
作者:小牛呼噜噜 | https://xiaoniuhululu.com
计算机内功、源码解析、科技故事、项目实战、面试八股等更多硬核文章,首发于公众号「小牛呼噜噜」
- 什么是幂等性?
- 为什么需要保证幂等性?
- 接口幂等设计和防止重复提交可以等同吗?
-
常用保证幂等性的措施
- 先select再insert
- 数据库设置唯一索引或唯一组合索引
- 去重表
- insert中加入exist条件判断
- 悲观锁
- 乐观锁
- 状态机
- 分布式锁
- token机制
- 尾语
什么是幂等性?
大家好,我是呼噜噜,所谓幂等性就是:任意次数请求 同一个资源,对资源的状态产生的影响和执行一次请求是相同的。
比如对于接口来说,无论调用多少次同一个接口,对资源的状态都只产生一次影响
为什么需要保证幂等性?
为什么需要做接口的幂等性?如果不做会发生什么事情?我们在实际企业开发过程中,如果仅是对数据库进行查询、删除指定记录操作,重复提交是没啥问题的。但是如果是新增或者修改操作,就需要考虑重复提交的问题。
比如,如果一个订单支付的时候,因各种原因重复提交多次,那如果没有幂等性处理的话,这个订单将会被支付多次的钱,这种和钱有关的错误是绝对不能容忍的。
经常发生重复提交的场景:
- 当我们在公司的系统里面,提交表格,前端没有对保存按钮的做控制,可以多次点击,然后我们又不小心快速点了多次,或者是网络卡顿, 还是其他原因,以为没有成功提交,就一直点击保存按钮,这样都会产生重复提交表单请求。
- 在实际开发过程中,网络波动是常有的事,所以很多时候 HTTP 客户端工具都默认开启超时重试的机制,这样就无法避免产生重复的请求。
- 还有就是项目可能使用一些中间件,比如kafka消费生产者产生的消息时,可能读到重复的消息,这样也会产生重复的请求。
- ……
接口幂等设计和防止重复提交可以等同吗?
接口幂等和防止重复提交有交集,但是严格来说并不完全等同
- 防重设计,主要从客户端/前端的角度来解决,主要为了避免重复提交,对每次请求的返回结果无限制,前端常见的手段:点击提交按钮变灰、点击后跳转结果页、每次页面初始化生成随机码,提交时随机码缓存,后续重复的随机码请求直接不提交
- 幂等设计,强调更多地是当重复提交请求无法避免的时候,还能保证每次请求都返回一样的结果。像我们上面对前端做的限制,是能绕过去的,抓包是能直接把接口给抓出来的,比如恶意批量调用接口,所以企业级系统,前后端都需要做限制,特别是涉及到钱的业务。绝不能偷懒,后面我们来详细讲讲对接口幂等的限制。
常用保证幂等性的措施
先select再insert
新手小白,在往数据库插入数据时,为了防止重复插入,一般会在insert前,通过关键字去先select一下,如果查不到记录就执行insert操作,否则就不插入
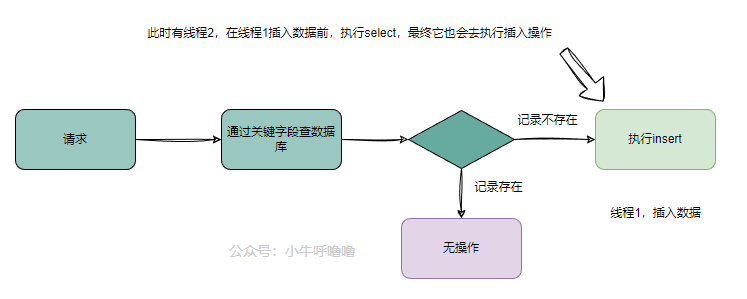
但如果并发场景下,这个就不行了。比如线程2,在线程1插入数据前,执行select,最终它也会去执行插入操作,这样就会产生2条记录。所以在实际开发过程中,是不建议如此操作的。
数据库设置唯一索引或唯一组合索引
数据库设置唯一索引是我们最常用的方式,一个非常简单,并且有效的方案。当记录多次插入数据库,会由于Id或者关键字段索引唯一的限制,导致后续记录插入失败
--创建唯一索引
alter table `order` add UNIQUE KEY `索引名` (`字段`);
第一条记录插入到数据库中,当后面其他相同的请求,再插入时,数据库会报异常Duplicate entry 'xx' for key 'xx_name',这个异常不会对服务器托管网数据库中既有的数据有影响,我们只需对异常进行捕获就行,直接返回,代表已经执行过当前请求。
笔者这里介绍一个骚操作:INSERT IGNORE
insert ignore INTO tableName VALUES ("id","xxx")
咦,会有读者觉得,这样哪怕索引冲突了,数据库会忽略错误返回影响行数0,这样就不用再在代码中,手动捕捉异常了,又方便又省事!
但事实真这样吗???

如果希望在每次插入新记录时,自动地创建主键字段的值。一般会将主键id的属性设为AUTO_INCREMENT,
如果我们使用INSERT IGNORE时,没有成功新增记录,但是AUTO_INCREMENT会自动+1,binlog中也没有 INSERT IGNORE 语句日志。这个会导致主从数据一致性问题,如果线上环境数据库是主从架构,从库该字段的AUTO_INCREMENT值会和主库不一致,切库(从库变成总库)的时候服务器托管网会冲突。
当然,查询Mysql官方手册,发现innodb_autoinc_lock_mode用于平衡性能与主从数据一致性,令 innodb_autoinc_lock_mode=0可以解决这个问题,将其设为0后, 所有的insert语句都要在语句开始的时候得到一个表级的auto_inc锁,在语句结束的时候才释放这把锁。也就是说在INSERT未成功执行时AUTO_INCREMENT不会自增,但是其也有缺点,会影响到数据库的并发插入性能。
Mysql官方手册明确指出,The setting innodb_autoinc_lock_mode=0 should not be used except for compatibility purposes.除非出于兼容性目的,否则不应设置innodb_autoinc_lock_mode=0。所以我们还是老老实实手动捕捉异常,慎用insert ignore
**innodb_autoinc_lock_mode: **在MySQL8中, 默认值为 2 (轻量级锁) , 在MySQL8之前, 5.1之后, 默认值为 1(混合使用这2种锁), 在更早的版本是 0(auto_inc锁)
去重表
去重表,其实也是唯一索引方案的一个变种,原表不太适合再新建唯一索引了,且数据量不大的话。我们可以再新建一张去重表,把唯一标识作为唯一索引,然后把对原表的操作和同时新增去重表 ,放在一个事务中,如果重复创建,去重表会抛出唯一约束异常,事务里所有的操作就会回滚。
insert中加入exist条件判断
有时候我们会遇到非常复杂的表,表结构确定了,比如已经有了许多索引字段,不太适合再新建索引的时候,呼噜噜 在这里再提供一个”骚操作”:可以通过insert中加入exist来解决重复插入的问题。
比如:
insert into order(id,code,password)
select ${id},${code},${password}
from order
where not exists(select 1 from order where code = ${code}) limit 0,1;
上面的sql注意思路就是将查询和插入写在同一个sql中,需要注意的是limit 0,1最后一定要加上,不然可能会出现重复插入的情况
悲观锁
悲观锁,顾名思义就是,对数据被外界或者内部修改处理时,持”悲观”态度,总认为会发生并发冲突,所以会在整个数据处理过程中,将数据锁定。
悲观锁的实现,通常依靠数据库提供的锁机制实现,在这里以mysql为例,最典型的就是”for update”。
select * from order where id = "xxxx" for update;
需要注意的是:使用悲观锁,需要先关闭mysql的自动提交功能,将 set autocommit = 0;
for update仅适用于Mysql中lnnoDB引擎,默认是行级锁,如果sql中有明确指定的主键时候,是行级锁,如果没有,会锁表(非常危险的操作)。for update一般和事务配合使用,一旦用户对某个行施加了行级加锁,则该用户可以查询也可以更新被加锁的数据行,其它用户只能查询但不能更新被加锁的数据行。直到显示提交事务(由于关闭了mysql的自动提交)时,for update获取的锁会自动释放。
悲观锁虽然保证了数据处理的安全性,但会严重影响并发效率,降低系统吞吐量。适用于并发量不大、又对数据一致性比较高的场景。
乐观锁
乐观锁,和悲观锁相反,对数据被外界或者内部修改处理时,持”乐观”态度,总认为不会发生并发冲突,所以不会上锁,只需在更新的时候会去判断一下在此期间有没有去更新这个数据。
一般是使用版本号或者时间戳,比如
- 我们在数据库中,给订单表增加一个version 字段
- select数据时,将version一起读出,当提交数据更新时,判断版本号是否和取出来的是否一致。如果不一致就代表,已更新,那就不更新。如果一致就继续执行更新操作。
- 每次更新时,除了更新指定的字段,也要将version进行+1操作
update order set name=#{xxx},version=#{version} where id=#{id} and version 不加锁就能保证幂等性,又增加了系统吞吐量,如果频繁触发版本号不一致的情况,反而降低了性能。
状态机
状态机也是乐观锁的一种,比如企业级货品管理系统中,订单的转单流程,将订单的状态,设置为有限的几个(1-下单、2-已支付、3-完成、4-发货、5-退货),通过各个状态依次执行转换,来控制订单转单的流程,是非常好的选择。
分布式锁
上面介绍了许多方案,在单体应用中是没啥问题的,但是随着时代的发展,现在微服务大行其道,以上方法就不太适应了。
在分布式系统中,上面唯一索引对于全局来说,是无法确定的,我们可以引入第三方分布式锁来保证幂等性设计。分布式锁,主要是用来 当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问
实现分布式锁常见的方法有:基于redis实现分布式锁,基于 Consul 实现分布式锁,基于 zookeeper实现分布式锁等等,本文重点介绍最常见的基于redis实现分布式锁,set NX PX + Lua
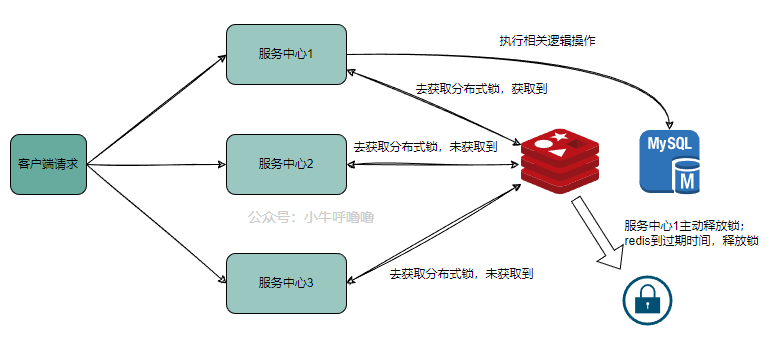
- 在分布式系统中,插入或者更新的请求,业务逻辑中先获取唯一业务字段,比如订单id之类的,接着需要获取分布式锁,对redis执行下述命令
SET key value NX PX 30000
各参数的含义:
- SET: 在Redis 2.6.12之后,
set命令整合了setex命令的功能,支持了原子命令加锁和设置过期时间的功能 - key:业务逻辑中先获取唯一业务字段,比如订单id,code之类,也可以在前面加一些系统参数当前缀,这个完全可以自定义
- value: 填入是一串随机值,必须保证全局唯一性(在释放锁时,我们需要对value进行验证,防止误释放),一般用uuid来实现
- NX: 表示key不存在时才设置,如果存在则返回 null。还有另一个参数XX,表示key存在时才设置,如果不存在则返回NULL
- PX 30000: 表示过期时间30000毫秒,指到30秒后,key将被自动删除。这个非常的重要,如果设置过短,无法有效的防止重复请求,过长的话会浪费redis的空间
- 然后执行插入或者更新,或者其他相关业务逻辑,在释放锁之前,如果有其他中心的服务来请求,由于key是一样的,无法获取锁,就代表这些是重复请求,不操作,直接返回
- 执行完插入或者更新后,需要释放锁,一定要判断释放的锁的value和与Redis内存储的value是否一致,不然如果直接删除的话,会把其他中心服务的锁释放调。
这种先查再删的2步操作,我们可以使用lua脚本,把他们变成一个”原子操作”
Lua 是一种轻量小巧的脚本语言,Redis会将整个脚本作为一个整体执行,中间不会被其他命令打断插入(l类似与事务),可以减少网络开销,方便复用
以下是Lua脚本,通过 Redis 的 eval/evalsha 命令来运行:
if redis.call('get', KEYS[1]) == ARGV[1] //判断value是否一致
then
return redis.call('del', KEYS[1])//删除key
else
return 0
end
这样依靠单体的redis实现的分布式锁能够很好的解决,微服务系统的幂等问题。但是有些公司的微服务更加庞大,redis也是集群的话,set NX PX + Lua就不够看了,这里介绍Redis作者推荐的方法-Redlock算法,这里就先不展开讲了,不然文章篇幅过长。先挖个坑,后面有空填一下:)
token机制
最后再补充一个方案利用token机制,每次调用接口时,使用token来标识请求的唯一性。token也叫令牌,天然适合微服务。基于token+redis来设计幂等的思路还是比较简单的,和分布式锁类似:
- 客户端发送请求,得去服务端获取一个全局唯一的一串随机字符串作为Token 令牌(每次请求获取到的都是一个全新的令牌),把令牌保存到 redis 中,需要有过期时间,同时把这个 ID 返回给客户端
- 客户端第二次调用业务请求的时候必须携带这个 token,服务端会去校验redis中是否有该token。如果存在,表示这是第一次请求,删除缓存中的token(这边还是建议用lua脚本,保证操作的原子性);如果缓存中不存在,表示重复请求,直接返回。
尾语
幂等性是系统服务对外一种承诺,特别业务中涉及的钱的部分,一定要慎重再慎重。虽然前端做限制会更容易点,但前后端都需要做努力,除了本文介绍的常见的方案,大家也可以集思广益,毕竟技术在发展,单体到集群分布式,还会继续发展,还有有新的问题产生。
本文虽然通篇在将幂等的重要性和如何实现幂等,但不可否认,幂等肯定导致系统吞吐量、并发能力的下降,企业级应用还是得根据业务,权衡利弊,感谢大家的阅读。
参考资料:
https://www.cnblogs.com/linjiqin/p/9678022.html
全文完,感谢您的阅读,如果我的文章对你有所帮助的话,还请点个免费的赞,你的支持会激励我输出更高质量的文章,感谢!

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
