
一、简介
本文博主给大家讲解如何在自己开源的电商项目newbee-mall-pro中应用协同过滤算法来达到给用户更好的购物体验效果。
newbee-mall-pro项目地址:
- 源码地址:https://github.com/wayn111/newbee-mall-pro
- 在线地址:http://121.4.124.33/newbeemall
二、协同过滤算法
协同过滤算法是一种基于用户或者物品的相似度来推荐商品的方法,它可以有效地解决商城系统中的信息过载问题。协同过滤算法的实践主要包括以下几个步骤:
- 数据收集和预处理。这一步需要从商城系统中获取用户的行为数据,如浏览、购买、评价等,然后进行一些必要的清洗和转换,以便后续的分析和计算。
- 相似度计算。这一步需要根据用户或者物品的特征或者行为,采用合适的相似度度量方法,如余弦相似度、皮尔逊相关系数、Jaccard指数等,来计算用户之间或者物品之间的相似度矩阵。
- 推荐生成。这一步需要根据相似度矩阵和用户的历史行为,采用合适的推荐策略,如基于邻域的方法、基于模型的方法、基于矩阵分解的方法等,来生成针对每个用户的个性化推荐列表。
-
推荐评估和优化。这一步需要根据一些评价指标,如准确率、召回率、覆盖率、多样性等,来评估推荐系统的效果,并根据反馈信息和业务需求,进行一些参数调整和算法优化,以提高推荐系统的性能和用户满意度。
在原有的商城首页为你推荐栏目是使用后台配置的商品列表,基于人为配置。在项目商品用户持续增长的情况下,不一定能给用户推荐用户可能想要的商品。
因此在v2.4.1版本中,商城首页为你推荐栏目添加了协同过滤算法。按照UserCF基于用户的协同过滤、ItemCF基于物品的协同过滤。 实现了两种不同的推荐逻辑。
-
UserCF:基于用户的协同过滤。当一个用户A需要个性化推荐的时候,我们可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的,而用户A没有听说过的物品推荐给A。
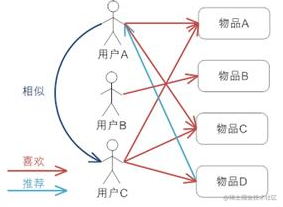
假设用户 A 喜欢物品 A、物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A 、物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。具体代码在ltd.newbee.mall.recommend.core.UserCF中。 -
itemCF:基于物品的协同过滤。预先根据所有用户的历史偏好数据计算物品之间的相似度,然后把与用户喜欢的物品相类似的物品推荐给用户。
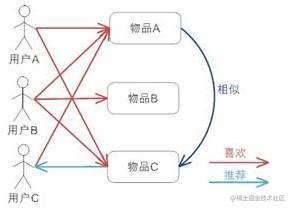
假如用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史喜好中可以认为物品A与物品C比较类似,喜欢物品A的都喜欢物品C,基于这个判断用户C可能也喜欢物品C,所以推荐系统将物品C推荐给用户C。 具体代码在ltd.newbee.mall.recommend.core.ItemCF中。
三、推荐算法代码实践
3.1 数据收集和预处理
在newbee-mall-pro中,我们基于用户下单的商品数据进行收集和预处理。
/**
* 根据所有用户购买商品的记录进行数据手机
*
* @return List
*/
@Override
public List getRelateData() {
List relateDTOList = new ArrayList();
// 获取所有订单以及订单关联商品的集合
List newBeeMallOrders = orderDao.selectOrderIds();
List orderIds = newBeeMallOrders.stream().map(Order::getOrderId).toList();
List newBeeMallOrderItems = orderItemDao.selectByOrderIds(orderIds);
Map> listMap = newBeeMallOrderItems.stream()
.collect(Collectors.groupingBy(OrderItemVO::getOrderId));
Map> goodsListMap = newBeeMallOrderItems.stream()
.collect(Collectors.groupingBy(OrderItemVO::getGoodsId));
// 遍历订单,生成预处理数据
for (Order newBeeMallOrder : newBeeMallOrders) {
Long orderId = newBeeMallOrder.getOrderId();
for (OrderItemVO newBeeMallOrderItem : listMap.getOrDefault(orderId, Collections.emptyList())) {
Long goodsId = newBeeMallOrderItem.getGoodsId();
Long categoryId = newBeeMallOrderItem.getCategoryId();
RelateDTO relateDTO = new RelateDTO();
...
relateDTOList.add(relateDTO);
}
}
return relateDTOList;
} 3.2 相似度计算
在推荐算法中,相似度建立是一个非常重要的过程,它标志着算法准不准确,能不能给用户带来好的推荐体验。在newbee-mall-pro中,我们将用户之间下单的商品进行相似度计算,因为如果两个用户购买了同一个商品,那么我们认为这两个用户之间是存在联系并且都存在付费行为。
// 遍历订单商品
for (OrderItemVO newBeeMallOrderItem : listMap.getOrDefault(orderId, Collections.emptyList())) {
Long goodsId = newBeeMallOrderItem.getGoodsId();
Long categoryId = newBeeMallOrderItem.getCategoryId();
RelateDTO relateDTO = new RelateDTO();
relateDTO.setUserId(newBeeMallOrder.getUserId());
relateDTO.setProductId(goodsId);
relateDTO.setCategoryId(categoryId);
// 通过计算商品购买次数,来建立相似度
List list = goodsListMap.getOrDefault(goodsId, Collections.emptyList());
int sum = list.stream().mapToInt(OrderItemVO::getGoodsCount).sum();
relateDTO.setIndex(sum);
relateDTOList.add(relateDTO);
} 通过余弦相似度算法计算用户与商品之间的相似度,从而为用户推荐最相似的商品。当两个用户购买了同一个商品时,我们就认为两个用户产生了关联,因此针对两个用户购买的同一个商品进行相似度计算,来建立用户之间的相似度。
余弦相似度是一种用于衡量两个向量之间的相似度的方法,它通过计算两个向量的夹角的余弦值来得到。在商城系统中,余弦相似度可以用于实现基于内容的推荐算法,即根据用户的历史购买或浏览行为,为用户推荐与其兴趣相似的商品。具体来说,可以将每个商品表示为一个特征向量,例如商品的类别、价格、评分等,然后将每个用户表示为一个偏好向量,例如用户购买或浏览过的商品的特征向量的加权平均。这样,就可以利用余弦相似度来计算用户和商品之间的相似度,从而为用户推荐最相似的商品。
计算相关系数,传入用户ID或者物品ID,计算相似度
/**
* 计算相关系数并排序
*
* @param key 基于用户协同代表用户id,基于物品协同代表武平id
* @param map 预处理数据集
* @param type 类型0基于用户推荐使用余弦相似度 1基于物品推荐使用余弦相似度
* @return Map
*/
public static Map computeNeighbor(Long key,
Map> map, int type) {
Map distMap = new TreeMap();
List items = map.get(key);
map.forEach((k, v) -> {
// 排除此用户
if (!k.equals(key)) {
// 计算关系系数
double coefficient = relateDist(v, items, type);
distMap.put(coefficient, k);
}
});
return distMap;
} 计算两个用户间的相关系数
/**
* 计算两个序列间的相关系数
*
* @param xList
* @param yList
* @param type 类型0基于用户推荐使用余弦相似度 1基于物品推荐使用余弦相似度 2基于用户推荐使用皮尔森系数计算
* @return
*/
private static double relateDist(List xList,
List yList, Integer type) {
List xs = Lists.newArrayList();
List ys = Lists.newArrayList();
xList.forEach(x -> yList.forEach(y -> {
if (type == 0) {
// 基于用户推荐时如果两个用户购买的商品相同,则计算相似度
if (x.getProductId().longValue() == y.getProductId().longValue()) {
xs.add(x.getIndex());
ys.add(y.getIndex());
}
} else if (type == 1) {
// 基于物品推荐时如果两个用户id相同,则计算相似度
if (x.getUserId().longValue() == y.getUserId().longValue()) {
xs.add(x.getIndex());
ys.add(y.getIndex());
}
}
}));
if (ys.size() == 0 || xs.size() == 0) {
return 0d;
}
// 余弦相似度计算
return cosineSimilarity(xs, ys);
} 余弦相似度计算
/**
* 来计算向量之间的余弦相似度,
* 也就是计算两个用户或者两个物品之间的相似度
* @param xs
* @param xs
* @return double
*/
private static double cosineSimilarity(List xs,
List ys) {
double dotProduct = 0;
double norm1 = 0;
double norm2 = 0;
for (int i = 0; i 3.3 推荐生成
基于用户协同的推荐生成,我们可以先找到和目标用户有相似兴趣的其他用户,然后把其他用户喜欢的,而目标用户没有买过的物品推荐给目标用户。
public class UserCF {
/**
* 物用户协同推荐
*
* @param userId 用户ID
* @param num 返回数量
* @param list 预处理数据
* @return 商品id集合
*/
public static List recommend(Long userId, Integer num,
List list, Integer type) {
// 对每个用户的购买商品记录进行分组
Map> userMap = list.stream()
.collect(Collectors.groupingBy(RelateDTO::getUserId));
// 获取其他用户与当前用户的关系值
Map userDisMap = CoreMath.computeNeighbor(userId, userMap, type);
List similarUserIdList = new ArrayList();
List values = new ArrayList(userDisMap.keySet());
values.sort(Collections.reverseOrder());
List scoresList = values.stream().limit(3).toList();
// 获取关系最近的用户
for (Double aDouble : scoresList) {
similarUserIdList.add(userDisMap.get(aDouble));
}
List similarProductIdList = new ArrayList();
for (Long similarUserId : similarUserIdList) {
// 获取相似用户购买商品的记录
List collect = userMap.get(similarUserId).stream()
.map(RelateDTO::getProductId).toList();
// 过滤掉重复的商品
List collect1 = collect.stream()
.filter(e -> !similarProductIdList.contains(e)).toList();
similarProductIdList.addAll(collect1);
}
// 当前登录用户购买过的商品
List userProductIdList = userMap.getOrDefault(userId,
Collections.emptyList()).stream().map(RelateDTO::getProductId).toList();
// 相似用户买过,但是当前用户没买过的商品作为推荐
List recommendList = new ArrayList();
for (Long similarProduct : similarProductIdList) {
if (!userProductIdList.contains(similarProduct)) {
recommendList.add(similarProduct);
}
}
Collections.sort(recommendList);
return recommendList.stream().distinct().limit(num).toList();
}
} 基于物品协同的推荐生成,找出与目标用户购买过的商品中最相似的前几个商品中目标用户也没有买过的商品推荐给用户。
public class ItemCF {
/**
* 物品协同推荐
*
* @param userId 用户ID
* @param num 返回数量
* @param list 预处理数据
* @return 商品id集合
*/
public static List recommend(Long userId, Integer num,
List list) {
// 按物品分组
Map> userMap = list.stream()
.collect(Collectors.groupingBy(RelateDTO::getUserId));
List userProductItems = userMap.get(userId).stream()
.map(RelateDTO::getProductId).toList();
Map> itemMap = list.stream()
.collect(Collectors.groupingBy(RelateDTO::getProductId));
List similarProductIdList = new ArrayList();
Multimap itemTotalDisMap = TreeMultimap.create();
for (Long itemId : userProductItems) {
// 获取其他物品与当前物品的关系值
Map itemDisMap = CoreMath.computeNeighbor(itemId, itemMap, 1);
itemDisMap.forEach(itemTotalDisMap::put);
}
List values = new ArrayList(itemTotalDisMap.keySet());
values.sort(Collections.reverseOrder());
List scoresList = values.stream().limit(num).toList();
// 获取关系最近的用户
for (Double aDouble : scoresList) {
Collection longs = itemTotalDisMap.get(aDouble);
for (Long productId : longs) {
if (!userProductItems.contains(productId)) {
similarProductIdList.add(productId);
}
}
}
return similarProductIdList.stream().distinct().limit(num).toList();
}
} 3.4 推荐评估和优化
在newbee-mall-pro中可以针对为你推荐栏目中推荐的商品做曝光率、点击率、下单数等作为监控指标来评估推荐效果。
四、用户协同和物品协同应用场景
用户协同和物品协同都是两种常用的推荐系统算法,它们分别利用用户之间和物品之间的相似度来给用户提供个性化的推荐。用户协同和物品协同的应用场景有以下几种:
- 用户协同适用于用户数量相对较少,用户兴趣相对稳定,物品数量相对较多,物品更新频率较高的场景。例如,电影推荐、音乐推荐、图书推荐等。
- 物品协同适用于用户数量相对较多,用户兴趣相对多变,物品数量相对较少,物品更新频率较低的场景。例如,新闻推荐、广告推荐、社交网络推荐等。
- 用户协同和物品协同也可以结合起来,形成混合推荐系统,以提高推荐的准确性和覆盖率。例如,电商平台可以根据用户的购买历史和评价,以及物品的属性和销量,综合使用用户协同和物品协同来给用户推荐商品。
商城系统使用用户协同还是物品协同,这是一个需要根据具体情况进行选择的问题。用户协同是指根据用户之间的相似度,为用户推荐他们可能感兴趣的物品。物品协同是指根据物品之间的相似度,为用户推荐与他们已经购买或浏览过的物品相似的物品。两种方法各有优缺点,需要综合考虑商城系统的目标、规模、数据量、稀疏度等因素。一般来说,如果商城系统的目标是增加用户的多样性和探索性,那么用户协同可能更合适,因为它可以为用户提供更广泛的选择。如果商城系统的目标是增加用户的满意度和忠诚度,那么物品协同可能更合适,因为它可以为用户提供更精准的推荐
在一般商城系统中,初期用户数量少可以使用用户协同,后期用户数远超商品数,使用物品协同会更好些,这两者也可以结合使用。推荐算法是不会一成不变的,它需要根据某些指标数据不断优化调整升值甚至重构使用另外的算法。
五、冷启动问题
商城协同算法冷启动问题是指在商城系统中,当新用户或新商品加入时,由于缺乏足够的交互数据,导致协同过滤算法无法为其提供准确的推荐结果。
在newbee-mall-pro就是指新用户还未下单
这种问题会影响商城的用户体验和转化率,因此需要有效的解决方案。一种常见的方法是使用流行度算法。
利用基于流行度的算法非常简单粗暴,类似于各大新闻、微博热榜、商城等,根据PV、UV、点击率、搜索率、下单商品排行等数据来按某种热度排序来推荐给用户。
总结
到这里,本文所分享推荐算法在商城系统实践就全部介绍完了,希望对大家实现推荐系统落地有所帮助,喜欢的朋友们可以点赞加关注😘。
公众号【waynblog】每周更新博主最新技术文章,欢迎大家关注
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
