
为什么需要链路跟踪
为什么需要链路跟踪?微服务环境下,服务之间相互调用,可能存在 A->B->C->D->C 这种复杂的服务交互,那么需要一种方法可以将一次请求链路完整记录下来,否则排查问题不好下手、请求日志也无法完整串起来。
如何实现链路跟踪
假设我们从用户请求接口开始,每次请求需要有唯一的请求 id (我们暂且标记为 traceId)来标识这次请求,然后当接口收到请求后,调用后续服务或者 mq 时,能将该 traceId 一直传递下去,并且 log 日志中可以打印出来,这样就实现了简单的链路功能。
如何为每次请求生成一个唯一的 requestId
微服务环境下,用户请求一般优先经过网关,网关再将请求转发到各个服务。微服务网关多种多样,比如 Nginx、Zuul、Spring Cloud Gateway、Kong、Traefik 等,假服务器托管网设存在这样一条链路,用户请求 -> nginx -> zuul -> service-a、service-b 等(这里我们使用 Eureka 作为服务注册中心,使用 Feign 来实现微服务之间相互调用、使用 Zuul 作为服务前置网关),调用大致如下:
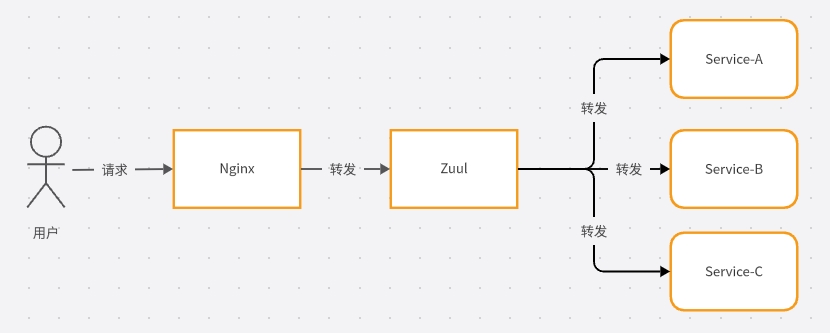
这样的话,从 nginx 请求开始,我们需要标识本次请求的 traceId,然后可以将 traceId 一直传递到 service 服务层,那么基于这样一个链路的话,我们怎么设计一个链路工具呢?
Nginx
nginx 从 1.11.0 版本就开始内置了变量 $request_id,其原理就是生成一串 32 位的随机字符串,虽然不能比拟 uuid,但是重复的概率也很小,可以视为 uuid 来使用。用户每次请求会生成一个 $request_id,可以作为我们的 traceId。
设置的话首先设置 nginx 日志格式,支持 $request_id:
log_format access '$remote_addr $request_time $body_bytes_sent $http_user_agent $request $status $request_id'
nginx 常用的内置变量及其含义如下:
- $remote_addr:客户端地址,如:172.16.11.1
- $remote_user:客户端用户名称
- $time_local:访问时间和时区,20/Dec/2022:10:47:58 +0800
- $request:请求的URI和HTTP协议,”GET / HTTP/1.1″
- $status:HTTP请求状态,304
- $body_bytes_sent:发送给客户端文件内容大小
- $request_time:整个请求的总时间
- $request_id:当前请求的id
其次要在 nginx 转发请求时,增加 traceId 的 header:
location / {
proxy_set_header traceId $request_id;
}
Zuul
traceId 经过 nginx 转发到 zuul 之后,zuul 路由转发时存在 header 丢失的问题,我们可以自定义一个 zuul 的前置过滤器了,在过滤器中再将 header 再传递下去,代码比较简单:
@Component
public class TraceIdPreFilter extends ZuulFilter {
private static final String TRACE_ID = "traceId";
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext requestContext = RequestContext.getCurrentContext();
HttpServletRequest request = requestContext.getRequest();
requestContext.addZuulRequestHeader(TRACE_ID, request.getHeader(TRACE_ID));
return null;
}
}
Service 服务层
service 服务层要做几件事:
- 接收暂存 zuul 转发过来的 traceId
- 日志文件配置,日志支持输出 traceId
- service 接收到 traceId 后,再调用其他服务时,需要将 traceId 继续传递下去
首先我们来看下代码层面,如何接收暂存 zuul 转发过来的 traceId,我们需要使用到过滤器和 MDC(放入MDC中的 key 可以在日志中输出)。我们创建一个过滤器,用来接收 zuul 转发过来的 traceId,并且将 traceId 设置到 MDC 以便我们的日志文件可以输出 traceId:
public class TraceIdFilter implements Filter {
private static final String TRACE_ID = "traceId";
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {
try {
HttpServletRequest httpRequest = (HttpServletRequest) request;
String traceId = httpRequest.getHeader(TRACE_ID);
TraceIdHelper.setTraceId(traceId);
filterChain.doFilter(request, response);
} finally {
// 清除MDC的traceId值,确保当次请求不会影响其他请求
TraceIdHelper.clearTraceId();
}
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void destroy() {
}
}
@UtilityClass
public class TraceIdHelper {
public static final String TRACE_ID = "traceId";
private static final ThreadLocal TRACE_ID_THREAD_LOCAL = new ThreadLocal();
/**
* 设置traceId,为空时初始化一个
* @param traceId
*/
public void setTraceId(String traceId) {
if (StringUtils.isBlank(traceId)) {
traceId = UUID.randomUUID().toString();
}
TRACE_ID_THREAD_LOCAL.set(traceId);
MDC.put(TRACE_ID, traceId);
}
/**
* 清除traceId
*/
public void clearTraceId() {
TRACE_ID_THREAD_LOCAL.remove();
MDC.remove(TRACE_ID);
}
/**
* 获取traceId
* @return
*/
public String getTraceId() {
return TRACE_ID_THREAD_LOCAL.get();
}
}
过滤器注册:
@Configuration
public class TraceIdConfig {
@Bean
pub服务器托管网lic FilterRegistrationBean loggingFilter() {
FilterRegistrationBean registrationBean = new FilterRegistrationBean();
registrationBean.setFilter(new TraceIdFilter());
// 设置过滤的URL模式
registrationBean.addUrlPatterns("/*");
return registrationBean;
}
}
再来看下我们的日志文件配置(logback.xml):
${LOG_PATTERN}
${FILE_PATH}
15
10MB
${FILE_LOG_PATTERN}
这里 xml 配置文件中配置了 traceId,这样日志中就能看到 traceId 被输出了。
最后的话服务之间调用时,我们需要传递 traceId 到下一个微服务,这就要用到 feign 的拦截器:
@Component
public class TraceIdFeignInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate requestTemplate) {
// spring的上下文对象
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
if (requestAttributes != null) {
// 前面的过滤器已经获取并设置了 traceId,这里就可以直接获取了
requestTemplate.header(TraceIdFilter.TRACE_ID, TraceIdHelper.getTraceId());
}
}
}
消息队列层
假设 service-a 发送一条 mq 消息后,service-b 消费到了,那么需要将消费链路也串起来怎么做呢?我们以 rocketmq 举例,rocketmq 提供了 UserProperty 可以发送带属性的消息,这样通过 UserProperty 我们便能实现 traceId 的传递。比如消息发送时:
Message msg = new Message("SequenceTopicTest",// topic
"TagA",// tag
("Hello RocketMQ " + i).getBytes("utf-8") // body
);
msg.putUserProperty("traceId", TraceIdHelper.getTraceId()); //设置 traceId
消息消费时:
String traceId = msgs.get(0).getUserProperty("traceId");
TraceIdHelper.setTraceId(traceId);
dubbo 如何传递 traceId
dubbo 的 spi 机制可以很方便的让我们来实现各种拓展,比如 dubbo 提供的 provider、consumer 过滤器,我们可以分别实现一个 provider、consumer 得到过滤器。
服务提供者那里,我们可以自定义一个 consumer 过滤器,过滤器中先通过 TraceIdHelper.getTraceId() 获取到 traceId 后再通过 dubbo 提供的 setAttachment(“traceId”, TraceIdHelper.getTraceId()) 将 traceId 传递下去。
同样地,服务消费者那里,我们可以自定义一个 provider 过滤器,首先通过 dubbo 提供的 getAttachment 获取到 traceId,之后再使用封装好的 TraceIdHelper.setTraceId 将 traceId 暂存即可,这里代码就不写了。
多线程时如何继续传递 traceId
我们的工具类 TraceIdHelper 注意看使用的 ThreadLocal 进行的 traceId 暂存,就会存在多线程环境下,子线程取不到 traceId 也就说子线程的日志没法打印出 traceId 的问题,解决思路的话有几种,
- 可以自定义 ThreadPoolTaskExecutor,线程 run 执行前先将 traceId 设置进去,缺点是比较麻烦
- 使用阿里提供的开源套件 TransmittableThreadLocal(使用线程池等会池化复用线程的执行组件情况下,提供ThreadLocal值的传递功能,解决异步执行时上下文传递的问题)
总结
链路工具的实现会用到多个组件,每个组件都需要不同的配置:
- nginx:配置
$request_id,转发时配置$request_idheader - zuul:配置前置过滤器,进行 traceId 向下游透传
- 服务层:log 日志文件配置,用到 MDC 来打印输出 traceId;用到了过滤器和 Feign 拦截器来实现 traceId 透传
- mq:消息队列要想实现 traceId 传递,如 rocketmq 需要用到 UserProperty
- 多线程:多线程时子线程可能会获取不到 traceId,可以自定义 ThreadPoolTaskExecutor 或者 使用阿里提供的开源套件 TransmittableThreadLocal
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: Android开发核心知识点梳理,25~40岁程序员进阶必备
1. Android的过去、现在和未来 在我的记忆中,早在2011年就有言论说Android系统要完蛋,时过9年后,Android系统仍旧坚挺。 现在Android已经广泛的应用在手机、平板、车联网、物联网、智能电视等等领域,是名副其实的终端霸主。且Andro…
