

生成式人工智能编码工具正在改变开发人员处理日常编码任务的方式。从记录我们的代码库到生成单元测试,这些工具有助于加快我们的工作流程。然而,就像任何新兴技术一样,总是有一个学习曲线。因此,当人工智能驱动的编码助手无法生成他们想要的输出时,开发人员(无论是初学者还是经验丰富的开发人员)有时会感到沮丧。(有没有觉得很熟悉?)
例如,当要求 GitHub Copilot 使用 p5.js(一个用于创意编码的 JavaScript 库)绘制冰淇淋甜筒🍦时,我们不断收到不相关的建议,或者有时根本没有建议。但当我们更多地了解 GitHub Copilot 处理信息的方式时,我们意识到我们必须调整与其通信的方式。
以下是 GitHub Copilot 生成不相关解决方案的示例:
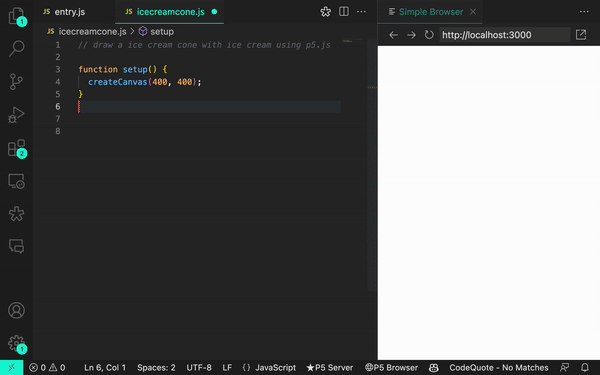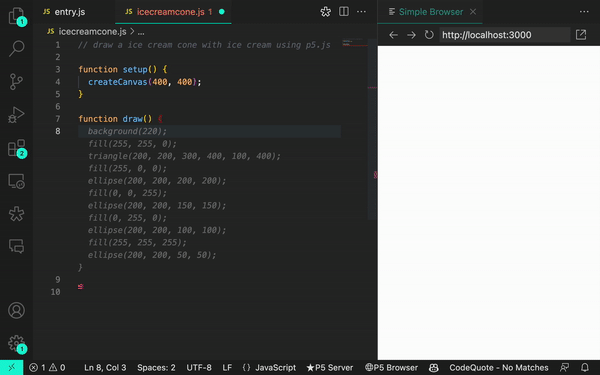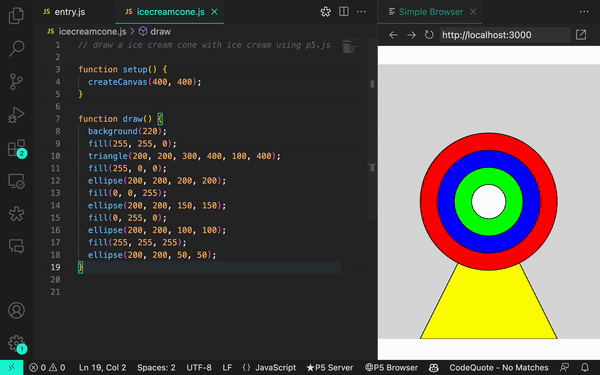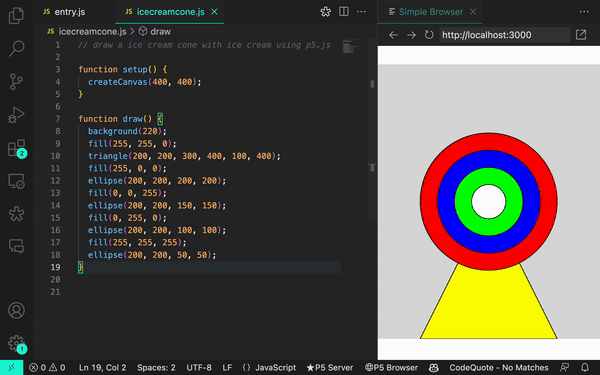
当我们调整提示时,我们能够生成更准确的结果:
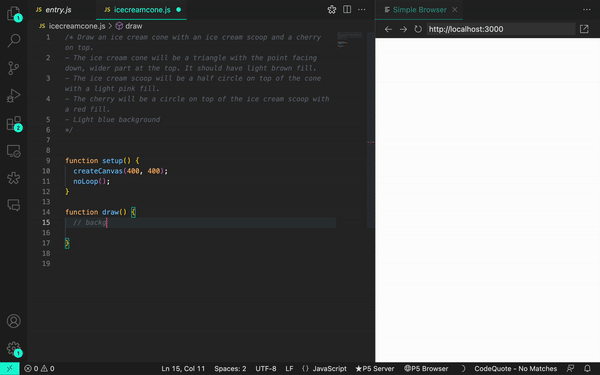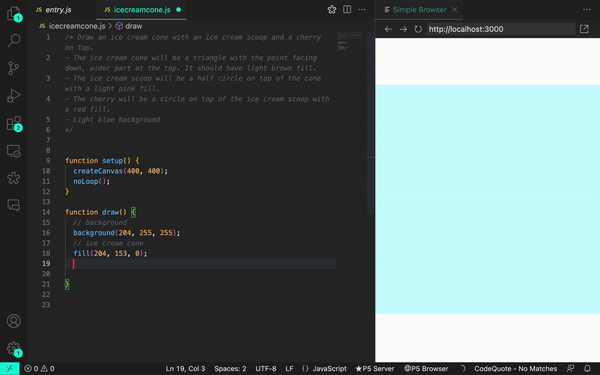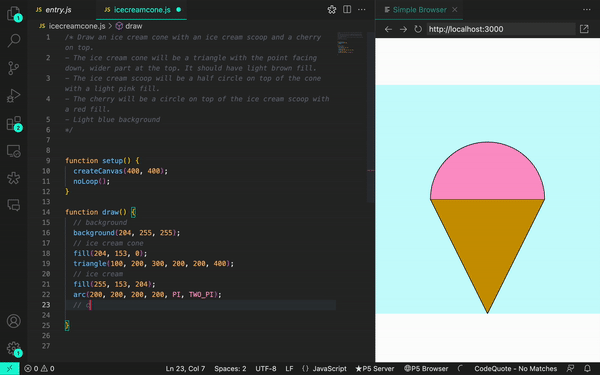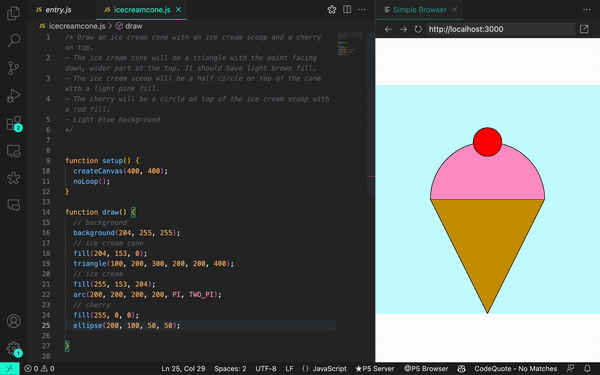
进步胜过完美
即使我们拥有使用人工智能的经验,我们也认识到每个人都处于生成式人工智能技术的试错阶段。我们也知道提供通用提示制作技巧的挑战,因为模型各不相同,开发人员正在解决的个别问题也各不相同。这不是一个最终的、万能的指南。相反,我们正在分享我们所学到的有关即时制作的知识,以在软件开发的新时代加速集体学习。
什么是提示,什么是提示工程?
这取决于你和谁说话。
在生成式 AI 编码工具中,提示可能意味着不同的含义,具体取决于您是询问正在构建和微调这些工具的机器学习 (ML) 研究人员,还是在 IDE 中使用这些工具的开发人员。
在本指南中,我们将从在 IDE 中使用生成式 AI 编码工具的开发人员的角度来定义术语。但为了让您全面了解,我们还在图表中添加了下面的 ML 研究人员定义。
提示 提示工程 上下文 开发人员 开发人员编写的代码块、单行代码或自然语言注释,以从 GitHub Copilot 生成特定建议 在 IDE 中提供说明或注释以生成特定编码建议 开发人员提供的详细信息,用于指定生成式 AI 编码工具的所需输出 ML 研究人员 编译 IDE 代码和相关上下文(IDE 注释、打开文件中的代码等),由算法不断生成并发送到生成式 AI 编码工具的模型 创建将为大型语言模型生成提示(IDE 代码和上下文的编译)的算法 算法发送到大型语言模型 (LLM ) 的详细信息(例如打开文件中的数据以及光标之前和之后编写的代码)作为有关代码的附加信息
使用 GitHub Copilot 进行快速制作的 3 个最佳实践
1. 设定高水平目标。🖼️
如果您有空白文件或空代码库,这将非常有帮助。换句话说,如果 GitHub Copilot 对您想要构建或完成的内容的上下文为零,那么为 AI 结对程序员设置舞台可能非常有用。在您开始详细介绍之前,它有助于为 GitHub Copilot 提供您希望其生成的内容的总体描述。
当提示 GitHub Copilot 时,将这个过程想象成与某人对话:我应该如何分解问题,以便我们可以一起解决它?我将如何与这个人进行结对编程?
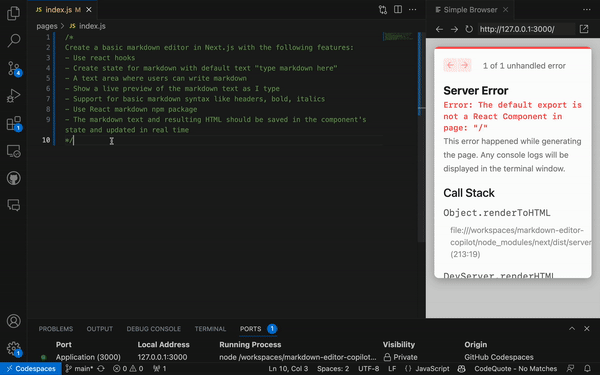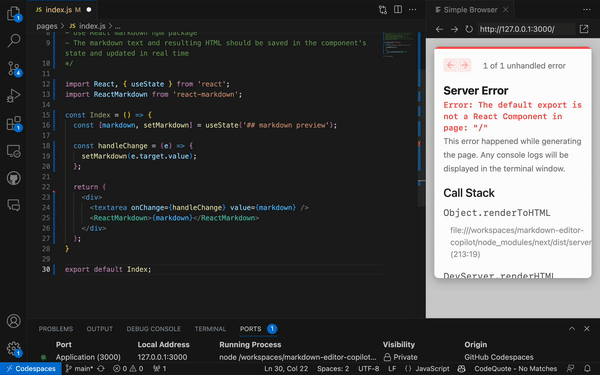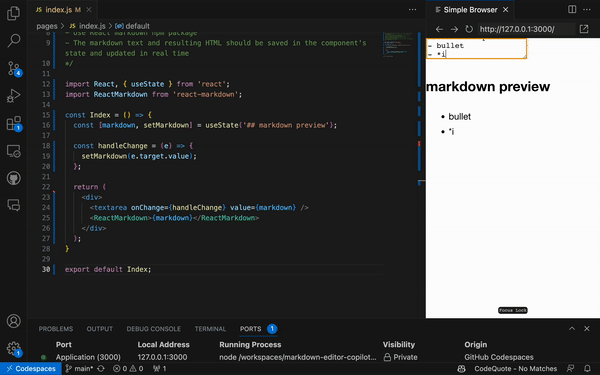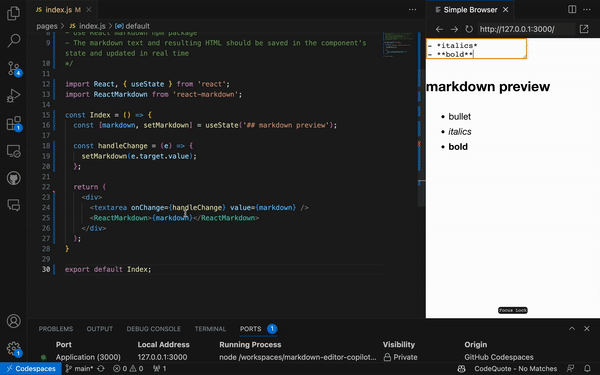
例如,在 Next.jst 中构建 Markdown 编辑器时,我们可以编写这样的注释
/*
Create a basic markdown editor in Next.js with the following features:
- Use react hooks
- Create state for markdown with default text "type markdown here"
- A text area where users can write markdown
- Show a live preview of the markdown text as I type
- Support for basic markdown syntax like headers, bold, italics
- Use React markdown npm package
- The markdown text and resulting HTML should be saved in the component's state and updated in real time
*/这将提示 GitHub Copilot 生成以下代码,并在 30 秒内生成一个非常简单、无样式但功能齐全的 Markdown 编辑器。我们可以利用剩余的时间来设计组件的样式:
注意:这种详细程度可以帮助您创建更理想的输出,但结果可能仍然是不确定的。例如,在评论中,我们提示 GitHub Copilot 创建默认文本“在此键入 markdown”,但它生成了“markdown 预览”作为默认词。
2. 让你的要求简单而具体。旨在接收来自 GitHub Copilot 的简短输出。🗨️
一旦您将您的主要目标传达给人工智能结对程序员,请阐明实现该目标所需遵循的逻辑和步骤。当您分解事情时,GitHub Copilot 可以更好地理解您的目标。(想象一下你正在写一份食谱。你会把烹饪过程分解成不连续的步骤——而不是写一段描述你想做的菜。)
让 GitHub Copilot 在每一步之后生成代码,而不是要求它一次性生成一堆代码。
以下是我们向 GitHub Copilot 提供用于反转函数的分步说明的示例:
3. 举一两个 GitHub Copilot 示例。✍️
从示例中学习不仅对人类有用,而且对人工智能结对程序员也有用。例如,我们想从下面的数据数组中提取名称并将其存储在一个新数组中:
const data = [
[
{ name: 'John', age: 25 },
{ name: 'Jane', age: 30 }
],
[
{ name: 'Bob', age: 40 }
]
];当我们没有向 GitHub Copilot 展示示例时……
// Map through an array of arrays of objects to transform data
const data = [
[
{ name: 'John', age: 25 },
{ name: 'Jane', age: 30 }
],
[
{ name: 'Bob', age: 40 }
]
];
const mappedData = data.map(x => [x.name](http://x.name/));
console.log(mappedData);
// Results: [undefined, undefined]它生成了错误的地图用法:
const mappedData = data.map(x => [x.name](http://x.name/));
console.log(mappedData);
// Results: [undefined, undefined]相比之下,当我们确实提供了一个例子时……
// Map through an array of arrays of objects
// Example: Extract names from the data array
// Desired outcome: ['John', 'Jane', 'Bob']
const data = [
[{ name: 'John', age: 25 }, { name: 'Jane', age: 30 }],
[{ name: 'Bob', age: 40 }]
];
const mappedData = data.flatMap(sublist => sublist.map(person => person.name));
console.log(mappedData);我们收到了我们想要的结果。
const mappedData = data.flatMap(sublist => sublist.map(person => person.name));
console.log(mappedData);
// Results: ['John', 'Jane', 'Bob']详细了解 AI 训练的常见方法,例如零样本学习、单样本学习和少样本学习。
使用 GitHub Copilot 进行快速制作的三个额外技巧
以下三个额外提示可帮助指导您与 GitHub Copilot 的对话。
1. 根据提示进行实验。
对话与其说是一门科学,不如说是一门艺术,即时创作也是如此。因此,如果您在第一次尝试时没有收到您想要的内容,请按照上述最佳实践重新设计提示。
例如,下面的提示是模糊的。它不为 GitHub Copilot 生成相关建议提供任何上下文或边界。
# Write some code for grades.py 我们迭代了提示以使其更加具体,但我们仍然没有得到我们想要的确切结果。这是一个很好的提醒,即为提示添加特异性比听起来更难。从一开始就很难知道您应该包含哪些关于您的目标的详细信息,以便从 GitHub Copilot 生成最有用的建议。这就是我们鼓励尝试的原因。
下面的提示版本比上面的更具体,但没有明确定义输入和输出要求。
# Implement a function in grades.py to calculate the average grade我们通过设置边界并概述我们希望函数执行的操作再次尝试提示。我们还重新表述了注释,使功能更加清晰(为 GitHub Copilot 提供了明确的验证意图)。
这一次,我们得到了我们想要的结果。
# Implement the function calculate_average_grade in grades.py that takes a list of grades as input and returns the average grade as a floating-point number2. 保持几个相关选项卡打开。
我们没有您应该保持打开的选项卡的确切数量,以帮助 GitHub Copilot 将您的代码置于上下文中,但根据我们的经验,我们发现一两个是有帮助的。
GitHub Copilot 使用一种称为相邻选项卡的技术,允许 AI 结对程序员通过处理 IDE 中打开的所有文件(而不仅仅是您正在处理的单个文件)来将您的代码置于上下文中。但是,不能保证 GItHub Copilot 会将所有打开的文件视为代码的必要上下文。
3. 使用良好的编码实践。
这包括提供描述性变量名称和函数,以及遵循一致的编码风格和模式。我们发现,与 GitHub Copilot 合作鼓励我们遵循我们在职业生涯中学到的良好编码实践。
例如,在这里我们使用了描述性函数名称,并遵循利用蛇形命名法的代码库模式。
def authenticate_user(username, password):结果,GitHub Copilot 生成了相关代码建议:
def authenticate_user(username, password):
# Code for authenticating the user
if is_valid_user(username, password):
generate_session_token(username)
return True
else:
return False将此与下面的示例进行比较,在该示例中我们引入了不一致的编码风格并且对函数的命名也很糟糕。
def rndpwd(l):GitHub Copilot 没有建议代码,而是生成了一条评论:“代码放在这里。”
def rndpwd(l):
# Code goes here保持聪明
生成式人工智能编码工具背后的法学硕士旨在从训练数据中查找和推断模式,将这些模式应用到现有语言,然后生成遵循这些模式的代码。考虑到这些模型的庞大规模,它们可能会生成一个尚不存在的代码序列。正如您查看同事的代码一样,您应该始终评估、分析和验证人工智能生成的代码。
一个练习示例👩🏽💻
首先,您需要安装 GitHub Copilot 并在 IDE 中打开。我们还可以访问GitHub Copilot 聊天的早期预览版,当我们对代码有疑问时,我们一直在使用它。如果您没有 GitHub Copilot 聊天功能,请注册加入候补名单。在此之前,您可以将GitHub Copilot与 ChatGPT 配对。
更具生成性的人工智能提示制作指南
- 使用 GitHub Copilot 进行快速工程的初学者指南
- AI 快速工程
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
本文分享自华为云社区《深入理解Java中的Reader类:一步步剖析》,作者:bug菌。 前言 在Java开发过程中,我们经常需要读取文件中的数据,而数据的读取需要一个合适的类进行处理。Java的IO包提供了许多类用于数据的读取和写入,其中Reader便是其中…
