
前言
为了保证有一个更健康的身体,所以慢慢降低了更新频率,在有了更多休息时间的前提下,思考了一下接下来准备分享的一些内容。
决定在更新一些技术干货的同时,会穿插一些架构知识,放在单独的专栏里面,希望大家能喜欢,里面包含了这些年工作中遇到的一些内容,以及自己充电后总结的一些知识,希望大家会喜欢。
标题做了较为详细的划分,大家不必一次看完,以免视觉疲劳。
场景
本篇分享以前在广州一家互联网公司工作时遇到的状况及解决方案,这家公司有一个项目是SOA的架构,这个架构那几年是很流行的,哪怕是现在我依然认为这个理念在当时比较先进。
我在这家公司待的时间不长,但因为平台不错,确实学习和实践了一点东西,所以整理一下分享给大家。
当时的项目背景大概是这样,这家公司用的是某软提供的方案(这公司贼喜欢提供方案且要钱多,忍不住吐槽哈),项目已经运行3年多,整体稳定。
数据库是MySQL,订单表的数据量已经达到3000多万条记录,并且随着项目的推广,最近那一年订单表数据量也在快速增长。
结果就是,客户方查询订单相关的业务时速度越来越慢,后期不论打开还是刷新都差不多要七八秒。
可以说已经严重影响了客户体验,降低了对方日常办事的效率,要求我们尽快解决,且敦促我们这是一件优先级非常高的事情。
在客户和公司领导的双重压力下,如何快速优化几千万数据的订单表,对于当时的团队着实是一个难题摆在面前。
我依稀记得自己当时还比较青涩,更多的是一个听众,不敢参与深入讨论哈哈。
整体方案
首先常规方案能想到的无非是这些:增加合理的数据库索引、优化核心SQL语句、优化代码等。
我这里可以告诉大家,一般的IT公司,但凡团队Leader是个有经验的人,这些基础方案都是会提前做的,会对项目上线后可能遇到的瓶颈有个基本的评估,因为真正运营周期变长以后,数据量逐渐增多,修改生产库是一种风险操作。
我不知道大家有没有过给某个生产库数据量比较大的表添加字段或索引的经历,而且是在白天上班操作,或者说你自己见过别人这么干,我只能说……这些都是狠人,要对其常怀敬畏之心。
我目前所在的公司就比较规范,研发人员建表时一定要提交申请走流程,且附带合理的索引,一起提交审核,最终通过了才能由主管审核执行。
至于这种流程怎么走,其实工具挺多,我这里就提一个用过的开源项目:Yearning,大家可以自己去了解下。
话题扯回来,正因前面所讲,在当前的问题下,这些基础方案实际上已经存在,在这里显然是用不上了,加上紧急问题紧急处理,没有那么多时间给你去对既有架构大动干戈。
因此,当时立马能想到且有效的临时性方案迅速在团队讨论中率先冒出来,就是数据库分区。
1、数据库分区
理解数据库分区,只需要记住以下两点:
- 数据库分区是把一张表的数据
分在了不同的硬盘上,但仍是一张表,说硬盘可能不完全准确,但就这样理解是最容易的。 - 不要把数据库分区和分库分表混淆,一个是
数据库级别的操作,一个是代理工具的操作,前者限制较多,后者更灵活。
知道这两点其实就足够了,数据库分区和分库分表也是面试中喜欢问的,因为确实有一些类似的地方。
好了,有了基本认识,那接下来就说下数据库分区如何操作的,先看个图有个画面。
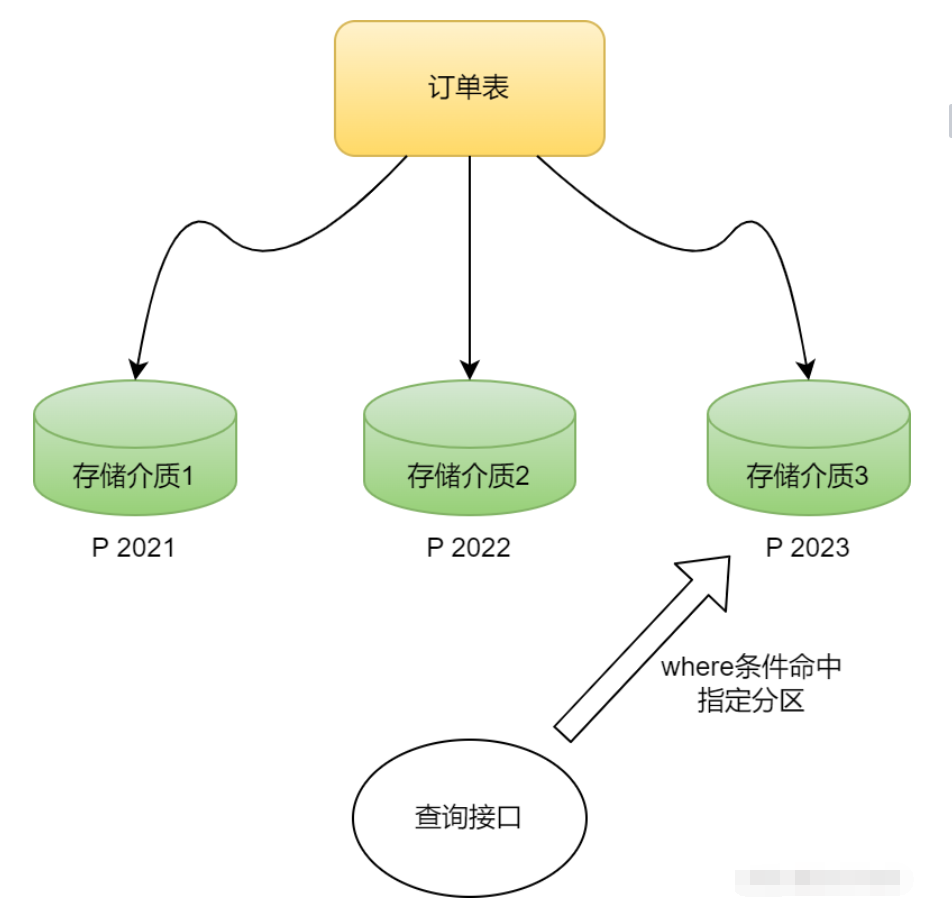
接着举个示例,我们假设有一张订单表,那么对这张订单表按照年份进行分区的命令如下:
-- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_number VARCHAR(20),
order_date DATE,
customer_id INT,
total_amount DECIMAL(10, 2)
);
-- 按照年份对订单表进行分区
ALTER TABLE orders
PARTITION BY RANGE(YEAR(order_date)) (
PARTITION p2018 VALUES LESS THAN (2019),
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024)
);
这样一来,数据库就会将这张表的数据按照YEAR(order_date)的值分别存在 p2018 ~ p2023 这6个分区中。
如果结合本篇的问题,3000多万条记录,那么按照年份分区,大概一个分区是1000万记录左右,然后可以优化查询语句只去扫描特定的分区,是不是一下就轻松了很多。
再深入点,按照年份一个分区1000万还是有点多了,我们是不是可以找到一个更合理的分区字段,让每个分区的数据更少呢?
这里就要结合实际业务了,没有真正的通用方案。
你要先明确一点,做分区的目的,最终是为了让某个业务环节的查询更快,就比如本篇这里,主要是为了让客户查询订单相关业务更快,那么你就要先把这块的查询语句摘取出来,分析一下里面的where条件有哪些。
-
比如,客户要查询某个或某些状态的订单,可能会这样写:where order_status in (?);
-
比如,客户要查询某个特定群体的订单,可能会这样写:where user_flag_id = ?;
-
比如,客户要查询某个或多个业务类型的订单,可能会这样写:where order_type in (?);
甚至,还可能有其他的组合条件掺杂进来,你千万别以为你去的每个公司都把表设计的很漂亮很合理,我这么多年工作下来,真见过不少奇葩设计,订单表里面能给你塞上openId或者某些单纯为了方便而加的冗余字段,完全把订单表自身的功能性打碎。
这个时候,如果分区字段本身存在,且刚好能把分区数据分的很合理,有利于查询,比如前面按照年份划分,每个分区如果只有两三百万记录,再结合本身的索引,查询就会很快,那么一切安好,搞完收工。
但如果分区字段很难定位,就像上面讲的,一些主要SQL语句的where条件并不包含相同的字段,那就头大了。
而且MySQL还有一个需要注意的点,就是它的分区本身是有限制的。
MySQL分区字段必须是唯一索引的一部分。
也就是说,如果没有其他能用的唯一索引,我们只能结合主键ID,和分区字段组成复合主键才行。
这就更难了,纯粹看这表长什么样了。
话到服务器托管网这里,其实大家也看出来了,数据库分区的优缺点很明显。
优点:遇到合适的场景,优化起来就是一个命令的事情。
缺点:限制太多,稍微复杂一点的场景你就很难定位分区字段。
那么,真的就没法分了吗?其实还有一个迂回的方案。
2、迂回方案
我们可以在表中新增一个专门为了分区而量身定做的字段,比如archive_flag,表示一种数据归档状态,当值为1时表示已归档,值为0时表示未归档。
这个字段可以没有业务意义,但一定要有分区意义。
我们可以把半年内的数据刷成 archive_flag=0,半年以外的数据刷成 archive_flag=1。
接下来,我们按照归档状态进行分区即可,半年内的活跃数据是一个分区,其他非活跃数据是一个分区。
最后,只需要把核心的查询语句where条件中都新增一个 archive_flag=0 就可以了,这样就会扫描这个非归档状态的分区,也就是活跃数据的分区。
试想一下,这个分区只有半年的记录,按照本篇的场景,最多也就是500万了,结合自身表索引,已经完全可以解决当前存在的问题。
好了,这个迂回方案其实挺不错的,但一定有人会有疑问。
1)、加字段真的好吗?
2)、为什么一定要半年内的数据?
首先解答第一个问题,答案是不好,在我这里的话甚至可以说非常不好,几千万数据量的表,为了解决一个查询问题刻意新增一个没有实际意义的字段,是舍本逐末的行为,如果除了这张表,还有其他表也有类似问题,难道每个都要加字段吗?显然是不可行,也是不安全的。
第二个问题,半年内的数据完全可以结合实际业务做修改。
举个简单的例子,你如果经常逛京东商城购物,一定会打开我的订单看看,实际上给你展示的就是近3个月的订单,你可以理解成这就是非归档的活跃数据。
当你想查询以前的记录时,就会给你一个链接叫历史记录,点击后跳转到历史记录列表,或者通过其他方式如下拉框,让你选择其他更早时间的订单数据,这种其实就是已经归档的数据。
这些数据一般不会直接从业务表里查出来,而是从其他归档表,或者非关系型数据库如mongodb、EasticSearch等查询出来。
这种方式就类似做了分区,把你经常访问的数据和访问频率较低的数据分布存储,达到一个数据分离的目的。
这样你就懂了,数据分区大体就是这样的思考方式。
现在回过头来想想前面说的优缺点,数据库分区真的合适吗?
实际情况下,很少有情况合适,主要原因还是前面讲过的,限制真的太多了,而业务往往又是复杂的。
另外,数据库分区对于很多程序员来说,其实是陌生的,在中小企业更是如此,有这样的现实摆在面前,加上短期内就要解决问题,随便使用的话对于团队来讲也是一种风险。
所以,另一种更合理的方案也就呼之欲出了,数据的冷热分离。
3、冷热分离
前面讲了那么多,其实就是为了过渡到这里来,上面的迂回方案或多或少已经摸到了冷热分离的边缘,主要是为了让大家知其然并知其所以然。
1)、基本概念
冷热分离听起来很高端,其实本质很简单,就是把活跃数据和非活跃数据区分开,一热一冷,频率高的查询只操作热数据,频率低的只操作冷数据。
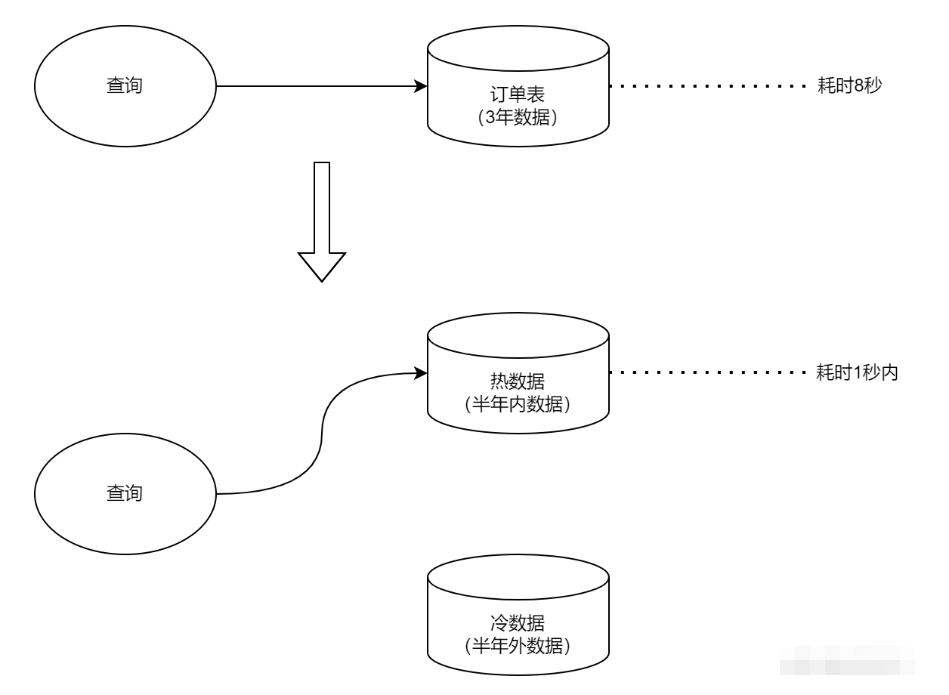
2)、存储方案
既然要分离,就要考虑清楚热数据和冷数据分别放在哪里。
这里我提供两种选择:
中小企业,我推荐依然用MySQL。
一来是不需要额外成本(降本增效?哈哈),二来是中小企业相对大厂,业务复杂度低一点且数据量小很多,那么此时完全可以用MySQL新增一张表来存储某个业务的冷数据,比如订单。
如果需要冷热分离的业务较多,也可以建一个单独的冷库,来专门存放冷数据,不过这种我也不太推荐,因为涉及到跨库查询,增加了维护难度,咱们程序员尽量对自己好一点哈。
一个项目里面,其实两三张冷表的出现已经可以处理核心业务数据冷热分离的问题了,如果真有那么多大数据的表,我觉得要从其他方面找问题了(一些老项目,设计上本身有问题,那是真的没好办法)。
大厂,推荐HBase。
大厂的资源较多,平台较大,冷热分离不单是解决这种问题的唯一方案,但大厂比较推荐更合适的数据库来存储这样的冷数据。
其中HBase是我从各种资料中见过的最多的一种,当然也有其他的,但HBase应该是里面最受欢迎的一类。
当然,我个人是没有大厂经验的,我只能把我掌握到的讯息告诉你们。
如果有兴趣的话,可以去学习下HBase,它是一种在 Hadoop 上构建的分布式、可扩展的列式数据库。
它最大的优势就是快速读写海量数据,且具有强一致性。
一般大厂对于冷数据的处理,往往都是因为冷数据在业务中也有相当的查询体量,如果太慢也不符合大厂维护项目的标准,所以有必要专门优化。
好了,这里之所以提到HBase,主要是为了扩充大家的知识面,其实中小企业的工程师也没啥必要特地去学,依靠自身兴趣驱动即可。
3)、区分冷热数据
既然要冷热分离,那么一张表中,如何区分哪些是热数据,哪些是冷数据?
要分析这张表的
字段特征,拿订单表举例,马上能想到的就是:订单状态、创建时间。
订单状态的话,其实也类似于前面数据库分区提过的归档状态,你可以将状态是已完成的数据归类为冷数据,而待处理、处理中的都归类为热数据,这个要视你们自己的业务决定。
创建时间的话,就比较常见了,也是我推荐中小企业使用的方法,因为几乎所有的核心业务表,都一定会有创建时间这个字段,我们可以把查询频繁的时间区间的数据归类为热数据,其他时间都归类为冷数据。
比如本篇我讲的案例,当时我们公司就是半年内的数据是查询非常频繁的,因此直接按照最近半年作为区分冷热数据的规则。
4)、如何冷热分离
这里有四种方案:
- 代码中处理
这个很好理解,比如订单表中,当状态从处理中改为已完成时,你就可以将这条记录归类为冷数据,放到冷表或冷库中。
优点是很灵活,而且实时性高。
缺点是相关的代码位置你都要做修改,另外如果是按照时间做冷热分离,这个方案基本就不可取。
你想想,你怎么判断呢?我们按照半年内的数据作为热数据,那么你在哪个方法哪个事件触发时将这笔订单归类为冷数据?可以说做不到。
- 任务调度处理
这种就是定时任务去扫描数据库,比如xxl-job,新建一个调度任务,定时去扫描数据库,判断哪些是冷数据,然后归档到冷表或冷库中去。
这种的优点,一来是不用大量修改代码,二来就是非常适合按照时间划分冷热数据的场景。因为它是一种延迟处理方式,你可以设置为半夜去运行。
比如我之前的那家公司,就是设置为凌晨以后执行,因为那个时候很少有用户在使用了,没有什么新的订单产生,哪怕有新的订单,也属于误差范围内,可以接受。
- 监听binlog
这种方案我是从书本上获取到的,给我涨了点知识。
监听binlog的目的说白了,就是判断订单状态是否变化,和代码中处理很类似,唯一的区别在于,
如果你维护的这个项目又老又复杂,代码很难改也改不全,监听binlog就是很好的方案了,你可以不改代码,监听数据库变更日志然后做相应处理即可。当然,缺点和前面一样,当按照时间来划分冷热数据时,这种方案也不可取,因为你不知道如何监听。
- 人工迁移
冷热分离操作的最终还是数据,分离实质上也就是一种数据迁移,因此,人工干预其实是很靠谱的选择。
上面每种方案都有自己的优势,但也有各自的局限性。
代码处理,你只能处理发布上线以后的新数据。
任务调度,当数据量庞大的情况下,你一次可能根本无法完成分离,对于紧急的要快速优化的场景显然不适合。
监听binlog,除了前面提到的缺点,还需要工程师对其比较熟悉,否则短时间内上手容易带来不确定性。
此时,DBA或集成工程师(俗称打杂工程师)的优势就体现出来了,备份后,抽某天晚上,直接把半年以外的数据迁移到冷库即可。
这样不仅简单,也避免了其他技术方案可能存在的问题及风险。专业的人,做专业的事,才是最靠谱的。
4、最终方案
通过上面简述的几种方案,我们已经有了较为清晰的认知。
现在我可以告诉大家,当初的公司所采用的方案是其中两种方案的结合:
人工迁移 + 任务调度。
人工迁移用于一次迁移完成冷数据到冷库,任务调度用于对后续新产生的数据进行解耦且延迟的冷热分离。
思维导图大概是这样:
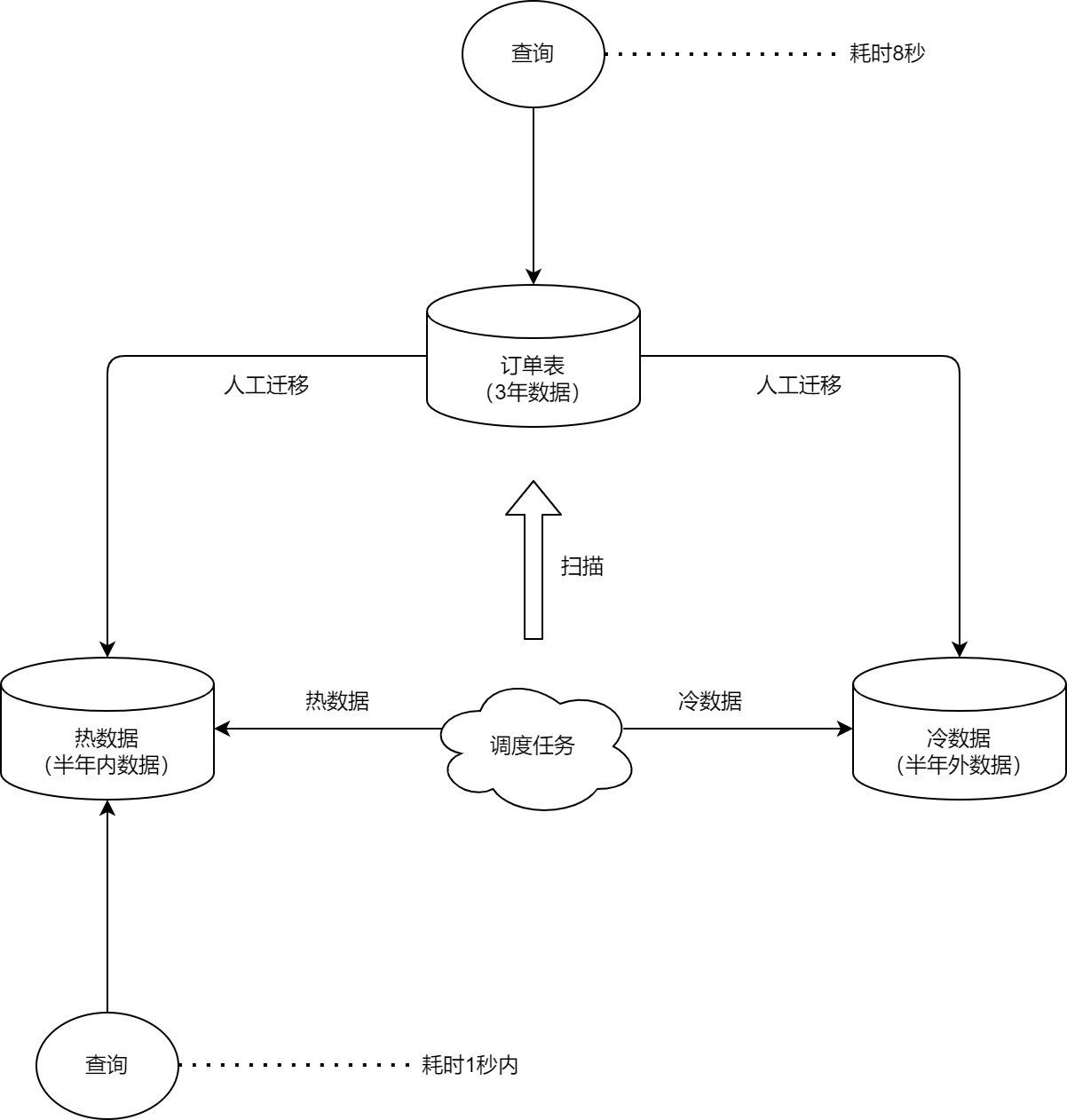
基本步骤如下:
-
1)、定位冷热分离的规则,比如本篇,就是按照订单交易完成时间,以半年内和半年外作为分离的基准;
-
2)、冷数据迁移,由公司的DBA或集成工程师对数据进行备份,然后在发布当晚将冷数据迁移到冷库中去;
-
3)、开发人员新建一个调度任务,并实现任务调用的接口,专门扫描数据库,将超过半年的订单数据通过程序逻辑迁移到冷库,保证热数据一直维持在半年内,任务可以每天凌晨执行一次,或根据自身业务决定调度频率。
这样一来,既解决了冷热分离规则的问题,不管是什么规则,你最终都可以通过人工迁移数据来做到分离。
也解决了时间上的紧迫性,你只需要开发一个用于调度的接口,不再需要考虑其他任何技术层面的影响,时间成倍缩短。
这在中小企业算是比较适合的方案了,当初我们在一周内就优化完成了,研发工程师用了1天完成调度接口的实现,剩下的时间都是集成工程师进行数据迁移的演练。
最终客户还是很满意的,核心业务的查询速度一下就提升了近10倍。
优缺点
好了,临近尾声,我们来说一下冷热分离方案整体的优缺点吧。
1、优点
优点我归纳了3点:
1)、提高性能
很明显,冷热分离后,将更多计算资源集中在了热数据上,将查询性能最大化。
2)、降低成本
对于千万级的数据表,冷热分离方案不需要额外的第三方中间件,极大地节约了成本。尤其是在中小公司,老板对成本还是很在意的。
3)、简化维护
冷热分离之后,对于数据的维护更直观,可以把更多精力放在热数据的处理上。
比如备份策略,冷热数据可以分别采用不同的策略维护,更关注热数据备份,简化冷数据备份。
2、缺点
缺点我归纳了2点:
1)、场景限制多
冷热分离并不是万能的,一定要根据业务来分析,查询的复杂度较高,很可能你冷热分离后,热数据的查询依然没有得到明显优化。
比如你有一张表,查询的语句关联很多,表数据量也挺大,那么这个时候冷热分离一点作用都没有,因为你分离完了,查询语句还是关联那么多,速度依然很慢。
这个时候,类似的场景就无法使用冷热分离方案了,而是要考虑其他服务器托管网方案,比如读写分离,比如查询分离,这样才能从根源上解决查询慢的问题。
2)、统计效率低
这种也是冷热分离方案比较明显的一个缺点,当你们的业务中,需要对数据做一些复杂的统计分析,甚至要求一定的实时性。
那么这个时候,因为已经冷热分离,冷数据的统计分析效率会非常低,对于客户提出的一些五花八门的统计分析就难以操作了。
因此,又需要引入其他方案来配合,比如ElasticSearch,这样又增加了额外的成本,不仅要考虑ES的资源成本,还要考虑诸如部署方案、维护方案、安全性问题等等。
今年我们内部就公布了一个小道消息,某家业内还挺不错的互联网公司因为ElasticSearch的未授权漏洞导致千万用户敏感信息被泄露,直接被行业除名了。
所以,在实际工作中,中间件的引入是个需要审慎考虑的问题,而不是你想当然了就可以使用。
总结
通篇写的还是挺长的,主要是一开始列出了大纲,但在写的过程中又想起了新的知识点,就一起加进来了。
前面讲的数据库分区等方案,主要是为了过渡,因为这是一个线性的思维,展现出来让大家知道一个方案最终落地的脉络是怎样的。
今后还会继续写一些架构相关的知识,放在单独的专栏里面,希望大家支持和喜欢。
如果喜欢,请点赞+关注↓↓↓,持续分享工作经验及各种干货哦!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
