

一、背景
在 B 端研发过程中,产品原型在产品需求文档中起着重要的作用。然而,在实际的开发过程中,我们发现了一些问题。首先,在需求评审阶段,有些产品需求文档可能缺少原型或者原型与研发团队的规范不一致,这需要研发同学与产品同学沟通补充原型图或者按照研发团队的规范进行绘制,这增加了产品同学和研发团队之间的沟通成本以及增加了产品同学的学习成本。其次,在业务验收阶段,开发的页面或效果可能不符合业务侧的期望,这又需要产品和研发团队反复沟通,导致业务侧对效果的感知链路过长。此外,产品同学还需要花费大量时间来根据需求文档描述输出样式固定的原型文档。
为了解决这些问题,我们想到了利用产品在『市场需求文档(MRD)——产品需求文档(PRD)——页面(Page)』沟通过程中沉淀的『共识』,即产品需求文档中的页面描述。我们可以利用大语言模型强大的推理能力,将这些共识『翻译』成符合研发团队规范的页面,从而减少沟通成本并缩短业务侧对效果的感知链路。另外,为了减少产品在不同界面切换频次,可以让产品利用浏览器插件在 PRD 文档页面进行文字选择,然后唤起原型生成工具生成页面原型和修改原型。本文主要介绍了我们利用大模型辅助产品同学生成页面原型的实践经验。
二、流程设计
一般来说,产品同学是根据业务同学或者运营同学的 MRD 来细化产品需求。如果业务有视觉要求,则会由设计同学负责产品的界面和交互设计,否则由产品同学利用常见市面上常见的原型工具来设计界面和交互。我们自研的智能原型工具的定位是作为产品同学在原型设计时的可选工具,且不改变产品的原有工作流。基于此,我们设计了如下原型生成流程: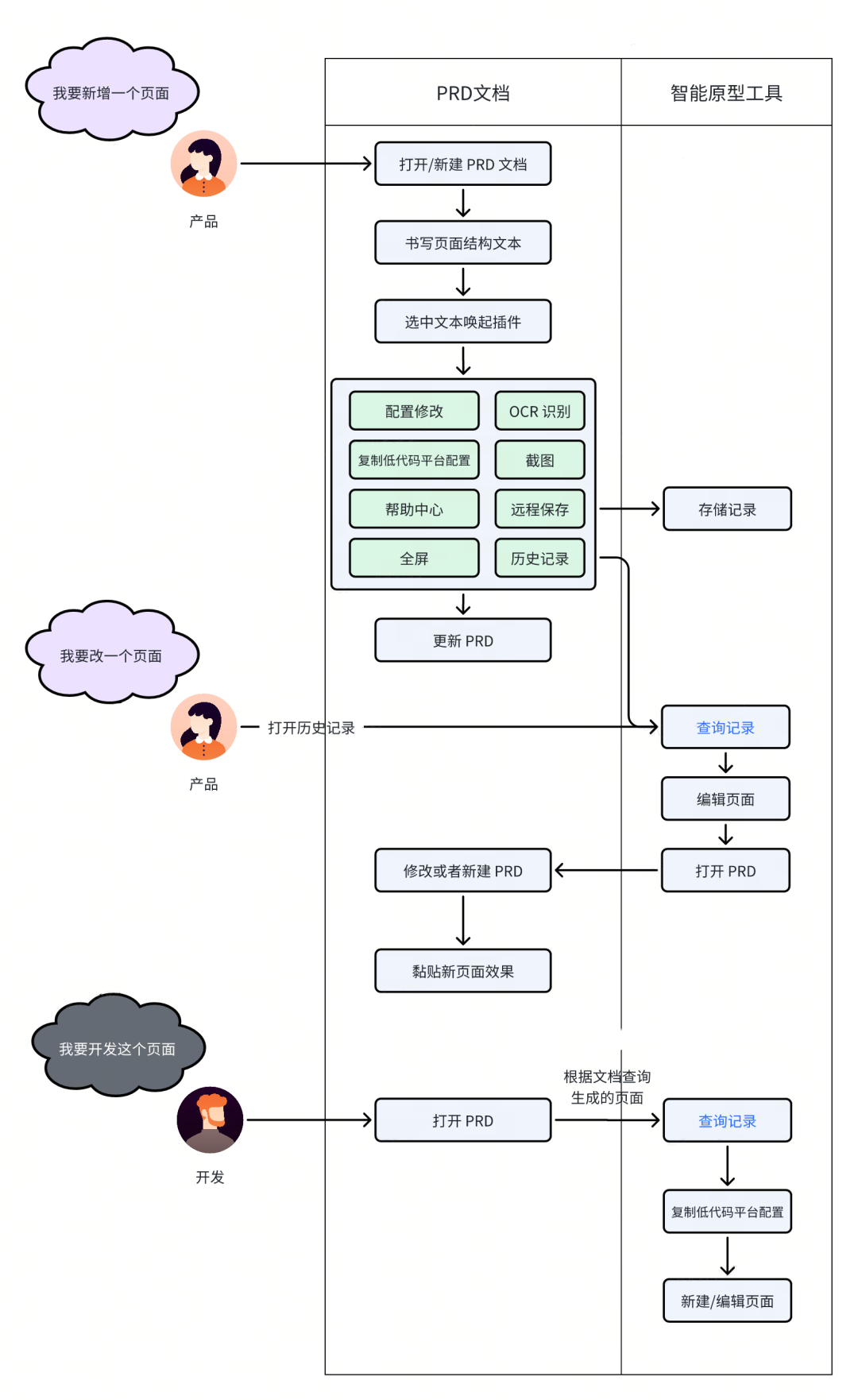
该流程主要是将用户利用常见市面上常见的原型工具变成利用智能原型工具插件选中 PRD 文档中的产品描述,利用 LLM 基于得物自研低代码平台配置规范生成原型图。产品同学工作的空间还是在文档中,不用切换到其他软件或者界面,即可利用 Chrome 插件来生成原型。产品同学保存生成的记录后,可以供自己查询,也可以供业务同学查看效果,还可以供研发同学快速开发使用。
三、实现原理
智能原型工具将产品所写的页面描述、修改指令、拖拽动作作为输入,低代码领域知识作为补充,大模型或可视化编辑器作为处理器,低代码 SDK 作为渲染器,页面原型作为输出。智能页面原型工具从输入到输出的具体实现原理如图所示: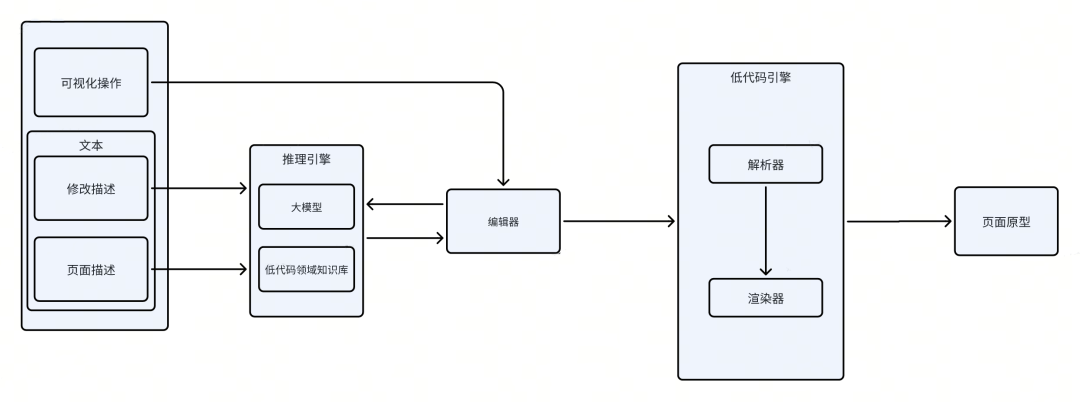
四、架构设计
根据上述生成流程设计,我们设计的产品原型生成分层架构如图所示: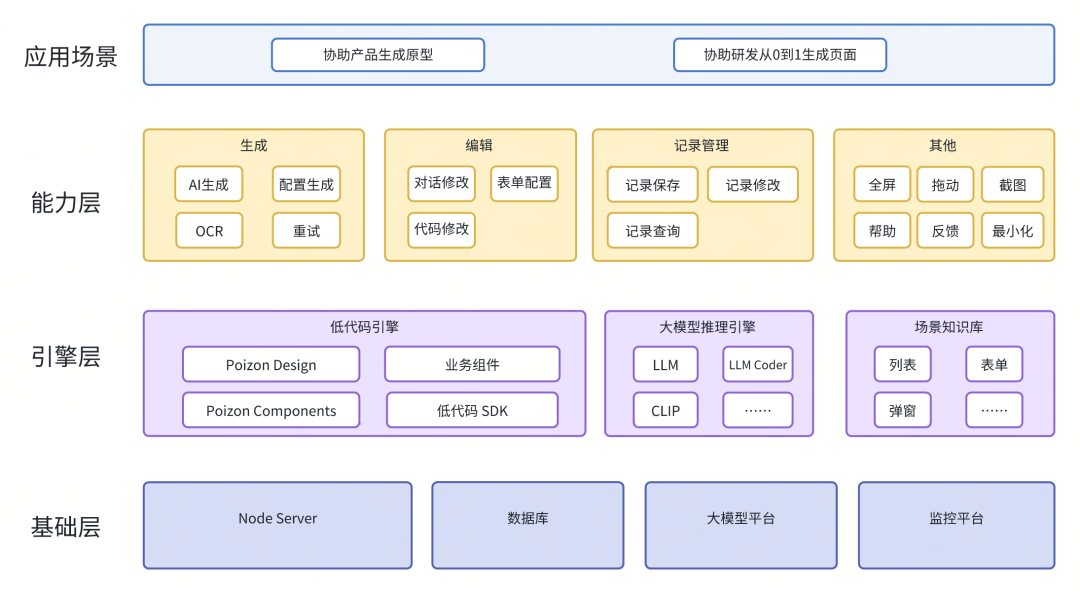
产品原型生成工具的架构可以分为四层,分别是应用场景、能力层、引擎层和基础层,具体如下:
-
应用场景:主要是产品同学利用智能页面原型工具生成原型和研发利用原型对应低代码平台配置完成从0到1的页面开发。
-
能力层:则是辅助产品同学生产原型的能力集合。这些能力支撑了产品快速生成、快速修改原型,生成内容可以管理,不影响产品同学使用流程等场景。
-
引擎层:是得物自研低代码引擎和推理引擎,是生成原型配置和渲染配置的发动机。得物自研低代码引擎不仅包括得物自研低代码SDK,还有得物B端组件Poizon Design、精品组件Poizon Components以及业务组件。推理引擎则包括文生文的通用模型、图生文的通用模型、生成低代码平台配置的Coder模型。推理引擎部署在得物自研大模型平台上。选择使用内部部署大模型的原因是,调用外部模型有数据泄露风险,外部模型API有一定稳定性风险,训练成本较高。场景知识库是依据对内部各业务域的PRD进行分析得到的高频场景而构建的。目前场景知识库已包含了列表、表单、弹窗等等高频场景。
-
基础层:则是产品原型智能生成工具的接口服务、记录存储、模型部署和监控。
五、实践效果
界面展示
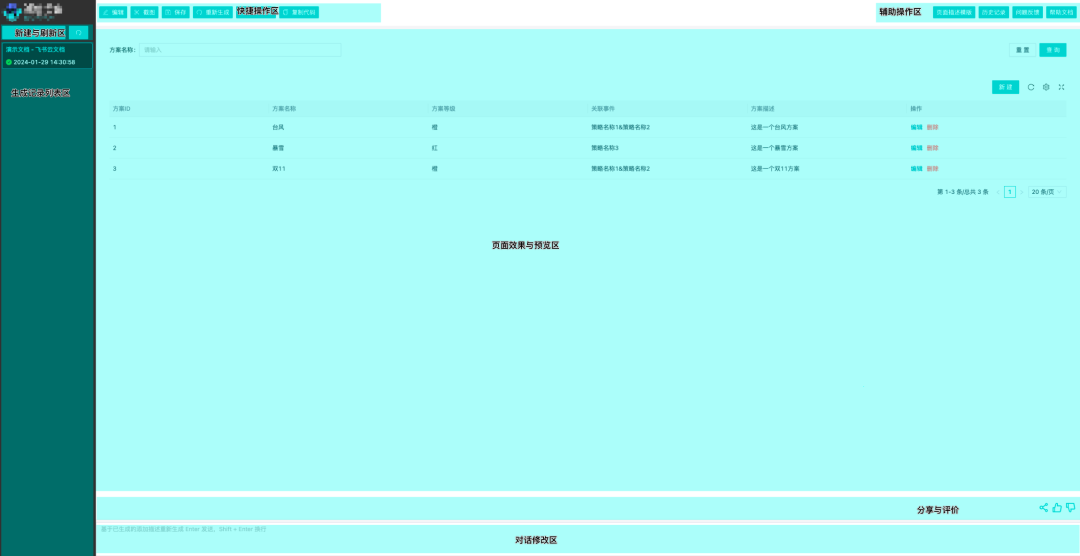
下图是界面原型智能生成工具的主界面,主要包括新建与刷新区、生成记录列表区、快捷操作区、辅助操作区、页面效果预览区、分享与评价区、对话修改区,具体如下:
- 新建与刷新区主要是在当前界面直接配置页面原型、服务器托管网根据页面描述智能生成界面原型以及刷新生成记录列表。
- 生成记录列表区主要是展示生成的界面原型关联的 PRD、原型描述、生成时间。
- 快捷操作区是界面原型编辑、截图、保存、重新生成、低代码平台配置编辑、复制低代码平台配置等操作的快捷按钮。
- 辅助操作区是界面描述模板、历史记录、问题反馈、帮助文档等帮助按钮。
- 页面效果与预览区是生成的原型展示区域,原型是可以交互操作的。
- 分享与评价是方便产品同学将生成的原型分享给业务或研发同学预览以及可以对智能生成的原型质量做评价帮助提升模型生成的准确性。
- 对话修改区是方便产品同学通过对话形式来利用模型对生成的界面原型做修改。
使用效果
下面视频中展示了从 PRD 文档到页面原型的过程。从视频中可以看到,智能原型生成工具支持对生成的原型进行微调,还生成了相对应的低代码平台配置。
落地情况
智能原型工具生成原型的用时在 15 秒以内,具备生成记录可查、可修改。同时,智能原型工具已实现关键使用链路埋点,可以及时发现产品同学使用卡点。目前内部已有较多的产品同学正在使用智能原型工具生成 B 端页面原型。通过与产品同学的沟通,收到的使用反馈总体体验是正向的。也有产品同学参与共建智能原型工具。
六、后续规划
-
场景扩展:目前,智能原型工具主要支持表单、列表、弹窗等等高频场服务器托管网景,后续将支持复杂表单、复杂列表、图表等等产品同学在工作中会涉及的页面场景。
-
大模型训练:在上文中可以看到模型是智能原型工具的加速器,但目前只用到了大模型的推理能力,需要外挂知识库才能生成符合规范的页面原型。这制约了生成原型的生成速度和扩展性。后续将利用工程化手段对得物自研低代码平台的使用教程、示例、用户使用数据等数据做结构化处理,然后利用大模型和知识库生成训练数据,对通用大模型进行微调,得到智能原型工具模型。同时,将训练过程工程化和自动化。从而进一步提升原型生成效率和质量,批量覆盖更多场景。模型训练思路如图所示:

-
优化 MRD2PRD2Code 链路:与自研低代码平台协同,缩短 MRD2PRD2Code 链路,使每一个产研链路中的每个节点的结论都可以得到一个可见的结果,从而进一步减少沟通成本与提升交付效率。
-
Web2Code 链路:Web2Code 主要是为了产品同学需要对老页面做修改的场景,产品同学打开老页面即可生成原型,然后在生成原型上做修改。
-
编辑功能增强:上文中提到智能原型工具的编辑功能是通过表单配置来对大模型生成的低代码平台配置进行修改,还不够灵活,后续组件拖拽式编辑功能。另外,支持产品通过组件拖拽生成原型以及相应产品描述功能。
*文/bigboy
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
非负矩阵分解(NMF) sklearn.decomposition.NMF 找出两个非负矩阵,即包含所有非负元素(W,H)的矩阵,其乘积近似于非负矩阵x。这种因式分解可用于例如降维、源分离或主题提取。 主成分分析(PCA) sklearn.decomposi服…
