
'''目标:拟合物料冷却规律
分类变量:物料规格,冷却方式
连续变量:温度,时间
其他因素:车间温度
现实因素:初始温度,初始时间
需求因素:目标温度的时间,目标温度的时长(时间-初始时间),当前时间的温度
不加入分类变量则为单个线性模型'''
'''实验1 只有温度和时间
每个物料的初始温度和初始时间不一样
无分类变量需转为读热编码'''
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
'''
# 生成数据
temperature = np.array([300, 200, 100, 10])
time = np.array([np.datetime64('2023-01-01 00:00:00'), np.datetime64('2023-01-01 07:00:00'), np.datetime64('2023-01-01 12:00:00'), np.datetime64('2023-01-01 20:00:00')])
time_initial = time[0]
temperature_initial = temperature[0]
# 转为与初始时间和初始温度比较,未做归一化(离差标准化),标准化等处理
# 这样, 所有的线性模型的初始自变量和初始因变量都是0,在第四象限大体呈递减状
# 模型拟合完成后,需要预测时,再分别加上初始时间和初始温度即可
x = time - time_initial
Y = temperature - temperature_initial
# 每个物料都有各自的初始时间和初始温度
# 生成数据,转化数据
# array内部长度不一需指定dtype
# 使用pandas生成面板数据以供筛选
'''
# 生成数据,转化数据
panel_data = pd.DataFrame(
{
'material': ['material_1']*3 + ['material_2']*4 + ['material_3']*5,
'time':
[np.datetime64('2023-01-01 00:00:00'), np.datetime64('2023-01-01 07:00:00'), np.datetime64('2023-01-01 18:00:00')] +
[np.datetime64('2023-01-01 00:00:00'), np.datetime64('2023-01-01 07:00:00'), np.datetime64('2023-01-01 12:00:00'), np.datetime64('2023-01-01 20:00:00')] +
[np.datetime64('2023-01-01 00:00:00'), np.datetime64('2023-01-01 06:00:00'), np.datetime64('2023-01-01 12:00:00'), np.datetime64('2023-01-01 16:00:00'), np.datetime64('2023-01-01 21:00:00')],
'temperature': [250, 150, 20] + [300, 200, 100, 10] + [310, 200, 90, 50, 5]
}
)
panel_data.set_index(['material'], inplace=True) # 若无这一步,下一步会报错
panel_data['time_initial'] = panel_data.groupby(['material']).apply(lambda x: x['time'][0])
panel_data['temperature_initial'] = panel_data.groupby('material').apply(lambda x: x['temperature'][0])
panel_data['x'] = panel_data['time'] - panel_data['time_initial']
panel_data['Y'] = panel_data['temperature'] - panel_data['temperature_initial']
panel_data.set_index([panel_data.index, 'time_initial', 'temperature_initial', 'time'], inplace=True)
# 汇总拟合
# 分组预测
X = panel_data['x'].dt.total_seconds().values.reshape(-1, 1)
Y = panel_data['Y']
linear_model = LinearRegression()
linear_model.fit(X, Y)
Y_pred = linear_model.predict(X)
plt.scatter服务器托管网(X, Y, label='Linear Regression Actual Data')
plt.plot(X, Y_pred, color='red', label='Linear Regression Prediction')
plt.xlabel('Time Difference')
plt.ylabel('Temperature Difference')
plt.title(f"Linear Regression Prediction Formula: Y_pred = {linear_model.coef_[0]:.4f} * X + {linear_model.intercept_:.4f}")
plt.legend()
plt.show()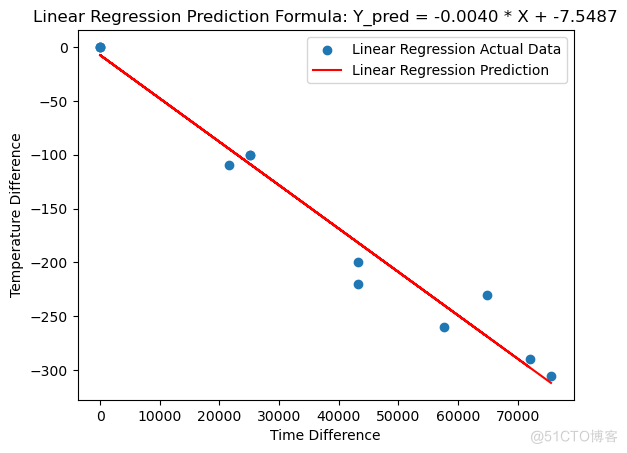
In[56]:
'''对照样本与拟合结果'''
panel_data['Y_pred'] = linear_model.predict(X)
panel_data['temperature_pred'] = panel_data['Y_pred'].values + panel_data.reset_index()['temperature_initial'].values
'''预测'''
predict_material = 'material_1'
predict_time = np.datetime64('2023-01-01 17:00:00')
target_temperature = 10
# 目标时间的物料温度
predict_X= np.array((predict_time - panel_data.loc['material_1'].reset_index()['time_initial'][0]).total_seconds()).reshape(-1, 1)
result_temperature = linear_model.predict(predict_X) + panel_data.loc['material_1'].reset_index()['temperature_initial'][0]
# 目标温度的时长和时间
target_Y = target_temperature - panel_data.loc['material_1'].reset_index()['temperature_initial'][0]
result_TimeDuration = pd.Timedelta(seconds = (target_Y - linear_model.intercept_) / linear_model.coef_[0])
result_time = np.array([np.datetime64(result_TimeDuration + panel_data.loc['material_1'].reset_index()['time_initial'][0])])In[]:
In[]:
In[22]:
import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# 指定支持中文的字体,例如SimHei或者Microsoft YaHei
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题In[3]:
# 定义指数衰减模型函数
def exponential_decay(t, T0, k):
return T0 * np.exp(-k * t)In[10]:
# 生成模拟数据
np.random.seed(0)
n_samples = 100
time = np.linspace(0, 10, n_samples) # 时间数据In[11]:
# 创建一个包含时间和冷却方式的DataFrame
data = pd.DataFrame({
'Time': time,
'Cooling_Method': np.random.choice(['Natural', 'Fan1', 'Fan2'], size=n_samples)
})In[13]:
# 根据不同的冷却方式生成温度数据
data['Temperature'] = 500 # 初始温度
data.loc[data['Cooling_Method'] == 'Natural', 'Temperature'] = data['Temperature'] * np.exp(-0.1 * data['Time'])
data.loc[data['Cooling_Method'] == 'Fan1', 'Temperature'] = data['Temperature'] * np.exp(-0.2 * data['Time'])
data.loc[data['Cooling_Method'] == 'Fan2', 'Temperature'] = data['Temperature'] * np.exp(-0.15 * data['Time'])In[20]:
# 拟合指数衰减模型
# 目的是针对不同的冷却方式拟合指数衰减模型,并将拟合的参数存储在一个字典中以供后续分析或可视化使用。
# 拟合是通过 curve_fit 函数完成的,该函数使用初始参数猜测值来拟合模型并返回最优的参数
fit_parameters = {} # 创建一个空字典,用于存储拟合参数
# 遍历不同的冷却方式
for method in data['Cooling_Method'].unique():
subset = data[data['Cooling_Method'] == method] # 从数据中选择特定冷却方式的子集
# 提供初始参数猜测值
# 如果你不打算使用某个变量的值,可以使用 _ 来表示它是一个占位符,用来忽略这个值
# 即curve_fit 函数的返回值中的第二个值,即协方差矩阵
# 例如,对于冷却方式 'Natural',初始参数猜测值是第一个时间点的温度和0.1
initial_guess = (subset['Temperature'].iloc[0], 0.1)
# 使用 curve_fit 函数来拟合指数衰减模型
# 这个函数会拟合一个给定的模型函数(这里是 exponential_decay)到数据中,并返回最优的参数
params, _ = curve_fit(exponential_decay, subset['Time'], 服务器托管网subset['Temperature'], p0=initial_guess)
# 将拟合参数存储在字典中,以便稍后使用
fit_parameters[method] = params
# 示例:
# 如果 data 数据包含不同冷却方式的温度数据和时间数据,fit_parameters 字典将包含每种冷却方式的拟合参数。
# 例如,fit_parameters['Natural'] 将包含冷却方式为 'Natural' 的拟合参数。
# 这些参数描述了指数衰减模型的 T0 和 k 参数,该模型用于拟合该冷却方式下的温度数据。In[23]:
# 绘制拟合曲线
plt.figure(figsize=(10, 6))
for method, params in fit_parameters.items():
fit_time = np.linspace(0, 10, 100)
fit_temperature = exponential_decay(fit_time, *params)
plt.plot(fit_time, fit_temperature, label=f'{method}拟合')
# 绘制原始数据
for method, subset in data.groupby('Cooling_Method'):
plt.scatter(subset['Time'], subset['Temperature'], label=method)
plt.xlabel('时间')
plt.ylabel('温度')
plt.legend()
plt.title('不同冷却方式下的温度趋势拟合')
plt.show()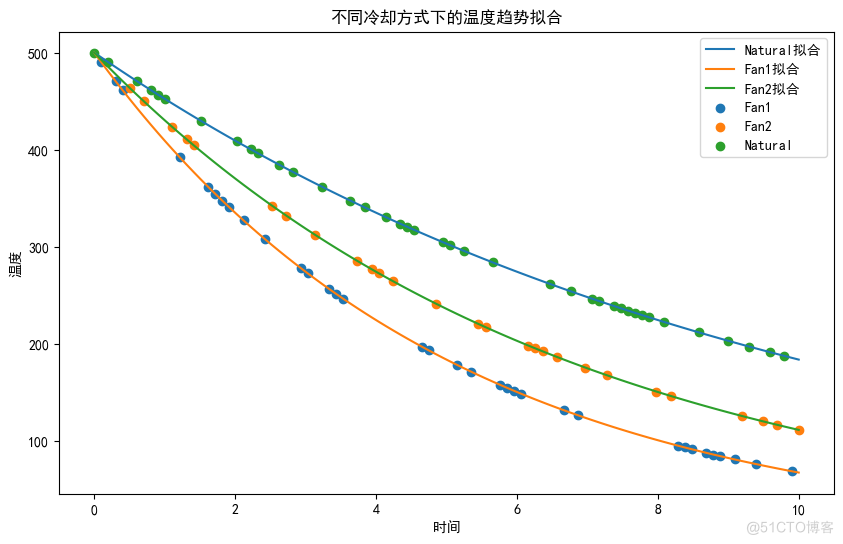
In[]:
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 【9月福利周】邀好友共领新人福利,茶具/游戏鼠标“2选1”
嘿,9月福利周来啦~ 今日起,邀请好友在51CTO博客成功发布第一篇原创技术文章,你和好友都有福利!(含代码400字以上必有奖) 活动时间 活动时间:9月14日-9月20日(共7天) 活动福利 活动页面:点击此处>>> 累计邀请人数 好友奖励…
