
摘要:本文整理自字节跳动基础架构工程师魏中佳在本次 CommunityOverCode Asia 2023 中的《字节跳动 MapReduce – Spark 平滑迁移实践》主题演讲。
随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务,从大数据研发和用户角度来看,MapReduce 引擎的运维和使用也都存在着一系列问题。在此背景下,字节跳动 Batch 团队设计并实现了一套 MapReduce 任务平滑迁移 Spark 的方案,该方案使用户仅需对存量作业增加少量的参数或环境变量即可完成从 MapReduce 到 Spark 的平缓迁移,大大降低了迁移成本,并且取得了不错的成本收益。
背景介绍
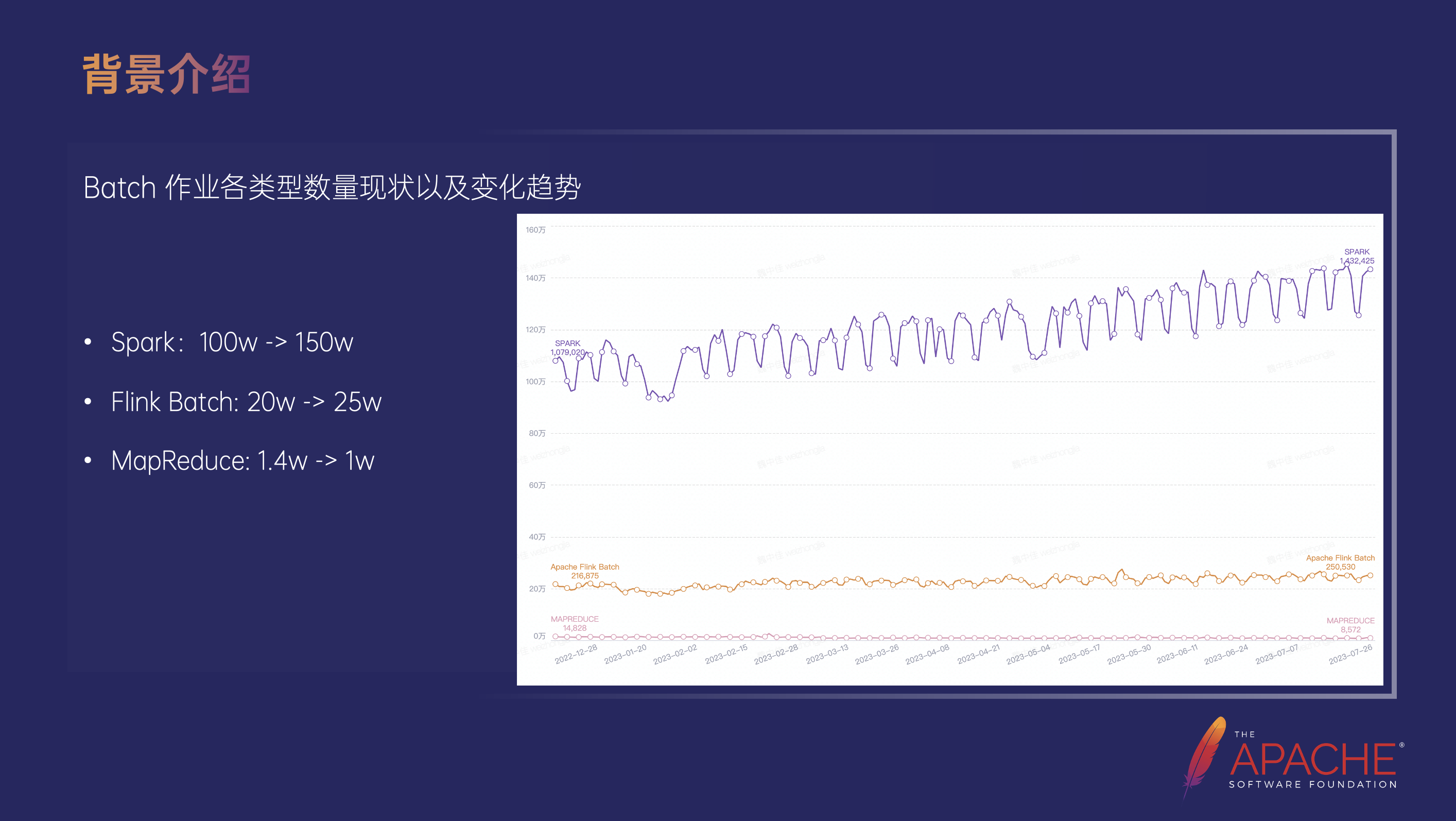
近一年内字节跳动 Spark 作业数量经历了从 100 万到 150 万的暴涨,天级数据 Flink Batch 从 20 万涨到了 25 万,而 MapReduce 的用量则处于缓慢下降的状态,一年的时间差不多从 1.4 万降到了 1 万左右,基于以上的用量情况,MapReduce 作为我们使用的历史悠久的批处理框架也完成了它的历史使命即将下线。
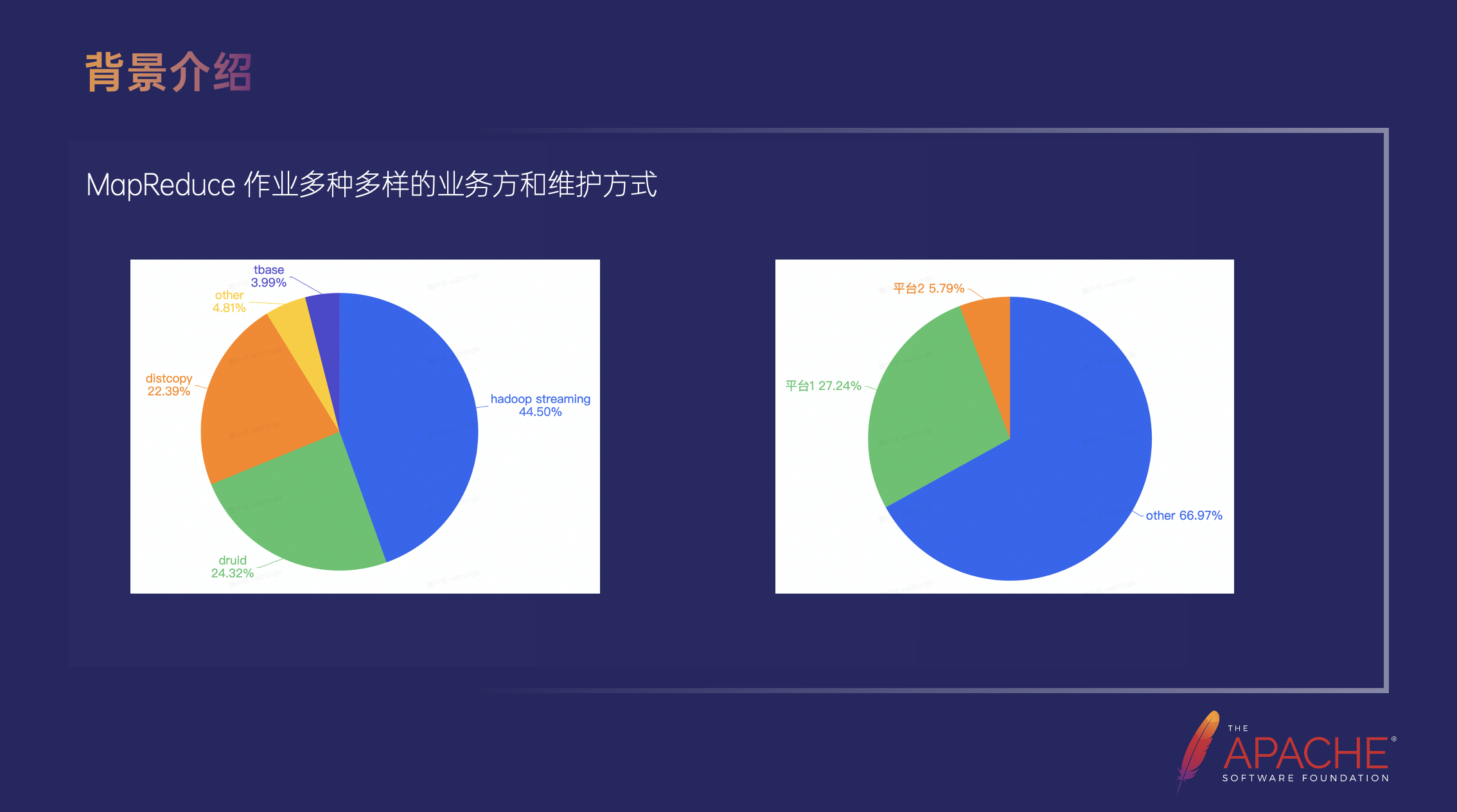
在正式推动下线之前,我们首先统计了 MapReduce 类型作业的业务方和任务维护方式。
左边的饼图是业务方的占比统计,占比最大的是 Hadoop Streaming 作业,差不多占到了所有作业的 45%,占比第二名的是 Druid 作业 24%,第三是 Distcopy 22%。这里的 Distcopy 和 Hadoop Streaming 没有按照业务线来分的原因是因为这两种类型的作业使用的是完全相同的代码,在我们推动升级的过程中可以视为相同的作业。
右边的饼图是维护方式的占比统计,占比最大的是 Others,占比高达 60%,Others 的意思是不被字节跳动内部任何一个平台管理的作业,这也非常符合 MapReduce 的特定,它是一个历史悠久的框架,很多的 MapReduce 作业在第一次上线的时候,甚至这些平台还没有出现,大部分都是从用户自己管理的容器或者可以连接到 YARN 集群的物理机上直接提交的。
为什么要推动 MapReduce 迁移 Spark
推动 MapReduce 下线有以下三个原因:
第一个原因是
MapReduce 的运行模式对计算调度引擎吞吐的要求过高。MapReduce 的运行模式中每一个 Task 对应一个 Container ,当 Task 运行结束后,就会释放 Container ,这种运行模式对于 YARN 来说是没有问题的,因为 YARN 的吞吐非常高。但是随着我们内部业务从 YARN 迁移到 K8s 集群的时候发现,MapReduce 作业经常会触发 API Server 报警,影响 K8s 集群的稳定性,一个 MapReduce 任务跑完经常需要申请 10w 个以上的 POD;而同样规模的 Spark 作业可能仅需要几千个 POD,因为 Spark 作业内部还有一层调度,Spark 申请到的 Container 作为 Executor 不会在跑完一个 Task 后推出,而是由 Spark 框架调度新的 Task 上来继续使用。
MapReduce 的运行模式对计算调度引擎吞吐的要求过高。MapReduce 的运行模式中每一个 Task 对应一个 Container ,当 Task 运行结束后,就会释放 Container ,这种运行模式对于 YARN 来说是没有问题的,因为 YARN 的吞吐非常高。但是随着我们内部业务从 YARN 迁移到 K8s 集群的时候发现,MapReduce 作业经常会触发 API Server 报警,影响 K8s 集群的稳定性,一个 MapReduce 任务跑完经常需要申请 10w 个以上的 POD;而同样规模的 Spark 作业可能仅需要几千个 POD,因为 Spark 作业内部还有一层调度,Spark 申请到的 Container 作为 Executor 不会在跑完一个 Task 后推出,而是由 Spark 框架调度新的 Task 上来继续使用。
第二个原因是
MapReduce 的
Shuffle
性能非常差。内部使用的 MapReduce 是基于社区的2.6版本,它的 Shuffle 实现依赖的 Netty 框架大概是十年前的版本,与当前的 Netty 相比差了一个大版本,在实际使用中也会发现它的性能比较差,而且也会在物理机创建过多的连接,影响物理机的稳定性。
MapReduce 的
Shuffle
性能非常差。内部使用的 MapReduce 是基于社区的2.6版本,它的 Shuffle 实现依赖的 Netty 框架大概是十年前的版本,与当前的 Netty 相比差了一个大版本,在实际使用中也会发现它的性能比较差,而且也会在物理机创建过多的连接,影响物理机的稳定性。
第三个原因是从开发工程师的角度考虑,我们内部有很多横向改造的项目,比如刚刚提到的 K8s 的改造,还有 IPV6 适配,改造成本跟 Spark 其实是一样的,但是 MapReduce 的任务数量现在只有 Spark 的 1%,不仅
改造的 ROI
很
低,不改造的情况下维护 MapReduce 作业的 History Server 和 Shuffle Service 也会花费大量精力。所以就需要推动从 MapReduce 到 Spark 的迁移。
改造的 ROI
很
低,不改造的情况下维护 MapReduce 作业的 History Server 和 Shuffle Service 也会花费大量精力。所以就需要推动从 MapReduce 到 Spark 的迁移。
升级 Spark 的难点
首先,存量任务的比例很低,目前每天只有1万多的作业量,但是绝对值依然很大,也会涉及到很多的业务方,且其中有很多是运行非常久的任务,可能运行了四五年,推动用户主动升级的难度很大。
其次,从可行性上而言,有一半以上的作业都是 Hadoop Streaming 作业,包含了 Shell ,Python,甚至 C++ 程序,虽然 Spark 有一个 Pipe 算子,但是让用户把已有的作业迁移到 Spark Pipe 算子还是有很大的工作量。
最后,在有用户协助启动改造的情况下,还会面临很多其他问题,比如在主要计算逻辑的迁移之外,还有很多外围的工具需要迁移;在迁移过程中某些 MapReduce 参数应该如何转化为等效的 Spark 参数,以及如何等效的在 Spark 中实现 Hadoop Streaming 作业脚本依赖的环境变量注入等问题,这些问题如果交给用户解决,不仅工作量大,失败率也很高。
整体方案
设计目标
上文梳理了现状、动机、难点,基于以上这些信息,在升级前的目标是:
-
避免用户进行代码级别的改造,实现用户完全不动,仅需增加一些作业参数就能完成升级。
-
需要支持各种类型的作业,包括 Hadoop Streaming,Distcp 以及普通用户使用 Java 编写的作业。其中 Hadoop Streaming 使用 MapReduce 的旧 API,而 Distcp 在使用的新 API,这就相当于我们的升级方案需要支持所有的 MapReduce 作业。
方案拆解
对整体方案的拆解主要分成四部分:
-
计算过程适配,主要是对齐 Mapreduce 的计算逻辑和 Spark 的计算逻辑。
-
配置适配,帮助用户自动地完成 Mapreduce 参数到 Spark 参数的转化。
-
提交端适配,这个是真正实现平滑迁移的关键点,使用户不需要修改他的提交命令就可以完成升级。
-
配合工具,帮助用户做数据正确性的校验。
计算过程适配
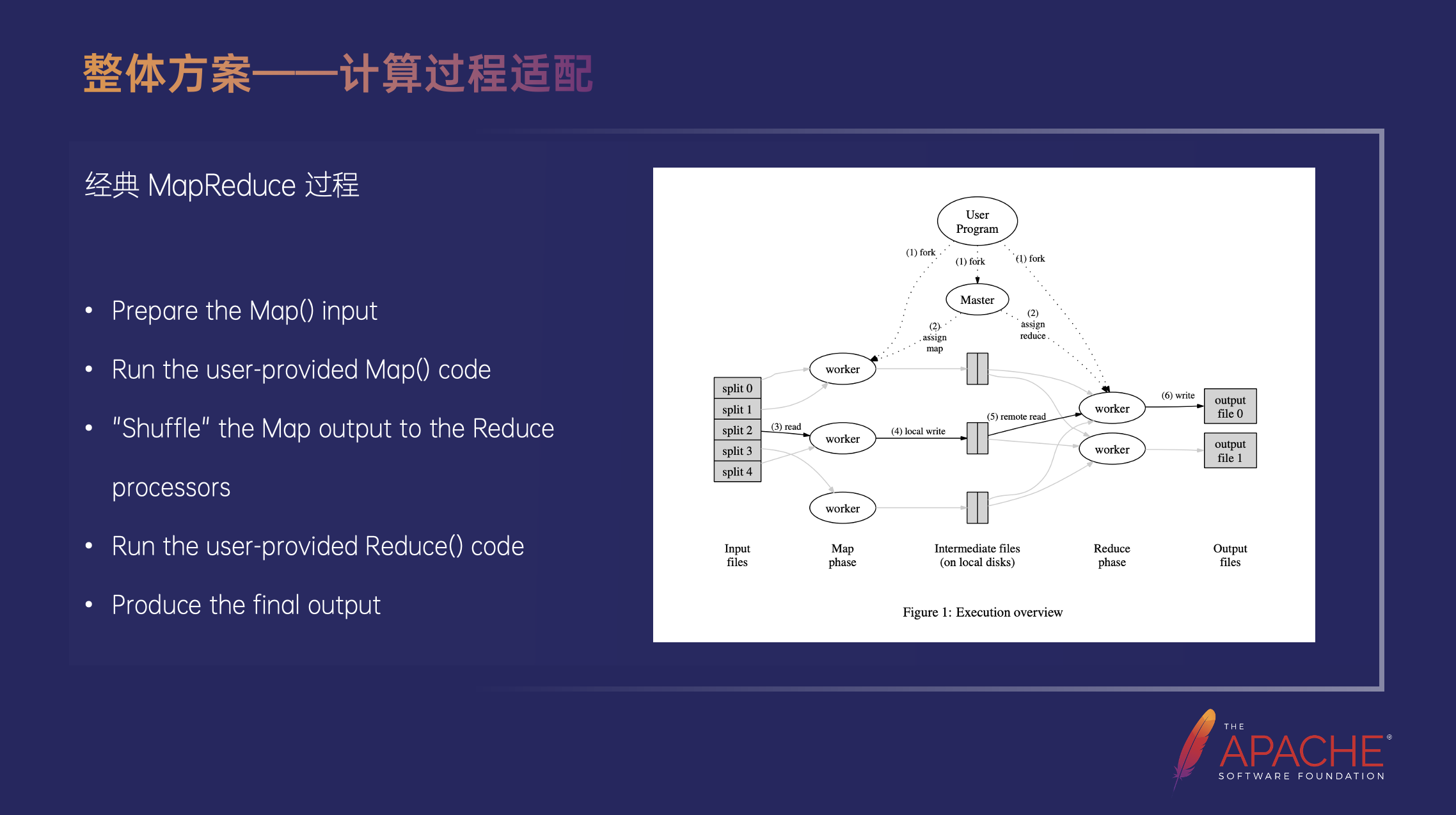
截图来自论文(https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf),一个经典的 MapReduce 过程分五步:
第一步是处理 Input 数据,然后把它做切分;第二步是运行用户提供的 Map 代码;第三步是做 Shuffle;第四步是运行用户提供的 Red服务器托管网uce 代码;第五步是把 Reduce 代码处理的结果写到 HDFS 文件系统中。实际上 MapReduce 还有一个十分广泛的用法,就是 Map Only,即没有下图中间两个步骤的用法。
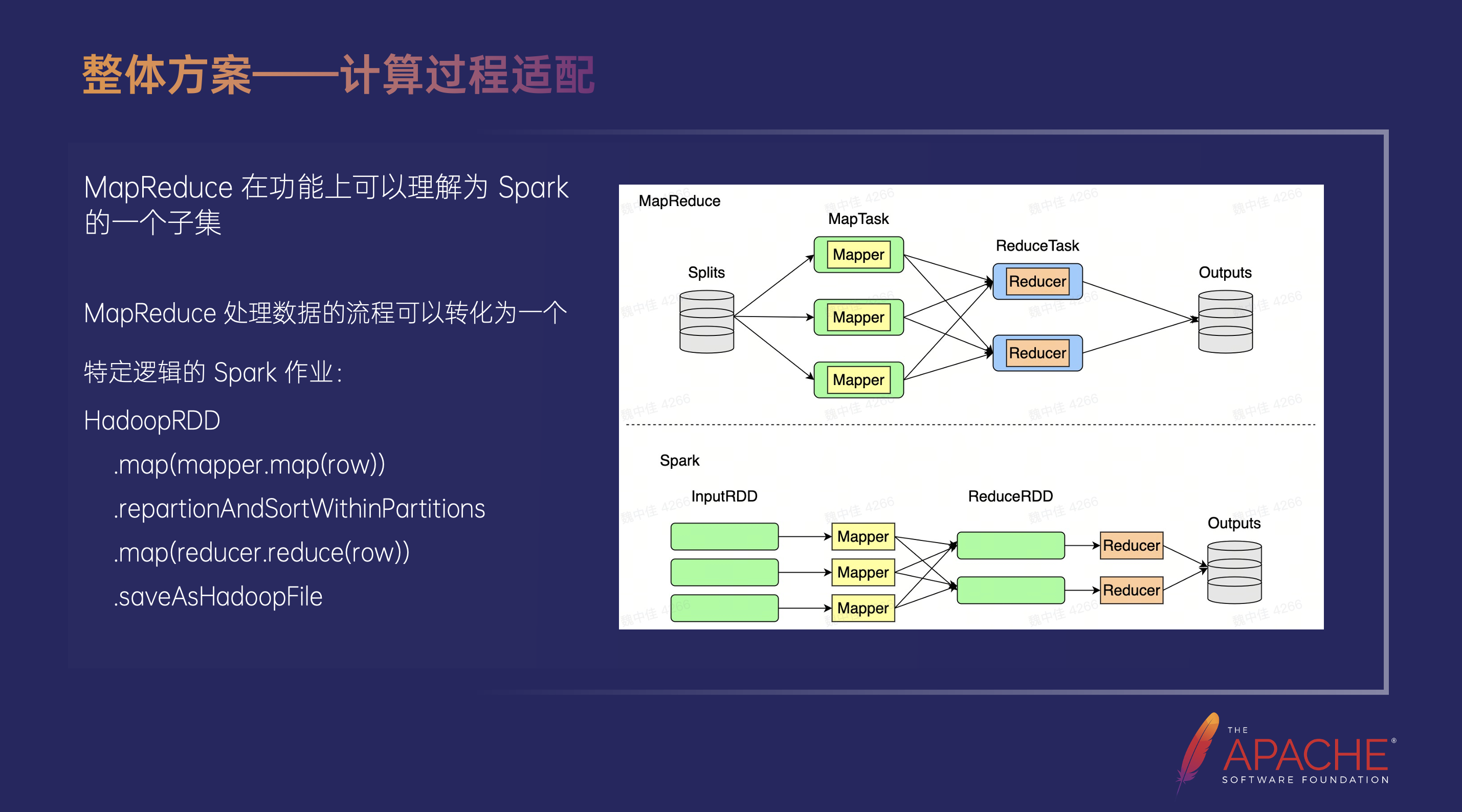
熟悉 Spark 的同学应该了解整个 MapReduce 的过程可以理解成是 Spark 的一个子集,甚至可以说是一个特定逻辑计算过程的 Spark 任务,我们在图中列举了一个伪代码,完美对应了前面整个 MapReduce 的过程。
第一步是去创建一个 Hadoop RDD,因为 Hadoop RDD 本身依赖的就是 Hadoop 自己的 Inputformat 的代码,所以这个是完全适配的;第二步调用 Spark 的 Map 算子,然后在 Spark 的 Map 算子里调用用户的 Map 函数;第三步,为了迁移的普适性,统一用 RepartitionAndSortWithinPartitions 方法。该方法完全对应了 MapReduce 里面的 Shuffle 过程;第四步用 Map 算子执行用户提供的 Reduce 代码;第五步 SaveAsHadoopFile,对应的是 Mapreduce 里最后的存储过程。

上述思路实际上是用户自己做 MapReduce 到 Spark 升级时的常规思路,但是如果我们要设计一个通用的升级方案,仅仅用 Spark 的算子对应到 MapReduce 的计算过程是不够的。通过对 MapReduce 和 Spark 框架分析发现:
最下层是相同的,都需要依赖资源调度器: YARN 或 K8s。上面一层的功能相同或者接近,但实现上是完全不同的,比如在 MapReduce 里的名字叫做 InputFormat,OutputFormat,在 Spark 里对应叫做 HadoopRDD saveAsHadoopFile;Mareduce 的计数器叫做 counter,对应在 Spark 里的 Accumulator。其他的包括 Shuffle、资源调度、History、推测执行这些功能都是对齐的,但实现也是不一样的,所以我们需要做的工作就是把 MapReduce 里的实现替换成 Spark 来实现。
在设计目标中提到的最上层—实现层应该是完全不变的,如上图粉色这一层是没办法直接运行在 Spark 底座上的,所以我们通过增加一个中间层去适配用户的代码和 Spark 计算接口,用 MapRunner、 ReduceRunner 适配 Hadoop 里的 Map 和 Reducer 方法,从而使 Spark 的 Map 算子可以运行 Mapper 和 Reducer,我们通过 Counter 的 Adapter 适配用户的 Counter 调用行为。当用户通过 Counter 接口 Increase 一个数字的时候会把它转化成对 Spark 的 Accumulator 调用,对 Configuration 也有对应的 Couf Translator,即在提交任务的时候,通过对用户生成一个 Hadoop 的Configuration 并用这个 Translator 把它翻译成对应的 Spark 参数,这个就是整个计算过程的适配,通过这个适配整体逻辑上就可以直接用一个 Spark 作业去跑用户的代码了。
配置适配

主要可以将配置分为三类:需要翻译的配置、直接透传的配置和需要忽略的配置。
在第一类需要翻译的配置中,比如作业资源类的参数,MapReduce 和 Spark 都需要告诉资源框架我需要什么样的 Container 来处理这些数据,但他们使用的参数是不同的,在提交作业的时候,需要完成参数的翻译,表格中还有环境变量、上传文件、作业并发数等,这些参数都需要做如上翻译。
第二类是需要直接透传的配置,因为 Spark 需要依赖 Hadoop 里非常多的类,这些类中的很多也需要配置。这里我们可以在翻译的时候通过加一个
hadoop.Spark. 的前缀就可以直接透传。
第三类是需要忽略的配置,就是在 MapReduce 里面有的功能,但在 Spark 里面没有。这种我们就把它放到用户手册里面,告诉用户不支持这个功能。
提交端适配
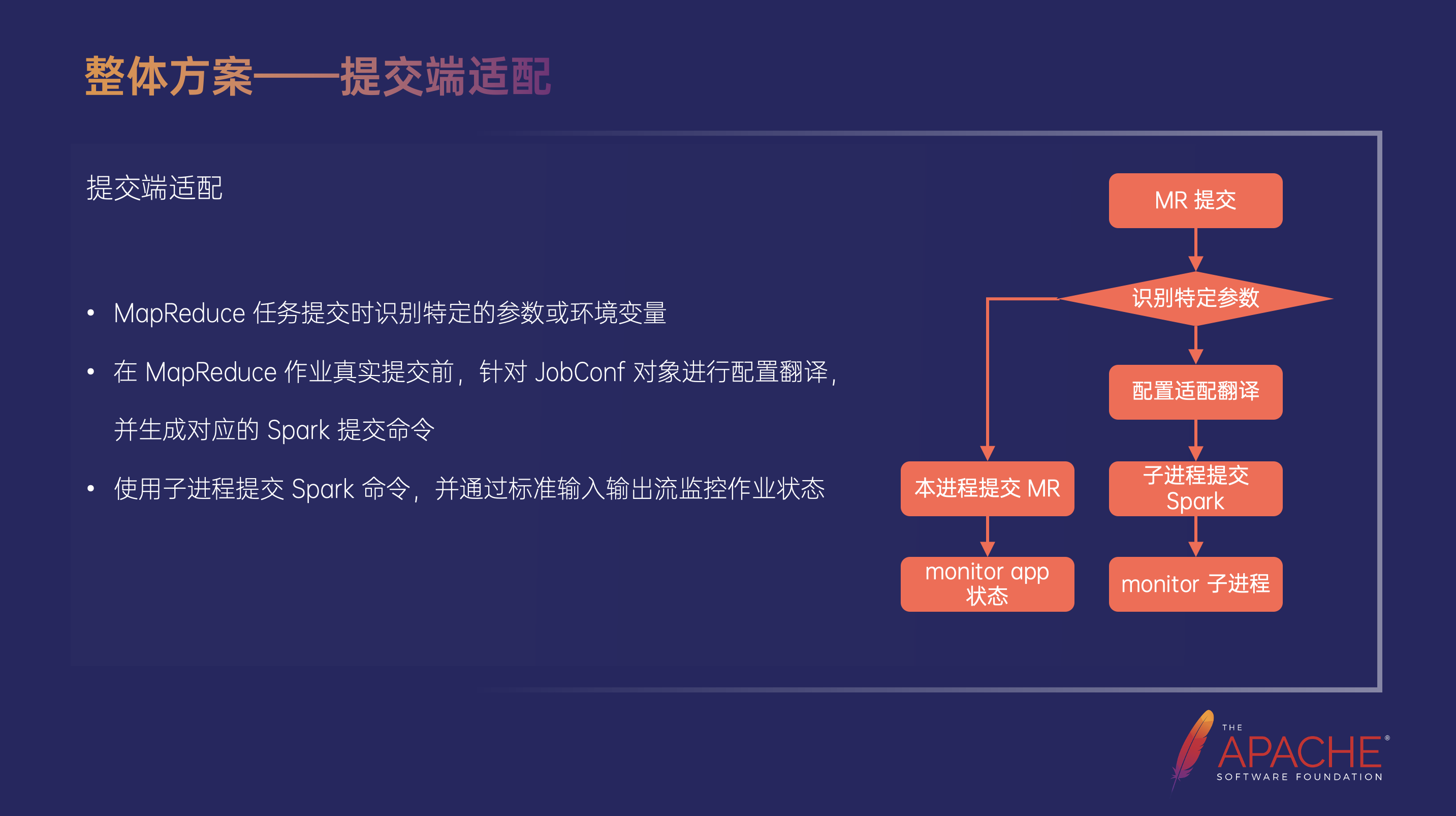
为了用户体验,我们希望用户提交的脚本是完全不需要修改的,依然用 Hadoop 的方式提交作业,不需要改成 Spark Submit。因此在实现中我们通过给 Hadoop 打了一个 Patch,在 MapReduce 作业提交的时候,提交程序去识别一个特定的参数或者环境变量,当识别到之后,就会使用我们刚刚提到的配置翻译的功能对这个 JobConf 对象做配置翻译,翻译完成后会生成一个对应的 Spark 提交命令开启一个子进程运行这个 Spark Submit 命令。
同时 MapReduce 本身有一个功能是通过不停地轮询来感知这个作业的运行状态。因为我们现在拥有了一个子进程,这个 Monitor 的行为由原来通过调用 RM 或者 AM 的接口去查询某一个 Application ID 的状态变成了查询这个子进程的状态。
正确性验证
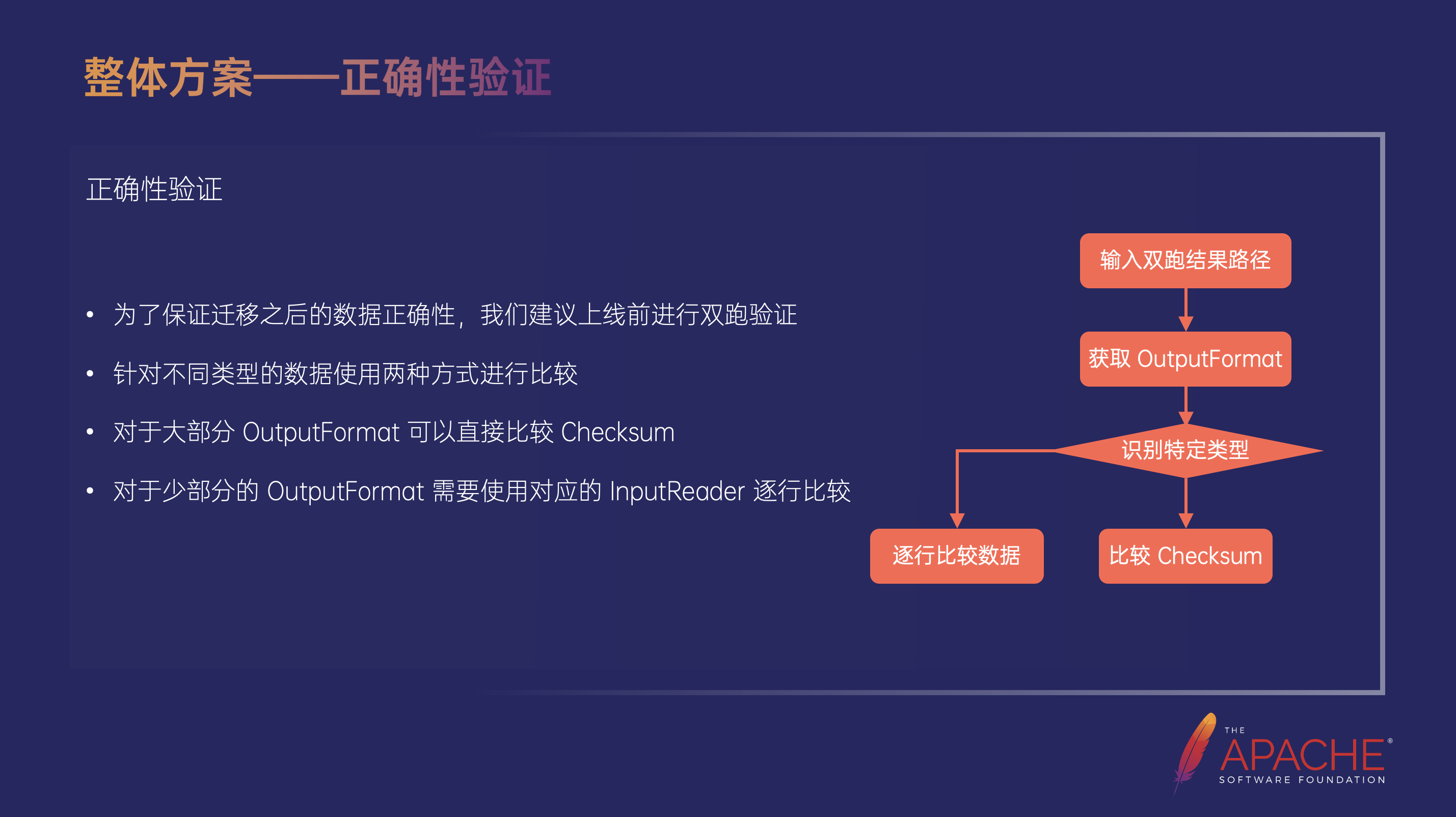
完成上述三个步骤之后基本能够实现平滑迁移,但在上线之前我们会建议用户做双跑验证,双跑验证实际上是大家都会进行操作的,但这里需要提及的是我们在这个地方遇到了一个问题,即针对不同的数据类型要用两种比较方式,对于大部分的 Output Format 是可以直接比较 CheckSum 的,但是对于少部分的 Output Format,需要使用对应的 Input Reader 逐行比较,因为有的 Output Format 生成的文件里面会包含类似于时间戳或者跟用户相关的一些信息,每一次运行产出的文件可能是不一样的,这个时候如果我们要去比较的话,就需要生成对应的 Reader,一行一行的把文件读出来做逐行比较。
问题及解决方案
内存设置-MapReduce内存与Spark Executor内存一一对应在某些情况下会触发OOM
上部分说到我们会对内存做一个平行翻译,比如原有的 MapReduce 任务使用 4G 内存转成 Spark 之后仍然使用 4G 内存,但是这样会使很多作业触发 OOM。主要原因是 MapReduce 和 Spark 的内存模型不完全相同,在 MapReduce 中做 Shuffle Spill 默认缓存是 256M,而在 Spark 里实际上是由一个 Memory Manager 管理内存,默认最大使用率为全部内存的 60%。同时 MapReduce Shuffle 时的网络协议和 Spark 也不一样,由此会创建更多的并发,使用更多的内存。
为了解决这个问题,我们给所有平行迁移的任务统一设置了一个参数 Spark.memory.fraction=0.4,用于降低 Shuffle Spill 时的内存,同时默认为每 Core 增加 512M 内存,在该策略上线之后,所有平滑迁移任务 OOM 的情况都已经解决了。
并发度设置-Hadoop Streaming作业在使用本地目录的时候可能会产生目录名冲突
Spark 作业可以支持一个 Container 里同时跑多个 Task。某些 HadoopStreaming 作业脚本在使用时会在本地目录下再创建一个目录,而在使用 Spark 时多个 Task 同时运行这个目录就会产生冲突。而在 MapReduce 中每个 Task 都会使用一个全新的 Container ,也就不会发生对应的冲突问题。
针对这个问题主要有以下两个解决办法:
第一,增加一个参数,用于控制升级后的 Spark 作业的 Executor 并发度,默认情况下直接给用户设置为单 Core 的 Executor,也就相当于一个 Executor 还是运行一个任务。
第二,建议用户修改他的目录创建逻辑,在创建本地目录时不要创建一个固定名称的目录,而是读取环境变量里面的 Task ID,创建一个带 Task ID 的本地目录来避免冲突。
类加载问题-升级后用户作业运行时会出现类加载的问题
很多的 Jar 包任务在升级之后会出现类加载问题。这个问题的根源是因为 Spark 类加载器使用了自定义的 ClassLoader,它对于类的加载分了两类,一类是 Framework 的 Class Loader,一类是 User Class 的 Class Loader。而 Hadoop 本身是 Spark Framework 所依赖的类,所以会使用 Framework 的 ClassLoader 来加载,同时用户的任务代码也依赖 Hadoop,就会有一部分依赖是使用户代码的 ClassLoader 来加载的,所以就会出现各种 Class 的加载问题。
针对这个问题大部分情况下设置 Spark.exec服务器托管网utor.userClassPathFirst=true 参数让 Spark 作业默认先去加载用户的类就能够避免。但会有一部分用户在设置这个参数之后出现问题,这样的情况手动设置成 False 即可解决。
功能对齐问题-MapReduce 功能跟 Spark 不完全对齐
在实践过程中用户会苦恼 MapReduce 中的有些功能在 Spark 里是没有的,比如 MapReduce 中可以通过设置一个参数支持部分 Task 成功,只要 Task 失败不超过这个比例,整个 Job 就是成功的,但在 Spark 中就没有这个功能。
解决办法是大部分情况下用户可以自己解决,但对于少部分的情况,如用户明确上游会有坏文件,我们则会提供一些其他的 Spark 参数来避免任务失败。
Task Attempt ID 问题-部分用户依赖环境变量中的 Task Attempt ID,在 Spark 中无该对应值
Task Attempt ID 问题本质上也是一个对齐的问题,有的用户尤其是 HadoopStreaming 作业依赖环境变量中的 Task Temp ID ,而该值在 Spark 中是没有严格对应概念的。Task Attempt ID 是 MapReduce 里某一个 Task 重试的次数,在 Spark 里面 Shuffle Failure 会导致 Stage Retry 而不是 Task Retry,在 Stage Retry 时这个 Task 的 Index 就会发生变化,所以 Retry 的次数无法对应到某一个 Partition ID。
这个问题我们实现了一个近似的解决方案,使用 Spark Task Context 里提供的另外一个全局递增的正整数—Attempt ID,用于区分不同的 Task 来解决对应值问题。
收益
统计
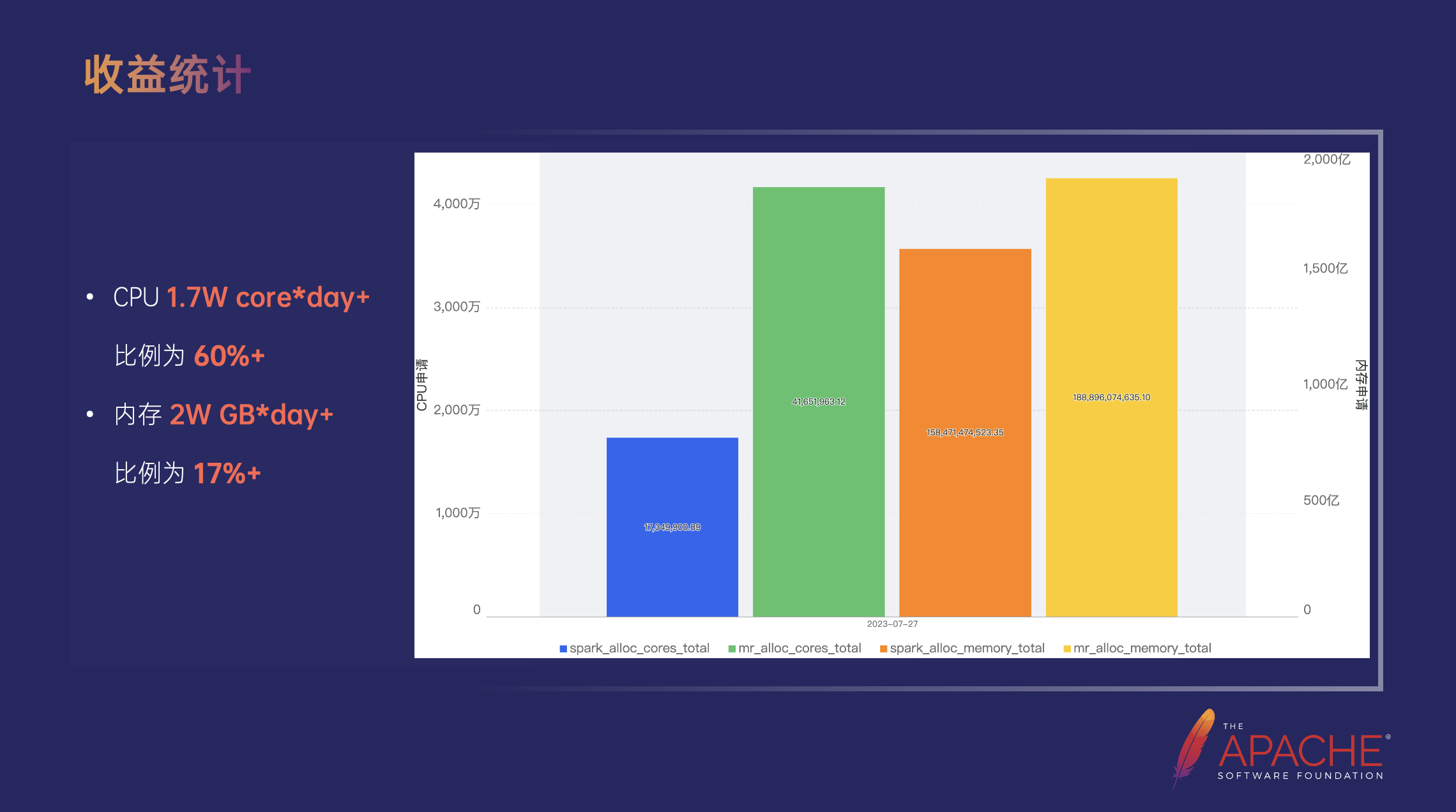
通过以上的平滑迁移方案推动用户从 MapReduce 升级到 Spark,整体取得了非常好的效果,以近 30 天所有完成迁移的平均 MapReduce 申请资源量(迁移前)和 Spark 申请资源量(迁移后)的对比为例。从图中可以看到,CPU 每天节省的申请量是 1.7 万,提升了 60%,即升级后用原来 40% 的资源就可以将这些任务全部运行完;内存上的用量每天可节约 20000GB 左右 ,为之前的 17% 左右 。
解读
-
如上介绍这是一个平滑迁移的方案,用户并没有使用 Spark 重写任务,大家都知道 Spark 是一个能够更好利用内存的静态引擎,因此平滑迁移的收益应该低于用户的手动迁移。因为当前的升级收益其实并不来自于 Spark 算子本身,实际上用户的处理逻辑是完全不变的,运行的代码也还是 MapReduce 代码,如果是 HadoopStreaming 作业的话,跑的代码就还是用户编写的脚本,所以这个收益并不来自于 Spark 算子本身。
-
收益主要来自于 Shuffle 阶段,即 Spark Shuffle 相比于 MapReduce Shuffle 从网络框架到实现细节都要更好。我们针对 Spark Shuffle 也做了一些深度的定制优化,提升了 Shuffle 的性能,如果大家感兴趣的话,可以去看相关文章推荐。Shuffle 优化缩短了作业的运行时间,有一些作业平均的 Map 时间为 2 分钟,Reduce 时间为 5 分钟,Shuffle 的时间很多都会高于 10 分钟。通过升级 Spark 之后,Shuffle 时间可以直接降到 0。这里因为 Spark 的 Shuffle 是异步 Shuffle,可以在主线程计算数据,在其他线程读数据,从而将中间 Block 的时间降到毫秒级。
-
因为收益主要来自 Shuffle,所以对 Map Only 作业的性能提升并不明显。所有完成了升级的 Map Only 作业、Distcp 作业,资源申请量变化不大,在 90% 到 110% 之间浮动。
-
CPU 的收益比内存收益明显更高的原因是 CPU 是完全平行的迁移,而内存不一样,Map 和 Reduce 通常取的是内存最大值,会造成内存的浪费。另外就是为了避免瓶颈迁移之后产生的 OOM 问题,又统一为每 Core 增加了 512M 内存,所以整体算下来内存申请量是增加的,但是因为 Shuffle 阶段的收益使作业的运行时间变短,整体内存的收益依然正向的。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
