
作者:陈璐、陈东
背景
OpenYurt 项目的使命是将 Kubernetes 在云端强大的管控能力下放到边缘测,把海量的异构边缘资源纳入进一个统一的边缘计算平台中。但边缘场景的一些特点并不符合为在云上运行而设计的 Kubernetes 的预设。这也正是 OpenYurt 需要解决的问题。边缘自治能力就是在这样的背景下诞生的。
与安全稳定的云上网络环境不同,在边缘场景中,边缘节点与云上的节点通常是不在一个网络平面内,需要通过公网与云端连接。公网连接带来了几方面的问题,比如高昂的公网流量成本,跨网域通信能力的需求以及本文所关注的公网连接的不稳定性问题。这些在 OpenYurt 体系里都得到了很好的解决。
我们今天主要想和大家分享 OpenYurt 社区针对最后一个问题的思考,以及针对其而设计的 OpenYurt 边缘自治能力。
Kubernetes 在不稳定网络环境下的问题
我们先看看原生 Kubernetes 在不稳定网络环境下会如何表现。当一个 Node 节点网络连接中断,那么接下来在 Kubernetes 集群会有一系列的动作 来处理这个事件 [ 1] 。
- Node 节点上的 kubelet 在 10s 内发现网络问题,并且更新 NodeStatus,但是由于网络断开无法上报到 Control Plane
- Control Plane 的 NodeLifeCycle Controller 在 40s 内接收不到 Node 的心跳,该节点状态被调整为 Not Ready,不会再有新的 Pod 调度到该节点上
- Control Plane 的 NodeLifeCycle Controller 在 5min 内接收不到 Node 的心跳,开始驱逐 Node 节点上所有的 Pod
当一个节点无法上报心跳,Kubernetes 集群据此判断该节点存在异常,作为异常资源它不再适合支持上层的应用。这样的做法对于数据中心里全天 24h 随时在线的机器是合适的,但在网络环境复杂的边缘场景里,这样的策略就有待商榷了。
首先,在一些边缘场景中,边缘节点需要主动地中断网络连接来支持断网维护的需求,此时原生 Kubernetes 会驱逐边缘容器,一些边缘组件也会由于 APIServer 无法连接,资源同步失败而报错,甚至退出,这显然是无法接受的。更深入一些,节点无法上报心跳这个现象背后可能有两方面的原因,要么是机器故障带着所有的 workload 一起挂掉了,要么是机器仍在正常运行但网络断连。Kubernetes 对这两种情况不做分别,直接将没有心跳的节点置为 Not Ready。但在边缘场景中,网络断连是一种常见的场景甚至需求,我们能不能分辨出这两类原因,仅在节点故障时才对 Pod 进行迁移重建。
其次,还有一类典型的边缘业务甚至要求在节点故障时也不要对 Pod 进行驱逐,它们需要将特定的 Pod 绑定到特定的节点上。比如图像处理的应用需要绑定到摄像头对应的机器上,智慧交通的应用需要固定在某个路口的机器上。这种与节点绑定的需求实际上违背了 Kubernetes 将底层资源与上层应用隔离开的设计理念,但这也是边缘业务确有的诉求,是需要 OpenYurt 来支持的。
最后,我们还需要考虑断网重启的情况。在原生 Kubernetes 架构下,Slave Agent(Kubelet) 的容器信息都保存在内存中,而断网状态下又无法从云端获取业务数据,如果此时边缘节点或者边缘节点的 Kubelet 发生异常重启,它们将无法进行业务容器恢复。
OpenYurt 边缘自洽能力保障业务持续运行
如果用一句话来总结边缘自治的需求,那就是保障弱网甚至断网环境下边缘业务的持续运行。 而在 Kubernetes 体系下要实现这样的能力,我们需要解决以下几个问题:
- 节点异常或重启时,内存数据丢失,网络断连时业务容器无法恢复
- 网络长时间断连,云端控制器对业务容器进行驱逐
- 边缘业务如何绑定到特定边缘节点
OpenYurt 提供了从云到边一整套完整的解决方案来应对边缘自治的挑战。
边缘侧数据缓存
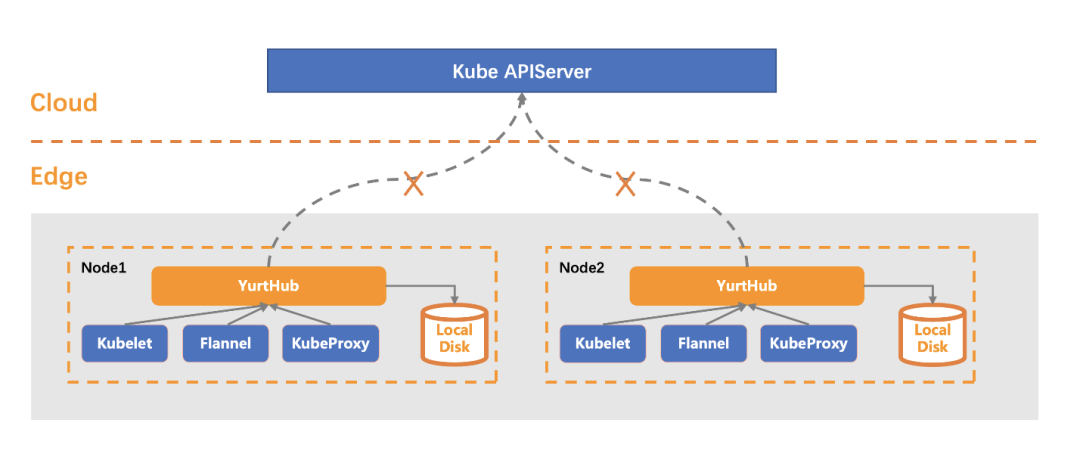
在边缘测,OpenYurt 引入了一个重要的组件——YurtHub。YurtHub 在边缘节点上提供 web 缓存及请求代理的的能力,节点上系统组件(如 kubelet)以及业务容器和云端通信都将经由该组件代理。
- 云边网络正常时,YurtHub 相当于一个带有数据缓存功能的“透明网关”,将请求转发到云端并缓存返回的数据。
- 云边网络断连时,YurtHub 将请求切流至本地缓存,使得边缘组件依然能成功获取资源。如果此时发生节点或组件重启,不需要依赖云端的数据,边缘业务可以通过本地数据缓存恢复。
- 与云端的通信恢复后,Yurthub 切流回云上的中心站点,本地缓存得以更新,代理请求恢复正常转发。
YurtHub 不仅优雅地解决了断网重启问题(问题1),而且这一层对 APIServer 额外的封装也拓展出了许多其他重要的 OpenYurt 能力 [ 2] 。
中心式心跳代理机制
OpenYurt 对原生 Kubernetes 的 Pod 驱逐策略进行了一定程度的增强。在原生 Kubernetes 中,边缘节点心跳一定时间没有上报时,云端控制器将对节点上 Pod 进行驱逐(删除并在正常节点上重建)。云边协同场景下,边缘业务有不一样的需求。一些业务期待云边网络断连造成心跳无法上报时(此时节点本身正常),业务 Pod 可以保持(不发生驱逐),仅节点故障时才对 Pod 进行迁移重建。
OpenYurt 1.2 版本首创了基于 Pool-Coordinator+YurtHub 的中心式心跳代理机制,如下图:

- 节点的云边网络正常时,Kubelet 通过 YurtHub 组件同时上报心跳到云端和 Pool-Coordinator 两处。
- 节点的云边网络断连时,Kubelet 通过 YurtHub 组件上报心跳到云端失败,此时上报到 Pool-Coordinator 的心跳带上特定标签。
- Leader YurtHub 会实时 list/watch pool-coordinator 中的心跳数据,当获得的心跳数据中带有特定标签时将帮助转发该心跳到云端。
通过 Pool-Coordinator 和 YurtHub 协同实现的心跳代理机制,保障了节点在云边网络断连状态下,心跳仍可继续上报到云端,从而保证节点上业务 Pod 不被驱逐(问题2)。同时心跳被代理上报的节点,也会被实时加上特殊的 taints,用于限制管控调度新 Pod 到该节点。
节点绑定
一些边缘业务要求在节点故障时也不对 Pod 进行驱逐,将业务绑定到节点上。OpenYurt 提供了两个角度来解决这个问题。
第一个角度从节点的角度出发,比如希望这个机器上的所有 Pod 都绑定到这台机器上。那么我们可以给这个节点打上标签 node.beta.openyurt.io/autonomy=true。
第二个角度是从业务出发,比如之前提到的智慧交通的业务希望它的生命周期和它运行的节点的生命周期保持一致。OpenYurt 1.2 版本新增了 apps.openyurt.io/binding 标签,如果 Pod 上带有这个标签,意味着这个 Pod 需要节点绑定的能力。
这两种方式实际上最终都是通过给对应 Pod 添加 toleration 实现绑定能力的。
总结
在边缘场景下,由于云边网络连接不稳定,需要边缘侧在缺少云端支持时有一定的自治能力。OpenYurt 基于原生 Kuberbetes 的架构,提出了一套非侵入式的解决方案,解决了边缘自治的几个痛点问题(节点断网重启,节点断网驱逐,节点业务绑定)。
OpenYurt 1.2 版本基于 Pool-Coordinator+YurtHub 的架构增强了边缘自治方面的能力。实际上边缘自治这个领域还有很大的想象空间,比如除了在断网状态下维持基本的 Pod 运行外,在后续版本中 OpenYurt 还会提供节点池的运维能力。欢迎有兴趣的同学来参与共建,共同探索一个稳定、可靠的无侵入云原生边缘计算平台的事实标准。
如果您对于 OpenYurt 有任何疑问,欢迎使用钉钉扫描二维码或者搜索群号加入钉钉交流群。(钉钉群号:12640034121)

相关链接🔗
[1] 一系列的动作来处理这个事件
https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/589-efficient-node-heartbeats/README.md
[2] 许多其他重要的 OpenYurt 能力
https://openyurt.io/zh/docs/core-concepts/yurthub/
点击此处,立即了解 OpenYurt 项目
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
