
发布于我的博客,也许同步更新于博客园
引入
跳表(跳跃表)能够维护一个数的集合(作用类似普通平衡树),查找时间复杂度为 (log n),与平衡树一样基于链表结构。由于不需要平衡树那么多旋转什么的,所以效率比较高,一般认为性能能打红黑树。除此以外,链表的特性使它能够以线性时间遍历某个子段。Redis 的有序集合就是用跳表实现的。
更简单来说,跳表是一个支持 (Theta(log n)) 时间随机访问的链表
定义
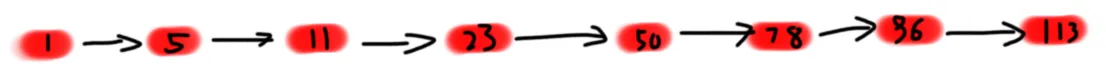
上面这个东西叫链表。
我们知道,链表只支持线性时间访问,所以不能二分。我们如果想维护一个有序序列的话,虽然插入删除很快,但是找到一个值对应的位置很慢。
我们又知道,链表的访问形式实际上是一个一个遍历,而它有 (n) 个元素,这是它 (Theta(n)) 复杂度随机访问的根源所在。
那我们是不是可以给链表精简一下呢?比如说,我给链表多加几层,每层减少一半的元素,像这样:
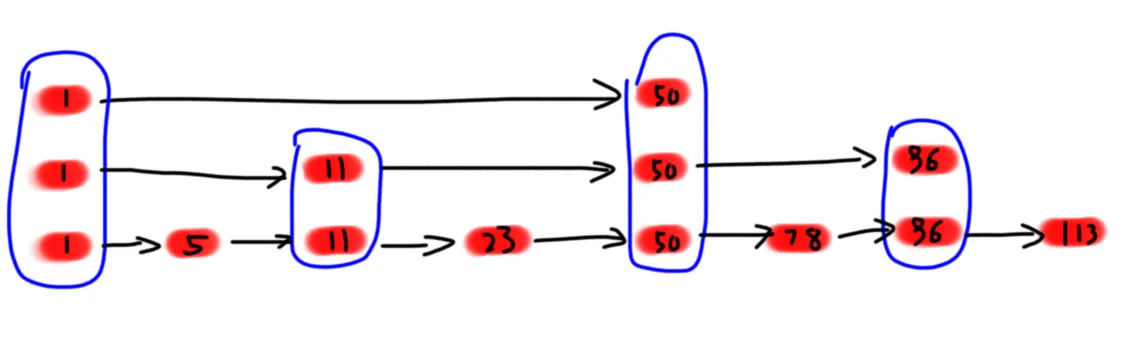
(蓝色方框括起来的是一个节点,实现的时候我们不需要把上面几层显式地建出来,只需要创建对应层的指针即可。)
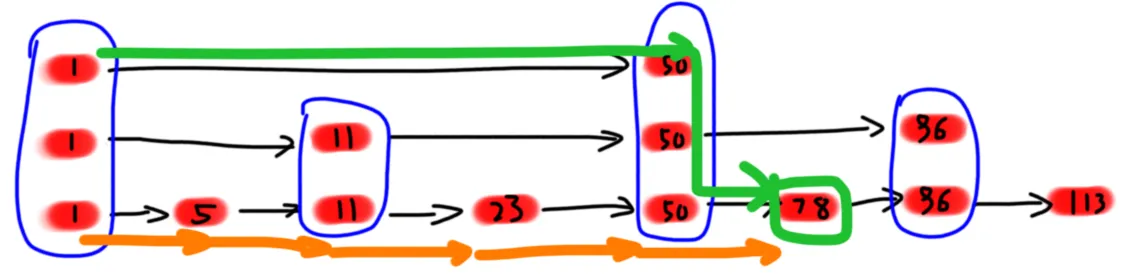
这样的话,我就能像上图这样找到 (78) 这个节点了。
橙色路径是原有路径,走了 (4) 次。而上面的绿色路径只走了 (log_2 4 = 2) 个次。好好好,那我这样建的话,我就能在链表上二分了!
实际上这个东西叫完美跳表。
跳表分两种,一种是上面的完美跳表(暂且这样叫)。这个东西最大的特点就是过于理想化了。如果加上插入删除的话,维护对应层的指针就太难了,每次都得更新。
另一种是基于随机化的跳表。
要随机化的东西叫做 (level)。一个跳表节点的 (level),代表着这个节点同时存在于 (1 sim level) 层的链表中。比如说,上图的值为 (1) 的节点 (level = 3),值为 (23) 的节点 (level = 1)。
取 (level) 的方式类似于抛硬币,计算 (level) 时,如果硬币正面朝上,就 (+1) 并继续抛;如果反面朝上,则停止。通过这样定下节点 (level) 的跳表就是我们今天要实现的跳表。
基本实现
为了方便演示,这里就不再封装跳表了,其实跟着教程一边走一边封装也是可行的。
一些变量
int level 记录跳表的最高 l服务器托管网evel。
Node head 为了防止过多的边界的分类讨论,建立一个空结点当头节点。
节点
动态分配内存太慢了,如果用动态分配的,我还不如直接 STL。
所以开好数组作为预分配的空间,然后我们可以开一个指针记录分配到了哪一个位置。需要创建新节点的时候直接返回一个 ++tot 即可。
struct Node {
int key, level;
Node* nxt[MAX_LEVEL];
} space[N], *tot = space;
此处 level 的含义是:该节点存在于 0 到 level – 1 层的链表中,与前文定义 1 到 level 不同。
垃圾回收可以自己实现,待会的整体演示里面会放。
分配一个新节点空间,返回新节点的指针:
#define new_node() (++tot)
创建一个值为 key 高度为 level 的节点:
Node* create_node(int level, int key) {
Node* res = new_node();
res->level = level;
res->key = key;
return res;
}
随机生成 level
前面说了,是抛硬币。
所以我们可以直接借用一些随机数生成器。
然后我们肯定不能让层数无限大啊,所以需要设置一个 MAX_LEVEL 作为最大层数。
#define MAX_LEVEL 12
std::random_device seed;
std::minstd_rand rng(seed());
int random_level() {
int res = 1;
while (res 本人做了测试,在随机种子 + 1000 次取值的测试下,梅森缠绕和线性同余两种算法通过 & 1 求出来的平均值基本上就是 (0.5pm 0.03),而且线性同余性能远比梅森缠绕高。然后用 PCG 算法测试了一下,发现 PCG 官方给的 C++ 实现能够做到 (0.5pm 0.02),性能接近线性同余,但是这玩意考场上得自己实现,所以还是用线性同余吧。
插入节点
声明:
void insert(int key);
三步走:找到需要插入的位置,插入节点,更新对应 level 的链表。
首先我们直接从高 level 开始跳,跳不了了就跳低一级的 level 即可找到需要插入的位置。
同时记录每一个 level 的当前位置之前的节点。(即可能需要更新后向指针的节点)。
Node *cur = head; // current
for (int lev = level - 1; lev != -1; --lev) {
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev]; // 存在满足要求的点就跳
update[lev] = cur;
}
细节:可能当前 level 还没有到跳表可能达到的最高 level,但是当前这个节点随机到的 level 值在这两个数中间,所以需要将 level 到 MAX_LEVEL 这段补全为 head:
int lev = random_level(); // 当前节点的 level 值
if (lev > level) {
for (int i = level; i 创建节点:
cur = create_node(lev, key);
执行插入操作,即对于每一层链表,更新前一个节点的指针,并让当前节点的后向指针指向后一个节点。
for (int i = lev - 1; i > -1; --i) { // 普通链表插入操作
cur->nxt[i] = update[i]->nxt[i];
update[i]->nxt[i] = cur;
}
删除节点
和插入类似。
void erase(int key) {
nodePointer cur = head; // current
for (int lev = level - 1; lev != -1; --lev) {
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev]; // 存在满足要求的点就跳
update[lev] = cur;
}
cur = cur->nxt[0];
for (int i = 0; i nxt[i] == cur)
update[i]->nxt[i] = cur->nxt[i];
else
break;
while (level > 1 && !head->nxt[level - 1]) // 更新当前最大层数
--level;
}
额外要注意的是,可能跳表的最高层就这一个节点,删了就没了,所以要判断并更新最大层数。
查找结点
实际上上面两个函数的第一部分就相当于查找。
bool find(int key) {
Node* cur;
for (int lev = level - 1; lev > -1; --lev)
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev]; // 存在满足要求的点就跳
return cur->nxt[0] ? cur->nxt[0]->key == key : false;
}
查找前驱后继的方法也差不多,前驱就是查找后直接返回 cur 而不是 cur->nxt[0],后继可以跳到 cur->nxt[lev]->key 的位置之后返回 cur->nxt[0]->key。最后的代码中有体现。
随机访问(按排名查询)
上面其实已经实现了跳表的基本功能了,但是显然,目前实现的功能都可以用平衡树替代,而且平衡树还能够按照数的排名查询。
由于维护的是有序序列,所以按照数的排名查询相当于随机访问。
接下来我们来实现跳表的随机访问。具体方法:维护每个后向指针的“跨度”(span),即它跳了几个节点。
形式化来说,设指针 (ptr) 从第 (a) 个节点指向第 (b) 个节点,则 (ptr) 的跨度为 (b-a)
除此以外,我们还需要维护一个长度 length,在每次 erase 和 insert 的时候加减一下就好了。
重写智能指针
啥是智能指针?不太清楚,但是我感觉维护一个 span 的指针实在太智能了!
我们需要给指针记录一个“跨度”,那就维护一个结构体作为指针,存原来的裸指针和跨度。
总的来说,需要构造函数并重载一个运算符,一个类型转换。
struct nodePointer {
int span;
Node* pointer;
nodePointer() {
this->pointer = nullptr; // 构造函数,将指针初始化为空
}
nodePointer(Node* node) {
this->pointer = node; // 如果提供了指针就用提供的
}
Node* operator->() {
return pointer; // 指针原有的箭头运算符,访问 nodePointer->x 相当于访问 pointer->x
}
operator Node*() const {
return pointer; // 智能指针转换为裸指针,直接返回 pointer 就好了
}
};
不要在所有地方都使用 nodePointer,我们只在需要维护跨度的地方使用就好了。
编写代码时一定要注意类型的使用,比如说 unsigned long 不应乱用之类的。如果错误地更新 span,而你滥用了 nodePointer,可能就没那么容易找到问题了。
博主因为滥用 unsigned,跳表调了两天多。
需要维护跨度的地方只有跳转用的指针,即 nxt[]。
更改后的代码:
struct Node {
int key, level;
struct nodePointer {
int span;
Node* pointer;
nodePointer() {
this->pointer = nullptr; // 构造函数,将指针初始化为空
}
nodePointer(Node* node) {
this->pointer = node; // 如果提供了指针就用提供的
}
Node* operator->() {
return pointer; // 指针原有的箭头运算符,访问 nodePointer->x 相当于访问 pointer->x
}
operator Node*() const {
return pointer; // 智能指针转换为裸指针,直接返回 pointer 就好了
}
};
nodePointer nxt[MAX_LEVEL];
} space[N];
using nodePointer = typename Node::nodePointer; // 为了方便书写,缩一下
重写插入函数
开一个数组记录每一层“上一个节点”的位置(利用跨度)。
int lst_pos[MAX_LEVEL];
然后在函数开头找位置的时候顺便把它处理出来:
for (int lev = level - 1; lev > -1; --lev) {
// 更新 lst_pos
if (lev == level - 1)
lst_pos[lev] = 0; // 默认得是 0
else
lst_pos[lev] = lst_pos[lev + 1]; // 否则从上一层继承
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev].span; // 更新
cur = cur->nxt[lev]; // 存在满足要求的点就跳
}
update[lev] = cur;
}
插入的时候计算一下就好了。
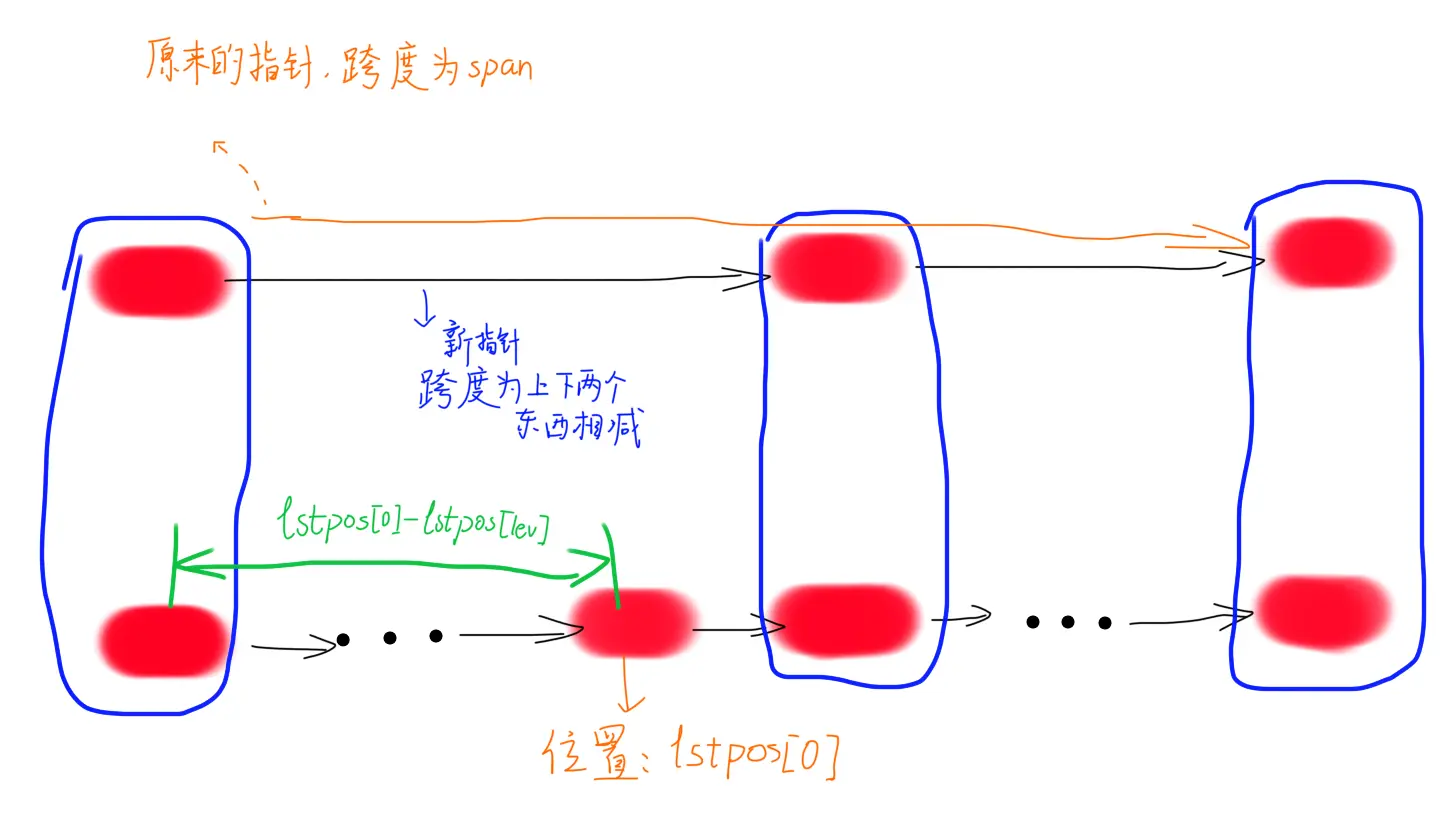
然后 level 大于这个节点的指针跨度要加一。
结合代码理解。
for (int i = 0; i nxt[i] = update[i]->nxt[i];
update[i]->nxt[i].pointer = cur; // 这里不要直接让 nxt[i] = cur,因为后面还要用到 nxt[i].span
cur->nxt[i].span = update[i]->nxt[i].span - (lst_pos[0] - lst_pos[i]); // lst_pos[0] 实际上就是上一个节点的位置
update[i]->nxt[i].span = lst_pos[0] - lst_pos[i] + 1;
}
for (int i = lev; i nxt[i].span; // 维护高于新节点的指针的跨度
别忘了 ++length。
重写删除函数
把要删掉的指针的 span 加起来赋值给新指针就好了。
和 insert 一样,别忘记比当前节点高的指针跨度要 -1。
for (int i = 0; i nxt[i] == cur)
update[i]->nxt[i].pointer = cur->nxt[i], update[i]->nxt[i].span += cur->nxt[i].span - 1; // 跨度直接扔给前面那个指针就行了
else
--update[i]->nxt[i].span;
随机访问(按照排名查询)
int findrk(int k) {
assert(k -1 ; --lev)
while (cur->nxt[lev] && k - cur->nxt[lev].span > 0) {
k -= cur->nxt[lev].span;
cur = cur->nxt[lev]; // 存在满足要求的点就跳
}
return cur->nxt[0]->key;
}
微调
我们可以对 MAX_LEVEL 和选取 level 的概率进行微调。
比如说下面的普通平衡树代码,把选取层数的 (p) 改成了 (frac 14),即 (rng() & 1) && (rng() & 1),MAX_LEVEL 设为了 (7),经测试这样比较快,在无快读不开 O2 的情况下吊打 Splay/FHQ/Treap,加了快读 O2 之后不知道为啥跑不过我之前写的指针 FHQ 了。另外数组 Treap 始终被吊打。这就是指针带给我的自信
复杂度分析
空间复杂度
设定了最高 level,所以空间复杂度只能是 (Theta(n)) 的。
时间复杂度
见 OI Wiki
后记
实际上跳表最大的优点是能够顺序访问,这点是很多平衡树做不到的,FHQ Treap 分裂区间之后中序遍历是可以的,但是常数太大。
等我把跳表模板题搞出来,他们都得死!
完整代码
含类型泛化和封装成类。
另外实现了一些输入输出操作,自己看应该能看懂了。
#include
#include
#include
#include
using std::cin;
using std::cout;
std::random_device seed;
std::minstd_rand rng(seed());
#define N 106
#define MAX_LEVEL 32
using i32 = signed int;
template
class skiplist {
private:
i32 level;
struct Node {
T key;
i32 level; // 千万的别用 unsigned
struct nodePointer {
i32 span; // 这个也千万他妈的别用 unsigned
Node* pointer;
nodePointer() {
this->pointer = nullptr; // 构造函数,将指针初始化为空
}
nodePointer(Node* node) {
this->pointer = node; // 如果提供了指针就用提供的
}
Node* operator->() {
return pointer; // 指针原有的箭头运算符,访问 nodePointer->x 相当于访问 pointer->x
}
operator Node*() const {
return pointer; // 智能指针转换为裸指针,直接返回 pointer 就好了
}
};
nodePointer nxt[MAX_LEVEL];
} space[N];
i32 bintop;
using nodePointer = typename Node::nodePointer;
Node *head, *tail, *tot, *rubbin[N / 4 * 3];
#define new_node() (bintop ? rubbin[bintop--] : ++tot)
#define del_node(x) (rubbin[++bintop] = (x))
Node* create_node(const i32& level, const T& key) {
Node* res = new_node();
res->level = level;
res->key = key;
return res;
}
i32 random_level() {
i32 res = 1;
while (res nxt[i] = nullptr, head->nxt[i].span = 0;
}
void insert(const T& key) {
Node* cur = head; // current
for (i32 lev = level - 1; lev > -1; --lev) {
// 更新 lst_pos,这里由于已经把 lst_pos[MAX_LEVEL] 设为 0 了,所以不需要像上文一样特判
lst_pos[lev] = lst_pos[lev + 1];
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev].span;
cur = cur->nxt[lev]; // 存在满足要求的点就跳
}
update[lev] = cur;
}
i32 lev = random_level();
if (lev > level) {
for (i32 i = level; i nxt[i].span = length; // 这层都还没有节点,直接从 head 指向尾部(nullptr),跨度为 length
}
level = lev;
}
cur = create_node(lev, key);
for (i32 i = 0; i nxt[i] = update[i]->nxt[i];
update[i]->nxt[i].pointer = cur; // 这里不要直接让 nxt[i] = cur,因为后面还要用到 nxt[i].span
cur->nxt[i].span = update[i]->nxt[i].span - (lst_pos[0] - lst_pos[i]); // lst_pos[0] 实际上就是上一个节点的位置
update[i]->nxt[i].span = lst_pos[0] - lst_pos[i] + 1;
}
for (i32 i = lev; i nxt[i].span;
++length;
}
void erase(const T& key) {
Node* cur = head; // current
for (i32 lev = level - 1; lev != -1; --lev) {
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev]; // 存在满足要求的点就跳
update[lev] = cur;
}
cur = cur->nxt[0];
for (i32 i = 0; i nxt[i] == cur)
update[i]->nxt[i].pointer = cur->nxt[i].pointer, update[i]->nxt[i].span += cur->nxt[i].span - 1; // 跨度直接扔给前面那个指针就行了
else
--update[i]->nxt[i].span;
while (level > 1 && !head->nxt[level - 1]) // 更新当前最大层数
--level;
del_node(cur);
--length;
}
bool find(const T& key) {
Node* cur = head;
for (i32 lev = level - 1; lev > -1; --lev)
while (cur->nxt[lev] && cur->nxt[lev]->key nxt[lev]; // 存在满足要求的点就跳
return cur->nxt[0] ? cur->nxt[0]->key == key : false;
}
T findrk(i32 k) {
assert(k -1 ; --lev)
while (cur->nxt[lev] && k - cur->nxt[lev].span > 0) {
k -= cur->nxt[lev].span;
cur = cur->nxt[lev]; // 存在满足要求的点就跳
}
return cur->nxt[0]->key;
}
i32 length;
};
skiplist list;
#include
int main() {
std::ios::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
i32 n, tx;
cin >> n;
for (i32 i = 1; i > tx;
list.insert(tx);
}
std::string s;
while (cin >> s) {
switch (s[0]) {
case ('l'): cout > tx;
list.insert(tx);
break;
case ('d'):
case ('r'): {
cin >> tx服务器托管网;
if (list.find(tx))
list.erase(tx);
else
cout > tx;
cout > tx;
cout 参考文献
《跳跃表数据结构与算法分析》 纪卓志 George
《跳表》 OI Wiki
推荐阅读
《关于 skip list 的一些扩展想法》
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: VictoriaMetrics源码:索引文件结构
VictoriaMetrics的索引文件,保存在{storagePath}/indexdb目录下: # tree ./indexdb/ -L 1 ./indexdb/ ├── 1759A6CAD53ABA2E ├── 1759A6CAD53ABA2F └── …
