
1.问题场景
有100亿个url被加入了黑名单,现在提供一个url要去判断是否属于黑名单。也就是一个很简单的一个东西是否属于一个集合的问题。
一般来说用set就能解决这种问题,但是由于url数目太多,内存中无法开辟一个这么大的空间去存放所有url,这个时候就需要我们去使用一种结构,去减少状态信息存储所需要的内存,而布隆过滤器就可以很好地实现这个功能。
2.基本知识
在了解布隆过滤器算法前,需要先了解一些前置知识,例如哈希函数和位图
哈希函数
哈希函数就是一个映射函数,可以把任意长的输入位(或字节)变化成固定长的输出字符串的一种函数。理想的哈希函数是从所有可能的输入值得到所可能的有限输出值的一个随机映射。
性质
- 哈希函数保证有离散性,即当m1和m2 这两个输入有一点差别的时候,最终经过哈希函数计算的输出结果可能完全不同,离散开来。
- 对于相同的输入,哈希函数计算的输出一定会相同,反过来只要输出不相同,那么输入一定就不会相同。对于不同的输入,极小概率下,哈希函数的计算输出会相同(即哈希碰撞),一般都不同。
- 同时哈希函数也保证有均匀性,即在输出的大范围里,每一小片区域中存在的值的个数是相近的(举例:一共有1000个值被输出,在整个输出范围里,每一小片区域里包含的值的个数基本相同)。
- hash函数为单向函数,给定消息m可以很容易计算h(m),但对于给定的x,不能求出满足x=h(m)的m
总而言之,哈希函数就是一个映射函数,计算的结果H(m)会在值域上离散均匀分布
位图
位图,bitmap或者bitarray,就是用bit位去存储信息的一种结构。正常的数组要么是int数组或者是long数组,每个元素是4字节或者8字节,也就是32bit或者64bit的信息表示一个元素或者一种状态。而bitarray就是1个bit表示数组里的一个元素或者一种状态服务器托管网,这样的优点就是非常省空间,本来用几十个bit表达的信息被它用1个bit就表达了(前提是信息能用位图表达的情况下)。
下面一串数字0和1即是位图的表示,一共有32个数字,分别表示数组里的32个元素,这些元素的值要么是0要么是1。
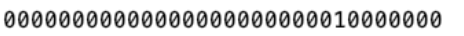
因为位图的每一个元素只有2个值,一般可以用来判断一个数是否出现过这种简单的布尔值是或否的问题。
如何实现一个位图?因为我们的数字都是32或64bit的,所以需要借助真实的数字来实现bitmap。现在设一个数字是32个bit,现在有一个长度位10的数组,这个数组可以用来表示长度为320的bit类型的数组,然后通过位运算去实现从bit数组里面取值
const arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
let i = 199 //想要获取bit数组里第199个元素的值
let numIndex = Math.floor(i / 32) //找到arr里的对应的元素
let bitIndex = i % 32 //找到对应元素里的位数
let value = (arr[numIndex] >> bitIndex) & 1 //获取第199位的值
对bitarray进行赋值操作
arr[numIndex] = arr[numIndex] | (1 //将第199位变成1 arr[numIndex] = arr[numIndex] &am服务器托管网p; (~(1 //将199位变成0
实现BitMap类
代码、案例如下
class BitMap {
constructor(size) {
this.size = Math.ceil(size / 32)
this.bitArray = new Array(this.size).fill(0)
}
getNumber(num) {
//获取位数
let numIndex = Math.floor(num / 32)
let bitIndex = num % 32
return (this.bitArray[numIndex] >> bitIndex) & 1
}
isExist(num) {
//判断一个数是否存在
let value = this.getNumber(num)
return value == 1
}
addNumber(num) {
//添加一个数
let numIndex = Math.floor(num / 32)
let bitIndex = num % 32
this.bitArray[numIndex] = this.bitArray[numIndex] | (1 bitIndex)
}
}
举例,现在有一个arr数组,arr数组里每个元素都是0-100的数,给定一个值x判断x是否出现过。
- 建立一个BitMap数组,这个bit数组只要4个元素(4个元素就可表示128位的信息)。
- 遍历arr数组,调用addNumber方法,出现过一个数就把bit数组的对应索引位置设置为1
- 调用isExist方法判断bit数组的索引x是否为1是1就说明出现过,否则就没出现过
对于这种值范围是给定的情况下,相比起普通的建立map或set统计是否出现过,这个做法只需要4个元素的额外数组空间,大大节省了空间
3.布隆过滤器
回到前面的问题,对于100亿个url的黑名单,现在希望也可以通过位图的方式来完成判断一个url是否出现在黑名单内,这样可以极大地压缩空间,但是url这种字符串是无法直接使用位图的,所以需要借助哈希函数的映射。
- 哈希函数的值域可以是一个数字,所以把url作为哈希函数的输入,就可以得到一个数字,即H(url) = number
- 位图需要把范围规定在0-m的一个范围,所以可以对哈希函数的计算结果number模上一个m,就可以把所有url经过哈希函数后的计算结果限制在0-m内了
此时已经把url变成0-m的数字了,已经可以直接用位图去判断是否存在了,但是仍然有一个问题,就是哈希碰撞。不同的输入也有可能会有相同的输出,如果m不够大,很可能存在一个不在黑名单的url在经过哈希函数的计算和取模之后,结果与黑名单中url的计算结果相同,那么不在黑名单的url就会被误判误封。
解决这个问题的办法可以是
- 取足够大的m,但是m仍然会受到内存大小的限制
- 选k个哈希函数,对每一个url都用这k个哈希函数计算,然后分别模上m,然后把这些结果全部添加到位图里(把对应索引处的元素值改成1)。当然对于想要判断的那个url,也要用这个k个哈希函数分别计算取模,然后拿这k个结果作为索引去位图里取值,只有当发现位图里这k个索引里的值全是1的时候,才判定url是黑名单url,只要存在一个位置是0,就说明不是黑名单url,因为如果是黑名单url,所有k个索引处的值一定都已经做过添加,都是1。通过k个哈希函数的计算,相比起仅用1个哈希函数计算失误率就降低了不少。
而m和k的取值则要取决于样本量n和允许的失误率p
m自然是样本越多,允许的失误率越低,取得值越大,当然内存足够的情况下也可以取得比公式里更多,这样可以降低失误率
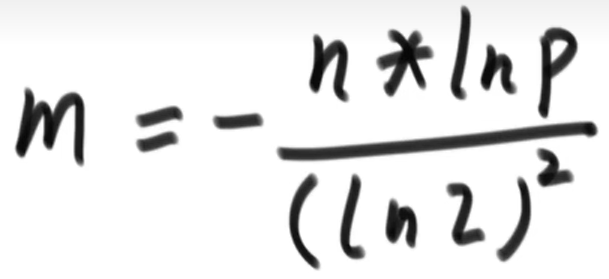
k的取值取决于m和n的比例,如果k取得太少,那么和之前的1个哈希函数计算差别不大,如果k取得太大,一次计算下来很多位置都设置成了1,再想判断的时候就很可能失误
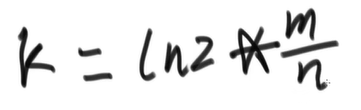
设定好了m和k,就可以按照之前的位图算法来进行判断一个url是否是黑名单内的url了
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 结合具体场景举例说明chatgpt预训练模型中Tokenization的原理
假设我们有一个场景,Alice想向Chatbot询问一部电影的推荐。她发送了一条消息:“你好,能给我推荐一部好看的电影吗?” 在这个场景中,Chatbot使用了ChatGPT预训练模型。首先,Chatbot需要对Alice的消息进行Tokenization,也…
