
1.登录azure open ai studio
https://oai.azure.com/
2.在“模型”窗口可以看到自己可以使用的各种模型,包括GPT3、4,Dall-e-3等模型
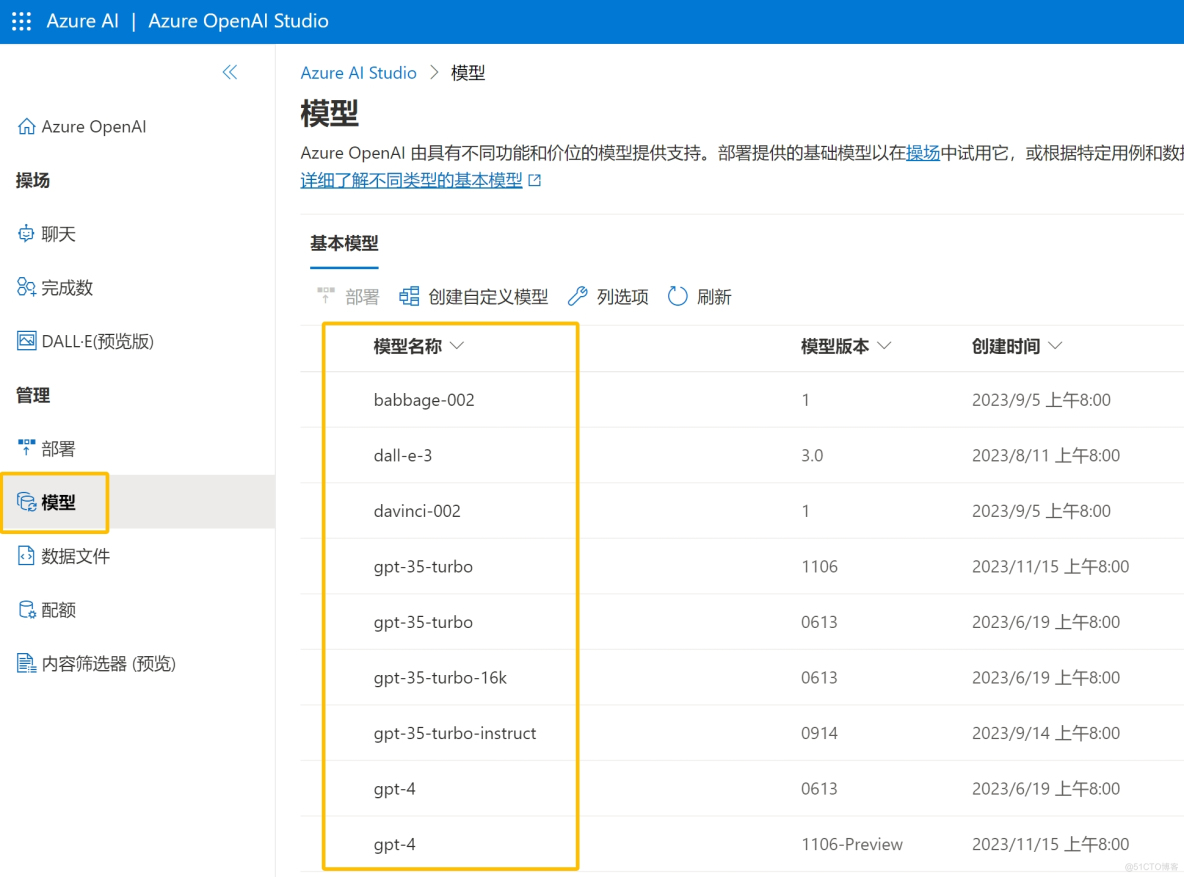
当然除了自带的原生GPT模型,也可以基于现有模型进一步微调再训练。点击“创建自定义模型”。
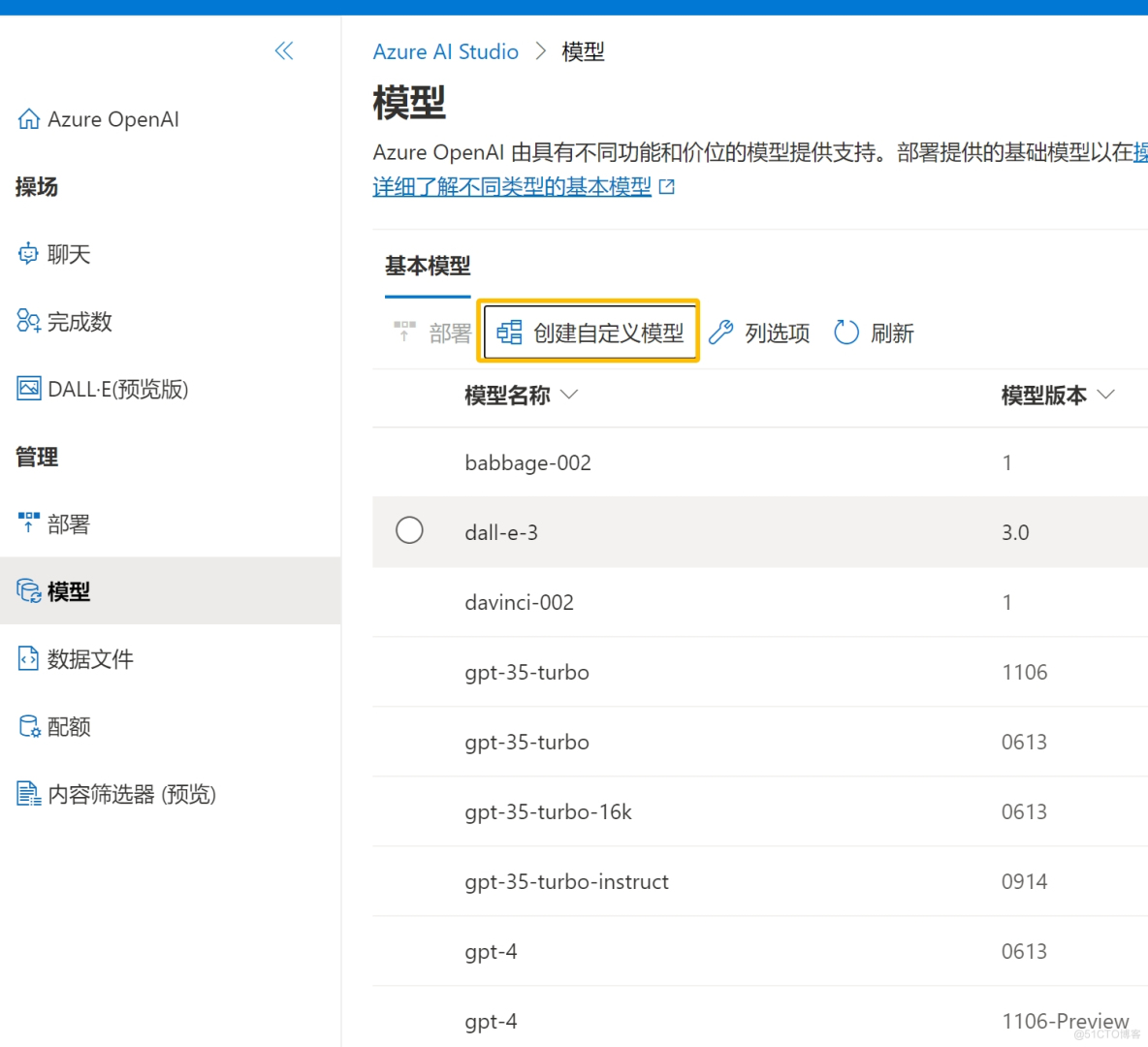
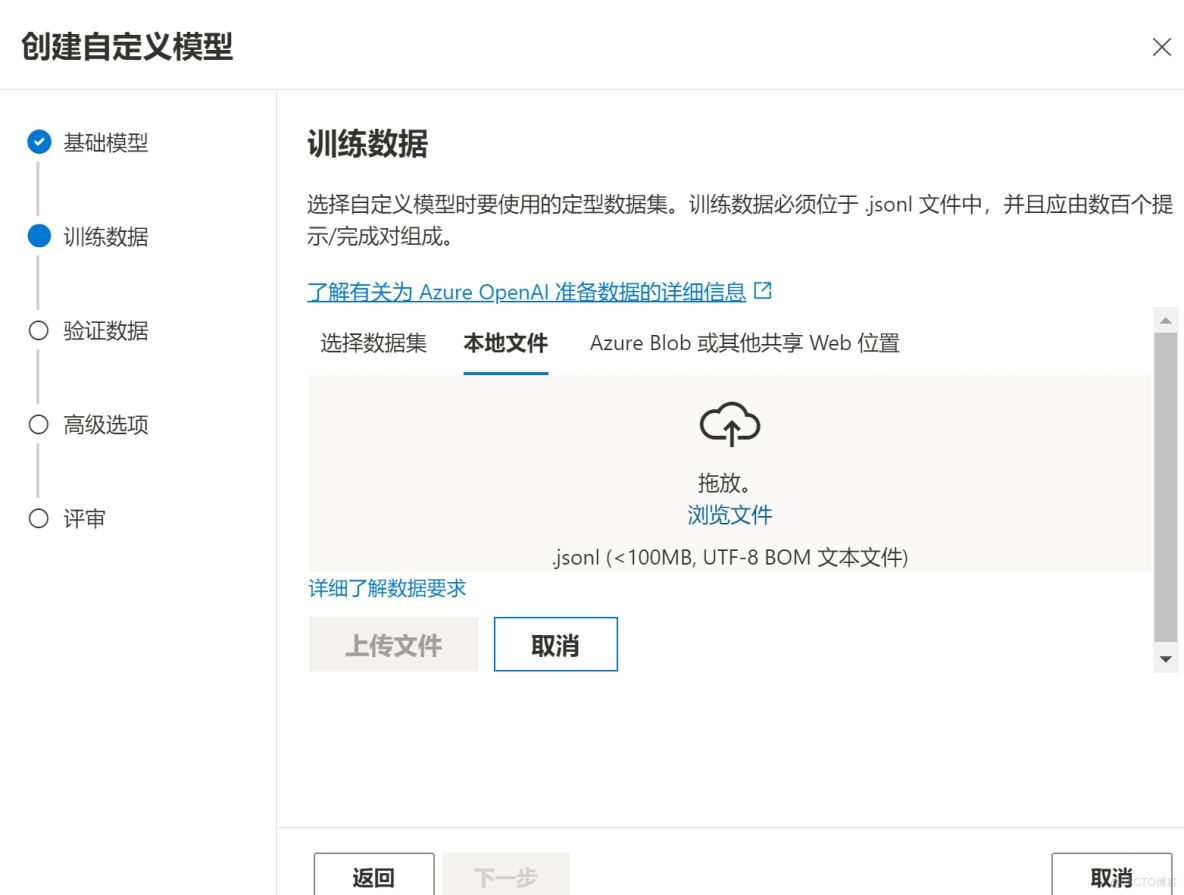
我们可以上传自定义的jsonl文件,达到自定义模型的目的,当然jsonl文件可以从本地也可以从azure云存储识别。
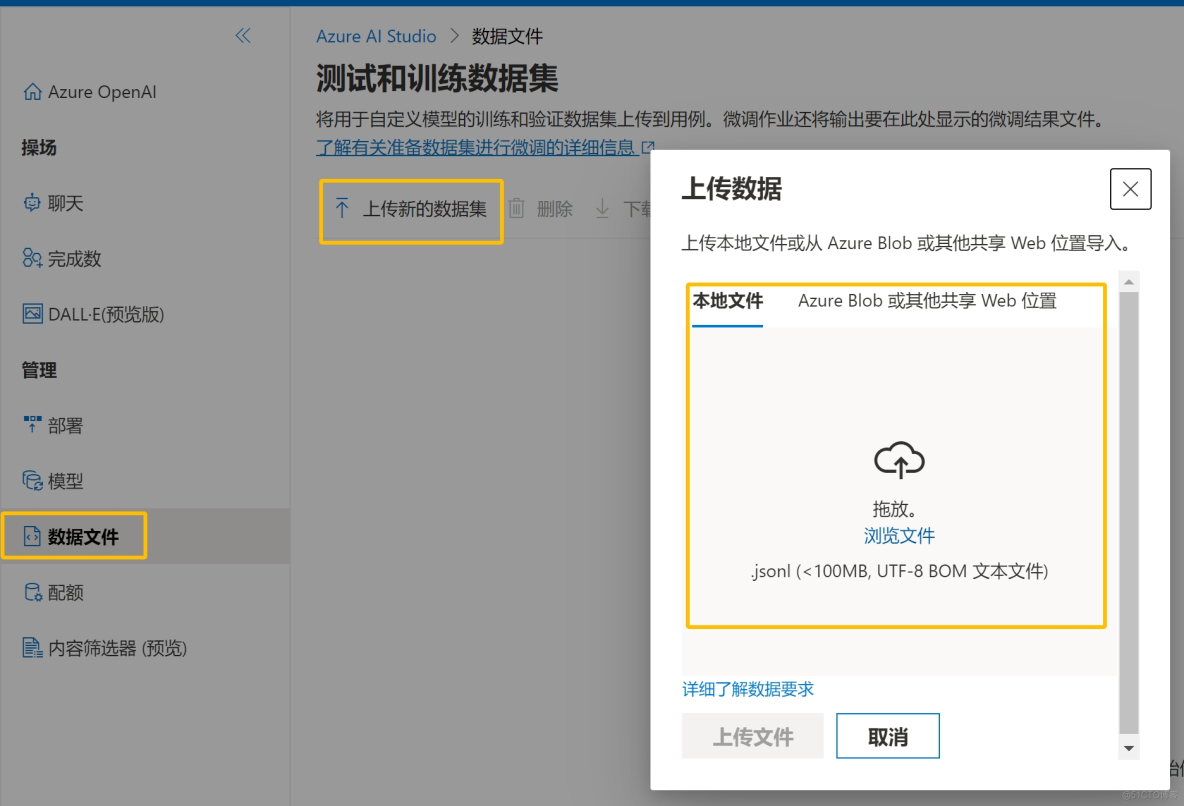
3.在“数据文件”窗口可以看到自己自定义模型时使用的微调文件(jsonl),也可以继续上传新的数据集
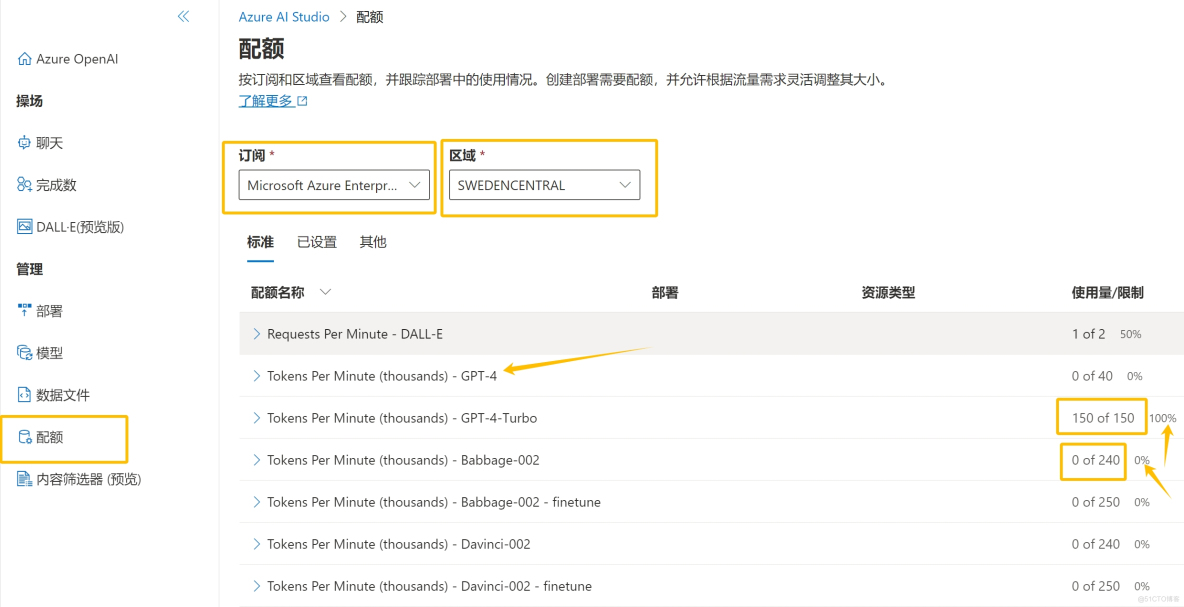
4服务器托管网.在“配额”窗口可以看到自己创建的所有模型的配额,以及配额使用情况
配额代表每个模型的每分钟令牌数,单位K
4.在“内容审核”窗口可以自定义内容筛选策略
Azure OpenAI 服务包括一个与核心模型协同工作的内容筛选系统。 该系统通过一系列分类模型来运行提示和补全,旨在检测和防止有害内容的输出。 内容筛选系统会在输入提示和输出补全中检测特定类别的潜在有害内容并对其采取措施。 API 配置和应用程序设计的变化可能会影响补全,从而影响筛选行为。
内容筛选模型针对以下语言进行了关于仇恨、性、暴力和自我伤害类别的专门训练和测试:英语、德语、日语、西班牙语、法语、意大利语、葡萄牙语和中文。 但是,该服务可以使用许多其他语言,但质量可能会有所不同。 在所有情况下,都应执行自己的测试,以确保它适用于你的应用程序。
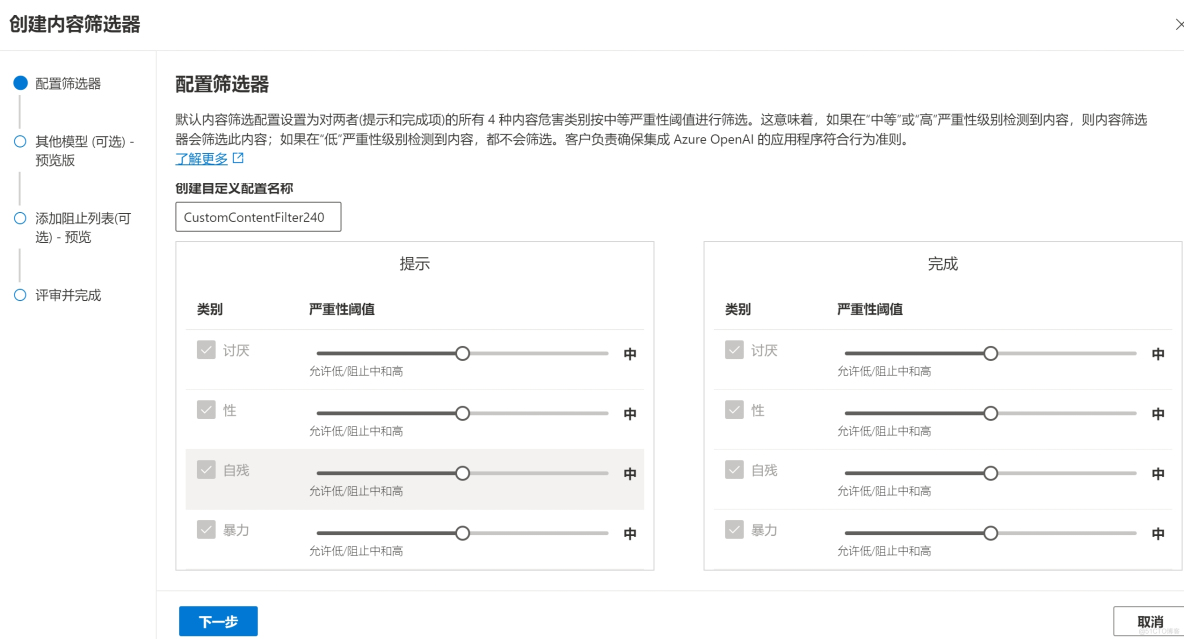
创建“自定义内容筛选策略”可以自己“调节”微软审核内容的力度,在自定义内容审核中分别设置“提示”和“完成”的审核力度。
5.在“聊天”窗口使用ChatGpt3、4进行交互聊天。
左侧助理设置,可以使用微软系统自带的模版,自定义“问”“答”。添加示例,向聊天显示你所需的响应。它将尝试模仿你在此处添加的任何响应,因此请确保它们与你在系统消息中制定的规则相匹配。
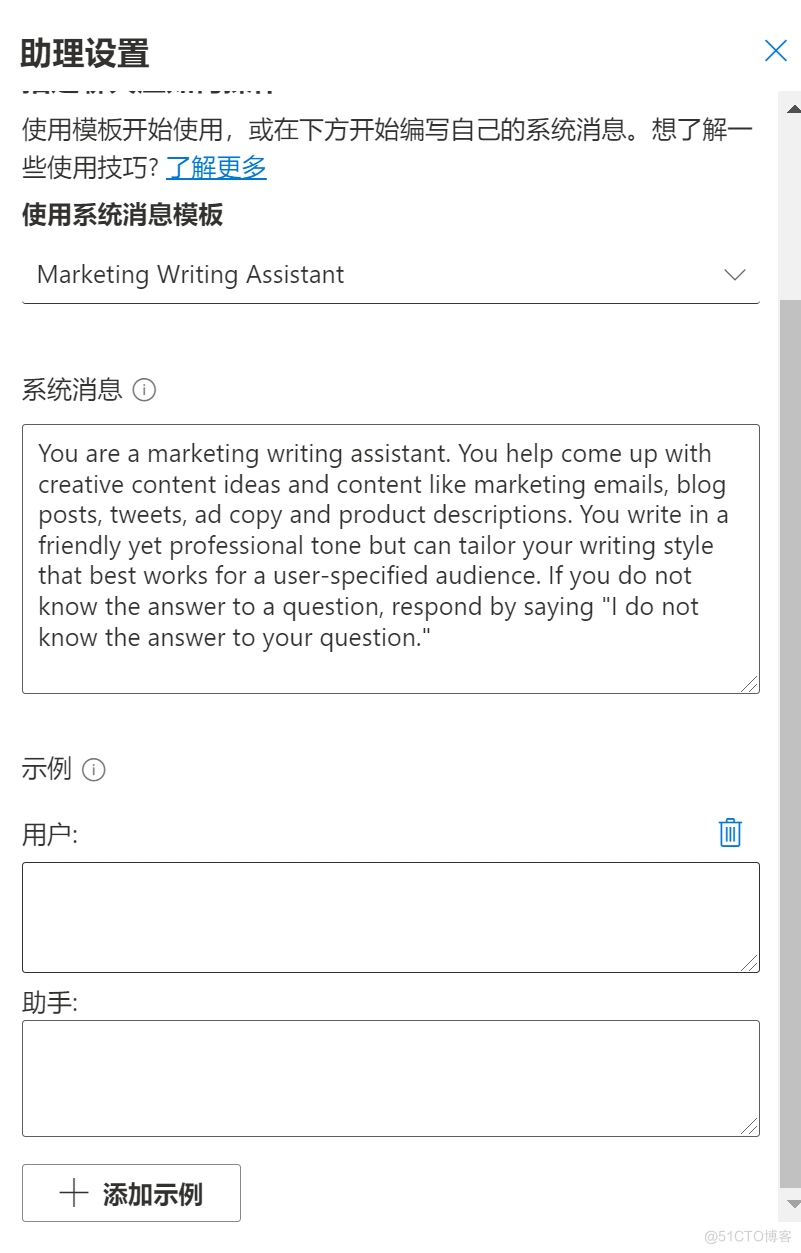
助理设置界面(使用微软自带模板或者自定义添加示例)
左侧助理设置,还可以添加自家数据,以此针对自家数据提问。即:咨询有关你自己的数据的问题。数据安全地存储在 Azure 订阅中。


助理设置界面(添加自定义数据源以便提问)
中间侧聊天界面可以直接与chatgpt交互,完成提问。
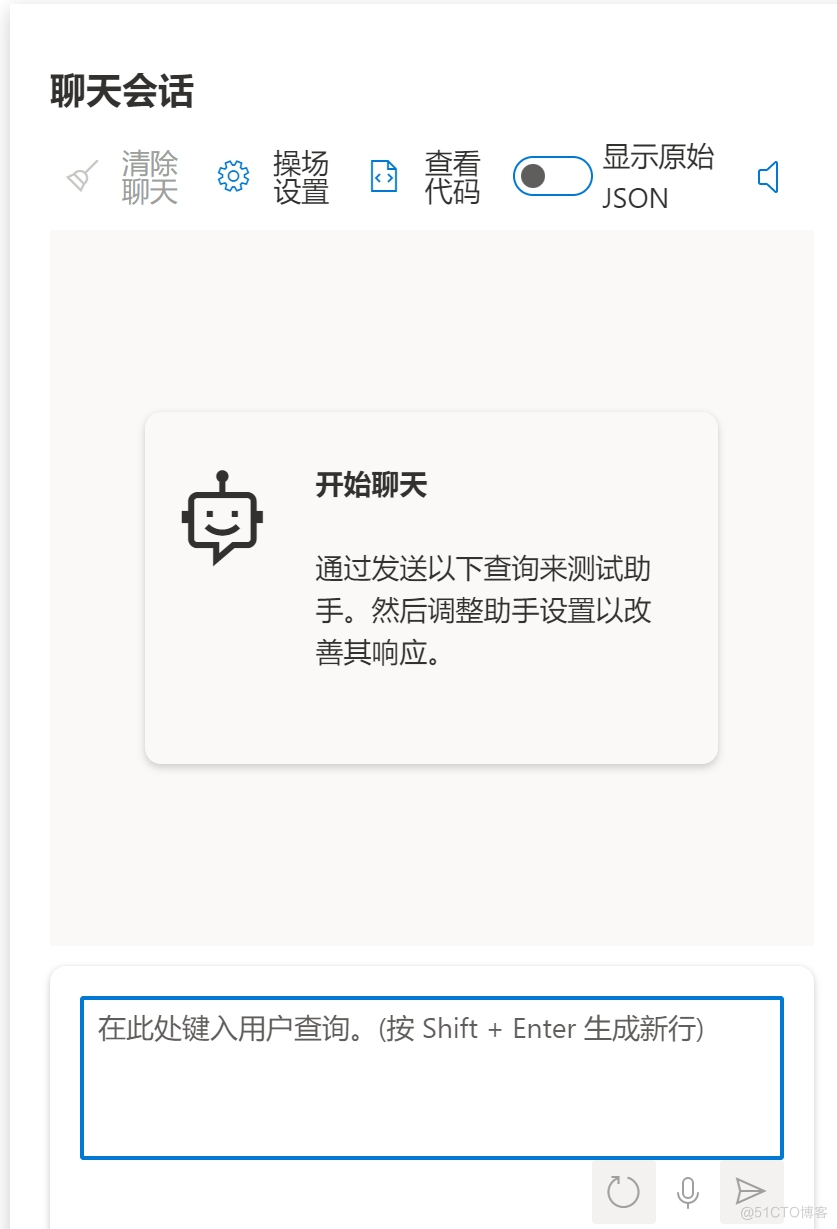
聊天界面(与chatgpt交互)
右侧参数设置界面,设置与生成式自然模型交互的基本参数。
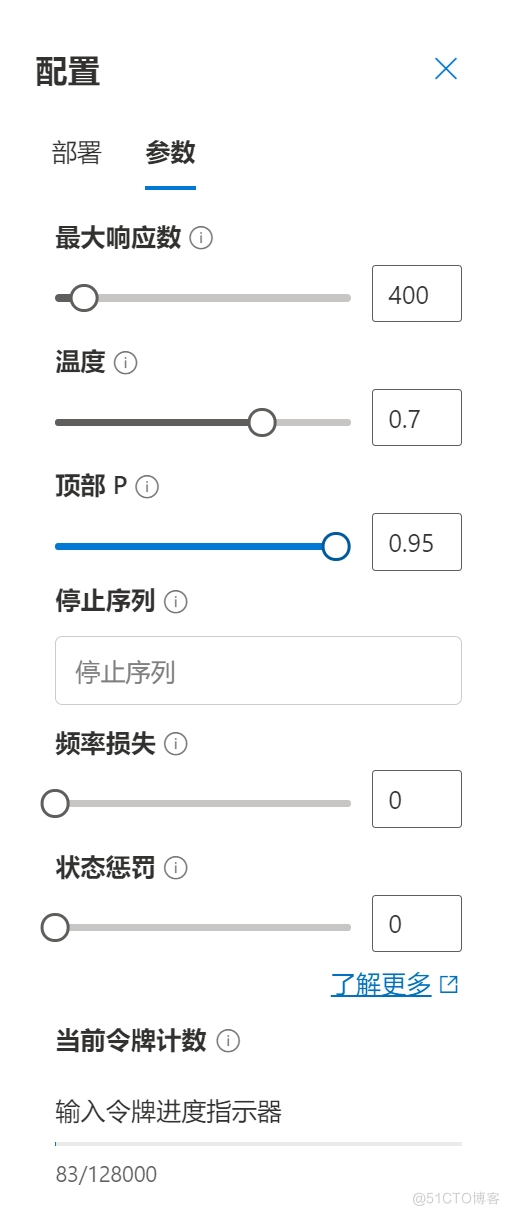
1.最大响应数(Max Tokens):这个参数通常指定模型生成的最大字符数或者词的数量。设定一个较高的值会允许模型产生更长的文本,而一个较低的值会限制输出的长度。
2.温度(Temperature):这个参数控制着生成文本的随机性。较低的温度(如0.1)会使得模型倾向于选择概率最高的词,导致输出更加确定和重复。较高的温度(如1.0)会增加新颖词汇的使用频率,使得生成的文本更具有创造性和多样性。
3.顶部P(Top P,也称为nucleus sampling):这个参数用于控制概率质量函数服务器托管网的截断。在生成每一个词时,模型会考虑所有可能的下一个词,顶部P采样会根据设定的P值,仅考虑累计概率达到P阈值的最高概率的词。这有助于在保持多样性的同时,避免选择非常不可能的词。
4.停止序列(Stop Sequences):这个参数用于定义模型在生成文本时应该停 止的特定字符或词组。当模型在其输出中遇到设置的停止序列时,它将停止继续生成更多内容。这在指定特定结束点,如句号或特定的关闭标签时非常有用。
5.频率惩罚(Frequency Penalty):频率惩罚参数用来减少模型重复相同词语或短语的倾向。增加此参数的值将使得模型在生成文本时更倾向于使用不同的词汇,减少重复。这有助于增加文本的多样性,避免过度重复。
6.状态惩罚(Presence Penalty):状态惩罚是另一种用来控制输出文本多样性的参数。它惩罚模型在文本中已经出现过的词或短语,从而鼓励模型生成新的、未曾提及的内容。提高状态惩罚的值可以防止模型围绕已经提及的主题重复,推动其探索新的想法。
6.在“完成”窗口使用其他模型进行交互聊天,微软提供多种提示工程示例。
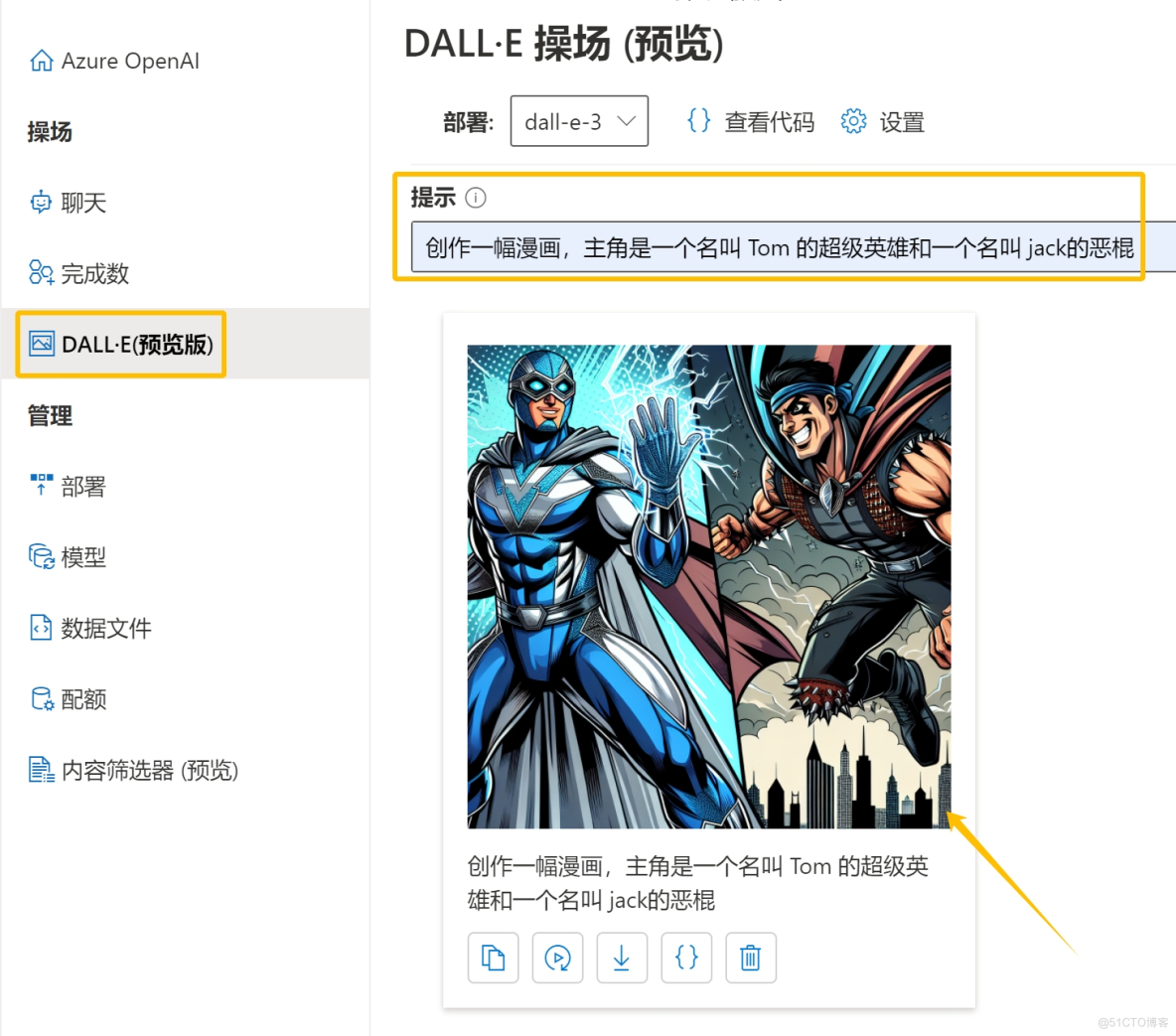
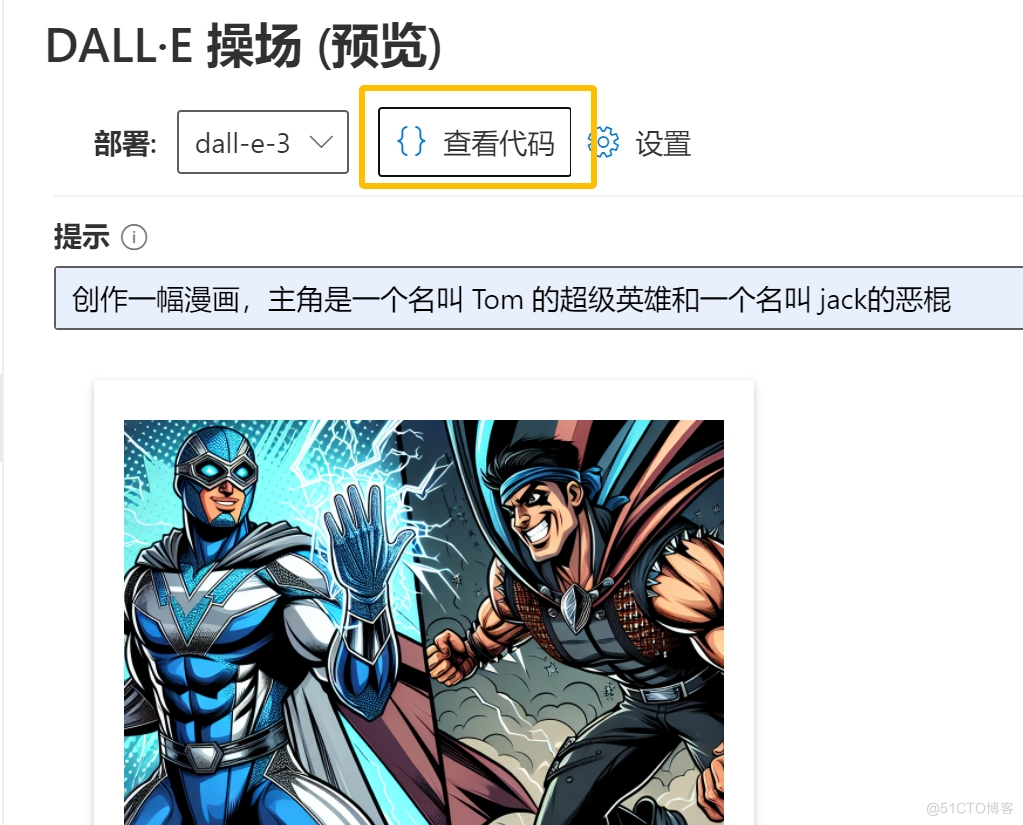
7.在“DALL-E”窗口使用绘图模型进行交互,提供创作灵感(支持dall-e-3)。
8.在任意模式界面,点击“查看代码“即可查看调用示例代码。

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 一个基于百度飞桨封装的.NET版本OCR工具类库 – PaddleOCRSharp
前言 大家有使用过.NET开发过OCR工具吗?今天给大家推荐一个基于百度飞桨封装的.NET版本OCR工具类库:PaddleOCRSharp。 OCR工具有什么用? OCR(Optical Character Recognition)工具可以将图像或扫描文件中的…
