
本文从应用视角出发,尝试把大语言模型中的一些长处放在推荐系统中。
01
背景和问题
传统的推荐模型网络参数效果较小(不包括embedding参数),训练和推理的时间、空间开销较小,也能充分利用用户-物品的协同信号。但是它的缺陷是只能利用数据集内的知识,难以应用open domain 的知识,缺乏此类语义信息和深度推理的能力。
大语言模型从这几个角度来看,正好跟推荐模型有一定取长补短的能力。它能够引入外部知识,能够有跨域的能力,但是它没有推荐场景下所需要的协同信号,另外它的计算成本(不管是训练还是推理)都非常高。
本次报告会尝试解答推荐模型和大模型如何取长补短。具体分两个角度:
-
在整个推荐流程中,可以在哪些地方运用大模型?
-
如何运用大模型?
技术交流群
建了技术交流群!想要进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
本文视角是将大模型引入传统的推荐流程来做一些辅助,当然以 LLM 作为backbone 也是另外一个非常值得探索的方向。本次报告中关于现有工作的调研分析也可以从我们的综述里找到:“How Can Recommender Systems Benefit from Large Language Models: A Survey”。
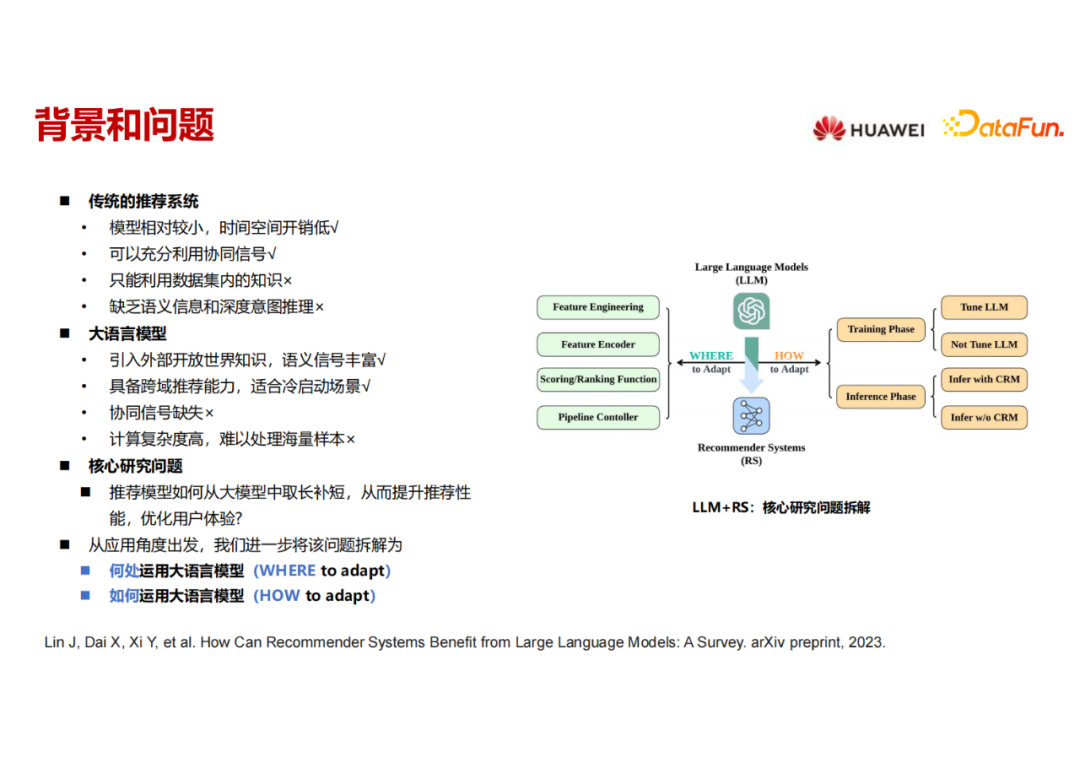
02
何处运用大语言模型(Where)
首先来解答第一个问题,在推荐系统流程中的何处运用大语言模型。

传统的推荐流程包括:数据采集,特征工程,特征编码,打分排序,还有整个的流程控制。上图中列出了近期(从2021年开始)的将大语言模型用于推荐系统相关工作。下面我会在每个流程中选择一个代表性工作进行介绍,让大家感受LLM在推荐流程中的作用。

特征工程主要聚焦于三方面:一是用户画像,是对于用户侧的理解;第二是物品画像,是对于物品内容的理解;第三是样本的扩充。已经有不同工作用 LLM 来对它们进行增强。

该工作(GENRE)在新闻推荐的场景下,用 LLM 构造了三个不同的prompts,分别来进行新闻摘要的改写,用户画像的构建,还有样本增强。
首先可以看到它把新闻的title, abstract 还有category 当作输入,然后要求大语言模型来生成一个摘要,把这个摘要当作这个新闻的 new feature输入下游。
然后是用户画像,根据用户过去观看过的新闻的标题,尝试去问大语言模型是否知道这个用户的一些感兴趣的topic,也就是用户的喜好和他所在的位置。
另外,因为有一些用户看过的新闻非常少,所以用大语言模型来做一些样本的扩充。这里是把用户看过的一些新闻的category,还有 title 输入到大语言模型里面去,希望大语言模型能够根据他看过的这些新闻,生成出来一些用户并没有看过,但可能感兴趣的“伪新闻”,然后把这些“伪”交互数据也当作训练集的一部分来进行训练。
实验表明这些手段都可以增强原始推荐的效果。
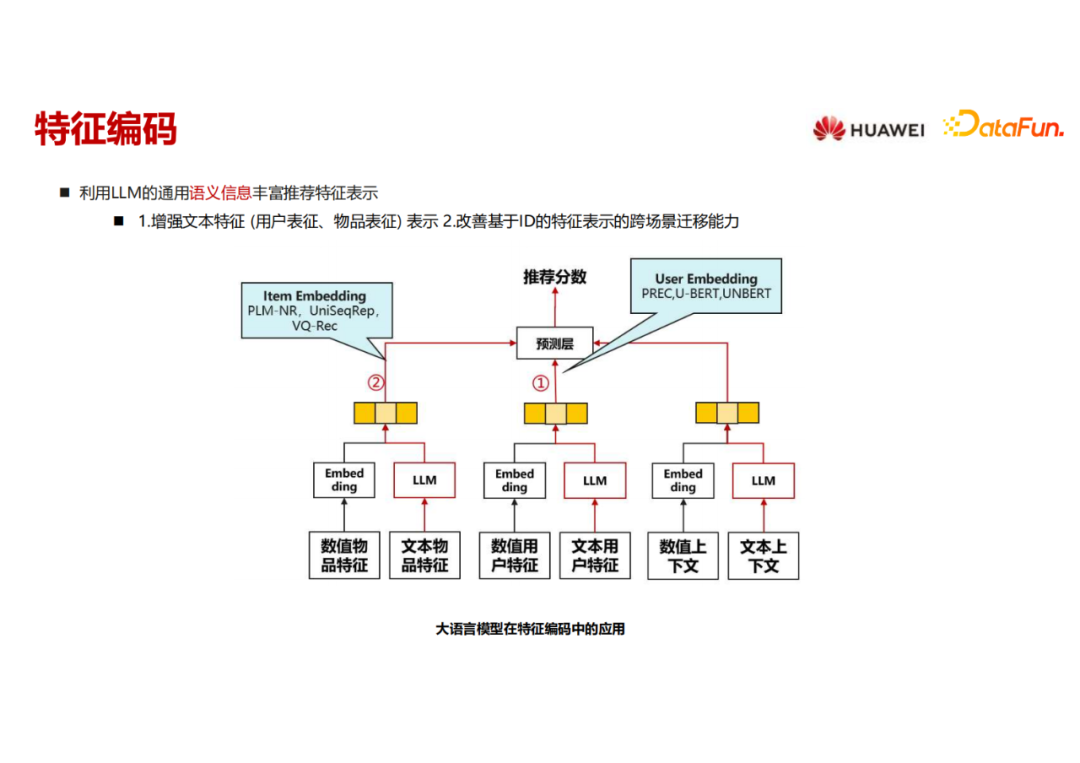
第二部分是用语言模型来做特征编码,丰富语义信息。这里的语言模型其实都不大,类似于 Bert ,因为它要内嵌进推荐模型一起去训练和推理,在实时性要求比较高和海量训练样本的情况下,语言模型的大小不会大。这里就聚焦在两块,一是如何用语言模型来丰富用户特征的表征,二是如何用语言模型来丰富物品特征的表征。
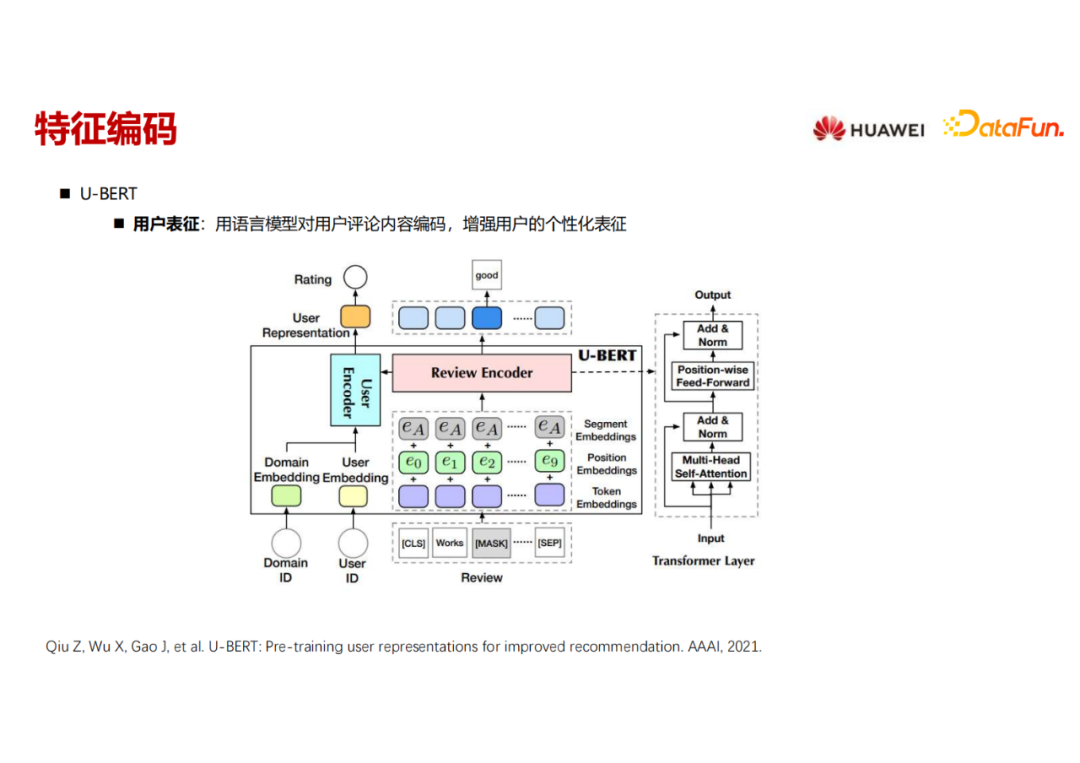
U-BERT这个工作是用语言模型做用户特征表示,把用户写过的 review 信息经过一个类似 Bert 的结构编码出来。这个用户的 encoder 里的另一块输入是用户原始的 ID embedding,加上当前推荐 domain 的 embedding 这两部分,与用户review信息的编码一起形成用户的个性化表征,然后送到下游的推荐任务里面去。
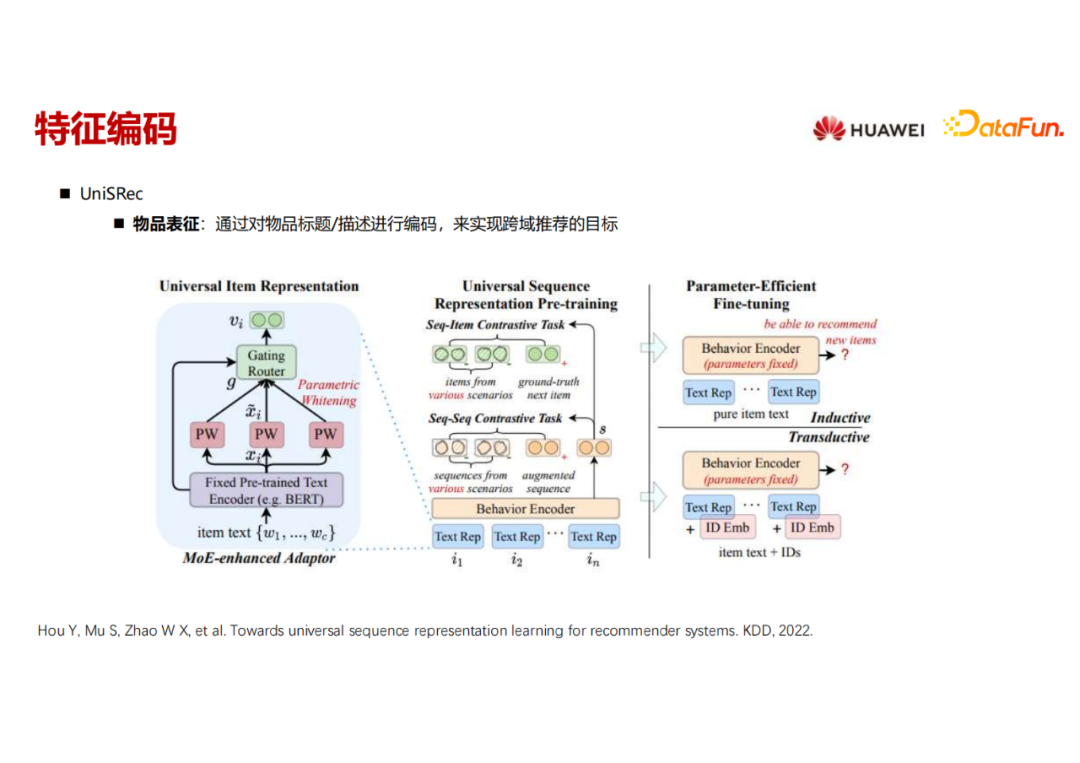
UniSRec这个工作使用语言模型做物品特征表示,把物品的 title 描述通过类似 Bert 的结构编码之后,得到物品文本信息的编码。之后经过一个预训练阶段,通过构建两个对比学习任务,将用户-物品的序列信息加入到物品的文本表征中。
第一个对比任务是把所有的用户,在不同场景下的不同类型的历史行为(如浏览、点击、下载等),全部拼成一个很长的序列,然后在这个序列里面做类似于 next token prediction 的任务;另一个对比任务就是sequ服务器托管网ence to sequence 的对比任务,从一个 sequence 里面通过 mask 或者采样的方式采样出来多个sequences。如果两个 sequence 是从同一个原始 sequence 里构造出来的,就是一对正例,否则就是负例。
通过这种预训练的方式,把序列信息和文本信息 encode 到一起,到了下游某一个具体场景做推荐的时候,做进一步基于next item prediction的fine tuning。
打分和排序阶段可以分成以下三种不同的任务,第一种是直接给 item 来进行打分;第二种是物品生成任务,直接生成用户感兴趣的下一个物品或者物品列表;第三种混合任务,用多任务的方法来建模。

这是一个发表在今年的 arxiv 上的工作,它是分别在三个不同的场景下直接用语言模型来进行打分,三个场景分别是 Zero shot、Few shot和微调。

Zero shot 场景,构造的prompt包括用户的历史行为包括观看的电影名称,题材和历史打分。给出某一电影的名字和题材,询问大语言模型,用户会给这部电影打多少分。
Few shot跟 Zero shot 形式略有不同,但大体思想一样,只不过是给出了一些打分的例子,把这些question和answer的pair也注入到prompt中去。
第三个场景就是微调的场景,不仅把用户-电影的交互数据当作prompt的一部分,而且通过实际分数和预测分数的残差去更新模型。这个工作提出了利用多任务的架构,一边做回归任务,一边是做多分类的任务,然后这两个loss合并后更新模型。在实验里面看到微调的方法比 Zero shot 和Few shot 效果要好很多。

下面一个工作是直接进行物品生成推荐。它把整个推荐任务拆成了两部分,第一部分是来做用户画像的生成,把用户所有看过的电影全部输入当作input,然后 output 是问这个用户喜欢什么类型的电影;第二部分把第一部分的用户画像当作 prompt 的一部分输进去,同时把历史交互过的电影和待推荐候选集也输入给大语言模型,用大语言模型来生成推荐列表。

大家可以思考一下为什么要把看似是一体的推荐任务拆成两部分?其实一个原因是因为通过这种拆解能够把它认为推荐系统里面最重要的一部分提示大语言模型。用LLM进行一步到位的推荐效果很有可能是不好的,因此用比较直接的方式来提示大语言模型来分步进行。第一步把用户画像输出来,然后显式地输入到第二步的商品推荐的 prompt 里面去,这样可能会达到更好的效果。这也提供了一个LLM做推荐的思路,有点类似于思维链。做推荐不一定要一步到位,因为推荐的过程还是比较复杂的,可以用人为的经验来设计拆解成多步。
拆解成多步带来的弊端就是对大语言模型的请求量增加了,本来请求一次,现在变成请求两次,未来还可能请求多次。
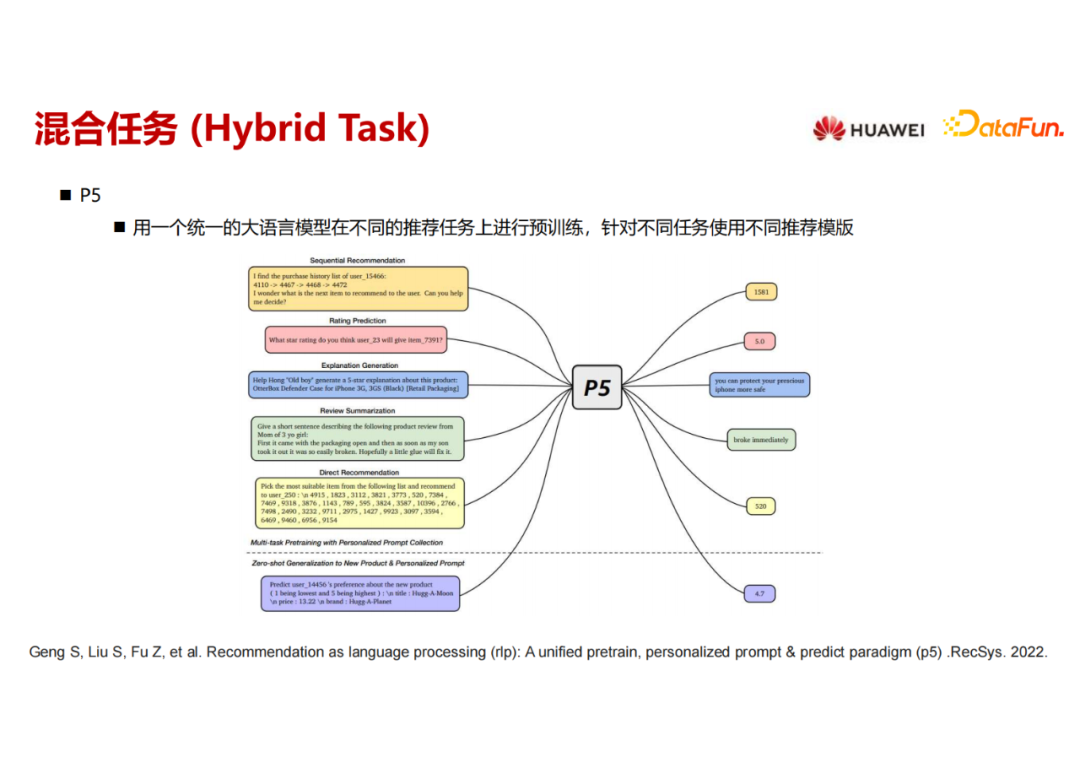
下一个工作是P5,其实跟 M6-Rec 相似,里面具体的技术细节不一样,但是想做的事情其实是一样的,用一个统一的大语言模型在不同的推荐任务上构造不同的prompt,然后用SFT 来进行不同下游任务的微调。
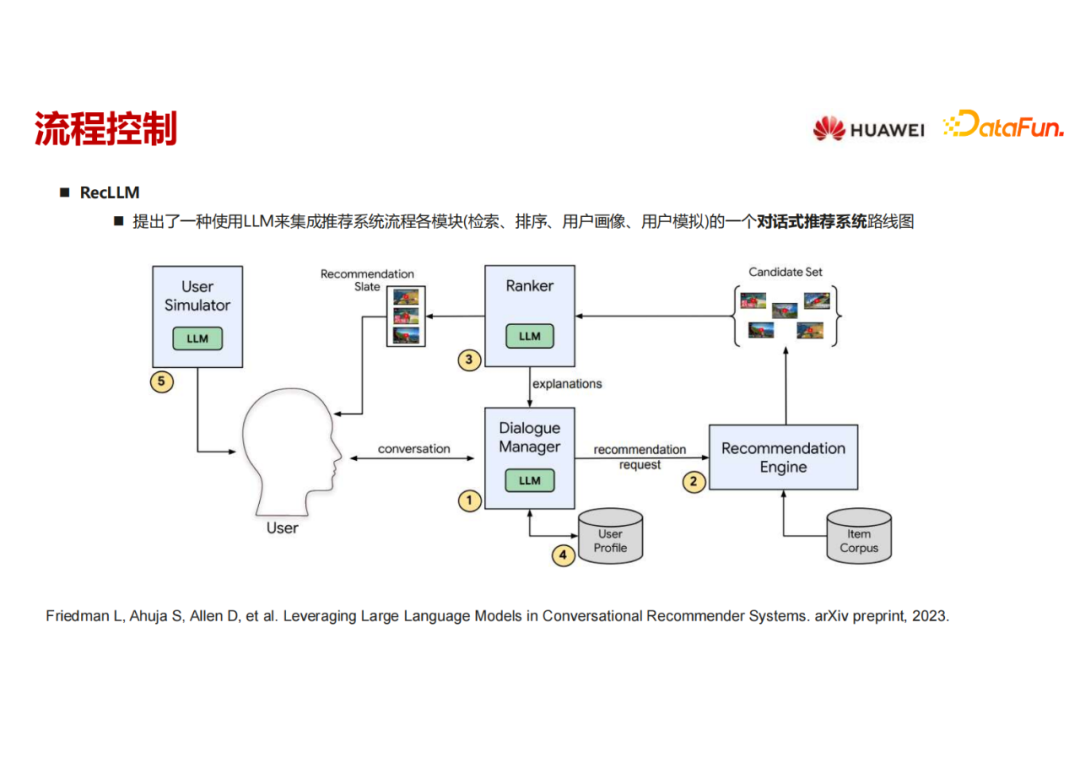
谷歌提出的工作是把大语言模型当作一个流程进行对话式推荐的框架。核心组件在 Dialog manager 这里,用一个大语言模型来调用其他的模块,这里面可能有ranker,可能用一个LLM来构造一个 user simulator或其他用户画像的构建,其他的模块可以用大语言模型,也可不用大语言模型。它的工作就是构造了这样一个流程和框架,用大语言模型作为核心调度来解一个比较复杂的对话式推荐任务。
通过这一章节的介绍可以看到,大语言模型在推荐的各个阶段有一些工作,比如特征工程如何构造,如何丰富 user 和item 特征,构造数据;还有 feature encoding也可以用语言模型,虽然现阶段还没用到很大的语言模型强化表达;另外,在打分模块里可以用直接打分或者生成式来推荐,或者是一种混合式的任务;最后,还可以把大语言模型当做一个调度器来进行调度。
03
如何运用大语言模型(How)
接下来分享如何运用大语言模型。
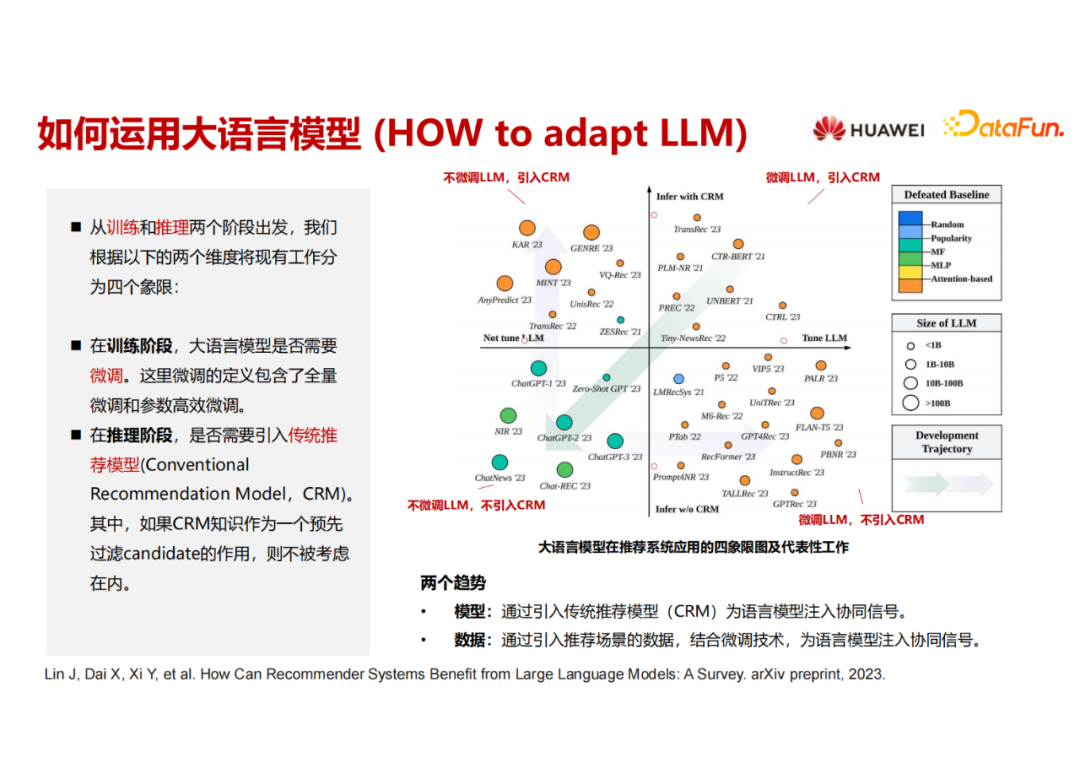
我们对现有基于语言模型的推荐工作进行了分类(数据截至6月底,后面会持续更新)。这里的x 轴表示在训练阶段大语言模型是否经过了微调,左侧是大语言模型不需要微调的工作,右侧是需要微调的。y 轴是推理阶段是否完全用大语言模型、抛弃了传统推荐模型。在y 轴的上半部分是依然需要推荐模型来进行辅助,下半部分是完全把推荐模型摒弃掉,用大语言模型来搞定推荐系统的推理。这里的颜色代表每篇 paper 里面对比的 baseline 是什么?颜色越冷,说明能够击败的 baseline 越弱。颜色越暖,说明能够击败的 baseline 越强。
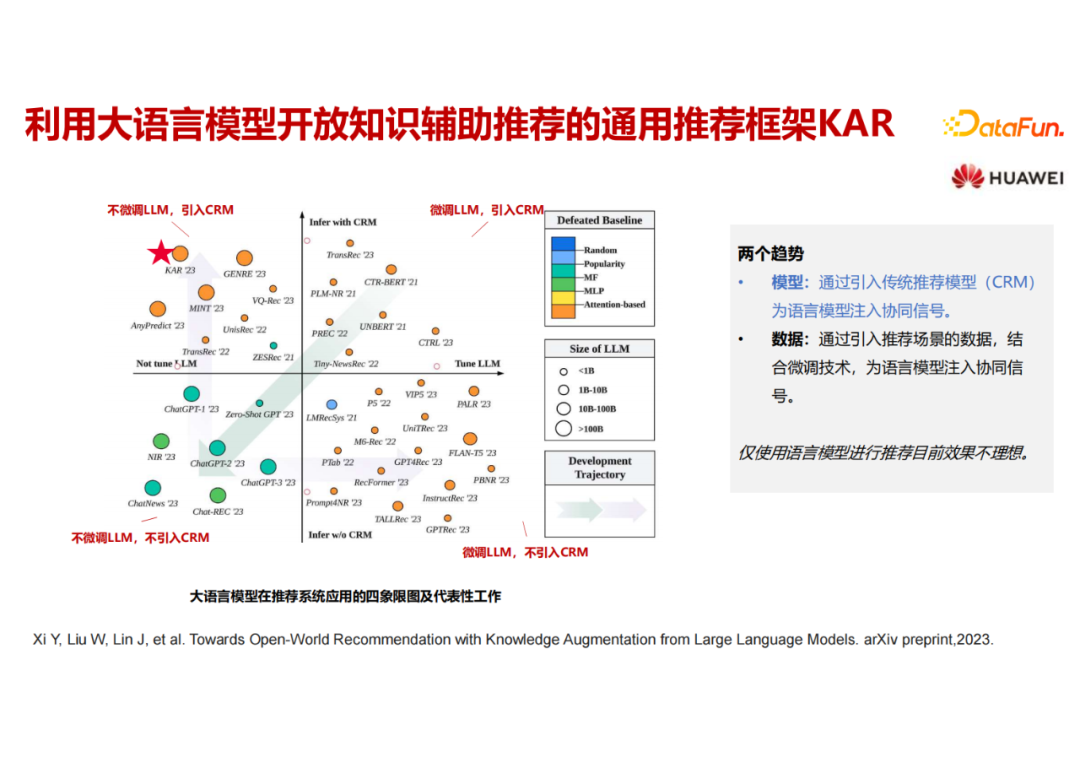
这里可以看到第三象限的颜色是比较冷的,第三象限是训练阶段LLM不微调、推理阶段不用推荐模型,把LLM当作API去调用,完全走 prompt 的路线,从模型的名字可以看出来有很多带有ChatGPT 或者 GPT 这种单词,它们的效果其实是有待提升的,效果要弱于其他三个象限的工作。X轴左侧的模型大小普遍是比较大的,左侧的工作中LLM是不微调而直接当作API来调用的,所以可以用一些比较大的模型来做,一旦涉及到大模型微调训练,因为资源的原因模型瞬间就小下去了。
从时间来看,第一象限实际上就是很多年前已经开始做的,用 Bert 来做一些 user 和item 的encoding。最近 ChatGPT 出来之后有很多的工作直接来探索怎么用 ChatGPT 来做推荐。一些探索性的工作直接从第一象限插到了第三象限,但是它的效果是有待提升的。之后出现了两个明显的趋势,其核心就是既然直接用大语言模型无法做好推荐,那就想办法把推荐的信号加进来。第一个趋势是大语言模型依然不微调,通过模型的方式来进行补救,加入了推荐模型,主要的工作在第二象限;另一个趋势是在第服务器托管网四象限,认为大语言模型单独可以做推荐,把推荐的信号加进去做微调。也许未来这两个路线又可以重新回归到第一个象限。这个图是尝试把现在 基于LLM的推荐模型 进行分类,后面也会持续更新该工作。当前survey比较偏应用视角,大家也可以关注下其它偏技术视角的工作。

介绍两个本团队做的工作,也是比较初步的探索。上图的工作属于第二象限,用大语言模型做API,不微调大语言模型,最终的推荐还是由传统的推荐模型来做。一句话概括这个工作就是用大语言模型来加强用户画像和物品画像的生成。
推荐系统是由封闭的训练集训练得到,相当于在一个小房子里;虽然多场景跨域推荐有一定迁移能力,但是还是相当于封闭在一个别墅中的多个小房子里。我们依然需要一条路来联通这栋别墅和外界。而大语言模型具有比较强的推理能力和对于世界知识的建模能力,非常适合当作联通小别墅和外部世界的路,这条路在这个工作里就是来做用户画像和物品画像。但如果直接用大语言模型,不加任何引导还是有问题的,因为用户的偏好比较复杂且多面,这个世界的知识也是海量的。对于一些数据集,用户 feature 和物品 feature 不那么丰富的时候,语言模型可以补充很多信息,但依然会带来很多噪音。
举例来说,之前介绍过做用户画像的工作生成的两个 feature :一是用户的兴趣;另一个是用户地域。如果我们要做电影推荐,用户兴趣是跟电影推荐相关的,但是用户地域信息可能跟这个任务没有多大关系,甚至有可能是噪音信息,那么对于这个 user feature 可能就没有必要生成。
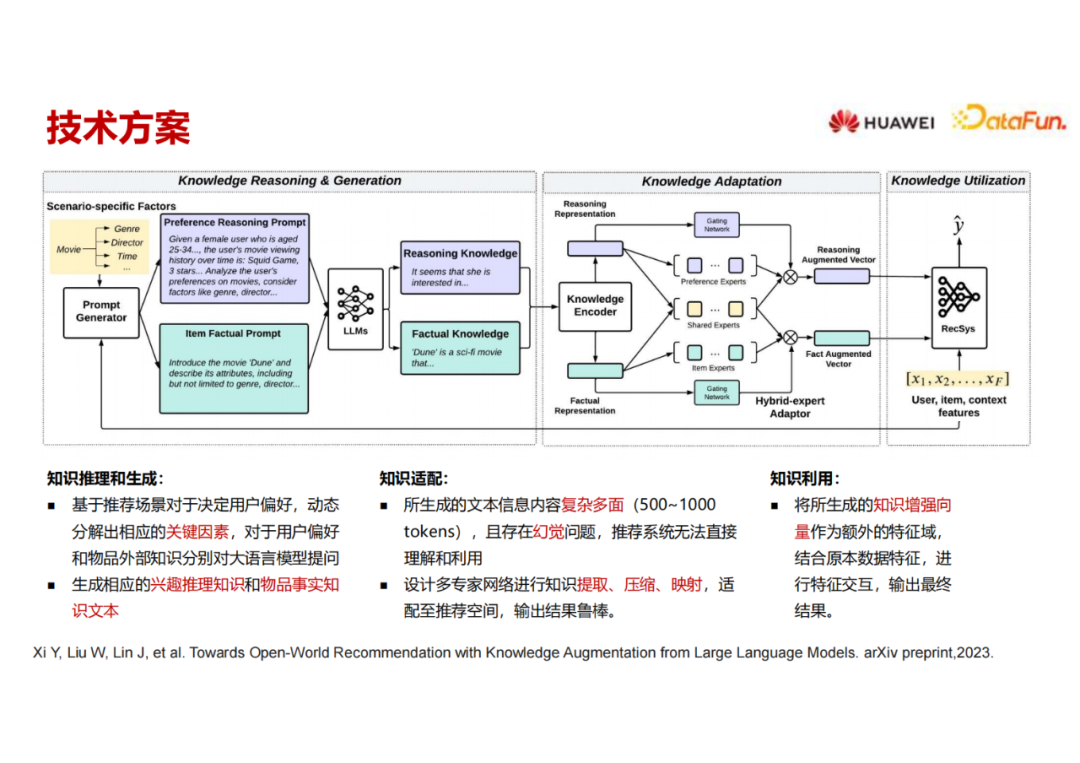
所以本团队提出来用LLM生成用户画像和物品画像,需要构造关键子因素,需要LLM来帮我们生成一些用户画像和物品画像要聚焦在在这些关键子因素上,不要偏离得太远。这个关键子因素是跟推荐场景相关的,对于电影推荐、商品推荐和视频推荐,关键子因素是不同的。
接下来的问题就变成了如何构造关键子因素。一是可以人工指定关键子因素,但我们也发现了另外一种比较自动的方法,就是去问大语言模型。比如一个电影推荐场景,能否告诉我 10 个最重要的影响推荐的因素是什么,feature 是什么,大语言模型可以告诉我是题材、演员、导演等等。换一个其它的推荐场景,大语言模型依然可以输出,人工再检查一遍,查漏补缺把关键的子因素定下来,然后把这些关键的子因素输回到下一步 user feature 和 item feature 的prompt 里面去。
把不同的 factor 输进去之后,prompt 就会引导大语言模型,不仅要扩展出我需要的信息,还要尽量focus 在现在需要的电影推荐场景。那么大语言模型的输出就会比较聚焦在这里。item也是同样的,通过问问题,比如告诉我用户的兴趣是什么。这个问题是很 general 的,把这个问题分解到多个关键子因素上去,使得回答能够更加聚焦在domain specific 的关键子问题上面。
第一步先构造这些关键子因素,并将它们加入构造用户画像和物品画像的prompt中,输入大语言模型,得到一些用户和物品的画像信息,输出到 knowledge encoder 里面去,这里可以用一些相对不那么大的模型去进行encode, 得到关于用户和物品的语义表达。最终希望把这两个表达当作两组额外的 feature 加到传统的推荐模型里来,这个传统的推荐模型可以是任意的模型。
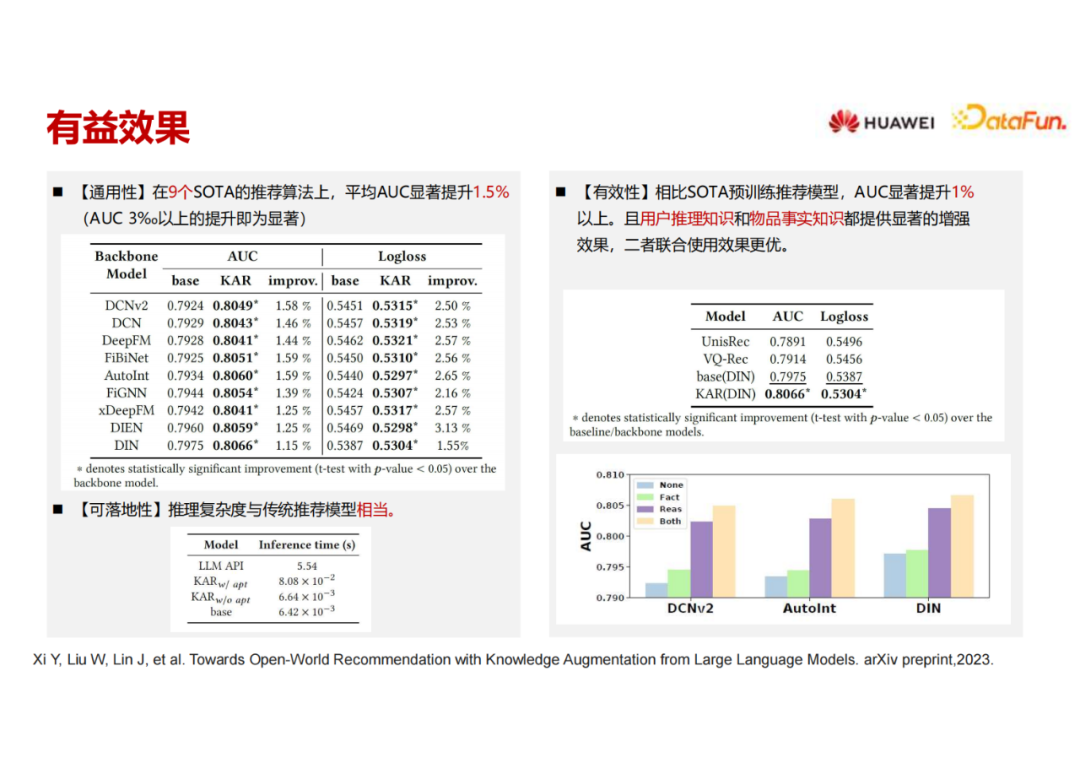
从工业视角出发,我们觉得这是一个可上线的方案。因为第一阶段可以放在离线来生成,可以把用户的长期行为输入LLM生成用户画像,这个过程比较耗时、耗资源,可以一周跑一次,看团队的资源情况。将生成的用户画像和物品画像的文本存在内存数据库中。甚至,我们可以将Reasoning Augmented Vector和Fact Augmented Vector存下来,就更节省计算资源,这两个向量输入后端的推荐模型。这个工作已经公开在ArXiv上,该版本里我们只做了一个公开数据集的实验,现在也在做更多的数据集来进行下一个版本的补充。可以看到这个用户画像和物品画像的生成过程作为一个通用模块,可以作用在很多不同的 backbone 上,加入了k AR 模块之后, AUC 和LogLoss的提升还是非常明显的。
对于可落地性,基于大语言模型推理生成可以放到离线来做,如果将LLM当作API去调用,花费时间较多,但是如果将LLM生成的用户画像和物品画像经过编码之后的向量存入数据库中,并在推理的适合实时去取,时间复杂度会大大降低。我们也和其它一些预训练模型进行了比较,我们的效果也是比较好的。
我们还做了一组ablation study,同时对用户和物品进行特征增强,或者只做其中一边,baseline 是完全不做,可以看到呈阶梯式的上升。如果用户画像和物品画像只能做一个,那么增强用户侧特征的效果好于物品侧,两侧都做的效果最好。
总结一下这项工作,把大语言模型当作用户画像和商品画像的补充,但是如果向LLM问比较general、nave的问题,效果并不好,而是需要构造一些关键子因素,让补充出来的文本更加适配当前的推荐场景。生成的文本信息经过text encoder转化成向量,然后再经过 knowledge Adapter,将刚才生成的向量从语义空间映射到推荐空间。

第二个工作叫CTRL,位于第一个象限。用语言模型和推荐模型协同,并在训练阶段也会去微调语言模型。现阶段语言模型并不是很大,我们现在也在尝试用更大的语言模型。
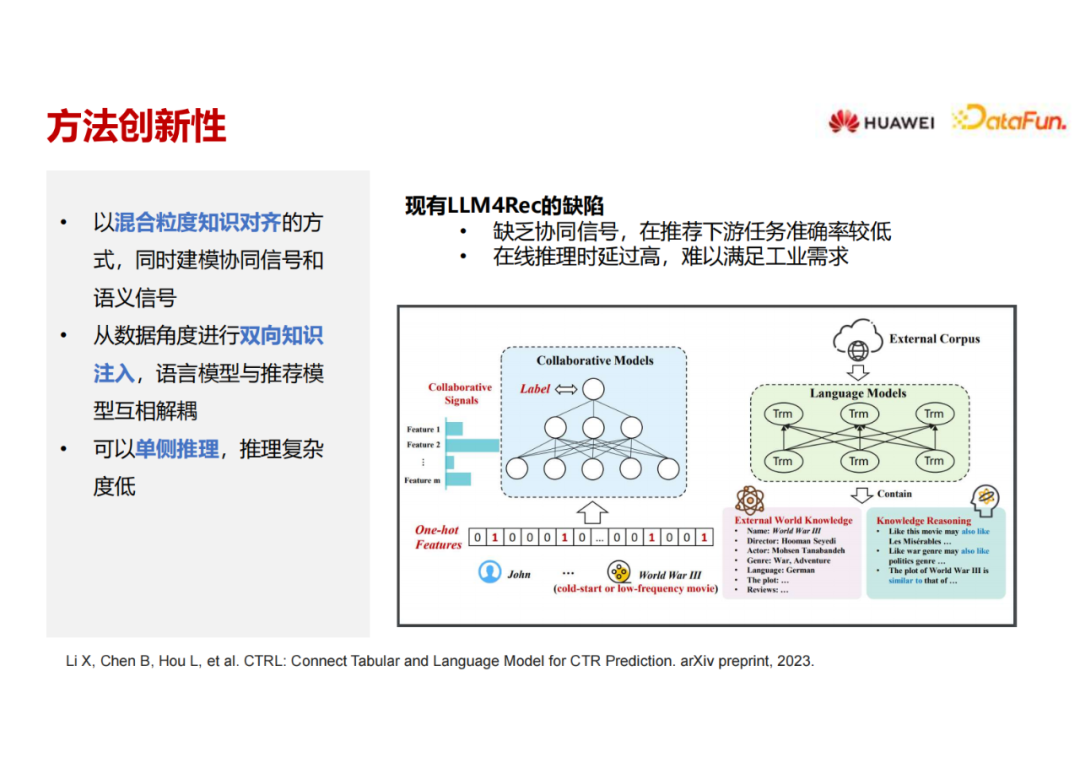
这里把推荐系统的信息看作两个模态,第一个是表格模态或者协同模态(传统的推荐模型聚焦于这个模态),第二个是本文模态(大语言模型聚焦于这个模态),这两个模态可以用对齐方进行模态对齐,提升效果。首先我们把通过构造不同的prompt来将协同模态数据转化为本文数据模态。比如一条样本是:一个年龄为 18 岁的女性,是一名医生,过去看过某些电影,然后判断另外一部电影她是否会观看。把这样一个推荐问题转化成一个文本描述,将协同模态和文本模态输入到两个不同的模型里面去,一个是传统的推荐模型,另外一个是文本模型(我们用BERT、ChatGLM进行尝试)。把文本信息输进去之后,通过一个语言模型encoder将训练样本的文本编码成向量,然后通过细粒度对比学习的方法将两个模态编码的信息进行对比。期望通过这种方式把预训练语言模型里的一些世界知识和语义信息,传递到协同过滤模型里的 embedding 里面去。
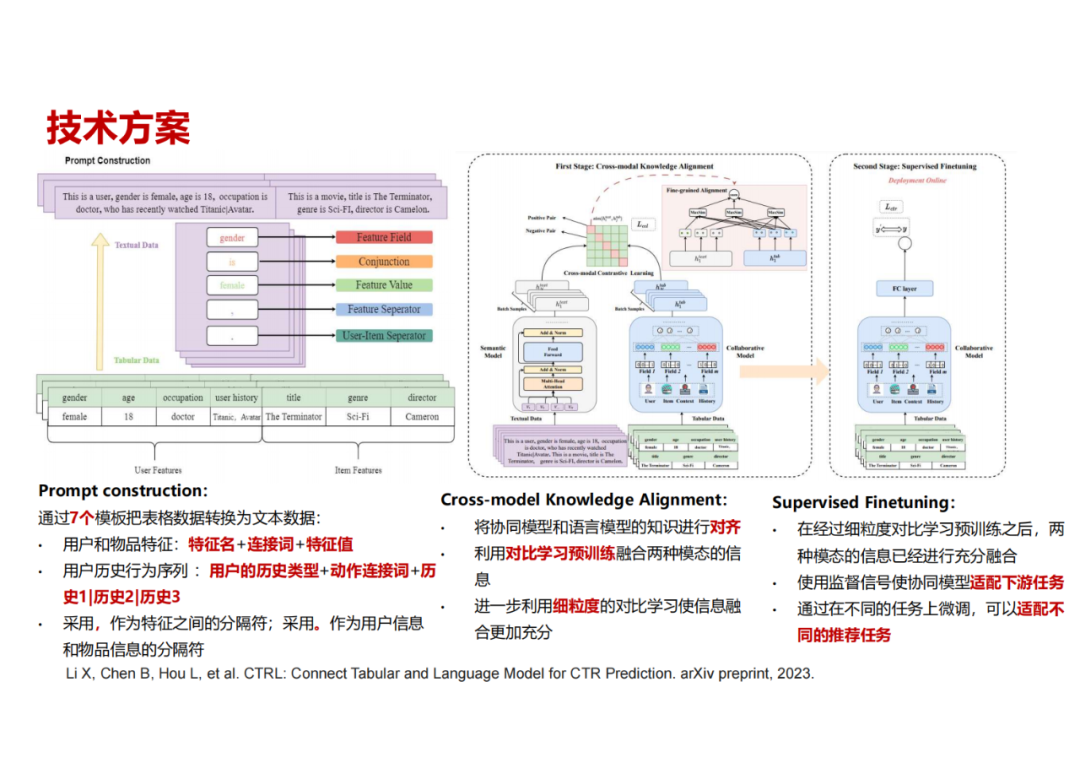
进行对比学习后,我们进入下一阶段,单独用协同模型,在一个特定的场景下做SFT,这样协同模型中embedding 里面已经有了一些语义信息,再把这些推荐的信号加进去,期望能够取得一个比较好的效果。
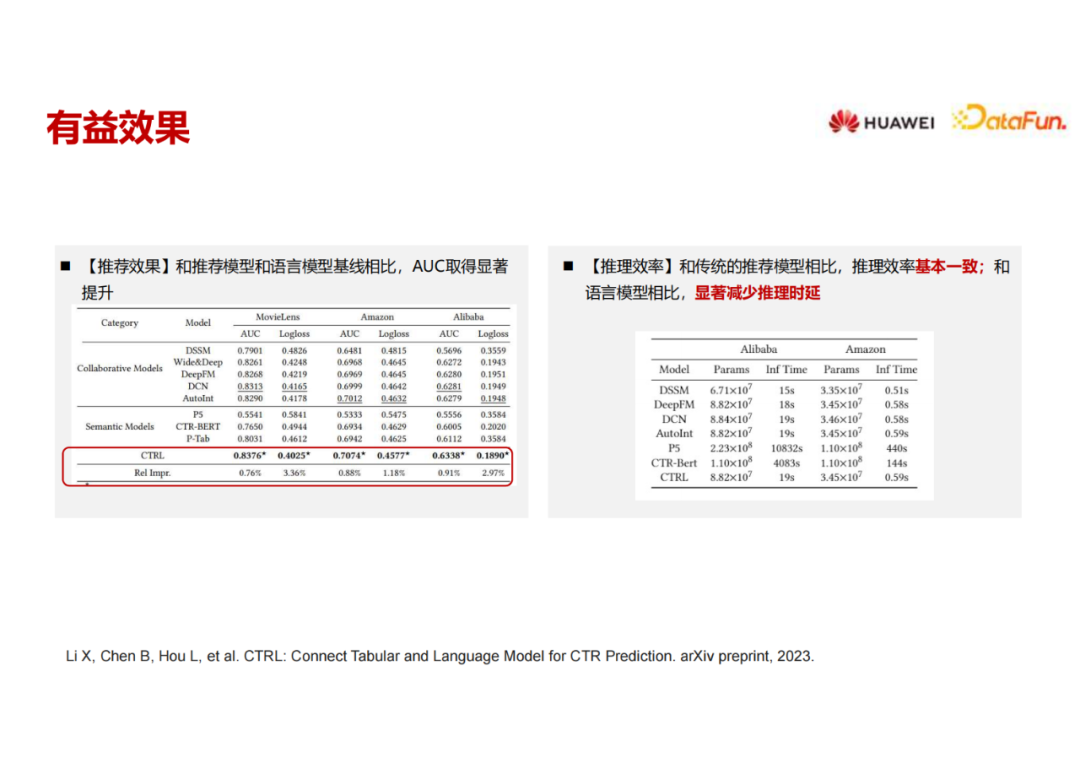
我们在三个不同的数据集上做了实验,包括MovieLens、Amazon,还有阿里巴巴。两组对比的baseline模型,一个是完全用协同模型,一个完全用语义模型。我们的模型精度比这两组baseline都有比较明显的提升。另一方面,由于我们在推理的时候只用协同模型,因此推理时延并不增加。我们在华为的一个工业数据集上进行了离线实验,也得到一个比较好的效果,现在正在做一些线上的部署。
04
挑战和展望
最后来看一下工业应用场景下的挑战,以及对未来工作的展望。

第一个大的挑战是训练效率。可能的解决方案是一些参数的高效微调,以及降低更新频率(利用推荐的协同模型来提升实时性)。
第二个问题是推理时延过高,也正是因为这个原因,前面介绍的两个工作没有在推理阶段引入LLM,而是把它的一部分结果进行预存,或者是用类似于蒸馏或者对比的方法,避免在推理阶段引入LLM。也可以用量化、蒸馏的方法来进行模型小型化部署。另外,可以避免把它用来做排序或者打分,仅作为特征工程或编码,避免直接在线上做模型推理。
第三个挑战是推荐领域的长文本建模。现在的解决方案是前面接一个召回模型或者粗排模型,把候选集聚焦到只有 10 个、 20 个或者 100 个范围内,再送入LLM。未来也有可能处理更长的文本这样可以面向更大的候选集的直接排序或打分。
最后,在推荐系统里面ID 类的特征依然是非常重要的。现在对于语言模型来说, ID 类特征的建模实际上做得并不是很好。有一篇paper做了一个探索,根据语义信息把 物品进行聚类,然后根据语义聚类的结果进行重新编码,这是一个非常好的思路。

回顾一下全文,从应用视角出发,以推荐系统为核心,分析了两个核心问题:整个推荐流程里面哪里可以用到大语言模型,大语言模型与推荐模型是如何配合的。
展望未来的发展,第一个趋势是LLM已经从传统的编码器和打分器在逐步外延,外延到特征工程、一些神经网络的设计,甚至是流程的控制。第二个趋势是纯用 LLM 不 微调从现在的实验结果来看效果不佳,如果要达到一个比较好的推荐效果,有两条路,一是微调大语言模型,另一个是用传统语言模型来进行融合。
未来大语言模型用在推荐里有如下几个可以发力的场景:
第一个就是冷启动和长尾问题;
第二个是引入外部知识,现在引入外部知识的手段还比较粗糙,就是把大语言模型拿来生成,其实纯用语言模型也没有很多外部知识。相反,语言模型也需要外部的知识,比如它需要集成一些检索能力,需要集成一些工具调用的能力。现在我们只用了基础的语言模型,并没有用它的检索和工具调用的能力。未来能够更加高效地、更加完备地引入更多的外部知识,通过检索或者工具的方式,也是提升推荐体验的一个方向。
第三个改善交互体验,让用户可以主动通过交互时界面自由地描述其需求,从而实现精准推荐。
05
Q&A
Q1:预训练 LLM 需要大规模语料,推荐系统的公开数据集可以支撑 LLM 的预训练吗?
A1:现在来看,训练 LLM 需要海量语料,公开数据集从量级来说不可能支撑 LLM 来进行预训练,比较实现的方案是基于一个已经预训练好的LLM,用公开数据集做第一阶段的SFT,之后可以基于我们自己的推荐场景来做第二阶段的SFT。
Q2:图与语言模型做推荐本质上区别是什么?
A2:图更多强调的是不同节点之间的结构,但是它对外部知识的利用还是不充分的。比如构造一个知识图谱,也是某一个垂域的知识图谱,不可能构造一个世界级别的知识图谱,但是语言模型在某种程度上可以把世界知识构建进来。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
