

文章来源|ByConity 开源社区
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。
GitHub |https://github.com/ByConity/ByConity
一、背景
选择对象存储的原因
技术选型上,对象存储已经成为云原生数据库/数仓的存储标配。从成本考虑看,云上环境对象存储价格相对较低 ,交互方式标准,用户只需为实际使用的存储容量和请求来付费即可。而使用 HDFS 成本相对较高,假如自己部署 HDFS 集群,需要承担使用 HDFS 的机器成本,包括存储能力和计算能力,使用时如更看重存储能力,计算能力或多或少会有浪费。部署 HDFS 之后还要额外的运维成本,包括监控机器状态、监控集群是否需要扩容、环境维护、定期运维操作等。
另外对象存储的 Avaliability 和 Durability 很优秀,参考几个主流云厂商提供的 SLA,如 AWS S3,它对数据的 Durability 可以提供 11 个 9 的级别。
HDFS 和对象存储的区别
图中以 S3 为例,列出了一些两者之间的区别:
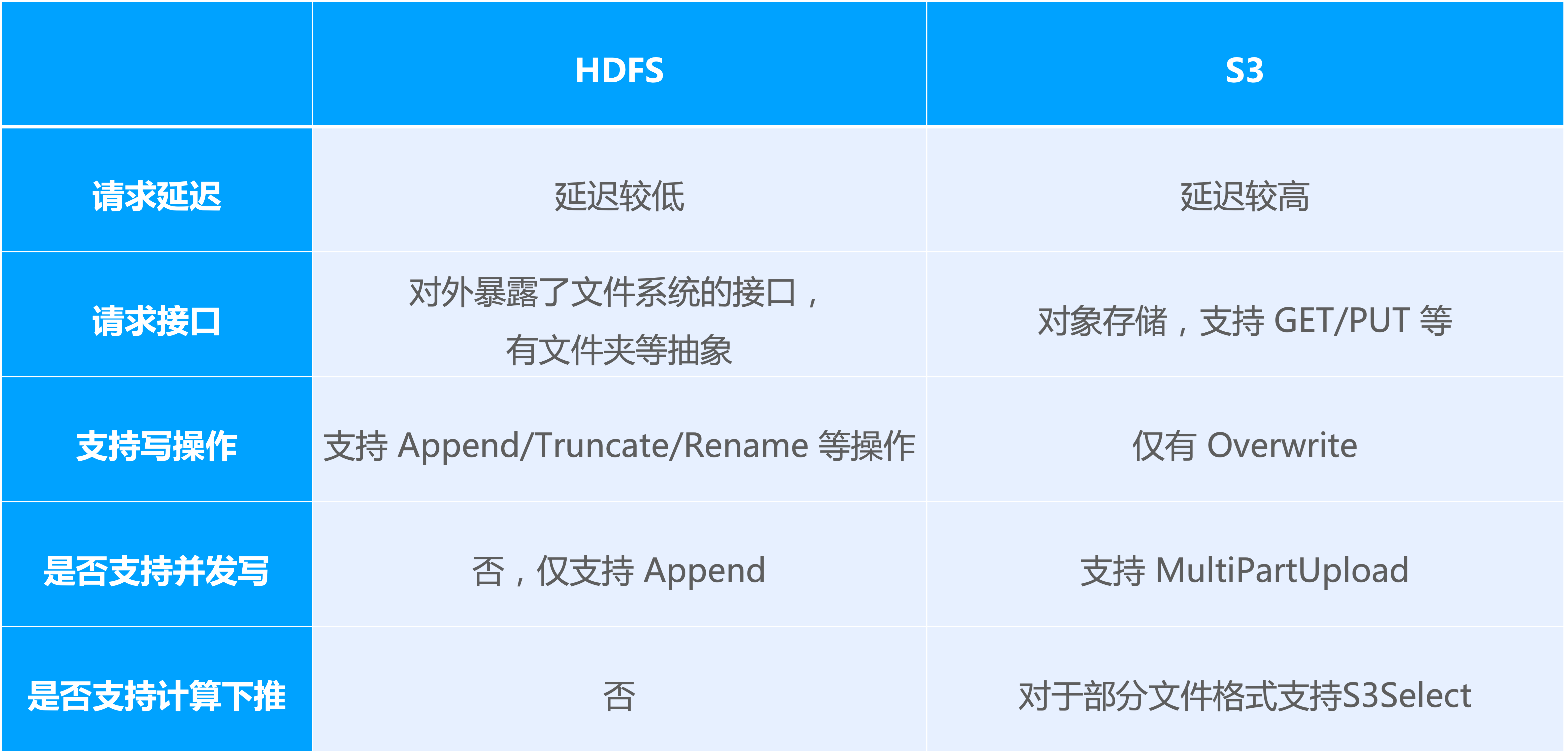
在请求延迟方面,HDFS 的延迟相对更低;对象存储即使是同一个 region 的内网访问,其延迟也相对更高,可能会有三、四十毫秒,HDFS 低的时候约 10 毫秒之内;
第二个就是对外暴露请求接口,HDFS 作为分布式文件系统,对外暴露了一些文件系统接口,及文件夹等抽象,会对外提供如 move directory 的操作;S3 作为对象存储,对外形式更类似一个 KV,支持 GET、PUT 或者 DELETE 等操作;
从支持写操作 的类型来说,HDFS 支持 Append,Truncate 和 Rename 等操作, S3 仅支持 Overwrite;
在写 入能力上,HDFS 对文件只支持 Append 追加写;S3 提供了一个比较特殊的接口—— MultiPartUpload,可以并发的写同一个对象的不同的部分;
还有一个特点就是 S3 除了对外提供像存储能力的接口之外,还提供 S3Select 的服务。对于像 CSV 或者 Parquet 的文件格式,可以将一些过滤条件下推到 S3 来做。
二、设计与实现
由于 HDFS 和对象存储其实是两个不同的系统,一个是分布式文件系统,一个是对象存储,它们对外提供的接口以及支持的一些操作都有区别。针对这些区别,在引擎支持存储类型时也有一些考量。此部分将介绍 ByConity 在支持对象存储时设计上的一些考虑和实现时改动的一些模块。
ByConity 支持对象存储的设计
Storage 存储
ByConity 引擎内部 Attach & Detach 操作依赖于数据做 Rename 的能力。使用 HDFS 作为存储时, ByConity 数据的存储路径为 root_prefix/{table_uuid}/{part_name}/data ;在做不同表之间数据的 Attach 时,如把表A 其中一个分区的数据转移到表B 中,Attach 语句会将 Part 从表 A 的路径里 Rename 到目标表B 中。对象存储如果要实现这样的 Rename 则只能 copy 完再 delete,开销相对更高。
为了解决上述的问题,ByConity 支持对象存储时修改了数据存储的 ObjectKey,使用 root_prefix/{part_id}/data 作为数据实际的 ObjectKey。在进行Attach 或者 Detach 的操作时,不再做对象的 Rename。相反,只对 Catalog 中的元数据做一些修改,如支持 Attach 操作,则只需服务器托管网将对应的 PartMeta 从原表 Rename 到目标表,不需要对对象存储上的实际数据做任何修改。对于 Detach 操作,在使用 HDFS 作为存储时,将 Part 移动到一个 Detach 目录下,也是依赖 Rename 操作。在支持对象存储存储时,存储部分只对存储对象的路径有部分修改,实际的文件格式还是保持和HDFS相同。
Catalog
在使用 HDFS 作为 ByConity的存储时,一个 Part Detach 之后,Catalog 里将不再记录和此 Part 相关的任何元信息。如果需要找到这些 DetachPart,可直接在 HDFS Detach 目录下 list 相关信息。在使用对象存储时,由于前文介绍的存储路径上的改动,无法再利用List接口获取到某张表的所有 Part,因此 Catalog 里额外维护了一批 DetachPartMeta,如果想要知道表有哪些 DetachPartMeta,可以直接在 Catalog 里扫描对应前缀的 key。
Transaction
为了支持 Attach 或者 Detach 操作的原子性,ByConity 在支持对象存储时新增 AttachMetaAction、DetachMetaAction、AttachMetaFileAction 等事务的 Action。
ByConity 支持对象存储的实现
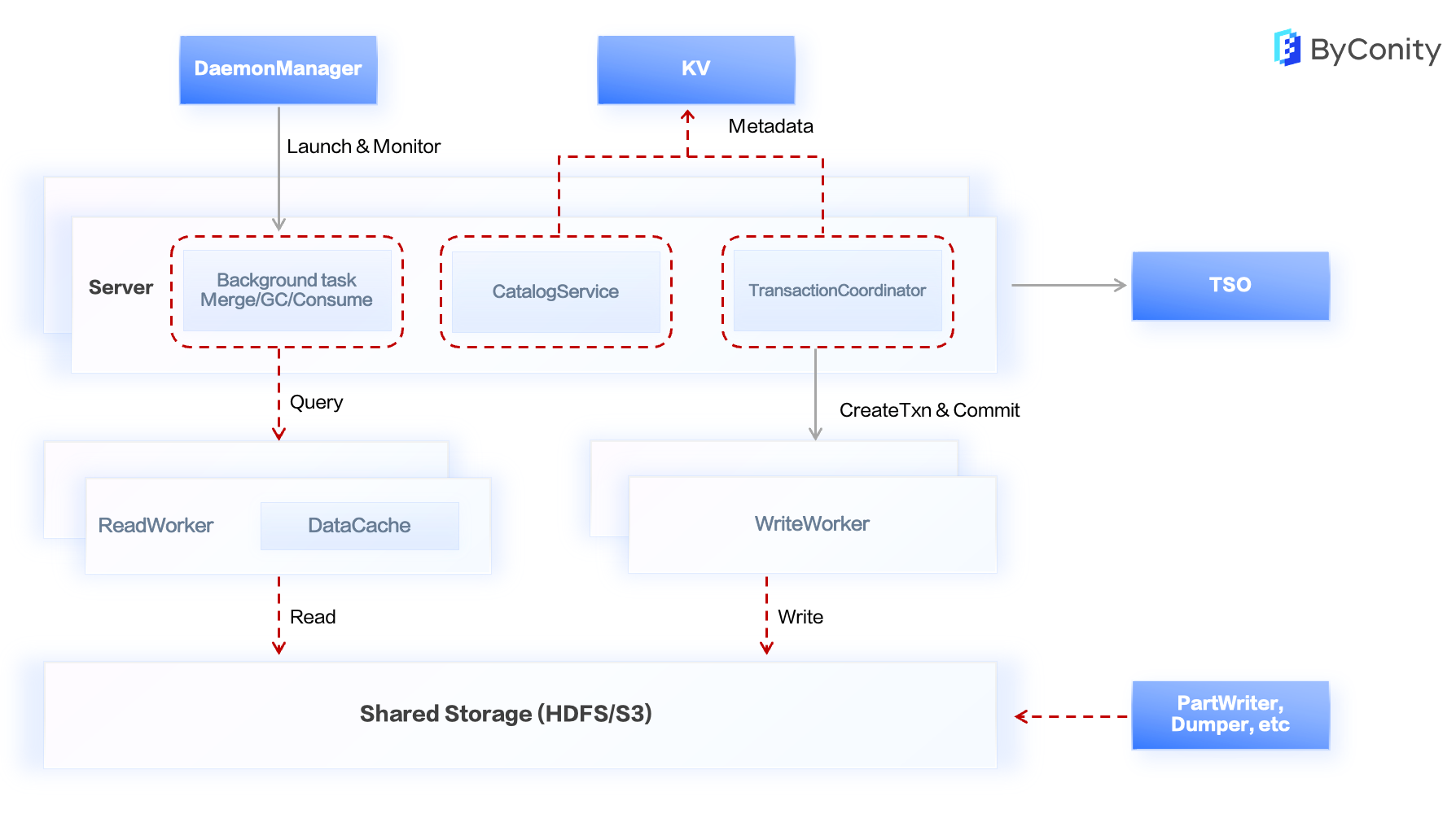
上图中标红的部分展示了 ByConity 为支持对象存储所做的修改。CatalogService 和 TransactionCoordinator 在上文中已提到,其他的一些进行的修改包括:
后台任务, 像GC这些后台任务在支持的对象存储过程中也进行了一些修改。在 HDFS 的表 GC 过程中,只需要在 HDFS 上把目录直接删掉即可。在对象存储上,所有表的数据都以相同前缀的Key来进行存储,同时Key中不包含表相关的信息。在做表的 GC 时,需要去 Catalog 中找到所有的 Part,并找到对应的 Objectkey,再进行删除。由于对象存储也支持 BatchDelete 的接口,所以也利用 Batch 接口及一些并发手段对大表的 GC 做了一些优化。
PartWriter 等周边工具 , 在数据导入的过程中,PartWriter 会将生成好的 part 写到一个 HDFS 路径中,引擎依赖 Attach 将数据 Rename 到目标表,再把 Meta 写到Catalog中,part 就可见了。使用对象存储作为存储时,PartWriter 会随机生成一个 PartID,并将生成的 Part 文件按照引擎使用的 ObjectKey 的格式写到对应的对象存储对象中。此时需要一个方式来找到 PartWriter 到底生成了哪些 Part,所以对 PartWriter 也做了一些修改。让 PartWriter 在运行过程中会生成一些额外 Task 的 Meta 文件,并依赖这些 Meta 文件来知道这些 PartWriter 到底写了哪些 Object。
ByConity 支持对象存储的 IO 流程
读取数据分为两步,第一步是构造 MergeTreeReaderCNCH,第二步用 ReaderCNCH 读取数据,ByConity 在支持对象存储的时候对 IO 流程上也做了一些修改。
-
构造 MergeTreeReaderCNCH
-
首先遍历所有需要读取的列,构造 ReaderStream。
- 在构造 ReaderStream 时,利用 part 的 disk 来构造对应读取数据的 ReaderBuffer。这里实现了一个新的 DiskByteS3 的类型。DiskByteS3 类型和 ClickHouse 的 DISK S3 有一些差别。ClickHouse 的 DISK S3 会利用本地磁盘来存储一些本地数据文件到对象存储对象的映射。在 ByConity 里,因为不依赖本地磁盘来存储数据,因此这里实现了一个新的 Disk类型。
- 在需要读取数据构造 ReaderBuffer 时,DiskByteS3 构造 RAReaderBufferForm3 来进行数据的读取。
-
根据需要读取的列和数据范围更新 DiskCache 统计信息,根据 DiskCache 策略决定是否需要在后台异步地 Cache 数据。
-
-
利用 ReaderCNCH 读取数据
- 需要 seek 的情况下,先利用 Mark 的信息 seek 到某个特定的位置,如不需要 Seek 则接着上次的位置接着读;
- 上层利用在构造 ReaderCNCH 时候构造好的 ReaderStream 的 data_buffer,根据对应列的序列化方式来去反序列化数据。
ByConity 支持对象存储的写入流程
-
将内存里的这些数据 Dump 到本地磁盘。 上层传过来的一个 block 会按照一些分区先进行一次 split,将这些临时的 Part 先写到本地的磁盘上。
-
生成 Part 的 ObjectKey
- ByConity将数据存储到对象存储的过程中会把所有数据以相同前缀来存放,因此需要为每个 Part 生成一个独立的 PartID,如果是引擎写入的 Part,会根据 PartName 进行哈希操作,来生成一个 PartID,因为 PartName 中有包含 minmax block 及 mutation 的信息,可以保证 PartName 在引擎中是唯一的。
- 周边的工具依赖用户传入一个唯一的 TaskID,在 TaskID 传入之后,会为任务生成的所有 Part 随机地生成一个 PartID,也会用用户传入的 TaskID 来拼接出一个 ObjectKey 用于保存和PartWriter任务相关的 TaskMeta。因为周边工具写入时所有 PartID 都是随机生成的,假如有碰撞的情况,可以依赖 TaskID 来做数据回滚。
-
把本地磁盘的对象去写入到对象存储上。
- 数据在写入对象存储时会在对象存储 Object 的 Metadata 上添加生成者 ID,如果是引擎写入,此 ID 即为事务 ID,如果是周边工具写入,此 ID 则为用户传入的 TaskID。通过在对象存储 ObjectMetadata 上添加生成者 ID,当存在写入冲突时,可以通过检查 ObjectMetadata 来确定对象是否由自己生成进而确定是否应该在回滚时删除。
- 举例来说,如果周边工具随机生成了一个 PartID,写入时发现对象存储上已有一个对象,在清理这个对象前我们需要确定对象存储上的对象由此次周边工具生成还是由引擎生成。这时需要检查 ObjectMetadata 的生成者 ID,只有相符的情况下才能确认是周边工具生成,避免误删除掉实际有用的数据。
ByConity 支持对象存储的 Attach/Detach
HDFS 的 Attach/Detach
HDFS 是文件系统,存在目录抽象,也支持 Rename 操作。在使用 HDFS 时候,数据的存储路径为root_prefix/{table_uuid}/{part_name}/data。在做 AttachFromTable 和 AttachFromPath 操作时引擎会直接扫描源路径,从 Path 里扫描出所有的 Part。找到符合条件的 Part 之后,将其 Rename 到目标表的目录中,并向 Catalog 写入Meta。HDFS上的Detach 也依赖 Rename 操作,包括将符合条件的 Part Rename 到 Detach 目录,再向 Catalog 里写入 DropRange,后台的 GC 线程将清理已经被 Detach 的 PartMeta。
对象存储的 Attach/Detach
因为 copy & delete 代价较高,ByConity 为每个 Part 分配了全局唯一的 PartID,数据在写入之后就不会再做Rename和拷贝的操作了。如果需要执行AttachFromTable的操作,则直接扫描表在 Catalog 中的 AttachPartMeta,收集所有符合条件的 PartMeta,通过事务操作将源表的 DetachPartMeta 移除,写到目标表的 PartMeta。
如果需要Attach一批PartWriter写入的数据,引擎会先根据传入的 TaskID 找到对象存储记录 Task Meta 的对象,读取得到 PartName 和 PartID 的映射关系。根据映射关系找到符合条件和可见的 Part,并写到目标表的 Catalog,此时Part可见。 Attach 成功后,会由事务负责删除 TaskMeta 的对象。
Detach 操作也不会有数据的 Rename,引擎会通过扫描 Catalog,将可见的 PartMeta 重写为 DetachPartMeta,数据依然留在原处,下次 Attach 时可直接读 Catalog 找到。
三、访问对象存储的性能优化
HDFS 和对象存储读取首字节的延迟,两者差距较大。因此 ByConity 针对对象存储的存储特性和访问模型做了针对性的优化。
IOScheduler
读取本地磁盘时,内核支持很多可配置的 Scheduler,会由 IOScheduler 进行 IO 请求的合并和去重,减少 IO 的次数并减少冗余的 IO。
读取 HDFS 和 对象存储远程存储时则没有此机制。因此带来一些问题:
-
有冗余的 IO,导致带宽浪费。如果两个查询同一时间执行,读一模一样的数据,在没有去重的情况下,会造成一个文件读两次。
-
IO请求数量多,在慢 IORequest 比例一定的情况下,IO 请求数量越多,查询受慢 IO 影响的可能性越大。假设有两个 IO 请求,一个读 0-1 byte,一个读 1-2 byte,虽然读数据很少且相邻,但实际还是向远端的两个 IO 请求。
- IO 请求数量多会带来一个什么问题?
- 由于 HDFS 和 对象存储都是远程存储,不可避免会有一些比较慢的 IO 请求。在 慢 IO 比例一定的情况下,IO 请求数量越多,查询受慢 IO 影响的可能性就越大。如果一个查询只有一个 IO,慢查询比例是 1%,查询遇到慢 IO 的概率则较小。但如果一个查询有 1 万次 IO,遇到慢 IO 的概率则非常大。
-
ByConity 在访问 对象存储时实现了 ReadAhead 机制,部分场景下可能有比较大的 IO 请求出现。
-
在数据没有 Prefetch 的情况下,计算和 IO 没有并行起来。在 ByConity 目前的执行模式中,还是先做一次 IO,读出来一部分数据,拿到上层做计算,再读下一部分数据。其实在上层做计算的过程中,可以先将一些数据 Prefetch 到内存中。

上图是目前 IOScheduler 已经实现的几个策略。右边是以 deadline Scheduler 做的一个实例,上层的查询的线程,会根据一些策略(如要访问的文件路径,或者根据一些随机的分配)将查询线程的 IO 请求分配到不同的 Scheduler 中。IOScheduler 的内部会对请求分配 Deadline,避免单个请求一直得不到执行。
另外也会对请求根据要读的文件路径,以及 Offset 做排序,将相邻的 IO 请求做合并。后台有很多个 IO Worker 不停地从不同的 IOScheduler 中每次取一批 IO 请求来执行。
目前支持功能如下:
-
将有重叠范围的数据请求合并成一个大的 IO 请求。如服务器托管网两个相邻的,一个读 0-1 兆,一个读 1- 2 兆,如果没有超过最大 IO 请求的限制,可以将它合并成一次 IO;
-
将所有 IO 请求对齐到某个可配置的边界上,让临近的请求(即使不相邻)也可以合并成一个;
-
对于过大的 IO 请求支持将其切分为多个请求并行执行。比方说 128 兆请求,可以将它切分成小一点,让不同的线程并发地做 lO;
-
对有重叠的请求进行去重来减少实际 IO 的次数和流量;
-
请求提交后支持设置 Deadline,避免请求被饿死;
-
基于一定的策略进行数据的 Prefetch,让数据在实际读取前就绪;
a. 基于 Offset,每次 IO 结束后后台触发 Offset 相邻的数据的请求的执行
比如上次读 0- 1 兆,那就假设他下次就读 1- 2 兆,每次 IO 结束之后,就在后台触发触发新的 IO 的任务,再去后台执行先 Prefetch 回来之后先放到内存中。
b. 基于 MarkRange,利用 MarkRange 计算下一个可能请求的数据范围并进行 Prefetch
在 ReaderCNCH 中,会通过索引、filter 等方式过滤得到查询需要的 MarkRange,利用这些 MarkRange 可以计算出需要查询的数据在文件中的 IO Range,从而可以提前根据该范围进行 Prefetch。
MemoryCache
MemoryCache 主要针对 DiskCache 已有的一些时效性差的问题:
- 数据访问需要符合 Cache 策略后才会在后台异步 Cache 到本地;
- 数据 Cache 本地后依赖操作系统的 PageCache 将数据 Cache 到内存中
因此,一个冷读数据可能得读好几次才能符合 Cache 策略,进而才能将它 Cache 到硬盘,之后再读并加载配置到 Cache 内存中,这样读后续的 IO 请求才可以从内存里取出此数据。
MemoryCache 将 IO 请求对齐到一定边界上,在读取远端时同步的将数据 Cache 到内存;在使用内存进行 Cache 的过程中,除 Cache 外还有一些计算任务也会使用内存。为了避免影响计算时对内存的使用,通过一个额外的模块监控内存消耗,在内存水位高后主动触发 MemoryCache 清理。
数据范围感知
在传统的查询中,ReadBuffer 负责打开文件并 Seek 到指定位置进行读取。但是,此时 ReadBuffer 只知道数据在文件中的起始位置,而不知道数据要读取到什么位置。在本地文件系统和 HDFS 中,这种逻辑是可行的。但是,在 对象存储里,每次数据读取都需要一次 Http 请求,如果 ReadBuffer 无法提前知道数据读取的范围,它只能尝试发送多次 Http 请求。这不仅会导致性能变差,也会带来对象存储使用成本上的问题。
因此,我们提前根据查询所需的 Mark Range 对数据文件中起始位置的 offset 和结束位置的 offset 进行计算,并将这两个 offset 都传递给 ReadBuffer。此时 ReadBuffer 可以只进行一次 http 请求,请求所有我们需要的数据。(对应下图的左下角)
但是,如果请求的数据范围过大,可能会带来内存上的问题。为了解决这一问题,我们采用了 Poco 的 HttpClient,它不会一次返回所有数据,而是返回一个流式的 Stream,可以让使用者从中按需进行读取。从而,我们可以实现仅发送一次 Http 请求,并从中多次读取。
当所有数据读取完毕后,这一次 Http 请求使用的 Session 可以被复用,省去了下一次 Http 建连的开销,进一步提升了访问对象存储的速度。 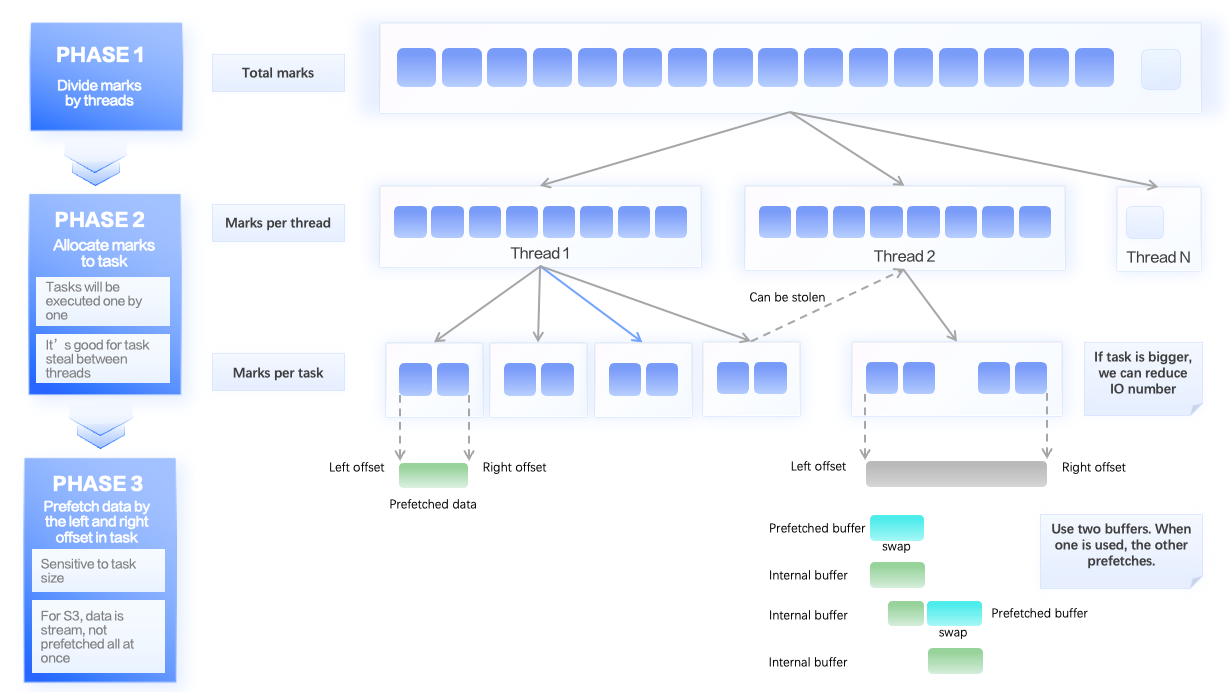
Double Buffer Prefetch
虽然我们成功减少了 HTTP 请求的次数,但每次使用数据时仍需同步等待从 Stream 中读取数据,这种读取方式的效率仍然较低。为了加速对象存储的数据读取速度,我们引入了 Prefetch 机制,用于异步从 Stream 中拉取数据,从而确保计算侧不必同步等待数据读取。
然而,Prefetch 不能无限制地进行,否则会导致 CPU 处理速度跟不上,大量的 prefetch 数据堆积,白白浪费内存资源。针对这一问题,我们采用了双 buffer 的 Prefetch 机制。其中一个 buffer 作为 internal_buffer 供查询上层计算使用,另一个 buffer 作为 prefetch_buffer 用于后台异步拉取下一批数据。每当 internal_buffer 耗尽时,它都会与prefetch_buffer 进行交换,实现后台异步读取和前台计算的无缝衔接。完成交换后,prefetch_buffer 会继续拉取下一批数据,避免同步等待和资源浪费。(对应上图的右下角)
通过预先设定 Range 减少 HTTP 请求次数,查询 Session 复用,以及 Prefetch 机制,我们实现了 40% 的性能提升。但是,这其中依然存在可优化的部分。一次查询中,所有需要查询的 Mark 会平均划分到各个线程。在各个线程内部,又会被平均划分为更细粒度的 Read Task,每个 Read Task 都包含一定数量的 Mark Range。这种细粒度的划分可以方便查询线程之间互相 Steal Work,避免由于某个线程过慢引发的长尾问题。
也就是说,Read Task 是查询执行的最小单位。我们会为每个 Read Task 计算一次数据文件的起始位置和结束位置,并发送一个对象存储 Http 请求。如果 Read Task 过小,就会导致对象存储 Http 请求次数增多。在未经优化前,每个 Read Task 包含固定大小的 20 个 Mark,这对于本地文件系统没有问题,但是对于对象存储而言显然过小。
Adaptive read task
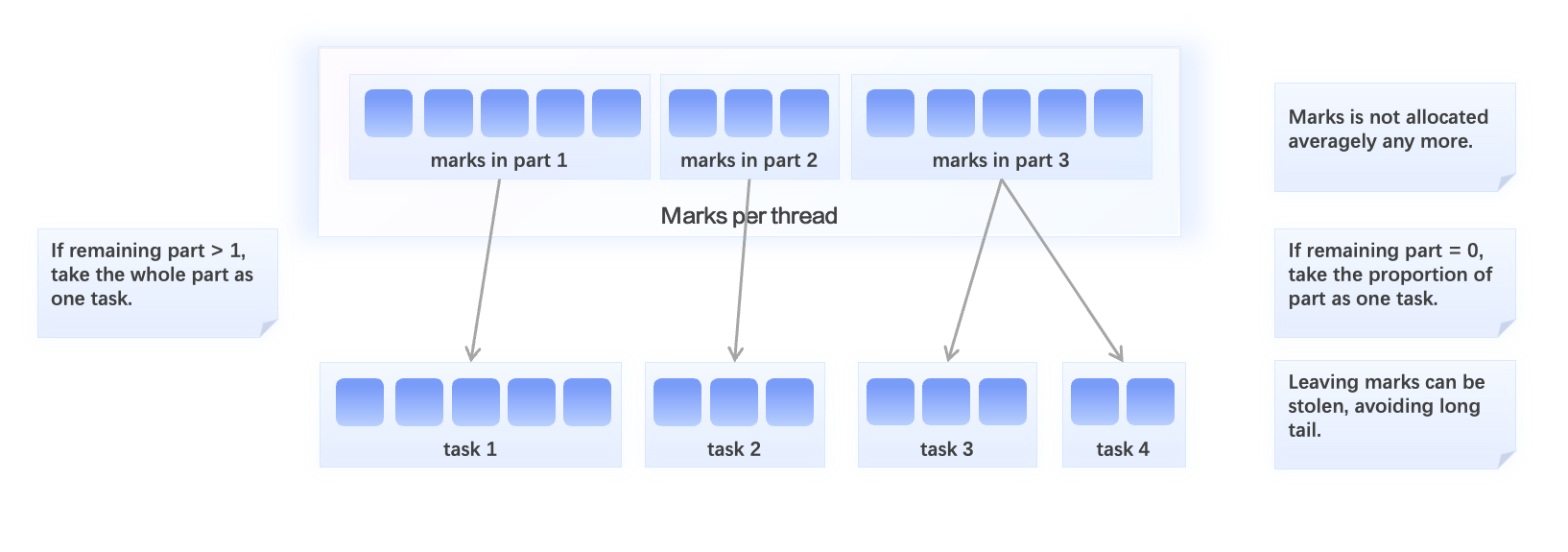
为了解决这一问题,我们进行了自适应大小的 Read Task 优化,每个 thread 下的 Task 不再采取平均分配的策略。
由于每个 Http 请求最多选择一个文件,多个文件的 Http 请求无法共享。而查询线程的任务队列中往往包含多个数据 Part,对应对象存储上多个不同的文件。因此,我们考虑以 Part 为单位对查询任务进行切分,每个 Part 作为一个 Read Task,从而最小化 Http 请求数量。但是,对于某个查询任务中只包含一个大 Part 的情况,这种划分方式会导致多个 Worker 线程之间无法进行 Work Steal 操作,从而导致部分线程出现长尾的问题。
因此,我们采取以下策略进行划分。如果线程的任务队列中剩余的 Part 数大于等于 1,意味着有剩余的任务可以被其余线程 Steal,此时我们考虑以 Part 为单位对 Read Task 进行划分,Part 文件的大小决定了这一 Read Task 的大小。如果线程的任务队列中没有剩余的 Part,此时我们考虑将该 Part 进行进一步拆分,取其中一定比例的 Mark Range 作为一个 Read Task,剩余的 Mark Range 可以作为单独的 Task 被其余线程 Steal。如果 Part 过小,即包含的 Mark Range 过少,我们则会避免此次拆分。
通过这一自适应优化,对比固定大小的 Read Task 实现了接近一倍的性能增长。
单个文件写入性能优化
CNCH 写入流程是先将内存中的数据 Dump 到本地,另外是将本地磁盘中的数据合并成最终文件,添加 Footer 或者 Header,再写入远端的存储。对象存储因为支持 MultiPartUpload,可以在本地将数据按照一定边界进行切分,并发地将其写到远端,这样对于一些比较大的 Part,其写入性能会更好。
四、配置与使用
以下将以 S3 为例,简要介绍 ByConity 如何配置和使用对象存储,以及如何在一套系统中同时使用 HDFS 和 对象存储。
配置
- S3Disk:在 storage_configuration 下将支持一个新的 Disk 类型——ByteS3。它有一些配置项,包括 tab、region、bucket、ak_id 和 ak_secret 等。
- StoragePolicy:需要设置一个新的 StoragePolicy,包含刚配置好的 S3Disk。

使用
配置集群默认使用 S3 作为存储 。 ByConity 的一个 Sensor 是 default policy 的配置项,可以直接向其设置成 S3 的 StoragePolicy,让整个集群都默认使用 S3 存储,当然也可以用 HDFS 作为默认存储。
利用建表参数指定某张表使用存储类型。 建表时可设置 StoragePolicy,利用 setting 指定某张表使用 S3,其他表使用 HDFS。
demo 演示可在ByConity 公众号查看。
五、最新进展
在 ByConity 0.2.0 中,我们通过引入 IOScheduler 等方式提高了冷读查询的性能,尤其是在 S3 上的冷读性能。0.3.0 版本通过引入 ReadBuffer 的 Preload 等优化,进一步提高了冷读性能。通过 Prefetch 和自适应 mark per task 等优化策略,可以将 S3 冷读性能提升一倍以上,HDFS 冷读性能提升 20% 左右。
下载体验:https://github.com/ByConity/ByConity/releases/tag/0.3.0
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
