
引言
SQL作为目前最通用的数据库查询语言,其功能和特性复杂程度远超大家常用的“SELECT * FROM tbl”这样简单,一段好的SQL和差的SQL,其性能可能有几十上千倍的而写出一个能够兼顾性能和易用性的SQL,超越的不仅仅是了解多少新特性的新写法,而是要深入理解数据的处理过程,然后设计好的数据的处理过程。
因此想推出本系列文章,并取名为《奇思妙想的SQL》,希望能够以实际案例出发,和大家分享一些SQL处理数据的新方案新思路,并在过程中模拟对问题本质的理解,希望大家能够喜欢~。
本文为系列第1篇,分享下于蚂蚁集团数据转运改造升级流程中,针对重立方的优化实践。
一、场景描述
在做数据汇总计算和统计分析时,最头疼的就是去重类指标计算(比如用户数、商家数等),特别是还要带多种维度的下钻分析,由于其不可累加的特性,几乎每一项换一个统计维度组合,都得重新计算。数据量小时考虑可以自动化的用明细数据即时直接统计,但当数据量大时就不得不提前进行计算了。
典型场景如下:省、市、区等维度下的支付宝客户端的日支付用户数(其中省、市、区为用户支付时所在的位置,表格中数据指标对应的)。
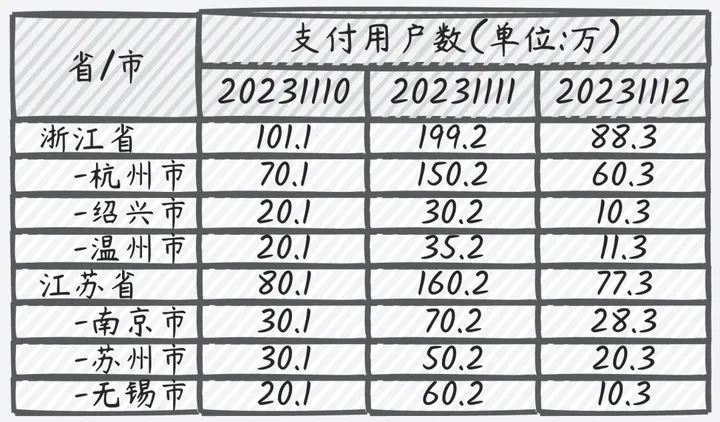
存在一种情况,某用户早上在杭州市使用支付宝支付了一次,下午跑到绍兴市时又使用支付宝线下支付了一次。那么在统计省+市维度的日支付用户数时,需要服务器托管网为杭州市、绍兴市市各维度下,需要按用户去重,只能为浙江省维度1。针对这种情况,通常就需要以Cube的方式完成数据预计算,同时每个维度组合都需要进行去重操作,因为不可累加。本文中的场景大致为去重立方。
二、常见的实现方法
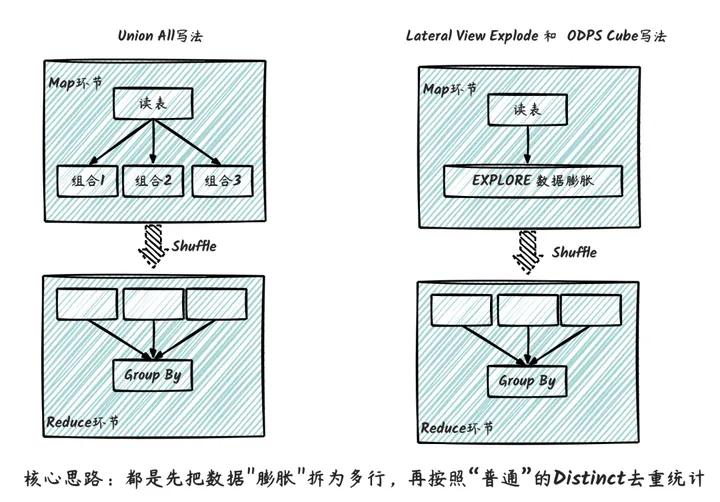
直接计算,每个维度组合单独计算。比如单独生成省、省+市、省+市+区等维度组合的多张表。每个表只计算固定的维度。然后是数据膨胀再计算,如并集All或者Lateral View Explode或者MaxCompute的Cube计算功能,通过数据膨胀实现一个数据满足多种维度组合的数据计算方法,如下图所示。

这个第三写法其实都类似,重点都在于如图所示对数据进行膨胀,再进行重统计。其执行流程如下图,核心思路去都是先把数据“膨胀”拆为多行,再按照“普通”的Distinct去重统计,因此性能上本身无严重差异,主要在于代码可维护性上。
三、性能分析
接下来方法核心都是先把数据“膨胀”拆为多行,再按照“普通”的不同去重统计,本身性能无差异,主要在于代码可维护性上。这几种方案计算耗时会随着需求维度组合线性增加,同时还要加上独特的本身对计算性能差的影响。
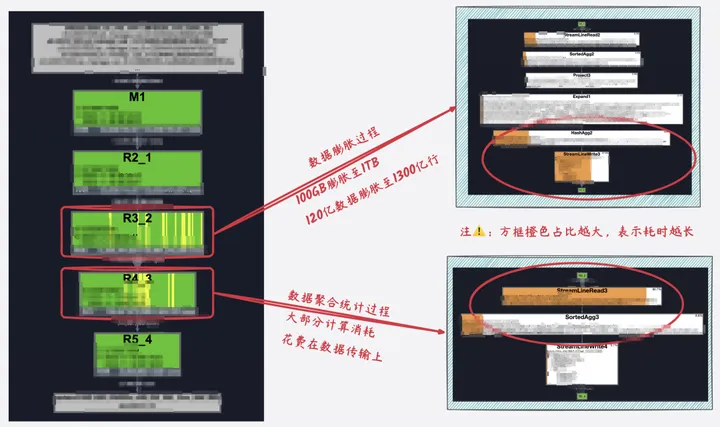
在实际实验中,我们发现,去重立方的计算过程中,80%+的计算成本消耗在数据膨胀和数据传输上。比如提取核心指标场景,需要计算各种组合维度下支付的用户数来实际实验中,大量100亿数据x25种维度组合进行测试,实际执行支撑任务如下图所示,其中R3_2为核心的数据膨胀过程,数据膨胀近10倍,中间结果数据大小由100GB膨胀至1TB 、数据量由100亿膨胀至近1300亿,大部分计算资源和计算运行时间都花在数据膨胀和传输上。若实际的组合维度进一步增加的话,数据膨胀大小也将进一步增加。
四、一个新思路
首先对问题进行拆解下,去重立方体的计算过程核心分为两个部分,数据膨胀+数据去重。数据膨胀解决的是一行数据同时满足多个维度组合的计算,数据去重块完成最终的去重统计,核心解决方案还是源于原始数据去匹配结果数据的需要。其中数据去重本身的计算量就会增大,而数据膨胀会导致这种情况加剧,因为计算过程中需要解拆和在shuffle过程中传输大量的数据。数据计算过程中是先膨胀再聚合,加上本身数据内容的中英文字符串内容增大,所以才导致大量的数据计算和传输成本。
而我们的核心思想是能够避免数据膨胀,同时进一步减少数据传输大小。因此我们联想到,是否可以采用类似用户打标签的数据打标方案,先进行数据去重生成UID粒度的中间数据,同时让需要的结果维度组合反向附加到UID粒度的数据上,这个过程中记录结果维度进行数量,用更小的数据结构去存储,避免数据计算过程中的大量数据传输。整个数据计算过程中,数据量理论上是逐渐收敛的,不会因为统计维度组合的增加而增加。
4.1.核心思想
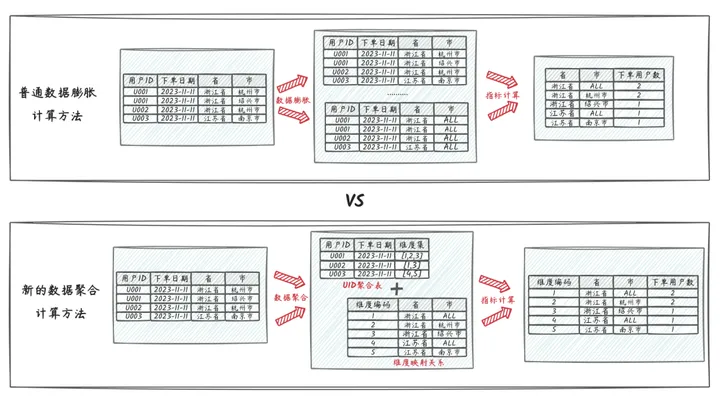
核心计算思路如上图,普通的数据膨胀计算立方体的方法,中间需要对数据进行膨胀,再聚合,其中结果统计服务器托管网需要的组合维度数就是数据膨胀的倍数,就像上面的“省、省+市”总共两个维度组合,数据预计要膨胀2倍。
而新的数据聚合方法,通过一定的策略方法将维度组合拆解为维度小表并进行编号,然后将哪些订单明确细数据聚合至用户粒度的中间流程数据,其中各类组合维度转换为数字标签记录到用户维度的数据记录上,整个计算过程数据量是呈收缩聚合的,不会膨胀。
4.2.逻辑实现
- 明细数据准备:以用户线下支付数据为例,明细记录包含订单编号、用户ID、支付日期、所在省份、最终所在市、支付金额。指标统计需求为统计包含省份、市组合维度+支付用户数的多维立方体。
| 订单编号 | 用户ID | 支付日期 | 所在省 | 所在市 | 支付金额 |
| 2023111101 | U001 | 2023-11-11 | 浙江省 | 杭州市 | 1.11 |
| 2023111102 | U001 | 2023-11-11 | 浙江省 | 绍兴市 | 2.22 |
| 2023111103 | U002 | 2023-11-11 | 浙江省 | 杭州市 | 3.33 |
| 2023111104 | U003 | 2023-11-11 | 江苏省 | 南京市 | 4.44 |
| 2023111105 | U003 | 2023-11-11 | 浙江省 | 温州市 | 5.55 |
| 2023111106 | U004 | 2023-11-11 | 江苏省 | 南京市 | 6.66 |
整体方案流程如下图。
- STEP1:对明细数据进行所需的要素提取(即Group By对应字段),得到维度集合。
- STEP2:对得到的维度集合生成Cube,物质Cube的行进行编码(假设需要所在省、所在省+所在市2种组合维度),可以用ODPS的Cube功能实现,再根据生成的Cube维度组合进行排序生成唯一编码。
| 原始维度:所在省 | 原始维度:所在省 | Cube 维度:所在省 | Cube 维度:所在市 | Cube行ID(可通过排序生成) |
| 浙江省 | 杭州市 | 浙江省 | 全部 | 1 |
| 浙江省 | 杭州市 | 浙江省 | 杭州市 | 2 |
| 浙江省 | 绍兴市 | 浙江省 | 全部 | 1 |
| 浙江省 | 绍兴市 | 浙江省 | 绍兴市 | 3 |
| 浙江省 | 温州市 | 浙江省 | 全部 | 1 |
| 浙江省 | 温州市 | 浙江省 | 温州市 | 4 |
| 江苏省 | 南京市 | 江苏省 | 全部 | 5 |
| 江苏省 | 南京市 | 江苏省 | 南京市 | 6 |
- STEP3:将Cube的行编码,根据映射关系回写到用户明细上,可用Mapjoin的方式实现。
| 订单编号 | 用户ID | 支付日期 | 所在省 | 所在市 | 汇总的Cube ID |
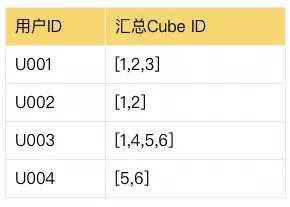
| 2023111101 | U001 | 2023-11-11 | 浙江省 | 杭州市 | [1,2] |
| 2023111102 | U001 | 2023-11-11 | 浙江省 | 绍兴市 | [1,3] |
| 2023111103 | U002 | 2023-11-11 | 浙江省 | 杭州市 | [1,2] |
| 2023111104 | U003 | 2023-11-11 | 江苏省 | 南京市 | [5,6] |
| 2023111105 | U003 | 2023-11-11 | 浙江省 | 温州市 | [1,4] |
| 2023111106 | U004 | 2023-11-11 | 江苏省 | 南京市 | [5,6] |
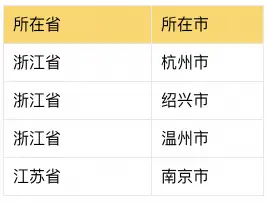
- STEP4:汇总到用户维度,可视化Cube ID集合字段进行去重(可以用ARRAY的DISTINCT)
- STEP5:按照Cube ID进行计数计算(由于STEP4已经去重啦,因此这里不需要再进行去重);然后按照映射关系进行维度还原。
| 立方体ID | 下单用户数指标 | Cube 还原维度:所在省 | Cube 还原维度:所在市 |
| 1 | 3 | 浙江省 | 全部 |
| 2 | 2 | 浙江省 | 杭州市 |
| 3 | 1 | 浙江省 | 绍兴市 |
| 4 | 1 | 浙江省 | 温州市 |
| 5 | 2 | 江苏省 | 全部 |
| 6 | 2 | 江苏省 | 江苏省 |
- 结束~
4.3.代码实现
WITH
-- 基本的明细数据表准备
base_dwd AS (
SELECT pay_no
,user_id
,gmt_pay
,pay_amt
,prov_name
,prov_code
,city_name
,city_code
FROM tmp_user_pay_order_detail
)
-- 生成多维Cube,并进行编码
,dim_cube AS (
-- Step02:CUbe生成
SELECT *,DENSE_RANK() OVER(PARTITION BY 1 ORDER BY cube_prov_name,cube_city_name) AS cube_id
FROM (
SELECT dim_key
,COALESCE(IF(GROUPING(prov_name) = 0,prov_name,'ALL'),'na') AS cube_prov_name
,COALESCE(IF(GROUPING(city_name) = 0,city_name,'ALL'),'na') AS cube_city_name
FROM (
-- Step01:维度统计
SELECT CONCAT(''
,COALESCE(prov_name ,''),'#'
,COALESCE(city_name ,''),'#'
) AS dim_key
,prov_name
,city_name
FROM base_dwd
GROUP BY prov_name
,city_name
) base
GROUP BY dim_key
,prov_name
,city_name
GROUPING SETS (
(dim_key,prov_name)
,(dim_key,prov_name,city_name)
)
)
)
-- 将CubeID回写到明细记录上,并生成UID粒度的中间过程数据
,detail_ext AS (
-- Step04:指标统计
SELECT user_id
,ARRAY_DISTINCT(SPLIT(WM_CONCAT(';',cube_ids),';')) AS cube_id_arry
FROM (
-- Step03:CubeID回写明细
SELECT /*+ MAPJOIN(dim_cube) */
user_id
,cube_ids
FROM (
SELECT user_id
,CONCAT(''
,COALESCE(prov_name,''),'#'
,COALESCE(city_name,''),'#'
) AS dim_key
FROM base_dwd
) dwd_detail
JOIN (
SELECT dim_key,WM_CONCAT(';',cube_id) AS cube_ids
FROM dim_cube
GROUP BY dim_key
) dim_cube
ON dwd_detail.dim_key = dim_cube.dim_key
) base
GROUP BY user_id
)
-- 指标汇总并将CubeID翻译回可理解的维度
,base_dws AS (
-- Step05:CubeID翻译
SELECT cube_id
,MAX(prov_name) AS prov_name
,MAX(city_name ) AS city_name
,MAX(uid_cnt ) AS user_cnt
FROM (
SELECT cube_id AS cube_id
,COUNT(1) AS uid_cnt
,CAST(NULL AS STRING) AS prov_name
,CAST(NULL AS STRING) AS city_name
FROM detail_ext
LATERAL VIEW EXPLODE(cube_id_arry) arr AS cube_id
GROUP BY cube_id
UNION ALL
SELECT CAST(cube_id AS STRING) AS cube_id
,CAST(NULL AS BIGINT) AS uid_cnt
,cube_prov_name AS prov_name
,cube_city_name AS city_name
FROM dim_cube
) base
GROUP BY cube_id
)
-- 大功告成,输出结果!!!
SELECT prov_name
,city_name
,user_cnt
FROM base_dws
;
- 实际的执行流程(ODPS的Logview)如下图。

4.4.实验效果
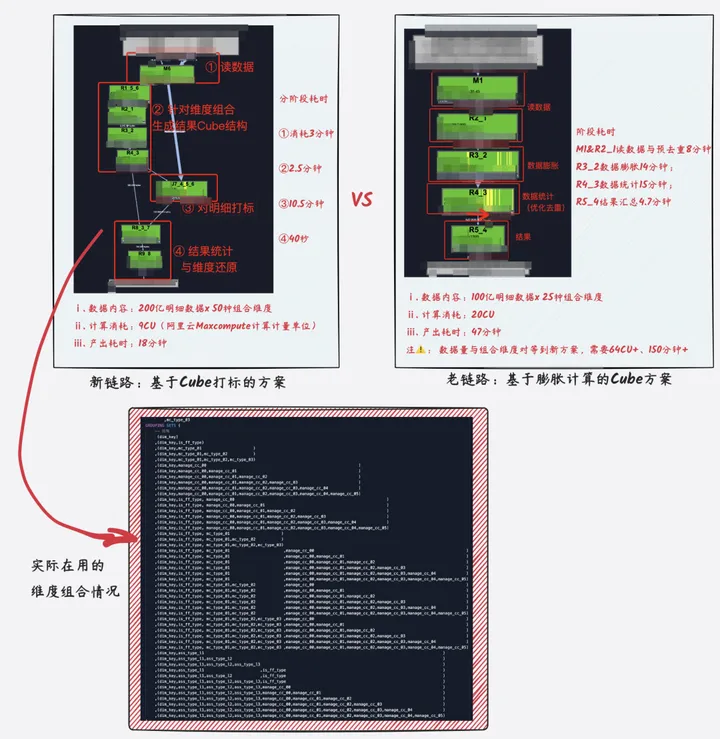
左边是基于Cube打标方案的新仓库。实验流程中将实验数据由100亿增加至200亿,组合维度数据由原来的25个增加至50种组合维度,整体运行在18分钟,若只计算和原始数据量、组合维度相同的数据,整体计算运行可控制在10分钟内。
右侧是基于膨胀数据计算的老仓库。实验数据设定为100亿,组合维度数为25种,中间过数据将膨胀至1300亿+,数据大小急剧膨胀至1TB+,整体运行47分钟。如果此方案扩展至新方法的200亿数据x50种组合维度,中间过程数据将膨胀至4000亿+,数据大小增加将膨胀至3TB+,整体计算指标将达到2.5小时+。
新方法目前已经在业务核心线索订单上线,在数据统计维度组合、数据计算量都大幅增加的情况下,整体核心指标侧壁之前,提前1小时以上,进一步相关的有效保障了核心指标是数据稳定性。
4.5.方案总结
常见的基于膨胀数据的Cube计算方法,数据计算大小和过程数据传输量将随着组合维度的数量呈线性增长,组合维度数越多,消耗在数据膨胀与Shuffle传输的资源和运动轨迹越多在实验过程中,100亿实验数据x25种维度组合场景,数据过程已经膨胀至1300亿+,数据大小由100GB膨胀至1TB,当数据量和维度组合数进一步增加时,整个计算过程基本上难以完成。
为了解决数据膨胀过程中产生大量过程数据,我们基于数据打标的思路反向操作,首先对数据聚合为UID粒度,过程中将需要的维度组合转化编码数字并赋予明细数据上,整个计算过程数据呈收敛聚合状,数据计算过程稳定,不会随着维度组合的进一步增加而急剧增加。在实验中,将实验数据由100亿增加至200亿+,组合维度由原来的25个增加至50种组合维度,整体运行控制在18分钟左右。若同等的数据量,采用老的数据膨胀方案,中间流程数据将膨胀至4000亿+,数据大小将增加至3TB+,整体计算运行时间将达到2.5小时+。
综上,当前的方案整体性能确实高于以往有完成的提升,并且不会随着维度组合的增加而有明显的增加。但当前的方案也有不足之处,即代码的可理解性和可性维护性,过程中的打标计算过程虽然不太固定,但整体上需要一个流程初始化理解的过程,目前尚无法实现普通UnionAll/Cube等方案的易读和易写。另外,当组合维度数很少(即数据膨胀倍数不高)时,两者的性能差异不大,此时建议还是用原始普通的Cube计算方案;但当组合维度数达到几十倍时,可以用这种数据打法修改指标的思路进行了压缩,毕竟此时的性能优势开始凸显,并且维度组合数加权,此方案的性能优势较大。
五、其他方案
BitMap方案。核心思路在于将不可累加的数据指标,通过可累加计算的数据结构,近似实现可累加指标的效果。具体实现过程方案是对用户ID进行编码,存入BitMap结构中,比如一个二进制位表示一个用户是否存在,消耗1个Bit。维度统计上卷时,再对BitMap的数据结构进行合并和计数统计。
HyperLogLog方案。非精确数据去重,相对于Distinct的精确去重,性能提升明显。
这两种方案,性能上相对于普通的Cube计算有巨大的提升,但BitMap方案需要对去重统计用的UID进行编码存储,对一般用户的理解和实操成本更高,除非系统级集成此功能,否则通常需要额外的代码开发实现。而HyperLogLog方案的一大弊端就是数据的不精确统计。
作者|佳二
原文链接
本文为阿里云原创内容,未经允许不得转载。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: Batrix企业能力库之物流交易域能力建设实践 | 京东物流技术团队
【直播预告】替代 Oracle,我们还有多长的路要走? 简介 Batrix企业能力库,是京东物流战略级项目-技术中台架构升级项目的基础底座。致力于建立企业级业务复用能力平台,依托能力复用业务框架Batrix,通过通用能力/扩展能力的定义及复用,灵活支持业务差异…
