
摘要:本文重点介绍了基于YOLOv5目标检测系统的MATLAB实现,用于智能检测物体种类并记录和保存结果,对各种物体检测结果可视化,提高目标识别的便捷性和准确性。本文详细阐述了目标检测系统的原理,并给出MATLAB的实现代码、预训练模型,以及GUI界面设计。基于YOLOv5目标检测算法,在界面中可以选择各种图片、文件夹、视频进行检测识别。博文提供了完整的MATLAB代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
- 1. 引言
- 2. 系统界面演示效果
- 3. 检测过程代码
- 4. 系统实现
- 5. 结果分析和优化建议
- 下载链接
- 6. 总结与展望
- 结束语
- 参考文献
➷点击跳转至文末所有涉及的完整代码文件下载页☇
完整代码下载:https://mbd.pub/o/bread/mbd-ZJiYmphw
参考视频演示:https://www.bilibili.com/video/BV1ro4y1w75j/
1. 引言
撰写这篇博客的初衷是分享YOLOv5目标检测算法的实现与应用,为大家提供实践指南。感谢粉丝们的支持。这里我非常鼓励读者深入理解背后原理,发挥创造力,进行探索与尝试,而不是简单地套用现成的解决方案。期待在未来的技术交流中,共同进步与成长。本博客内容为博主原创,相关引用和参考文献我已在文中标注,考虑到可能会有相关研究人员莅临指导,博主的博客这里尽可能以学术期刊的格式撰写,如需参考可引用本博客格式如下:
[1] 思绪无限. 基于YOLOv5的目标检测系统详解[J/OL]. CSDN, 2023.05. https://wuxian.blog.csdn.net/article/details/130472314.
[2] Wu, S. (2023, May). A Comprehensive Guide to Object Detection System Based on YOLOv5 [J/OL]. CSDN. https://wuxian.blog.csdn.net/article/details/130472314.
目标检测作为计算机视觉领域的一个重要研究方向,旨在从图像或视频中检测并识别特定物体(Ren et al., 2015)[1]。近年来,随着深度学习技术的发展,卷积神经网络(CNN)在目标检测领域取得了显著成果。R-CNN(Girshick et al., 2014)[2]是第一个将卷积神经网络应用于目标检测的方法,该方法首先使用选择性搜索生成物体候选框,然后使用CNN对候选框进行特征提取,最后通过支持向量机进行分类。R-CNN相较于传统方法在目标检测任务上取得了较好的性能,但计算速度较慢,无法实现实时检测。
为解决R-CNN速度问题,Girshick提出了Fast R-CNN(Girshick, 2015)[3]。Fast R-CNN通过引入RoI池化层,将物体候选框的特征提取与分类进行联合训练,大幅提高了检测速度。然而,Fast R-CNN仍依赖于选择性搜索生成物体候选框,导致检测速度仍有待提升。Faster R-CNN(Ren et al., 2015)[1]进一步改进了Fast R-CNN,通过引入区域提议网络(RPN),实现了物体候选框生成与特征提取的端到端学习。Faster R-CNN在保持较高精度的同时,取得了更快的检测速度。SSD(Liu et al., 2016)[4]是另一个流行的目标检测方法,通过在不同尺度的特征图上进行检测,实现了对不同尺度物体的高效检测。SSD在速度与精度上达到了较好的平衡,但在小物体检测上性能略逊于Faster R-CNN。
YOLO(You Only Look Once,Redmon et al., 2016)[5]系列算法凭借其实时性和准确性在目标检测领域受到广泛关注。YOLO将目标检测任务视为回归问题,通过单次前向传播实现目标的位置与类别预测。YOLOv2(Redmon and Farhadi, 2017)[8]通过改进网络结构与训练策略,在保持实时性的同时进一步提高了检测精度。YOLOv3(Redmon 和 Farhadi, 2018)[9]采用了多尺度特征融合,引入了类别与物体性(objectness)分离的策略,提高了小物体检测性能。YOLOv4(Bochkovskiy et al., 2020)[7]在YOLOv3的基础上,融合了多种最新的目标检测技术,如CSPNet、PANet和SPP,进一步提高了检测精度与速度。YOLOv5(Bochkovskiy et al., 2020)[6]作为最新版本,在YOLOv4的基础上进行了架构优化,实现了更高的精度与更快的速度。
虽然目前已经有许多基于YOLOv5的目标检测应用,但多数针对特定领域,缺乏统一、易用的界面。因此,本博客将介绍一种基于YOLOv5的目标检测系统,使用MATLAB实现,并提供图形化用户界面(GUI)以便于用户进行交互操作。本博客的贡献点如下:
- 提供了一个基于YOLOv5的通用目标检测系统,支持不同领域的目标检测任务;
- 详细介绍了MATLAB实现的原理,包括预处理、模型加载、预测、结果可视化等;
- 提供了一个易用的GUI界面,支持图片检测、批量检测、视频检测以及调用摄像头检测;
- 允许用户更换不同的网络模型,以满足不同任务的需求;
- 结果可视化方面,通过界面直观显示检测结果,便于用户分析。
2. 系统界面演示效果
本节将介绍基于YOLOv5的目标检测系统的图形化用户界面(GUI)功能及演示效果。
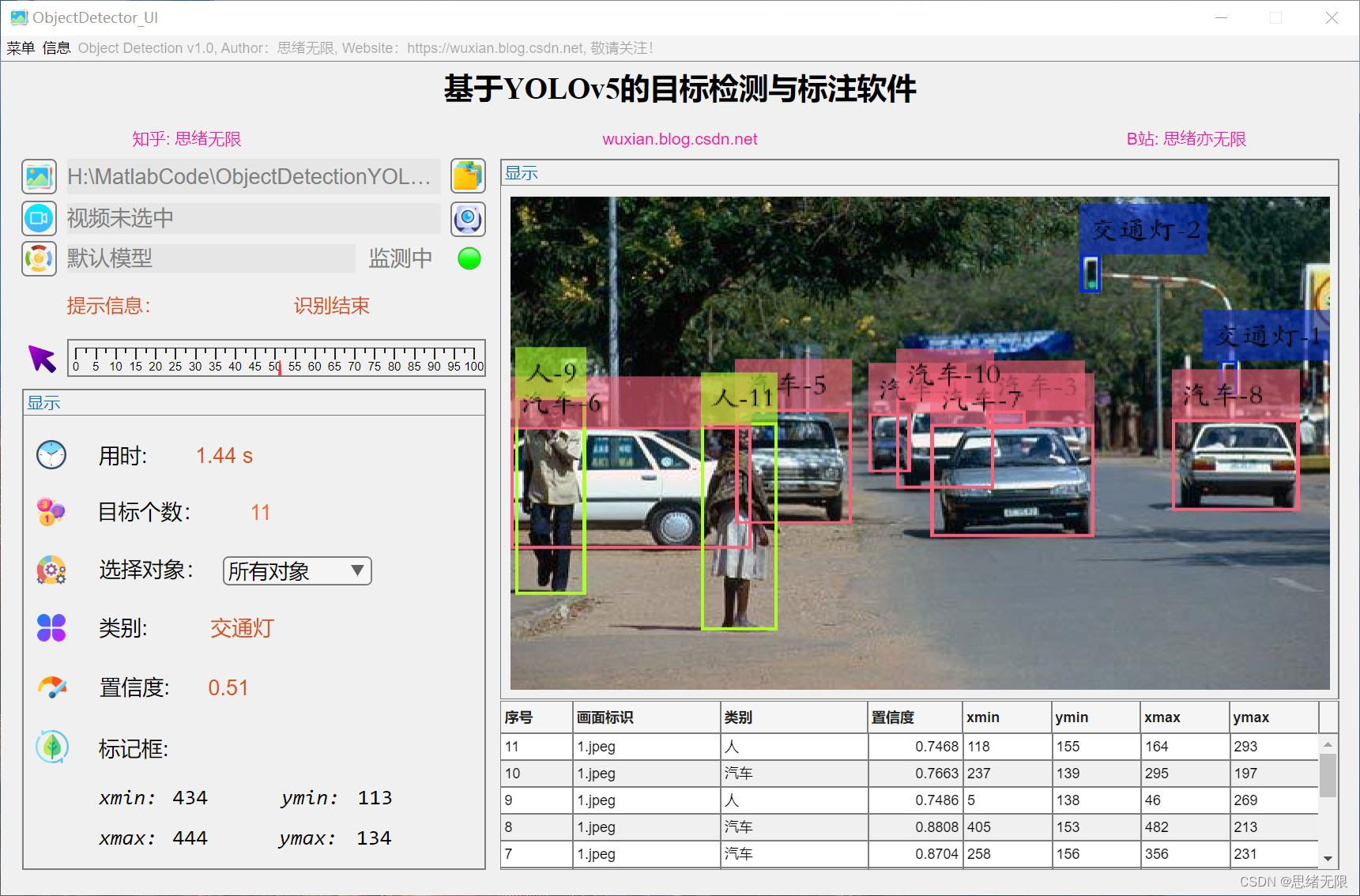
(1)选择图片检测:用户可以通过文件选择对话框选择一张图片进行目标检测。系统会自动将图片调整为合适的尺寸,并将结果显示在GUI界面上。结果包括物体的类别、置信度以及边界框。
(2)选择文件夹批量检测:用户可以选择一个文件夹进行批量检测。系统会自动处理文件夹中的所有图片,并将检测结果记录在下方的表格中。输出结果包括带有边界框和类别标签的图片。
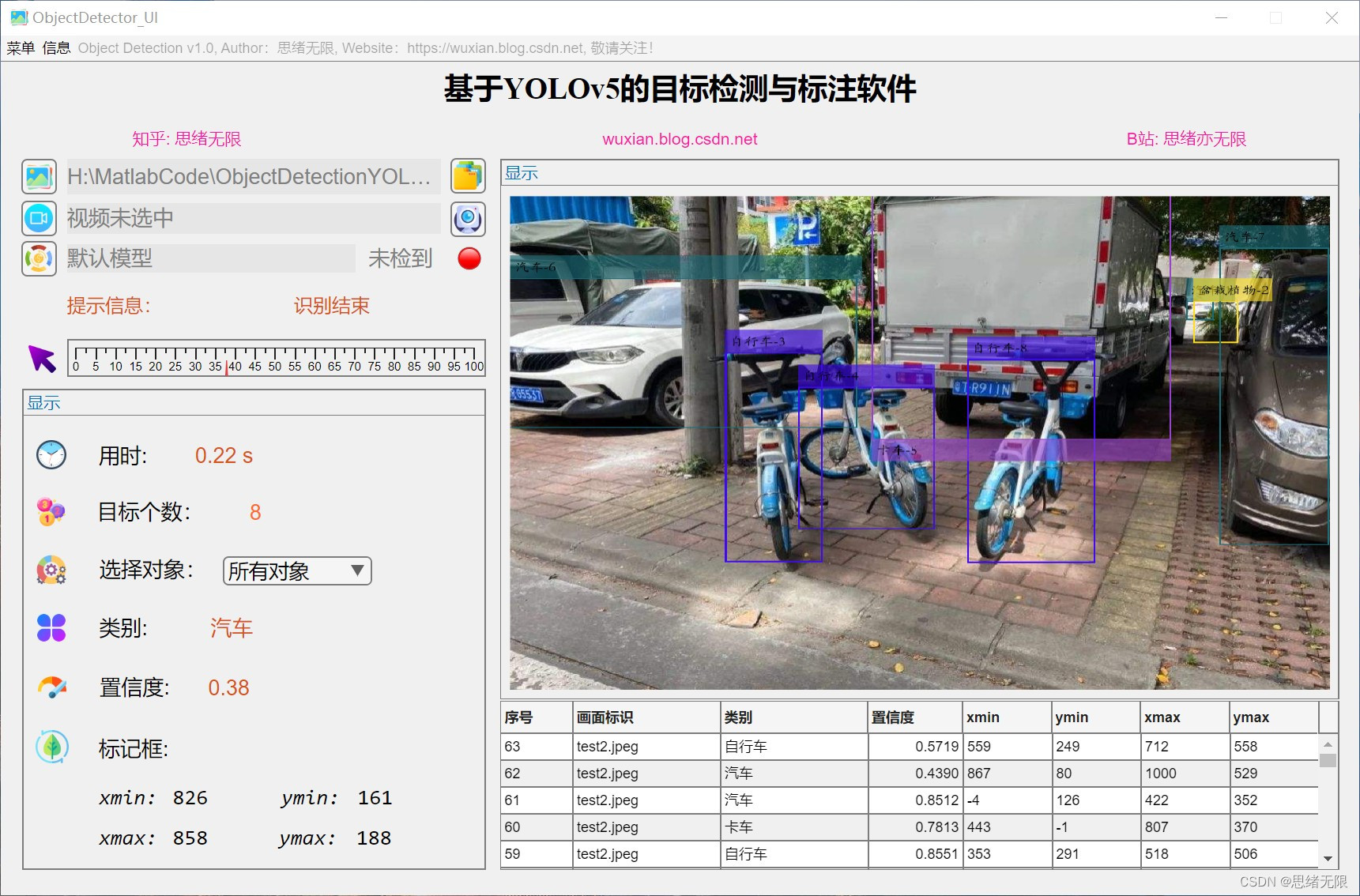
(3)选择视频检测:用户可以选择一个视频文件进行目标检测。系统会对视频中的每一帧图像进行目标检测,并将检测结果实时显示在GUI界面上。同时,用户可以选择将检测结果保存为视频文件。
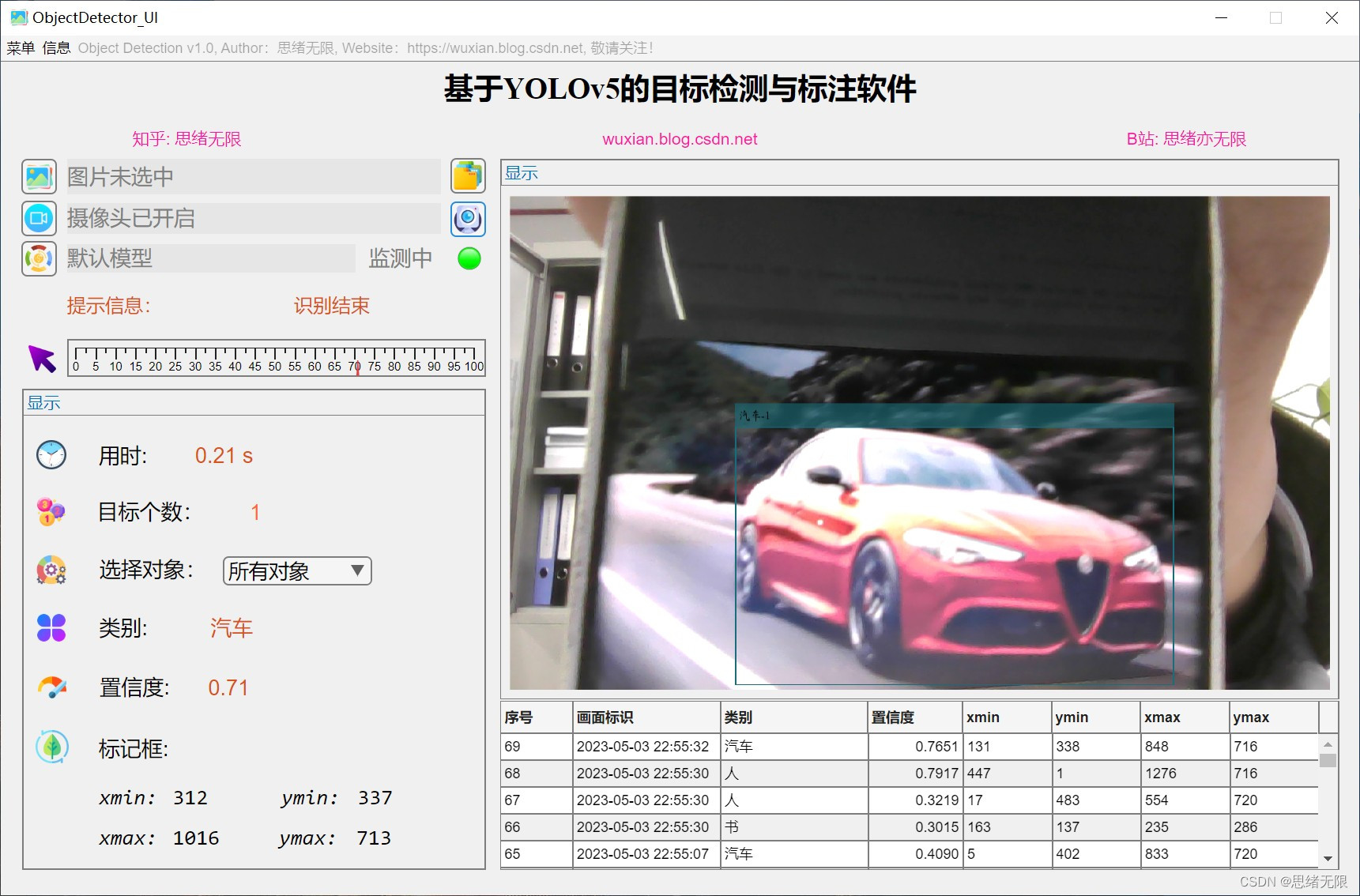
(4)调用摄像头检测:用户可以使用系统内置的摄像头进行实时目标检测。系统会捕捉摄像头的视频流,并对每一帧图像进行目标检测。检测结果将实时显示在GUI界面上。
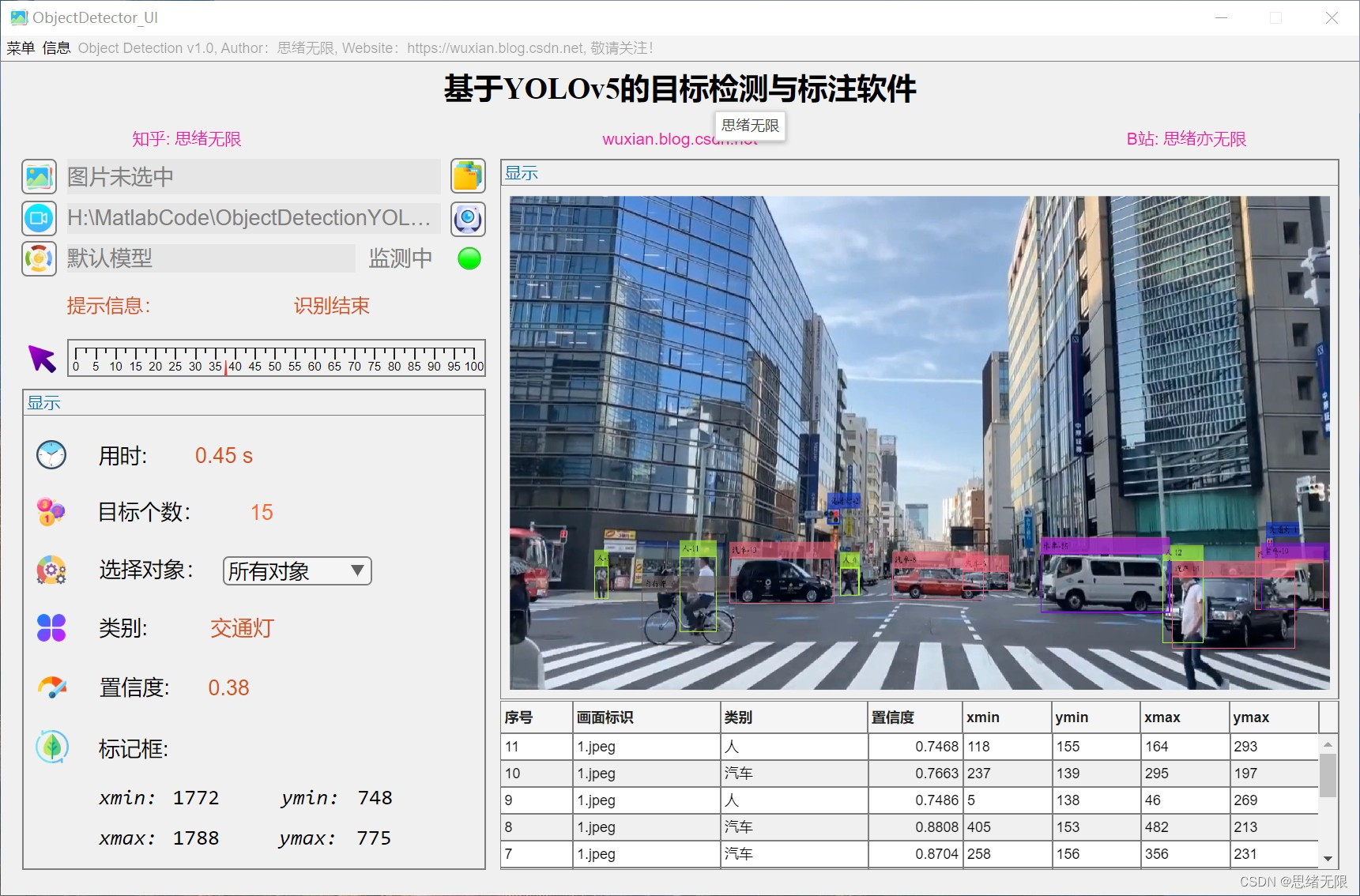
(5)更换不同网络模型:系统支持用户更换不同的YOLOv5网络模型。用户可以根据自己的需求,选择合适的模型进行检测。不同的模型在精度和速度上可能存在差异。
(6)通过界面显示结果和可视化:系统的GUI界面提供了直观的结果展示和可视化功能。用户可以清晰地查看检测到的物体、边界框、类别以及置信度。

3. 检测过程代码
首先,创建一个名为Detector_YOLOv5的类,它封装了执行目标检测的所有方法。以下是类的主要组成部分:
属性(Properties):类的属性定义了检测器所需的信息,例如类别名称(COCO数据集中的80个类别)、权重文件、置信度阈值、非极大值抑制(NMS)阈值和各类别的颜色;方法(Methods):类的方法定义了实现目标检测的功能。构造函数(Detector_YOLOv5)在初始化时加载预训练的YOLOv5模型。detect方法对给定的图像执行目标检测,代码还包括一些常量属性。
classdef Detector_YOLOv5 接下来,详细介绍detect方法的实现:
- 图像预处理:输入图像被调整为YOLOv5所需的尺寸(例如,640×640像素),然后将其归一化并调整维度以适应模型输入要求。
- 模型推理:将预处理后的图像传递给networks_yolov5sfcn函数,该函数使用预训练的YOLOv5模型计算预测结果。
- 后处理:根据预设的置信度阈值筛选预测结果。使用非极大值抑制(NMS)来合并重叠的边界框。
- 结果输出:将预测结果(边界框、分数和类别标签)返回给调用者。
methods % 方法块开始
%构造函数,特点也是和类同名
function obj = Detector_YOLOv5(model, model_fcn)
if nargin == 2
% 导入模型
obj.colors = randi(255, length(obj.cocoNames),3);
obj.weights = importONNXFunction(model, model_fcn);
obj.class_names = categorical(obj.cocoNames_Chinese); % 类别标签
end
end
% 成员方法,执行预测
function [bboxes, scores, labels] = detect(obj, image)
% 使用YOLOv5进行预测
% 预处理图像
[H,W,~] = size(image);
image = imresize(image, obj.input_size);
image = rescale(image, 0, 1);% 转换到[0,1]
image = permute(image,[3,1,2]);
image = dlarray(reshape(image,[1,size(image)])); % n*c*h*w,[0,1],RGB顺序
if canUseGPU()
image = gpuArray(image);
end
% 模型推理
[labels, bboxes] = networks_yolov5sfcn(image, obj.weights,...
'Training',false,...
'InputDataPermutation','none',...
'OutputDataPermutation','none');
% 后处理: 阈值过滤+NMS
if canUseGPU()
labels = gather(extractdata(labels));
bboxes = gather(extractdata(bboxes));
end
[maxvalue,idxs] = max(labels,[],2);
validIdxs = maxvalue>obj.throushHold;
% nms
indexes = idxs(validIdxs);
predictBoxes = bboxes(validIdxs,:);
predictScores = maxvalue(validIdxs);
predictNames = obj.class_names(indexes);
predictBboxes = [predictBoxes(:,1)*W-predictBoxes(:,3)*W/2,...
predictBoxes(:,2)*H- predictBoxes(:,4)*H/2,...
predictBoxes(:,3)*W,...
predictBoxes(:,4)*H];
% 结果输出
[bboxes,scores,labels] = selectStrongestBboxMulticlass(predictBboxes,...
predictScores,...
predictNames,...
'RatioType','Min',...
'OverlapThreshold', obj.nmsThroushHold);
end
end % 方法块结束
这里给出如何使用Detector_YOLOv5类对图像进行目标检测。首先加载模型,然后创建检测器实例。接着,读取图像,执行检测并可视化结果(在图像上绘制边界框、类别标签和置信度)。最后,将标注后的图像保存到文件。这里讲解如何使用已经训练好的YOLOv5 ONNX模型进行目标检测。首先加载模型并创建检测器实例:
model = './yolov5s_no.onnx'; % 模型位置
yolov5 = Detector_YOLOv5(model, 'networks_yolov5sfcn');
首先,定义模型文件的路径,这里使用了预训练好的YOLOv5 ONNX模型。接着,利用Detector_YOLOv5类创建一个检测器实例。networks_yolov5sfcn是一个MATLAB导入的ONNX模型的函数,用于实现YOLOv5模型的前向传播。下面读取待检测的图像:
image_path = './test_/000328.jpg';
image = imread(image_path);
指定待检测图像的路径,并使用imread函数读取图像。使用检测器进行目标检测:
tic
[bboxes, scores, labels] = yolov5.detect(image)
fprintf('预测时间: %0.2f s',toc);

调用detect方法对读取的图像进行目标检测。detect方法返回三个输出:边界框(bboxes)、置信度得分(scores)和类别标签(labels)。同时,使用tic和toc函数计算检测所需的时间。绘制检测结果并保存标注后的图像:
annotations = string(labels) + ": " + string(round(scores*100)) + '%';
[~, ids] = ismember(labels, classesNames);
labelColors = colors(ids,:);
labeled_image = insertObjectAnnotation(image,'rectangle',bboxes,...
cellstr(annotations),...
'Font','华文楷体', ...
'FontSize', 18, ...
'color', labelColors,...
'LineWidth',2);
imshow(labeled_image);
imwrite(labeled_image, 'labeled_image.png'); % 保存标记的图片

将检测结果(类别标签、置信度得分和边界框)添加到图像上。首先,为每个检测到的目标生成一个包含类别标签和置信度的字符串(annotations)。然后,根据类别标签确定对应的颜色。接着,使用insertObjectAnnotation函数将检测结果绘制到图像上,并使用imshow函数显示标注后的图像。最后,使用imwrite函数将标注后的图像保存到文件。
4. 系统实现
本节将详细介绍基于YOLOv5的目标检测系统的设计框架和实现方法。系统主要分为两个部分:预测部分和图形用户界面(GUI)部分。预测部分主要包括图片、文件夹分类、模型更换等功能。GUI部分则包含各种操作按钮和可视化结果展示。在设计GUI界面时,需要考虑如下几个方面:
- 界面布局:设计一个清晰、易于使用的界面布局,便于用户进行各种操作。
- 功能实现:实现用户在界面上执行的各种操作,例如选择图片、文件夹分类、模型更换等。
- 可视化结果展示:将检测结果以图形或文本的形式展示在界面上,便于用户查看和分析。
基于以上要求,可以设计一个包含以下功能的GUI界面:
- 选择图片检测:用户可以通过点击按钮选择一张图片进行目标检测。
- 选择文件夹批量检测:用户可以选择一个文件夹,对文件夹中的所有图片进行目标检测。
- 选择视频检测:用户可以选择一个视频文件,对视频中的每一帧进行目标检测。 调用摄像头检测:用户可以使用摄像头实时进行目标检测。
- 更换不同网络模型:用户可以在多个预训练模型之间进行切换,以满足不同场景的需求。
- 通过界面显示结果和可视化:将检测结果以图形或文本的形式展示在界面上。
为了实现上述功能,可以使用MATLAB的App Designer工具来创建GUI界面。App Designer是一个基于MATLAB语言的交互式开发环境,可以方便地设计和创建具有各种功能的图形用户界面。以下是使用App Designer创建的基于YOLOv5的目标检测系统的GUI界面实现步骤:
打开MATLAB,选择App Designer工具创建一个新的项目。
- 在设计界面中添加各种组件,例如按钮、文本框、图像框等。设置组件的属性和样式,以满足界面设计要求。
- 编写各个组件的回调函数,实现相应的功能。例如,点击“选择图片检测”按钮时,弹出文件选择对话框,让用户选择一张图片进行检测;点击“调用摄像头检测”按钮时,启动摄像头并实时显示检测结果。
- 在回调函数中调用YOLOv5目标检测算法,获取检测结果,并将结果显示在界面上。例如,将检测到的目标用矩形框标记,并在图像框中显示;将检测到的目标类别和置信度以文本的形式显示在文本框中。
- 根据需要,添加其他功能和组件,例如模型切换功能。在界面中添加一个下拉菜单,列出可用的预训练模型。当用户在下拉菜单中选择一个模型时,更新回调函数中的模型参数,以使用新的模型进行检测。
- 完成界面设计和功能实现后,保存并运行项目。在运行界面中测试各个功能,确保功能正常运行并满足需求。
对于需要进一步优化的功能,可以在App Designer的代码视图中进行修改和调整。例如,优化检测算法的性能,提高实时检测的帧率;调整界面布局,使其更美观易用。
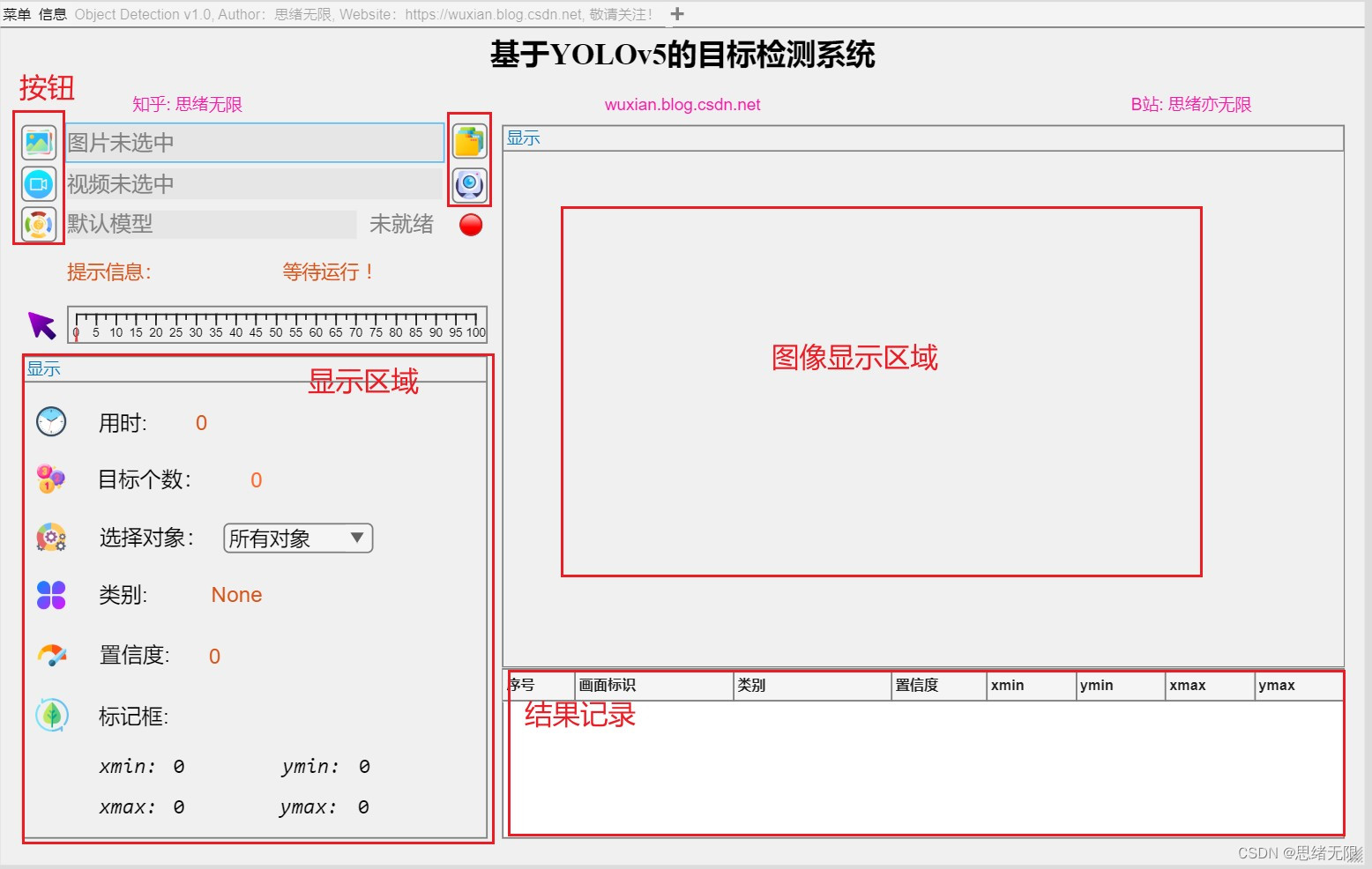
通过以上步骤,可以实现一个基于YOLOv5的目标检测系统的GUI界面。用户可以通过界面方便地选择图片、文件夹或视频进行目标检测,并在界面上查看和分析检测结果。同时,用户还可以根据不同场景的需求,切换不同的预训练模型进行检测。
5. 结果分析和优化建议
在本节中,将对YOLOv5目标检测算法的检测结果进行分析,并提出一些建议以优化其性能。
结果分析:通过使用预训练的YOLOv5模型进行目标检测,可以观察到以下特点
- 检测速度:YOLOv5具有较快的检测速度,这对于实时应用非常重要。尤其是在GPU加速的情况下,检测速度可以达到实时水平。
- 准确性:YOLOv5的检测准确性相对较高,可以在各种场景中准确检测出目标物体。然而,在一些复杂场景中,例如目标遮挡、小目标和低分辨率情况下,检测性能可能会受到影响。
- 通用性:YOLOv5能够检测多达80个类别的目标,具有较高的通用性。然而,对于一些特定的应用场景,可能需要在特定的数据集上进行微调,以提高检测性能。
针对YOLOv5目标检测算法的特点,提出以下优化建议:
模型微调:为了提高YOLOv5在特定应用场景的检测性能,可以在相关数据集上对模型进行微调。通过在有限的训练数据上进行微调,模型可以更好地适应新的场景,从而提高检测准确性。
数据增强:在训练过程中,使用数据增强技术可以提高模型的泛化能力。例如,可以使用图像旋转、缩放、翻转、裁剪等方法扩充训练集。数据增强有助于模型学习到更多的特征,提高检测性能。
模型融合:在一些复杂场景下,可以考虑将多个检测模型进行融合,以提高检测准确性。例如,可以将YOLOv5与其他目标检测算法(如Faster R-CNN、SSD等)进行融合,综合利用各自的优势,提高整体检测性能。
多尺度检测:针对不同尺寸的目标,可以考虑使用多尺度检测策略。通过将输入图像调整到不同的尺寸,可以在不同的尺度上进行目标检测,从而提高检测准确性。
根据实际应用场景的需求,可以对YOLOv5进行一定程度的调整以满足特定场景的要求:
自定义类别:根据实际应用需求,可以对YOLOv5进行修改,以检测特定类别的目标。这需要重新训练模型,使其能够识别和检测自定义类别的物体。
减小模型规模:为了适应边缘设备(如移动设备、嵌入式设备等)上的计算能力限制,可以考虑减小YOLOv5模型的规模。通过降低模型的层数、通道数等参数,可以降低模型的计算复杂度,提高在边缘设备上的运行速度。需要注意的是,这可能会对检测性能产生一定影响。
模型压缩和优化:为了进一步提高模型在边缘设备上的运行速度和内存占用,可以采用模型压缩和优化技术,如模型剪枝、模型量化等。这些方法可以降低模型的计算复杂度和内存占用,提高运行速度,但可能对检测性能产生一定影响。
实时检测优化:在进行实时目标检测时,可以考虑采用滑动窗口、跟踪等技术,减少重复检测区域,提高检测速度。此外,还可以结合场景信息,对感兴趣区域进行优先检测,从而提高检测效率。
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,mlx, mlapp文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
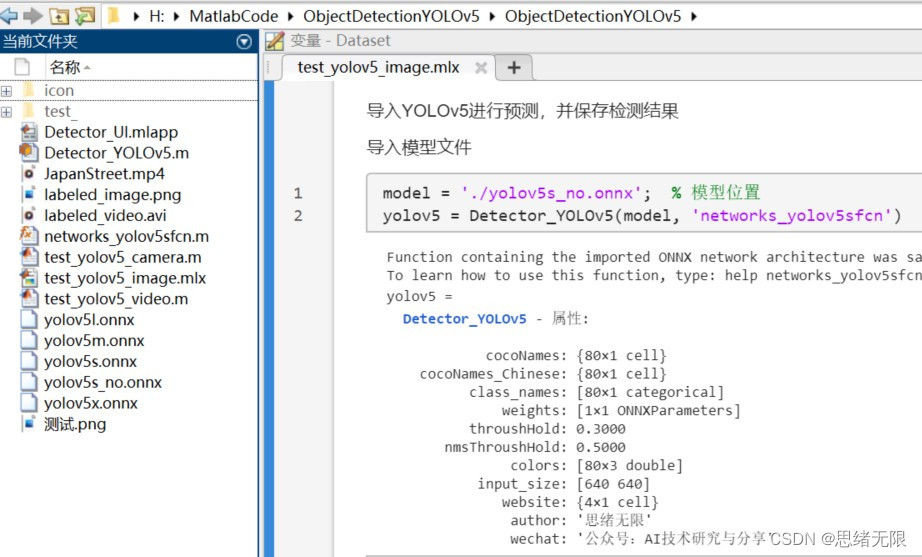
在文件夹下的资源显示如下图所示:
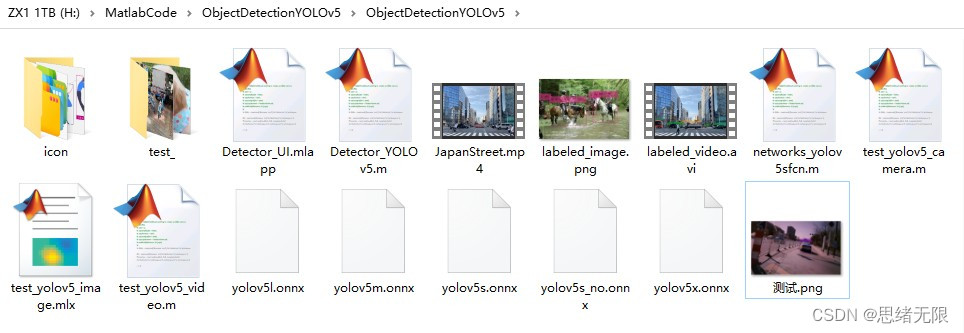
注意:该代码采用MATLAB R2022a开发,经过测试能成功运行,运行界面的主程序为Detector_UI.mlapp,测试视频脚本可运行test_yolov5_video.py,测试摄像头脚本可运行test_yolov5_camera.mlx。为确保程序顺利运行,请使用MATLAB2022a运行并在“附加功能管理器”(MATLAB的上方菜单栏->主页->附加功能->管理附加功能)中添加有以下工具。
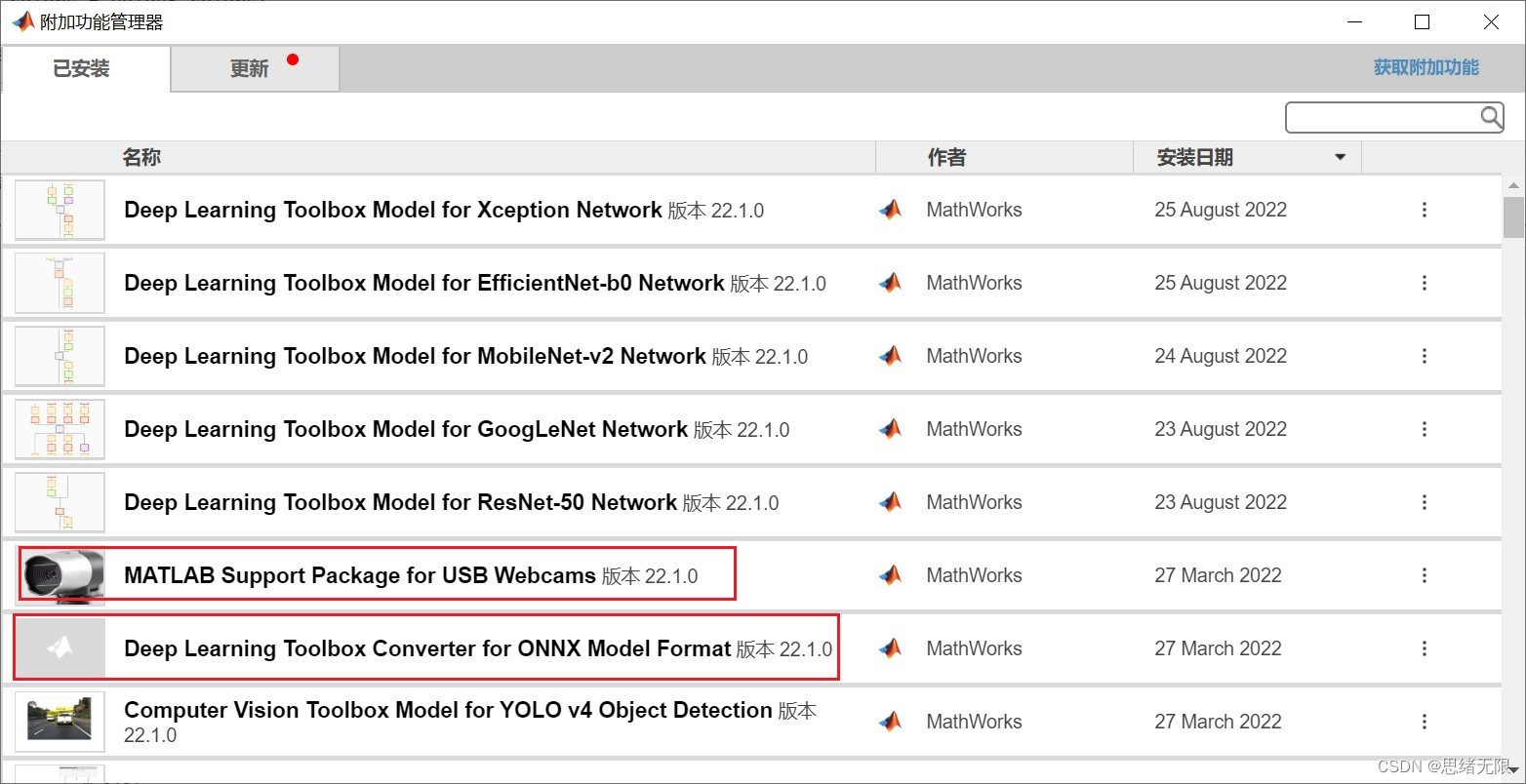
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见参考博客文章里面,或参考视频的简介处给出:➷➷➷
完整代码下载:https://mbd.pub/o/bread/mbd-ZJiYmphw
参考视频演示:https://www.bilibili.com/video/BV1ro4y1w75j/
6. 总结与展望
本文详细介绍了YOLOv5目标检测算法的原理、网络结构及其在实际应用中的优化方法。YOLOv5作为一个高效、实时的目标检测算法,在各种场景中都表现出较好的性能。首先介绍了YOLOv5的背景知识,包括YOLO系列算法的发展历程和YOLOv5相较于前代算法的改进。接着,详细阐述了YOLOv5的网络结构和损失函数设计,并通过实际代码实现展示了如何使用YOLOv5进行目标检测。最后,讨论了针对实际应用场景的优化方法,以提高YOLOv5在各种场景中的目标检测能力。总的来说,YOLOv5是一个值得学习和应用的目标检测算法。通过对其进行一定程度的调整和优化,可以使其更好地满足实际应用场景的需求,提高目标检测的效果和效率。
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
参考文献
[1] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28, 91-99.
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580-587.
[3] Girshick, R. (2015). Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision, 1440-1448.
[4] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. European Conference on Computer Vision, 9905, 21-37.
[5] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 779-788.
[6] Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). YOLOv5: An improved real-time object detection model. arXiv preprint arXiv:2006.05983.
[7] Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
[8] Redmon, J., & Farhadi, A. (2017). YOLO9000: Better, faster, stronger. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7263-7271.
[9] Redmon, J., & Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
