6 编译后产物体积对比
自定义编译

使用npm包@ffmpeg/ffmpeg @ffmpeg/core

对比全量引入24.5M,我们只需要4M,体积上的收益还是非常明显的。
06 总结
使用FFmepg+Wasm方案进行视频抽帧,通过自定义编译FFmpeg减少编译产物的体积;定义关键帧优先策略,第一时间给到用户抽帧结果,尽可能减少用户等待时间。在 Emscripten 工具链的加持下,可以方便地将C/C++代码编译成Wasm,并配合产出完整的与web的交互js。在速度和体验以及视频兼容性方面都取得了较为明显的收益,请大胆拥抱WebAssembly为web赋能吧!
目前这套方案已在百家号视频场景落地数月,收益明显。
项目地址:https://github.com/wanwu/cheetah-capture,欢迎star。
封装好api支持按照帧数目和秒数抽取。你也选择自定义编译,通过更改FFmpeg的编译参数让他支持更多的视频类型,通过更改capture.c文件增加更多api能力,期待你来丰富更多场景。
——END——
推荐阅读:
百度研发效能从度量到数字化蜕变之路
百度内容理解推理服务FaaS实战——Punica系统
精准水位在流批一体数据仓库的探索和实践
视频编辑场景下的文字模版技术方案
浅谈活动场景下的图算法在反作弊应用
Serverless:基于个性化服务画像的弹性伸缩实践
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
