
大家好,我是易安!今天我们来谈一谈缓存应该如何设计。
什么是缓存
缓存是一种临时储存数据的方式。当用户查询数据时,系统会首先在缓存中查找,如果数据已经存在于缓存中,则直接使用,否则系统会到数据的原始位置寻找。因此,缓存本质上是一种用空间换时间的技术,通过数据在空间上的重复,提高数据访问的速度。
然而,随着分布式和云计算技术的不断发展,数据存储技术也在不断地变化。不同的存储技术在价格和性能上存在巨大的差异。因此,在设计软件时,如果没有合理设计多层级的缓存系统,不仅会浪费资金,而且也难以达到期望的性能收益。
什么时候用缓存
让我们从两个问题开始,了解缓存设计应该在什么时候进行以及如何根据不同数据类型的特性进行比较分析,以实现优秀的缓存设计。
- 在互联网应用服务中,缓存技术的目的仅仅是为了提高访问速度吗?
实际上,缓存技术在分布式系统中扮演了一个重要的系统级性能设计的角色。例如,当某个数据库的负载接近系统瓶颈时,我们可以通过缓存技术将负载分摊到其他数据库中,以实现负载均衡。因此,使用缓存的目的不仅仅是为了提高访问速度。
- 在大型系统中,是否需要为每种数据类型都设计缓存机制?
实际上不需要。在实际业务场景中,系统中包含的业务数据种类非常多,无法为每种数据类型都设计和实现缓存机制。因此,我们需要识别哪些数据访问对性能影响较大,以确定需要使用缓存机制的数据类型。
如何识别需要使用缓存机制的数据类型呢?一般我们需要对性能建模设计方法,即通过分析和评估手段,识别出哪些数据访问操作对性能影响最为关键,然后进行缓存设计。
在确定需要使用缓存机制的数据类型后,你可能会发现,这些数据类型之间的特性差异非常大,如果使用同一种缓存设计的话,难以发挥出软件性能的最佳状态。
因此,在这里,我总结了三种需要使用缓存机制的数据类型:不变性数据、弱一致性数据和强一致性数据。了解这三种数据类型的差异以及对应的缓存机制设计方法,可以帮助你实现优秀的缓存设计。
不变性数据
首先是不变性数据,它代表数据永远不会发生变化,或者在较长一段时间内不会发生变化。因此,我们可以将这类数据作为优先考虑使用缓存技术的一种数据类型,在实际业务场景中也非常常见。例如,Web服务中的静态网页和静态资源,数据库表中的列数据和key的映射关系,以及业务的启动配置等,都可以视为不变性数据。
另外,不变性数据还意味着实现分布式一致性非常容易。我们可以为这些数据选择任意的数据存储方式,也可以选择任意的存储节点位置。因此,在实现缓存机制时,我们可以采用灵活且简单的方式。例如,在Java语言中,你可以直接使用内存Caffeine或内置的数据结构作为缓存。
值得注意的是,在针对不变性数据进行缓存设计时,可以选择永久不失效或基于时间的失效方式作为缓存失效机制。如果采用基于时间的失效方式,你还需要根据具体业务需求,在缓存容量和访问速度之间进行权衡。
弱一致性数据
第二种数据类型是弱一致性数据,它代表数据经常发生变化,但是业务对数据的一致性要求不高。换句话说,不同用户在同一时间点上看到的数据可能不完全一致,但这是可以接受的。
由于这类数据对一致性的要求较低,因此在设计缓存机制时,我们只需要实现最终一致性即可。在实际业务中,这类数据非常常见,例如业务的历史分析数据和一些搜索查找返回的数据,即使最近的一些数据没有记录,也不会对业务产生影响。
另外,快速识别这类数据还有一个方法,那就是使用数据库Replica(复制)节点中读取的数据。大部分数据库Replica节点的数据都不满足强一致性要求,因此可以认为这些数据是弱一致性数据。
针对弱一致性的数据,我们通常使用基于时间的缓存失效机制。由于弱一致性的特性,你可以选择各种数据存储技术,如内存缓存或分布式数据库缓存。你甚至可以基于负载均衡的调度,设计多层级缓存机制。
强一致性数据
第三种缓存数据类型是强一致性数据,它指的是数据经常发生变化,且业务对数据库的一致性要求非常高。换句话说,任何用户在系统中的任何地方看到的数据都应该是最新的。
我不建议在针对这种类型的数据使用缓存机制,因为这会引入新的问题并增加复杂度。例如,用户可以直接提交和修改数据,如果没有同步修改缓存中的数据,就会导致数据不一致性,从而导致严重的业务故障。
但在某些特殊的业务场景中,如果有个别数据访问频率非常高,我们仍需要通过缓存机制来提升性能。在设计缓存机制时,需要注意以下两点:
- 缓存的实现方式必须 采用修改同步。换句话说,所有的数据修改都必须同步更新缓存和数据库中的数据。
- 需要确定特定业务流程中缓存数据可以 使用多长时间。例如,某些缓存数据只能在单个业务流程中使用,不能跨业务流程使用。
需要注意的是,使用缓存目的是为了性能优化,因此需要使用评估模型来分析缓存是否达到了性能优化的目标。
评估模型公式为:AMAT = Thit + MR * MP,其中:
- AMAT(Average Memory Access Time)代表平均内存访问时间;
- Thit指的是命中缓存后的数据访问时间;
- MR指访问缓存的失效率;
- MP指缓存失效后,系统访问缓存的时间与访问原始数据请求的时间之和。
注意,AMAT与原始数据访问之间的差异代表使用缓存所带来的访问速度提升。在一些不当的缓存使用场景中,增加的缓存机制可能会降低数据访问速度。因此,接下来我将通过真实的缓存设计案例,带你理解如何正确使用缓存,以提升系统性能。
典型场景
好,在开始介绍之前呢,我还想给你说明一下,在真实的业务中,缓存设计的场景其实有很多,这里我的目的主要是让你明确缓存设计的方法。因此,我会从两个比较典型的案例场景入手,来带你理解缓存的使用。
如何做好静态页面的缓存设计?
在Web应用服务中,一个重要的应用场景就是静态页面的缓存使用。这里的静态页面是指一个网站内,所有用户看到的都是一样的页面,除非重新部署否则一般不发生变更,比如大部分公司官网的首页封面等。
通常静态页面的访问并发量是比较大的,如果你不使用缓存技术, 不仅会造成用户响应时延比较长,而且会对后端服务造成很大的负载压力。
那么针对静态页面,我们在使用缓存技术时,可以通过将静态缓存放到距离用户近的地方,来减少页面数据在网络上的传输时延。现在,我们来看一个针对静态页面使用缓存设计的示意图:

如图上所示,针对静态网页,首先你就可以在软件后端服务的实例中使用缓存技术,从而避免每次都要重新生成页面信息。然后,由于静态网页属于不变性数据,所以你可以使用内存或文件级缓存。另外,针对访问量非常大的静态页面,为了进一步减少对后端服务的压力,你还可以将静态页面放在网关处,然后利用OpenResty等第三方框架增加缓存机制,来保存静态页面。
除此之外,在网页中很多的静态页面或静态资源文件,还需要使用浏览器的缓存,来进一步提升性能。
注意,这里我并不是建议你针对所有的静态页面,你都需要设计三层的缓存机制,而是你要知道,在软件设计阶段,一般就需要考虑如何做静态页面的缓存设计了。
设计数据库多级缓存
还有一个典型的缓存场景是针对数据库的缓存。现在的数据库通常都是分布式存储的,而且规模都比较大,在针对大规模数据进行查询与分析计算时,都需要花费一定的时间周期。
因此,我们可以先识别出这些计算结果中可以使用缓存机制的数据,然后就可以使用缓存来提升访问速度了。下面是一张针对数据库缓存机制的原理图:
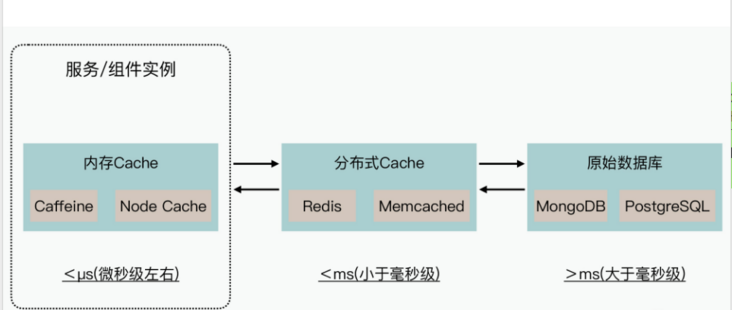
从图上我们可以看到,内存级Cache、分布式Cache都可以作为数据计算分析结果的缓存。而且,不同级的缓存访问速度是不一样的,内存级的Cache访问速度可以到微秒级别,甚至更好;分布式Cache访问速度通常可以小于毫秒级别;而针对原生数据库的查询与分析,通常是大于毫秒级别的。
因此,在具体设计缓存机制的时候,你就需要依据前面我介绍的缓存使用原理,识别出数据类型,然后选择并设计缓存实现机制。
另外,在使用缓存机制实现访问速度优化的过程中,我们的 主要关注点是不同层级缓存所带来的访问速度提升,而在这里,不同层级缓存也是可以在一个数据库中的。比如,在我参与设计的一个性能优化项目中,其Cache策略就是,使用MongoDB中的另外一个Collection(集合),来作为缓存查询分析,以此优化性能。
所以,你在做缓存设计时,关注点应该放到不同的数据种类,以及不同层级缓存的性能评估模型上,而不是只关注数据库。只有这样,你才能设计出更好、更优的性能缓存方案。
总结
本文重点介绍了缓存技术的使用原理和典型应用场景,当你在进行软件业务系统性能设计时,可以结合本文内容,识别出系统中各种可缓存的数据类型,然后有针对性地设计缓存方案,并且还可以根据评估模型,来进行前期的性能验证分析。
另外,在具体的缓存技术实现中,比如缓存替换算法、缓存失效策略等,通常这部分能力是内置于缓存库的配置选项当中的,或者选用第三方库即可,需要自定义设计算法的实现场景很少。所以这里你需要重点做的,就是选择合适的配置和策略即可。
本文由mdnice多平台发布
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
