
HUGGINFACE PEFT库:
实现LORA, prefix-tuning. prompttuning, AdaLoRA, LLaMA-Adapter训练的库
HUGGINFACE accelerator库:
是一个将pytorch模型迁移到CPU/GPU/Multi-GPUs/TPU/Fp16/bf16模式下训练的一个标准库

DeepSpeed
Pytorch的分布式并行计算框架(Distributed Data Parallel,简称DDP),它也仅仅是能将数据并行,放到各个GPU的模型上进行训练。
DeepSpeed,它就能实现这个拆散功能,它通过将模型参数拆散分布到各个GPU上,以实现大型模型的计算,弥补了DDP的缺点,非常方便,这也就意味着我们能用更少的GPU训练更大的模型,而且不受限于显存。
Zero
zero 1 2 3
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
发表在SC 20,DeepSpeed项目最初就是论文中ZeRO方法的官方实现。
ZeRO-Offload: Democratizing Billion-Scale Model Training发表在ATC 21
ZeRO-Infinity: Breaking the GPU Memory Wall for Ex服务器托管网treme Scale Deep Learning 发表在SC 21,同样是进行offload,ZeRO-Offload更侧重单卡场景,而ZeRO-Infinity则是典型的工业界风格,奔着极大规模训练去了。
参考资料:https://zhuanlan.zhihu.com/p/428117575
deepspeed就是主要使用了这种方式
Lora
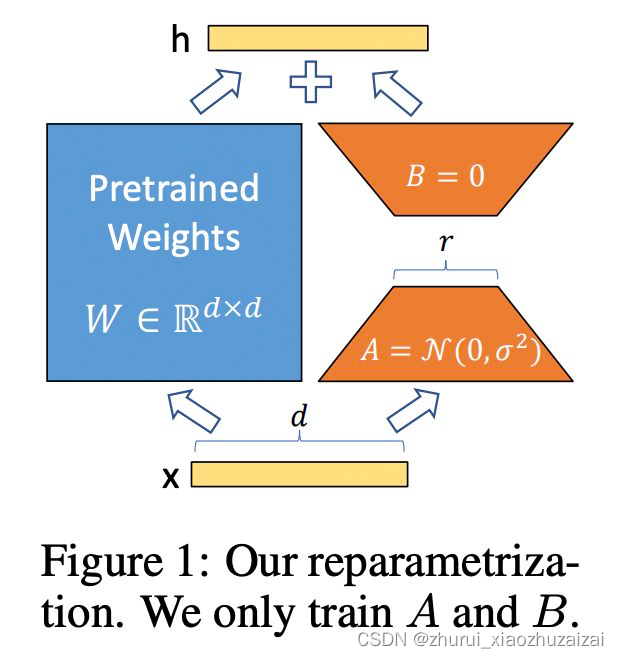
LoRA 发现再微调 LLMs 时,更新矩阵(update matrix)往往特别 sparse,也就是说 update matrix 是低秩矩阵。LoRA 的作者根据这一特点将 update matrix reparametrize 为两个低秩矩阵的积积BA 。
其中W=[dk],,A 和 B 的秩为 r,且 r远远小于min(d, k)。如此一来,A+B 的参数量将大大小于W .
LoRA 的论文:
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
https://arxiv.org/pdf/2106.09685.pdf
借助 Huggingface PEFT 框架,使用 LoRA 微调 mt0:
https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.服务器托管网net
