

检索增强生成(RAG)是一种新兴的 AI 技术栈,通过为大型语言模型(LLM)提供额外的“最新知识”来增强其能力。
基本的 RAG 应用包括四个关键技术组成部分:
-
Embedding 模型:用于将外部文档和用户查询转换成 Embedding 向量
-
向量数据库:用于存储 Embedding 向量和执行向量相似性检索(检索出最相关的 Top-K 个信息)
-
提示词工程(Prompt engineering):用于将用户的问题和检索到的上下文组合成大模型的输入
-
大语言模型(LLM):用于生成回答
上述的基础 RAG 架构可以有效解决 LLM 产生“幻觉”、生成内容不可靠的问题。但是,一些企业用户对上下文相关性和问答准确度提出了更高要求,需要更为复杂的架构。一个行之有效且较为流行的做法就是在 RAG 应用中集成 Reranker。
01.什么是 Reranker?
Reranker 是信息检索(IR)生态系统中的一个重要组成部分,用于评估搜索结果,并进行重新排序,从而提升查询结果相关性。在 RAG 应用中,主要在拿到向量查询(ANN)的结果后使用 Reranker,能够更有效地确定文档和查询之间的语义相关性,更精细地对结果重排,最终提高搜索质量。
目前,Reranker 类型主要有两种——基于统计和基于深度学习模型的 Reranker:
基于统计的 Reranker 会汇总多个来源的候选结果列表,使用多路召回的加权得分或倒数排名融合(RRF)算法来为所有结果重新服务器托管算分,统一将候选结果重排。这种类型的 Reranker 的优势是计算不复杂,效率高,因此广泛用于对延迟较敏感的传统搜索系统中。
基于深度学习模型的 Reranker,通常被称为 Cross-encoder Reranker。由于深度学习的特性,一些经过特殊训练的神经网络可以非常好地分析问题和文档之间的相关性。这类 Reranker 可以为问题和文档之间的语义的相似度进行打分。因为打分一般只取决于问题和文档的文本内容,不取决于文档在召回结果中的打分或者相对位置,这种 Reranker 既适用于单路召回也适用于多路召回。
02.Reranker 在 RAG 中的作用
将 Reranker 整合到 RAG 应用中可以显著提高生成答案的精确度,因为 Reranker 能够在单路或多路的召回结果中挑选出和问题最接近的文档。此外,扩大检索结果的丰富度(例如多路召回)配合精细化筛选最相关结果(Reranker)还能进一步提升最终结果质量。使用 Reranker 可以排除掉第一层召回中和问题关系不大的内容,将输入给大模型的上下文范围进一步缩小到最相关的一小部分文档中。通过缩短上下文, LLM 能够更“关注”上下文中的所有内容,避免忽略重点内容,还能节省推理成本。
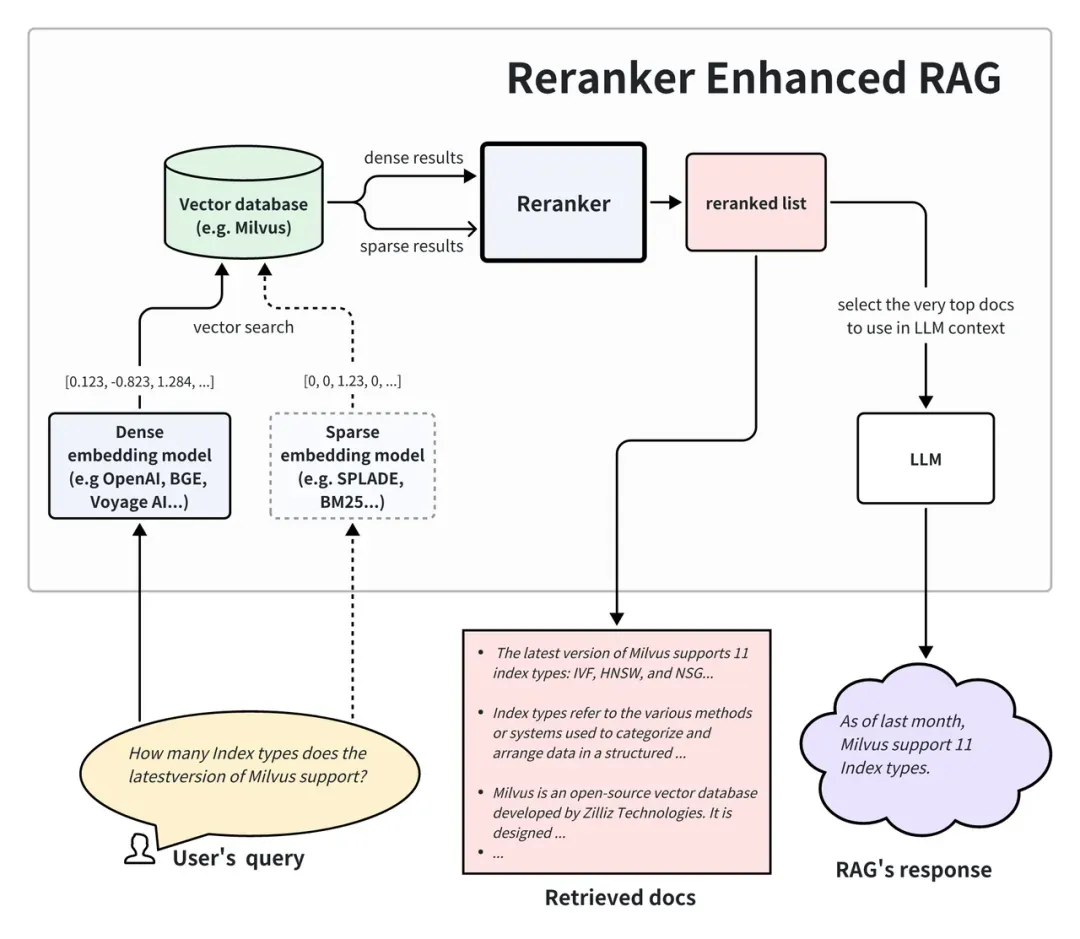
上图为增加了 Reranker 的 RAG 应用架构。可以看出,这个检索系统包含两个阶段:
-
在向量数据库中检索出 Top-K 相关文档,同时也可以配合 Sparse embedding(稀疏向量模型)覆盖全文检索能力。
-
Reranker 根据这些检索出来的文档与查询的相关性进行打分和重排。重排后挑选最靠前的结果作为 Prompt 中的Context 传入 LLM,最终生成质量更高、相关性更强的答案。
但是需要注意,相比于只进行向量检索的基础架构的 RAG,增加 Reranker 也会带来一些挑战,增加使用成本。
03.使用 Reranker 的成本
在使用 Reranker 提升检索相关性的同时需要着重关注它的成本。这个成本包括两方面,增加延迟对于业务的影响、增加计算量对服务成本的增加。我们建议根据自己的业务需求,在检索质量、搜索延迟、使用成本之间进行权衡,合理评估是否需要使用 Reranker。
Reranker 会显著增加搜索延迟
未使用 Reranker 的情况下,RAG 应用只需执行低延迟的向量近似最近邻 (ANN) 搜索,从而获取 Top-K 相关文档。例如 Milvus 向量数据库实现了 HNSW 等高效的向量索引,可实现毫秒级的搜索延迟。如果使用 Zilliz Cloud,还能借助更加强大的 Cardinal 索引进一步提升搜索性能。
但如果增加了 Reranker,尤其是 Cross-encoder Reranker 后,RAG 应用需要通过深度学习模型处理所有向量检索返回的文档,这会导致延时显著增加。相比于向量检索的毫秒级延迟,取决于模型大小和硬件性能,延迟可能提高到几百毫秒甚至到几秒!
Reranker 会大幅度提高计算成本
在基础架构的 RAG 中,向量检索虽然需要预先使用深度学习模型处理文档,但这一较为复杂的计算被巧妙设计在离线状态下进行。通过离线索引(Embedding模型推理),每次在线查询过程只需要付出极低计算成本的向量检索即可。与之相反,使用 Reranker 会大大增加每次在线查询的计算成本。这是因为重排过程需要对每个候选文档进行高成本的模型推理,不同于前者可以每次查询都复用离线索引的结果,使用 Reranker 需要每次在线查询都进行推理,结果无法复用,带来重复的开销。这对于网页搜索、电商搜索等高流量的信息检索系统非常不适用。
让我们简单算一笔账,看看使用 Reranker 的成本。
根据 VectorDBBench 的数据,一个能负担每秒钟 200次 查询请求的向量数据库使用成本仅为每月 100 美元,平摊下来相当于每次查询成本仅为 0.0000002 美元。如果使用 Reranker,假设第一阶段向量检索返回 top-100 个文档,重排这些文档的成本高达 0.001 美元。也就是增加 Reranker 比单独执行向量搜索的成本高出了 5000 倍。
虽然很多实际情况中可能只针对少量结果进行重排(例如 10 到 20 个),但是使用 Cross-encoder reranker 的费用仍然远高于单纯执行向量搜索的费用。
从另一个角度来看,使用 Reranker 相当于在查询时负担相当于离线索引的高昂成本,也就是模型推理的计算量。推理成本与输入大小(文本的 Token 数)和模型本身的大小有关。一般 Embedding 和 Reranker 模型大小在几百 MB 到几个 GB不等。我们假设两种模型尺寸接近,因为查询的文档一般远大于查询的问题,对问题进行推理成本忽略不计,如果每次查询需要重排 top-10 个文档,这就相当于10 倍对于单个文档离线计算 Embedding 的成本。如果在高查询负载的情况下,计算和使用成本可能是无法承受的。对于低负载的场景,例如企业内部高价值低频率的知识库问答,这一成本则可能完全可以接受。
04.成本比较:向量检索 v.s. Cross-encoder Reranker v.s. 大模型生成
虽然 Reranker 的使用成本远高于单纯使用向量检索的成本,但它仍然比使用 LLM 为同等数量文档生成答案的成本要低。在 RAG 架构中,Reranker 可以筛选向量搜索的初步结果,丢弃掉与查询相关性低的文档,从而有效防止 LLM 处理无关信息,相比于将向量搜索返回的结果全部送进 LLM 可大大减少生成部分的耗时和成本。
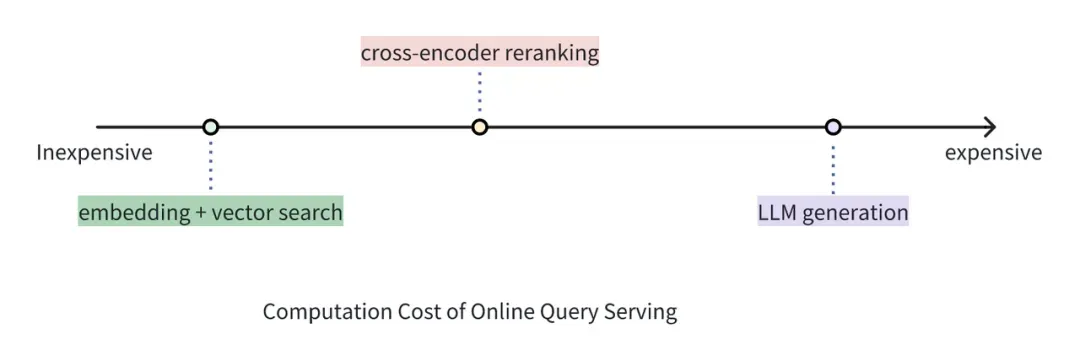
举一个贴近实际的例子:第一阶段检索中,向量搜索引擎可以在数百万个向量中快速筛选出语义近似度最高的 20 个文档,但这些文档的相对顺序还可以使用 Reranker 进一步优化。虽然会产生一定的成本,但 Reranker 可以在 top-20 个结果进一步挑出最好的 top-5 个结果。那么,相对更加昂贵的 LLM 只需要分析这 top-5 个结果即可,免去了处理 20 个文档带来的更高成本和注意力“涣散”的问题。这样一来,我们就可以通过这种复合方案平衡延迟、回答质量和使用成本。
05.哪种情况适合在 RAG 应用中使用 Reranker?
追求回答高精度和高相关性的场景中特别适合使用 Reranker,例如专业知识库或者客服系统等应用。因为这些应用中的查询都具有很高的商业价值,提升回答准确性的优先级远高于系统性能和控制成本。使用 Reranker 能够生成更准确的答案,有效提升用户体验。
但是在网页搜索、电商搜索这类场景中,响应速度和成本至关重要,因此不太适合使用代价高昂的 Cross-Encoder Reranker。此类应用场景更适合选用向量检索搭配更轻量的 Score-based Reranker,从而确保响应速度,在提升搜索质量的同时降低开销。
06.总结
相比于单独使用向量检索,搭配 Reranker 可以通过对第一层检索结果的进一步精细化排序提高检索增强生成(RAG)和搜索系统中答案的准确性和相关性。但是使用 Reranker 会增加延时和提高使用成本,因此不适合高频高并发的应用。考虑是否使用 Reranker 时,需要在回答准确性、响应速度、使用成本间做出权衡。
如果需要在 RAG 应用中使用 Reranker,可以采用最新推出的 py服务器托管milvus 模型库组件调用 Reranker 模型配合 Milvus 的向量检索。同时 Zilliz Cloud 不仅提供向量数据库这一关键组件,还推出了 Pipelines 功能,通过调用 API 服务一站式完成文本向量化、检索、重排序,简化了 RAG 应用的后端架构和降低维护成本。有兴趣的读者可以访问链接(https://docs.zilliz.com/reference/python/Model) 或者浏览(https://milvus.io/docs )了解在 Zilliz Cloud Pipelines 或者 Milvus 使用 Reranker 的详情。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 【密码学基础】Diffie-Hellman密钥交换协议
DH介绍 Diffie-Hellman密钥协议算法是一种确保共享密钥安全穿越不安全网络的方法。 这个机制的巧妙在于需要安全通信的双方可以用这个方法确定对称密钥,然后可以用这个密钥进行加密和解密。 但是注意,这个密钥交换协议 只能用于密钥的交换,而不能进行消息的…
