
1. 引言
在过去的十年里,出现了许多涉及计算机视觉的项目,举例如下:
- 使用射线图像和其他医学图像领域的医学诊断应用
- 使用导航图像分析建筑物和土地利用率相关应用
- 各种环境下的目标检测和跟踪,如交通流统计、自然环境垃圾检测估计等

上述应用所采用的计算机视觉的方法遵循统一的标准流程:
- 首先定义需要解决的问题所属类别(分类、检测、跟踪、分割) 以及相应输入数据的分辨率等
- 接着需要人工标注数据
- 选择一个网络进行训练,验证和进行一些统计值分析服务器托管网
- 建立推理脚本并进行部署
到2023年底,人工智能领域迎来了来自生成式AI的新爆发:大语言模型(LLM)和图像生成式模型。每个人都在谈论它,那么它对计算机视觉领域的应用有什么改变呢?本文我们将探索是否可以利用它们来构建数据集,以及如何利用新的架构和新的预训练权重,或者从大模型中进行蒸馏学习。
2. 理想的计算机视觉应用开发
在工业界,我们通常感兴趣的是可以以相对较小的成本来构建和部署计算机视觉相关应用,小规模计算机视觉特性如下:
- 小规模计算机视觉开发成本不应过高
- 它不应该需要庞大的基础设施来训练(想想算力和数据规模)
- 它不需要具备强大的研究技能,而是现有技术的扩展应用
- 推理应该是轻量化和快速的,这样它就可以在嵌入式或部署在CPU/GPU服务器上
小规模计算机视觉显然不是当今人工智能的趋势,因为我们看到具有数十亿参数的模型开始成为一些应用程序的标准设计。我们听到了很多关于这方面的消息,但重要的是要记住,关注较小的规模在某些场景的应用也是至关重要的,并不是所有项目都应该遵循谷歌、Meta、OpenAI或微软的大模型规模趋势。事实上,大多数有趣的计算机视觉项目实际上比那些成为头条新闻的项目规模要小得多。
考虑到这一点,我们还能利用人工智能的最新发展来进行相关应用开发吗?首先让我们深入了解下计算机视觉下的基础模型。
3. 计算机视觉基础模型
最近的大语言模型(LLM)非常流行,因为大家可以轻松地在应用程序中使用基础模型(许多是开源的,或者可以通过API使用), 事实上大家也可以把GPT、Bert、Llama想象成这样的提取文本特征的基础模型。基础模型是一个非常大的通用神经网络,可作为大多数下游任务的基础。它包含了关于非常广泛的主题、语义、语法等的知识。
类比到计算机视觉领域中,我们已经使用这样的模型有一段时间了:在过去的10年里,使用在ImageNet上预先训练的神经网络(100万张标记的图像)作为下游任务的“基础”模型是标准的训练流程。大家可以在上面建立自己的神经网络,如果需要的话,可以根据自己的数据对其进行微调。
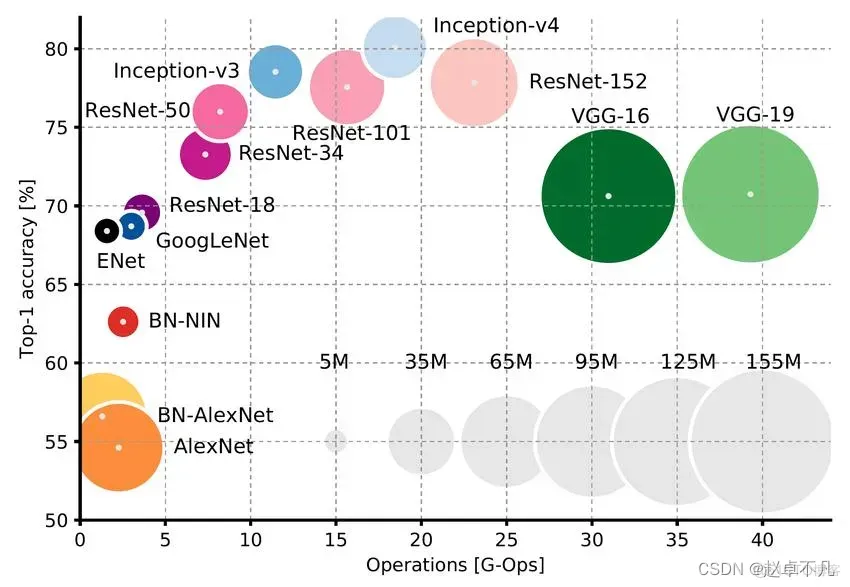
ImageNet上预训练的视觉网络和大语言预训练模型LLM之间有两个主要的概念上的差异:
- 训练二者的数据类型不同:ImageNet上视觉网络的训练依赖于纯有监督学习,一个1000个类别的分类任务;然而
LLM属于生成式模型,它们是使用原始文本以自监督的方式进行训练的(任务通常为预测下一个单词) - 这些基础模型对新任务的适应:ImageNet上预训练网络需要新的学习过程来适应新任务。对于LLM,虽然也可以对模型进行微调,但该模型足够强大,通常可以直接用于下游任务,而无需做进一步的训练,只需提供给模型正确的提示信息,使其对新任务有用
目前大多数计算机视觉应用,如分类、目标检测、语义分割等任务,仍然使用ImageNet预训练网络的权重。让我们回顾一下最近推出的新模型,这些模型可能对我们的计算机视觉任务有用。
4. 大规模视觉模型
在计算机视觉的世界里,除了ImageNet外,今年来有很多自监督网络的例子,其中一些是生成式模型(想想最新的GAN和最近大火的扩散模型)。它们仅在原始图像或图像-文本对(例如图像及其描述)上进行训练。它们通常被称为LVM(大规模视觉模型)。
- DINOV2: 一组大型ViT集合(视觉transformer,1B参数量),明确旨在成为计算机视觉的良好基础模型,即这样的模型可以提取一些通用的视觉特征,也就是说,这些特征适用于不同的图像任务,无需进行进一步的微调即可使用, 而且它以完全自监督的方式进行训练。

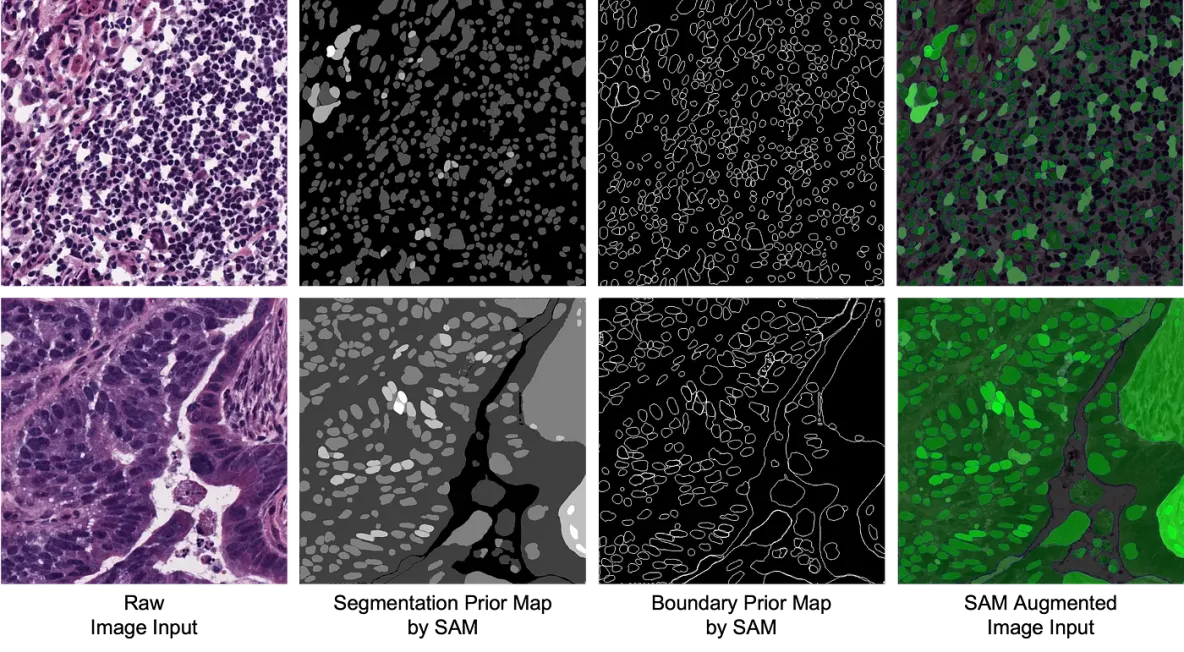
- SAM: 一个致力于高分辨率图像的ViT,专门设计用于分割,并实现零样本分割(无需注释即可生成新的分割mask)。使用LoRA可以廉价地“微调”SAM,从而大幅减少必要的训练图像数量。另一个用例是使用SAM作为医学图像分割中的补充输入。
5. 图文大模型
图文大模型的主要以图像文本对作为模型的输入,这类模型随着对比学习的快速发展也得到了迅速的崛起,举例如下:
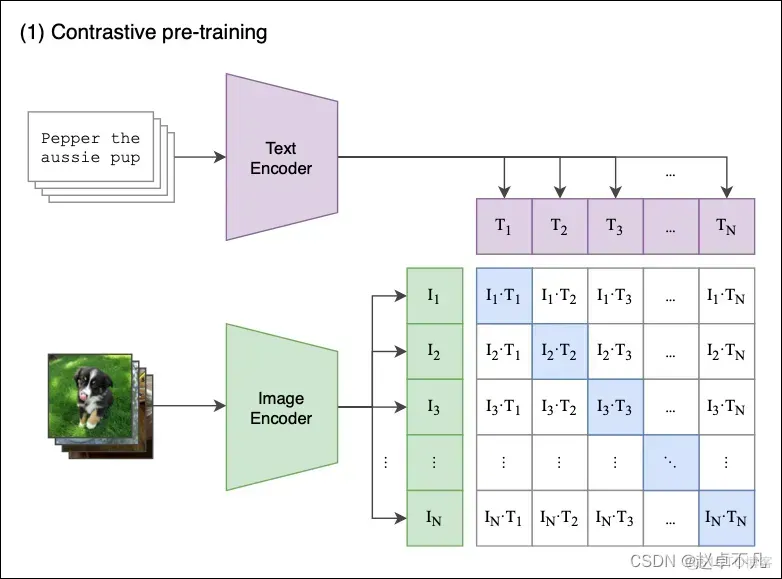
- CLIP: 图像和文本描述的特征对齐,非常适合少样本分类任务,并在实践应用中作为各种下游CV任务的基础模型
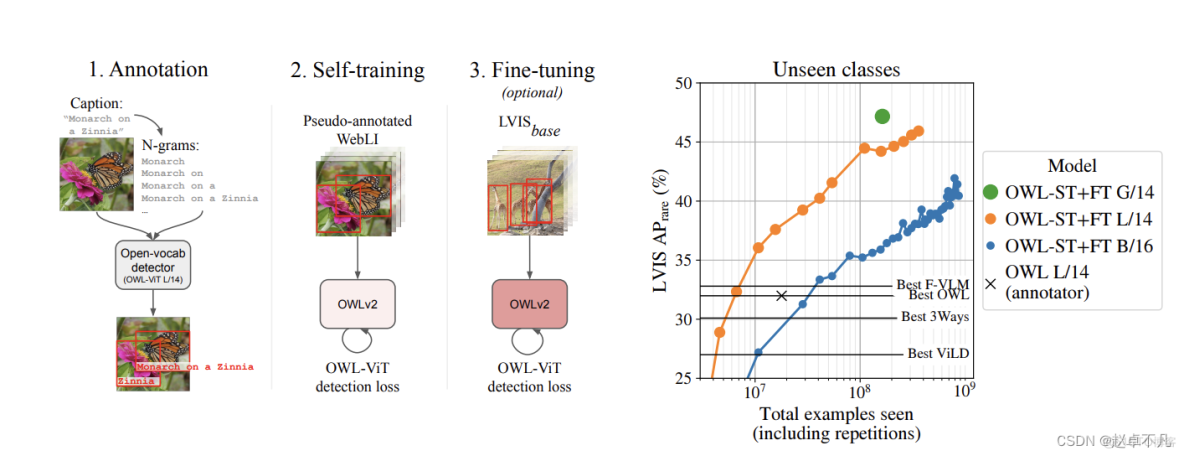
- Scaling Open-Vocabulary Object Detection: 现有的开放世界目标检测算法中,得益于大规模的图像-文本对,预训练的encoder有较多的数据支撑,但在应用于目标检测时,由于检测数据集比起图像-文本数据集数量规模少很服务器托管网多,限制了开放世界目标检测算法的性能。这里作者用self-training的范式来扩展检测数据集。
6. 文生图大模型
文生图模型现在属于大规模生成式模型,通常为多模式的任务(包括在其架构中能够理解复杂文本的大型语言基础模型),比较出名的例子为StableDiffusion以及DALL-E这两项工作的细节,可以直接去附录进行更全面的了解研究。
7. 视觉多任务大模型
- Florence-2: unified Computer Vision (Microsoft)
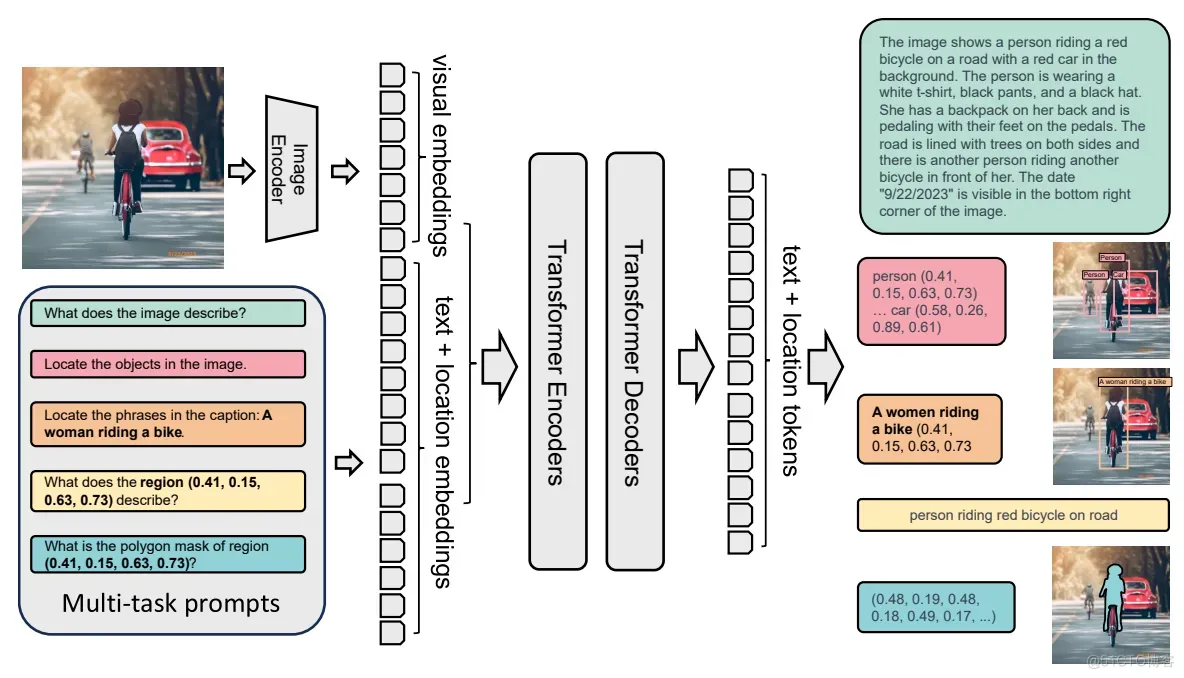
该模型采用了一种基于prompt的统一表示方法,广泛适用于各种 CV 和 Visual-Language 任务。与现有的 CV 大模型在迁移学习方面表现出色不同,它在执行各种任务时可以通过简单的指令来处理不同的空间层次和语义粒度的复杂性。Florence-2 核心为通过采用文本提示作为任务说明来支持语义描述生成(image captioning),目标检测(object detection)、定位(grounding)和分割(segmentation)等相关视觉任务。
8. 多用途大模型
业内还涌现一批封闭源代码,仅通过API调用的大型多用途大模型,虽然不以视觉为中心,但展示了卓越的视觉功能,而且还具有生成式功能:比如Open AI的GPT-4V 以及Google的Gemini(下图所示),都带来了行业内新的大模型发展高度。与之对比,还有许多开源的、较小规模的多用途视觉+文本大模型也在开发中,例如LlaVA。
所有这些模型都是强大的基础模型,涵盖了许多视觉文本领域,并擅长在许多情况下进行判别式或生成式任务。
9. 总结
本文主要用来回顾了23年相关大模型在计算机视觉多个领域的发展现状,以及一些突出的技术论文概要分享,主要涉及图像大模型到图文大模型以及生成式大模型。对于这些大模型,在实际工作和项目中,我们更多的应该是思考如何在我们特定的、小规模的背景下利用好它们。
本章节主要为相关论文的梳理和概述总结,下一节我们会针对实际项目中如何结合大模型进行数据集的构造等方向进行归纳总结。
10. 参考链接
主要参考论文和文献资料梳理如下:
DINO V2
SAM
SAMed
SAM medical image segmentation
CLIP
Scaling Open-Vocabulary Object Detection
StableDiffusion
DALL-E
Florence-2
GPT-4V
Gemini
LlaVA
Small Scale Computer Vision
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: java基础语法api之随机数的介绍以及案例应用
一:概述 在实际开发应用中,我们都会看到,有许多的场景中需要使用到随机不确定的数。在这时,我们就需要用到API中的Random类。 二:具体说明 JDK_API帮助文档中的说明 Random: – 该类的实例用于生成随机数 构造方法: – Random():创…
