
在本篇文章中,我们将带您首先通过解读 LLM 的全景图,深入探讨了 LLM 的六个关键领域,随后提出五种主要方案以解决企业在这一技术领域面临的挑战。从商业模型到开源模型、微调、自定义构建,再到与 AI 提供商的合作,本文将引领您深入了解 LLM 的技术脉络,为探索和应用这一技术提供一些思考与指导。
大型语言模型图
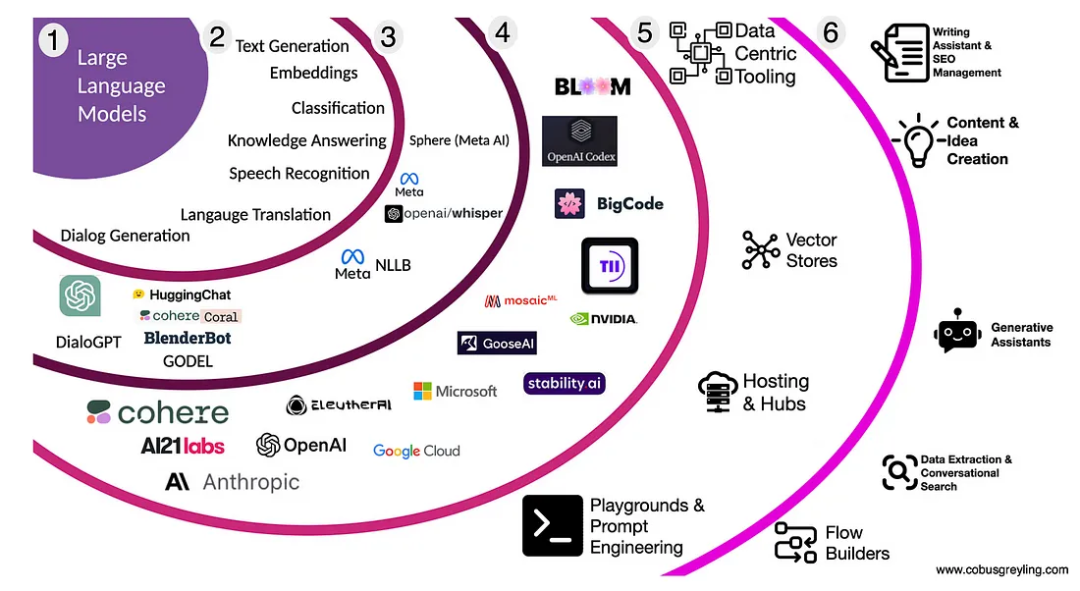
上图显示了由 LLMs 延伸出来的内容,分为六个区域。随着这些区域的扩展,产品和服务有不同的需求和机会。其中一些机会已经被发现,但还有一些尚未被发现。在区域5为差异化、实质性的内置知识产权和卓越的用户体验提供了更大的机会,使企业能够利用 LLMs 的力量。
区域1 – 可用的大型语言模型
就 LLM 而言,从本质上讲 LLM 是与语言绑定的,不过多模态模型已经在图像、音频等方面引入。这种转变产生了一个更通用的术语,即基础模型。除了增加的模态性外,还提供了多个更专注于特定任务的模型,以及大量开源模型可供使用。
新的提示工程(Prompt Engineering)技术[1]说明了如何增强模型性能,以及市场如何朝着利用数据发现、数据设计、数据开发和数据交付来实现这种程度的模型自治的方向发展。
除了增加模式外,大型商业供应商还提供了多种模式,这些模式更加针对具体任务。此外,还出现了大量开源模型,新的提示技术说明了如何提高模型性能,以及市场如何朝着利用数据发现、数据设计、数据开发和数据交付来实现模型自治的方向发展。
区域2 – 通用用例
随着大型语言模型的出现,功能更加细分,模型被训练用于特定任务。例如 Meta 下的 Sphere 专注于知识问答,称之为知识密集型自然语言处理(KI-NLP)。像 DialoGPT、GODEL 和其他模型则专注于对话管理等方面。
最近 LLM 的发展采用了一种方法,即模型结合了这些特点,并且可以通过不同的提示技术提取出令人惊叹的性能。
LLM 的主要实现和应用如下:
-
文本分析变得越来越重要,嵌入对于这类实现至关重要。
-
语音识别,也称为 ASR,是将音频语音转换为文本的过程。通过一种称为词错误率(WER)的方法可以轻松地衡量任何ASR过程的准确性。ASR 为 LLM 的训练和使用提供了大量的录音语言数据。
这个领域有两个值得注意的变化:
- 知识问答和知识密集型 NLP(KI-NLP)方法被 RA服务器托管网G 提示工程在推理中取代。
- 对话生成由 GODEL 和 DialoGPT 等发展推动。这些已被 ChatGPT、HuggingChat 和 Cohere Coral 等特定实现所取代。还有通过提示工程,在提示中呈现对话上下文的小样本训练(Few-shot training)。
区域3-具体实现
该区域列出了一些特定用途的模型。目前已逐渐分为两部分,一个是通用的 LLM,另一个则是基于 LLM 的数字/个人助手。
区域4-模型
这里列出了业内最为突出的大型语言模型提供商。大多数 LLM 都具有内置的知识和功能,包括自然语言翻译、解释和编写代码的能力,通过提示工程进行对话和上下文管理。
区域5-基础工具
该领域显示的是利用 LLM 的工具,包括向量存储、Playground 和提示工程工具。例如 HuggingFace 这样的托管平台通过模型卡和简单的推理 API 实现无代码交互。
在这个区域中我还列出了数据中心工具(Data Centric Tooling),它专注于重复使用 LLM 的高价值用途。
在这个领域的市场机会是创造基础工具,以解决未来对数据发现、数据设计、数据开发和数据交付的需求。
企业可参考的 LLM 五大应用方案
企业希望利用 LLM 来创造更多商业价值和竞争优势,随着 LLM 领域的迅速演进和分化,做出正确的选择不仅需要了解可用的模型,还需要了解每个模型如何与企业独特的业务目标保持一致。企业不得不在日益复杂的选择面前谨慎抉择。这里我们列出关于企业采用 LLM 的五大方案,企业可单独或混合应用以实现其业务目标。
商业模型
商业模型,如 ChatGPT、Google Bard 和 Microsoft Bing,为追求实现大型语言模型的有远见的领袖和企业家提供了一种简单高效的解决方案。这些模型已经在不同的数据集上进行了广泛的训练,提供了文本生成、语言翻译和问答能力。它们的主要优势在于它们的即时可用性。通过正确的策略、程序和流程,企业可以快速部署这些模型,迅速利用它们的能力。
然而,需要记住的是,虽然这些模型设计用于多功能性,服务于广泛的应用,但它们可能在您企业特定的任务中表现不佳。因此,应考虑它们在您独特的业务需求中的适用性。

开源模型
对于考虑 LLM 解决方案的企业来说,开源模型是一种经济实惠的选择。这些免费提供的模型提供先进的语言功能,同时将成本最小化。然而,值得注意的是,对于需要广泛定制的组织,开源模型可能无法提供与专有选项相同的控制水平。
在某些情况下,它们是基于比商业模型更小的数据集进行训练的。开源 LLM 仍然提供文本生成、翻译和问答任务的多功能性。开源模型的主要优势在于其成本效益。几家开源提供商提供微调以与特定的业务需求相一致,提供更加个性化的方法。
一个考虑因素是开源模型的维护和支持。公共云提供商经常更新和改进他们的商业模型,而开源模型可能缺乏一致的关注。评估所选择的开源模型的可靠性和持续发展是确保长期适用性的重要因素。
微调模型
微调模型允许企业在特定的业务任务上实现最佳性能。这些模型通过使用组织的数据进行额外的训练,结合商业模型的优势。
一家希望改进其客户支持聊天机器人的公司可能会从一个能够理解和生成自然语言的商业模型开始。他们可以使用其历史客户支持聊天记录来对其进行微调,以训练其特定服务器托管网的客户查询、响应和上下文。
微调模型的优点在于能够根据具体需求定制模型,同时受益于商业模型提供的易用性。这对于行业特定的术语、独特的要求或专业用例尤其有价值。然而,微调可能需要大量的资源,需要一个准确代表目标领域或任务的合适数据集。获取和准备这个数据集可能涉及额外的成本和时间。
微调可以使企业将大型语言模型适应其独特的要求,提高性能和任务特定的相关性。尽管涉及规划和投资,但这些好处使得微调模型对于旨在增强其语言处理能力的组织非常有吸引力。
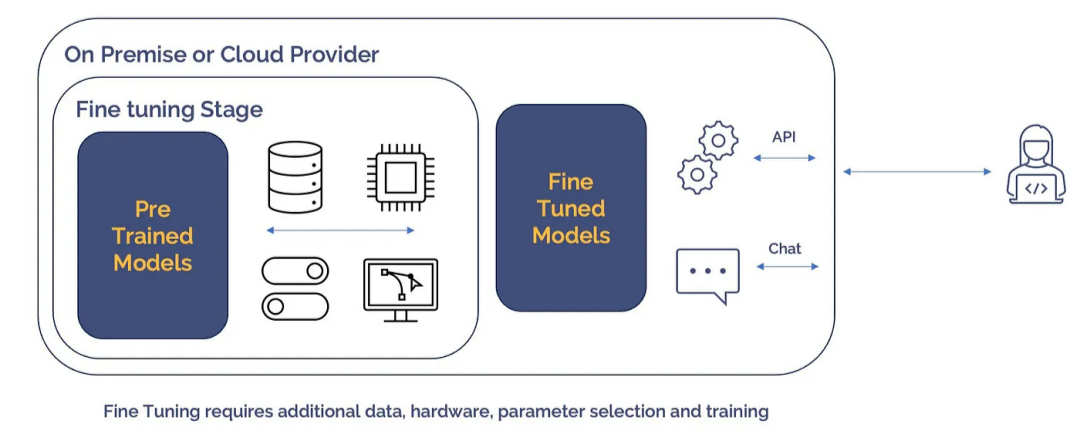
构建自定义语言模型
从头开始构建自定义语言模型 LLM 可以为企业提供无与伦比的控制和定制性,但成本较高。这个选项很复杂,需要机器学习和自然语言处理的专业知识。自定义 LLM 的优势在于其量身定制的性质。它可以根据您企业的独特需求进行设计,确保最佳性能和目标的一致性。
通过自定义 LLM,您可以控制模型的架构、训练数据和微调参数。然而,构建自定义 LLM 非常耗时和昂贵。它需要一个熟练的团队、硬件、广泛的研究、数据收集和注释以及严格的测试。还需要进行持续的维护和更新,以保持模型的有效性。
构建自定义 LLM 是寻求绝对控制和高性能的组织的最佳选择。尽管需要投资,但它为您的语言处理需求提供了高度定制的解决方案。
混合方法
混合方法结合了不同策略的优势,提供了一个平衡的解决方案。通过将商业模型与微调或自定义模型结合使用,企业可以实现定制化和高效的语言模型策略。
该方法经过优化,以满足特定任务要求和行业细微差别。例如,当出现新的客户请求时,商业模型可以处理文本并提取相关信息。这种初始交互受益于商业模型对语言理解和知识的普遍掌握。经过明确训练于企业客户参与和对话数据上的微调或自定义模型接管。它分析处理后的信息,提供定制化和上下文相关的回应,利用其在客户评价和类似互动方面的训练。
通过采用混合方法,企业可以实现一个灵活高效的策略,提供定制化解决方案的同时利用商业模型中的知识。这个策略为在已有语言模型的背景下解决企业特定需求提供了实用和有效的方法。
与 AI 提供商合作
与 AI 提供商合作是实施 LLM 的一个可行选择。这些提供商提供专业知识和资源,用于构建和部署定制语言模型。与 AI 提供商合作的优势在于获得他们的专业知识和支持。他们拥有深入的机器学习和自然语言处理知识,有效地指导企业。他们提供见解,推荐模型,并在开发和部署过程中提供支持。不过选择与 AI 提供商合作,请考虑可能涉及额外成本,评估财务影响。
通过与 AI 提供商合作,企业可以从专业知识中受益,确保 LLM 的顺利整合。尽管应考虑成本,但与AI提供商合作的优势,尤其是在专业指导和支持方面,可能超过了费用。
结论
在快速发展的生成式 AI 世界中,选择正确的道路不仅仅需要掌握可用模型,还需要理解每个模型如何与您独特的业务目标相契合。成功实施这些模型并非偶然之举,需要取决于全面的思考,平衡即时需求与未来趋势和机遇。并非所有情况都有通用的解决方案,因此最佳的策略应当是量身打造的。在生成式 AI 的复杂环境中,最大的挑战通常不在于技术本身,而在于确定正确的策略以释放其潜力。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 第三章 数据链路层 | 计算机网络(谢希仁 第八版)
文章目录 第三章 数据链路层 3.1 使用点对点信道的数据链路层 3.1.1 数据链路和帧 3.1.2 三个基本问题 3.2 点对点协议PPP 3.2.1 PPP协议的特点 3.2.2 PPP协议的帧格式 3.2.3 PPP协议的工作状态 3.3 使用广播信道…
