
随着大型语言模型的不断蓬勃发展,相关新模型,新应用和新范式也在不断涌现,自4月发布以来,FATE-LLM已经迭代发布了多个版本,不断完善大语言模型在联邦学习场景下的支持,以解决构建、使用大模型时的数据隐私保护问题以及公域数据短缺,可用数据不足的问题,在社区中得到了广泛的关注。
由VMware AI Labs团队发起并贡献的KubeFATE项目也在最近的多个版本中增强了对FATE-LLM在云原生环境下的支持,特别是针对FATE-LLM任务的专有需求,KubeFATE在包括容器构建、GPU调度与使用、模型存储等方面加入了专门的设计。本篇文章将给出一个基于KubeFATE v1.11.2和FATE-LLM v1.2的联邦大模型微调任务实例,并从任务设定、环境部署、所用技术、实验结果与分析等角度进行一个全方位的完整介绍。
任务设定与环境部署
在本文中,我们以FATE-LLM v1.2的GPT2教程为基础,设定一个两方的横向联邦学习场景,两方Party ID分别为9999和10000,我们使用一个文本情感分类的任务来微调一个预训练的GPT2模型。该任务使用的数据集为IMDB影评数据集,与原教程的少量数据的示例不同,我们将训练数据集中全部25000条记录平均分给两方作为各方的训练数据,同时使用测试数据集的25000条记录作为评估数据。
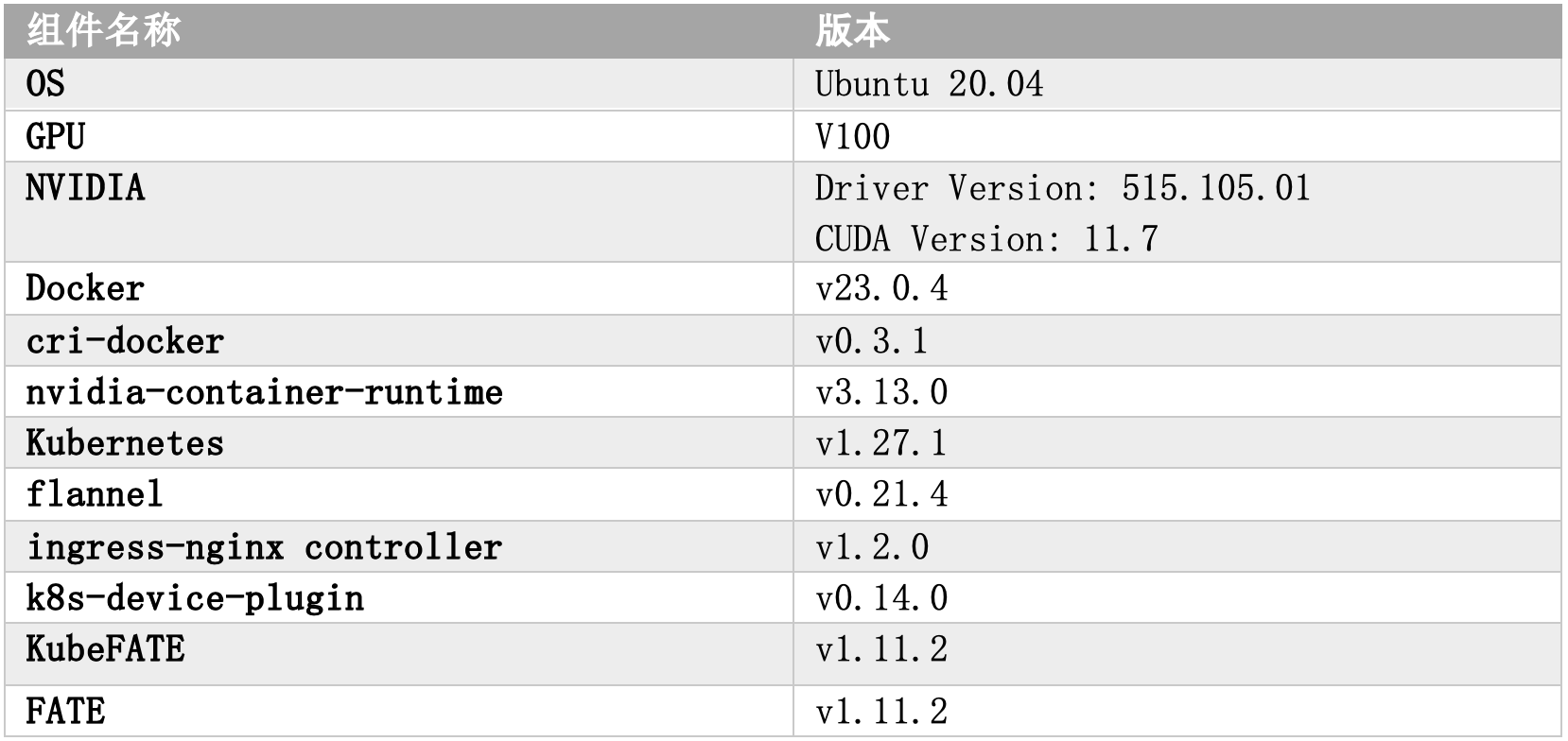
对于实验环境,我们创建了两个Kubernetes集群,分别代表联邦任务的两个参与方。每个Kubernetes集群都包含一个vSphere虚拟机作为GPU节点,各虚拟机使用PCI Passthrough技术分别与一块Nvidia V100 GPU集成。我们使用Docker和cri-docker,以及nvidia-container-runtime和k8s-device-plugin等组件以在Kubernetes集群中使用该GPU。本实验所有关键依赖项的具体版本如下:
我们可以按照KubeFATE项目GitHub仓库中的K8s环境使用指南来部署KubeFATE和FATE集群。要使用 FATE-LLM,我们需要在用于部署FATE集群的cluster.yaml文件中显式指定某些设置。首先我们应该将algorithm参数设置为“ALL”,并将device参数设置为“GPU”,这表示我们要使用包含FATE-LLM和相关模块,以及带有GPU驱动和库的FATE容器镜像。此外,我们需要在python组件即FATE-Flow容器的配置中,在resources资源部分加入GPU资源的请求,例如本文使用了“nvidia.com/gpu: 1”。以下是这些设置的示例:

需要注意的是,本文示例中FATE-LLM的训练任务是由FATE-Flow容器执行的,因此GPU资源分配给了名为python的容器。对于使用了DeepSpeed的FATE-LLM任务,我们需要为nodemanager组件配置该GPU资源设定。此外,我们建议为FATE集群开启持久化,从而使KubeFATE能够保存FATE-LLM任务中的预训练模型、微调模型、任务记录、日志等,防止这些关键文件在容器发生重启后被清理。
为了验证FATE集群部署后的环境和设置,我们可以使用kubectl exec进入fateflow pod并使用nvidia-smi命令检查其中可用的GPU资源。在FATE集群部署好后,我们就可以开始发起FATE-LLM任务了,FATE-LLM v1.2中使用HuggingFace生态的peft库来支持多种高效的参数微调方法,在本文的实践中,我们将采用LoRA、Prefix Tuning、Prompt Tuning和P-Tuning的方法进行比较实验。
采用的PEFT方法
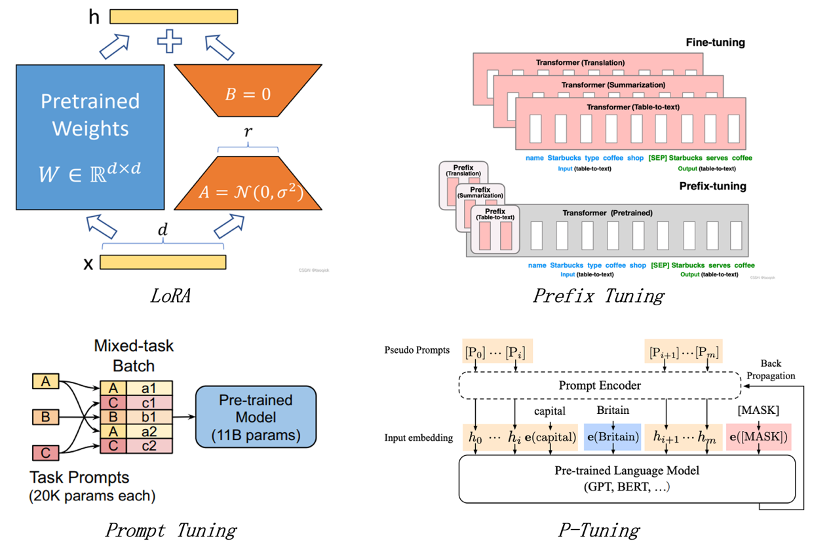
为了使用大语言模型来完成特定的下游任务,如果需要对模型的全部参数进行微调,会造成了巨大的时间开销与数据存储、传输成本。PEFT方法在保持模型性能相当的前提下,通过减少微调的参数量以降低计算、存储、传输数据的成本。在本节中,我们将简要介绍采用的四种PEFT方法。
-
LoRA(Low-Rank Adaptation):LoRA的核心思想是在适应新任务时,权重矩阵的更新不必与原始权重矩阵具有相同的“秩”。因此对每个权重矩阵,我们可以引入两个低秩矩阵模块去代表该更新,微调时则仅训练更新这些低秩的矩阵。在实践中,LoRA一般被应用到attention模块服务器托管网中。
-
Prefix Tuning:该方法在每个transformer层的输入之前构造一段任务相关的virtual tokens作为prefix,在训练时只更新prefix部分的参数,而固定transformer中的其他部分参数。此外,为了防止直接更新prefix的参数导致训练不稳定的情况,prefix层前可以加入了MLP(Multi-layer Perception)结构,即将prefix分解为更小维度的input与MLP的组合。
-
Prompt Tuning:该方法可以看作是Prefix Tuning的简化版本,它只在输入层加入prompt tokens,而并不需要加入MLP进行调整。
-
P-Tuning:该方法的思想也是在输入层添加可训练的prompt参数,由于prompt的词之间是彼此关联的,离散的prompt对于连续的神经网络并不是最优解,我们需要采用某种方法将它们关联起来。于是P-Tuning将一些伪prompt输入至LSTM或类似模型中,利用LSTM的输出向量来替代原始的prompt token,最后一起输入至预训练语言模型中。
运行FATE-LLM任务
接下来我们便可以着手运行FATE-LLM任务。首先,guest与host两方需将本地数据上传至FATE系统,即将预处理后的CSV文件分别放入各方的FATE-Flow容器中。然后我们可以在KubeFATE提供的Jupyter Notebook中使用以下代码将上传的数据绑定到FATE中。(对于host方,需要绑定data_host数据)
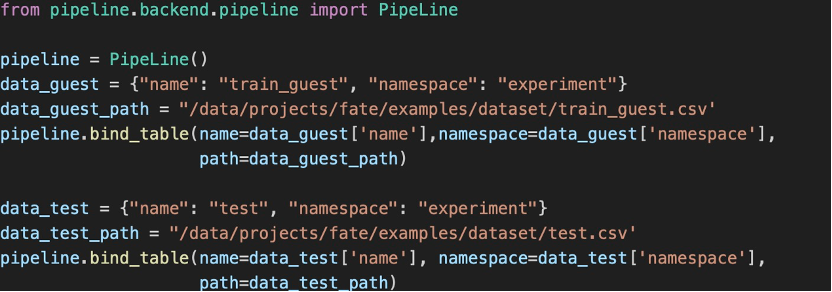
随后我们便可以在guest方提交联邦学习任务,具体流程与FATE-LLM仓库中的GPT2微调教程基本一致,以下是需额外注意的几点:
-
因为本文加入了用于评估的测试数据,我们可以新建一个Reader组件读取该数据并作为NN组件的validate_date;
-
若任务出现超时或Pin memory thread退出等异常,可以尝试将“save_to_local_dir=True, pin_memory=False”添加到TrainerParam;
-
对于本文使用的二分类任务,我们为其配置了Evaluation组件用于评估训练后的模型的性能。
我们使用了多种不同的参数设置方式运行了若干个FATE-LLM任务来评估它们对训练过程与模型性能的影响:
-
设置TrainerParam中的CUDA参数来比较训练时使用CPU和GPU的差异
-
设定peft_type与peft_config参数来采用不同的PEFT方法以及配置
-
设置aggregate_every_n_epoch参数比较不服务器托管网同的本地训练轮次对训练效果的影响
-
调整TrainerParam中的epoch参数找到模型效果最好的轮次(最大为10)
-
我们实现了非PEFT的GPT2 Full Fine-tuning方法,并以此作为对照进行了对比实验
实验结果分析
我们对使用的设备类型、PEFT方法以及运行的epoch次数均进行了多元化的设置。模型性能通过AUC、F1-score等机器学习指标进行评估。除此以外,我们还列举了若干实验本身的数据,包括聚合过程的数据传输量,任务运行时间等,便于进行更深入的分析。在使用PEFT方法对模型训练过程进行优化时,我们尽量使用peft库默认的参数配置。以下是我们实验的部分结果数据:
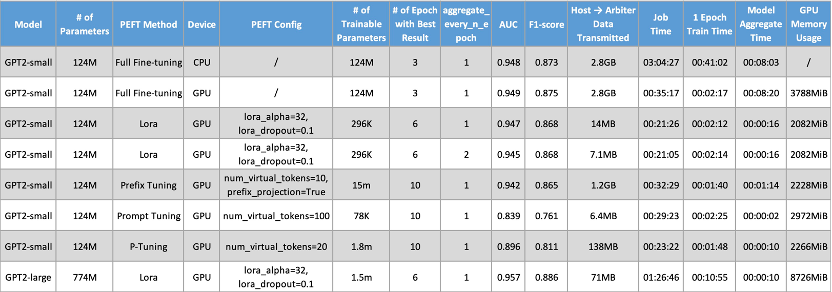
通过对比表格中与模型性能相关的指标,我们可以看到LoRA、Prefix Tuning方法与Full Fine-tuning对照实验的模型性能相当。与此同时,它们的数据传输量、整体训练时间也显著低于Full Fine-tuning,更进一步,我们观察到设定更大一点的模型聚合间的本地训练轮次(同时总轮次不变),能够进一步降低数据传输成本,同时不影响模型性能,这证实了联邦学习与PEFT方法之于微调大语言模型是可行且高效的。而对于另两种PEFT方法,模型性能则有较大的差距,我们猜测这与可训练参数过少或相关PEFT组件参数设置有关,导致模型泛化能力受限。我们在接下来的实验中也将尝试其他方法和参数组合以进一步验证。
总结与展望
本文介绍了使用KubeFATE从部署、配置到发起运行FATE-LLM任务的完整流程。我们展示了不同配置下的实验结果,并进行了分析。实验数据证实了将大语言模型与联邦学习架构结合的合理性,并体现出PEFT方法的强大性能。其在显著降低通信成本、数据存储成本的同时,将模型性能维持在一个相当可观的水平。
本文提供的实例基于FATE-LLM v1.2版本,可作为横向联邦场景下,使用云原生基础设施对同构的大语言模型进行PEFT的微调训练的一个参考。除GPT2示例以外,KubeFATE也支持FATE-LLM v1.2中的其他模型和训练方法,例如使用DeepSpeed进行ChatGLM-6B、Llama等模型的训练。而在最新发布的v1.3版本中,FATE-LLM项目引入了FTL-LLM面向大语言模型的联邦迁移学习范式,并实现了联邦Offsite-Tuning框架。我们会在后续的KubeFATE迭代中进一步加强相关的支持,也欢迎社区开发者和用户的参与和关注。
内容来源|公众号:VMware 中国研发中心
有任何疑问,欢迎扫描下方公众号联系我们哦~

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 如何用大模型Prompt解决行业场景问题?大厂中文教程来了!
科技爆炸,大模型一马当先 生成式 AI 正以惊人的势头改变着我们的世界,新的浪潮席卷着全球各个行业和领域,颠覆了很多人的工作、生活范式。自 PGC、UGC 之后,AIGC 俨然成为炙手可热的内容生产模式。只要你有想法和创造的激情,大模型都能帮助你爆发出巨大能量…
