
前言
遗传算法是一种模拟自然进化过程与机制来搜索最优解的方法,它由美国 John Holland 教授于20世纪70年代提出。遗传算法的主要思想来源于达尔文生物进化论和孟德尔的群体遗传学说,通过数学的方式,将优化问题转换为类似生物进化中的染色体基因的交叉和变异等过程,因此具有坚实的生物学基础和鲜明的认知学意义。和许多传统优化算法尤其是基于梯度的算法相比,遗传算法通过交叉和变异引入的随机性减少了陷入局部最优解的概率。同时遗传算法以适应度函数为导向,无需计算目标函数的导数和其他信息,这使得它适用于复杂的非线性和多维优化问题,因此被广泛应用于模式识别、图像处理、自动控制、工程设计和机器人等领域,具有广泛的应用价值。
虽然遗传算法表现优异,但是它的各个参数对其性能有着重要的影响。对于一个优化问题,如果没有找到合适的遗传算法参数,可能导致算法早熟或者收敛性能差的问题,需要迭代多个世代才能找到全局最优解。这些问题毫无疑问会阻碍遗传算法的落地应用,因此研究各个参数对算法产生了怎样的影响,进而确定合适的参数选取准则,对于改善遗传算法的搜索能力和收敛速度有着重要的意义。
本文通过遗传算法求解 Rastrigin 函数在二维空间的最小值问题,研究算法的各个参数的变化对最优解和收敛速度的影响,进而给出遗传算法参数选取准则,使得遗传算法在具体问题上能有更优异的表现。
遗传算法
遗传算法将优化问题的可行解编码为二进制形式,称为染色体。对于多维空间下的可行解,每个维度被编码为二进制形式的基因,共同组成了一条染色体。
遗传算法的流程如下图所示,可以分为以下几个过程:
- 初始化种群。在种群个体数为 (N) 和基因长度为 (L_c) 的情况下,随机生成 (N) 条染色体,作为初始种群 (X_0)。
- 个体评价。使用适应度函数计算种群中各条染色体 (C_i) 的适应度 (f_i)。
- 终止条件判断。如果适应度变化幅度小于指定的阈值或者迭代次数达到最大值,结束遗传算法,将种群中适应度值最大的染色体解码,可以得到最优解;否则继续下一步。
- 选择。根据各条染色体适应度的值,计算染色体的选择概率 (f_i=f_i / ∑f_i),使用轮盘赌算法随机选择出 (M=(1-α)N) 条染色体,其中 (α) 代表保留的适应度值最大的染色体的比例,这部分保留的染色体不会参与下面的交叉和变异过程,而是作为优秀个体被保留到下一次迭代。
- 交叉。对轮盘赌算法选出的 (M) 条染色体中的每一条染色体 (C_f),在交叉概率为 (P_c) 的情况下随机选择另一条染色体 (C_m) 和一个交叉位置 (k),将 (C_f [0:k-1]) 和 (C_m[k:]) 进行拼接,生成新染色体 (C_c)。
- 变异。对 (M) 条染色体分别独立依概率 (P_m) 进行一个随机比特的翻转。
- 回到步骤 2 计算新种群的个体适应度。

可以看到,遗传算法的上述流程中共有6个参数需要调节,各个参数如下表所示:
| 符号 | 说明 |
|---|---|
| (N) | 种群规模,即种群染色体的数量 |
| (L_c) | 基因长度 |
| (alpha) | 保留的优秀染色体比例 |
| (P_c) | 交叉概率 |
| (P_m) | 变异概率 |
| (varepsilon) | 适应度变化阈值或迭代次数 |
代码实现
使用 Python 实现的遗传算法如下所示,使用 get_solution() 方法可以对目标函数求极值:
class GA:
""" 遗传算法 """
def __init__(self, pop_size=200, dna_size=20, top_rate=0.2, crossover_rate=0.8, mutation_rate=0.01, n_iters=100):
"""
Parameters
----------
pop_size: int
种群大小
dna_size: int
染色体大小
top_rate: float
保留的优秀染色体个数
crossover_rate: float
交叉概率
mutation_rate: float
变异概率
n_iters: int
迭代次数
"""
self.pop_size = pop_size
self.dna_size = dna_size
self.top_rate = top_rate
self.crossover_rate = crossover_rate
self.mutation_rate = mutation_rate
self.n_iters = n_iters
def get_solution(self, obj_func, bound: List[tuple], is_min=True):
""" 获取最优解
Paramters
---------
obj_func: callable
n 元目标函数
bound: List[tuple]
维度为 `(n, 2)` 的取值范围矩阵
is_min: bool
寻找的是否为最小值
Returns
-------
index: int
最优解的下标
Xm: list
历次迭代的最优解
Ym: list
历次迭代的最优值
"""
Xm, Ym = [0], [0]
# 初始化种群
pop = np.random.randint(
2, size=(self.pop_size, self.dna_size*len(bound)))
Xm[0], Ym[0] = self._get_best(pop, obj_func, bound, is_min)
# 迭代求最优解
for _ in range(self.n_iters):
X = self._decode(pop, bound)
fitness = self._fitness(obj_func, X, is_min)
keep, selected = self._select(pop, fitness)
new = self._crossover_mutation(selected)
pop = np.vstack((keep, new))
xm, ym = self._get_best(pop, obj_func, bound, is_min)
Xm.append(xm)
Ym.append(ym)
idx = np.argmin(Ym) if is_min else np.argmax(Ym)
return idx, Xm, Ym
def _decode(self, pop: np.ndarray, bound: List[tuple]):
""" 将二进制数解码为十进制数 """
result = []
N = 2**self.dna_size-1
pows = 2**np.arange(self.dna_size, dtype=float)[::-1]
for i, (low, high) in enumerate(bound):
X = pop[:, i*self.dna_size:(i+1)*self.dna_size]
X = low + (high-low)*X.dot(pows)/N
result.append(X)
return result
def _fitness(self, obj_func, X: tuple, is_min=True):
""" 适应度函数 """
y = obj_func(*X)
e = 1e-3
return -y+np.max(y)+e if is_min else y-np.min(y)+e
def _select(self, pop: np.ndarray, fitness: np.ndarray):
""" 根据使用度选择染色体 """
# 保留一定比例的优秀染色体
n_keep = int(self.pop_size*self.top_rate)
idx_keep = (-fitness).argsort()[:n_keep]
# 按照适应度值随机挑选出剩下的染色体
n_select = self.pop_size-n_keep
p = fitness/fitness.sum()
idx = np.random.choice(np.arange(self.pop_size), n_select, True, p)
return pop[idx_keep], pop[idx]
def _crossover_mutation(self, pop: np.ndarray):
""" 交叉变异 """
result = []
for child in pop:
# 交叉
if np.random.rand() 实验
本文使用遗传算法求取 Rastrigin 函数在二维空间的最小值问题,优化问题可描述为:
]
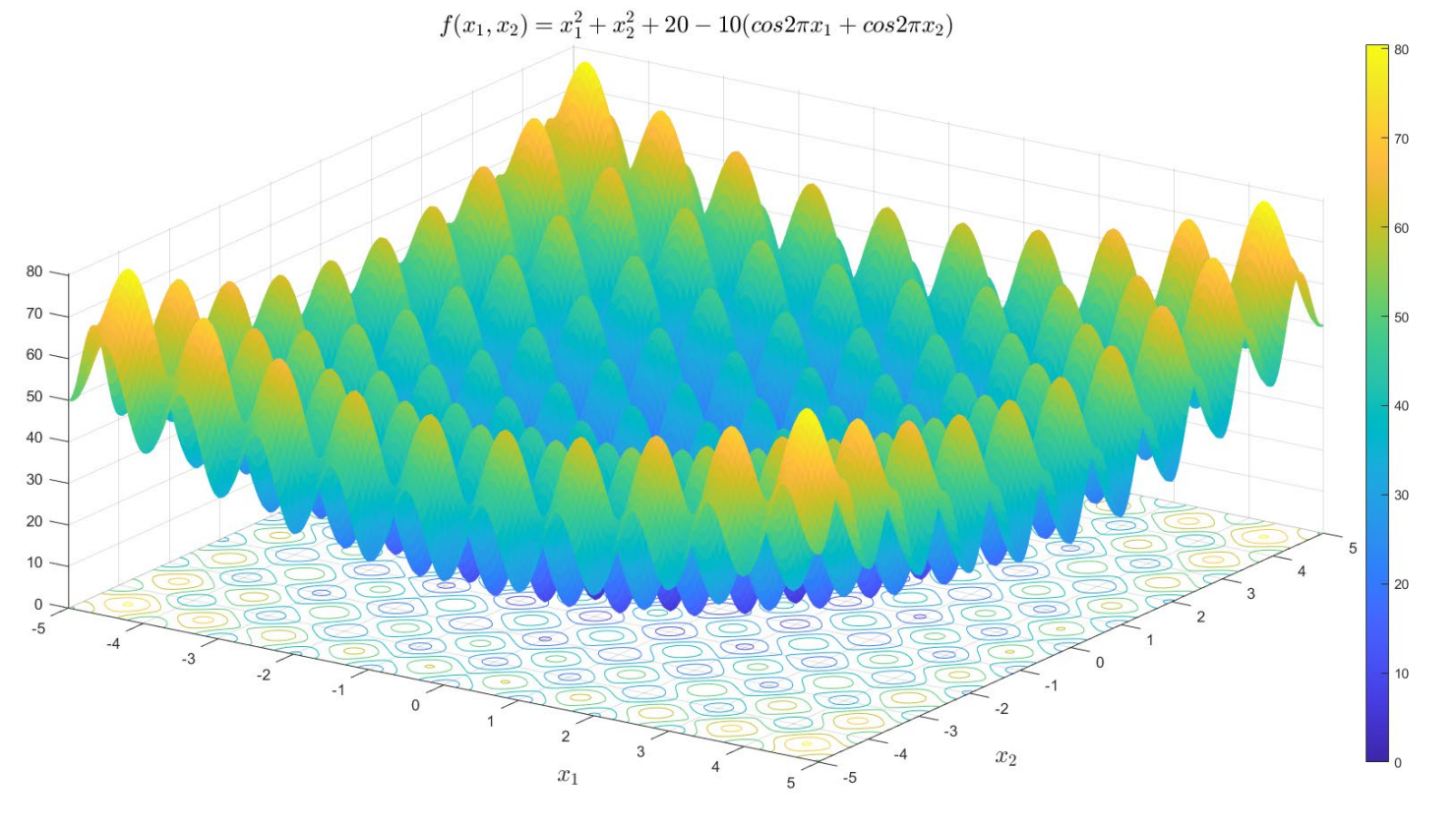
观察函数图像可知 Rastrigin 函数具有多个局部最小值点,在 ((0,0)) 处是最优全局最优解,此时最优目标值为 (f^*(x_1, x_2)=0)。为了更好地研究各个参数的变化对遗传算法的搜索能力和收敛速度的影响,本文在 (N=200, L_c=20, alpha=0.2, P_c=0.8, P_m=0.01, varepsilon=100)(使用迭代次数作为结束条件)的条件下分别调整每个参数,仿真并分析每个参数值下目标函数值曲线的变化。为了减少随机性造成的干扰,每个参数下进行 10 次仿真,并取平均值作为最终结果。
调整种群规模
当种群规模在 ([20, 260]) 区间内变化时,迭代曲线如下图所示。可以看到,当种群规模 较小时,种群多样性会比较少,会造成近亲繁殖的现象,算法容易陷入局部最优解且收敛速 度较慢。随着种群规模的扩大,多样性逐渐提升,交叉和变异更有可能繁殖出更优秀的个体, 算法很快就收敛于全局最优解。对比 (N=180) 和 (N=260) 的迭代曲线,发现二者的收敛速度 差异并不大,所以种群数量不能设置过大,一味增大种群数量只会造成运算开销的上升。

调整基因长度
基因长度对迭代曲线的影响如下图所示,由图可知,当基因长度为 (L_c=5) 时,二进制数据分辨率过低,算法很快收敛到解 ((1.129, 1.129))。有趣的是当基因长度 (L_c in { 35,40,45 }) 时的收敛到最优解的速度并没有快于 (L_c=20) ,原因在于染色体长度越大,分辨率就越高,这减小了随机交叉和变异对染色体的十进制数的影响。

调整保留的最优染色体比率
保留最优染色体的比率在 ([0.1, 0.9]) 之间变化时,迭代曲线的对比如下图所示。由图可知,如果保留的最优染色体过多,会导致用于交叉和变异的染色体数量变少,减少了算法从局部最优解跳到全局最优解的可能性,因此 (alpha = 0.9) 时算法收敛速度明显慢于其他曲线。而 (alpha = 0.1) 时保留的最优个体太少,过多的交叉和变异可能导致算法在多个局部最优解之间跳 动,只有 (alpha in {0.2, 0.3, 0.4}) 时算法快速地收敛于全局最优解。

调整交叉概率
交叉概率在 ([0.1, 1.0]) 之间变化时,迭代曲线的对比如下图所示。可以发现,交叉概率较小时,种群内的染色体通过交叉繁衍出更优秀个体的概率也更低,因此算法收敛速度较慢。而交叉概率取 0.8 以上的值时,种群繁衍出优秀个体的概率变大,收敛速度明显加快。

调整变异概率
为了更好地体现变异概率变化对算法表现的影响,本文分别在种群规模为 40 和 200 的 情况下仿真 ([0.02, 0.20]) 范围内的 (P_m) 对应的迭代曲线。观察图 (a) 可以发现种群规模较小时,变异概率越高,染色体进化到更优秀个体的概率也越大,算法收敛速度越快。当种群规模扩大到 200 时,过大的变异概率反而会影响算法收敛到全局最优解。

调整迭代次数
本文使用迭代次数作为算法的结束条件,由下图可知当迭代次数较少时,种群还未成熟,算法没有收敛到全局最优解。当迭代次数达到 60 次时,迭代曲线取向平缓,表明种群已成熟,算法已收敛到全局最优解,此后的迭代对算法的贡献很小,却带来了一定的计算开销。

结论
本文针对遗传算法的参数调节问题,开展基于遗传算法的 Rastrigin 函数优化问题研究。 仿真结果表明,种群规模、基因长度、保留的最优染色体比例和迭代次数不能过小或过大,更大的交叉概率可以增大进化出更优秀个体的概率,而更大的变异概率在种群规模较小时也能加速算法收敛到全局最优解的速度。对于遗传算法在其他场景上的应用,可以在这个调参准则的基础上进行参数选择,能让遗传算法有更好的表现。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: StampedLock:高并发场景下一种比读写锁更快的锁
摘要:在读多写少的环境中,有没有一种比ReadWriteLock更快的锁呢?有,那就是JDK1.8中新增的StampedLock! 本文分享自华为云社区《【高并发】高并发场景下一种比读写锁更快的锁》,作者: 冰 河。 什么是StampedLock? ReadW…
