


作者 | Chip Huyen
OneFlow编译
翻译|杨婷、宛子琳
机器学习模型具有概率性。对于同一个问题,机器可能会给出不同回答,以“世界上最棒的美食是什么?”这一问题为例。假如我们间隔一分钟,对同一个人提问,这个人两次给出的回答应该是相同的;但如果我们分两次问模型同样的问题,它给出的答案可能会发生变化。如果模型认为越南菜最好吃的概率为70%,意大利菜最好吃的概率为30%,那么相应的,模型会有70%的概率回答越南菜,30%的概率回答意大利菜。
这种概率特性使人工智能在创造性任务中大放异彩。创造力不就是超越常规可能、跳出思维框架的能力吗?
然而,这种概率性也会导致不一致(inconsistency)和幻觉问题。对于依赖事实的任务而言,这是致命的。
近期,本文作者调研了一家人工智能初创公司三个月的客户支持请求,发现五分之一的问题是用户不理解或不知道如何处理这种概率特性导致的。
要理解AI响应的概率性,就需要了解模型生成响应的方式,即采样(或解码)过程。本文包括以下三部分:
-
采样:采样策略和采样变量(包括温度、Top-k和Top-p)。
-
测试时采样:采样多个输出,以帮助提高模型性能。
-
结构化输出:如何让模型按照一定格式生成输出。
(本文作者Chip Huyen是实时机器学习平台Claypot AI的联合创始人。本文经授权后由OneFlow编译发布,转载请联系授权。原文:https://huyenchip.com/2024/01/16/sampling.html)
1
采样
对于给定输入,神经网络首先计算所有可能值的概率,然后根据这些概率确定输出。对于一个分类器而言,可能的值就是可用的类(class)。例如,如果一个模型被训练用于分类电子邮件是否为垃圾邮件,那么可能的值就只有两个:垃圾和非垃圾邮件。模型会计算每个值的概率,如垃圾邮件的概率是90%,非垃圾邮件的概率是10%。
为生成下一个词元,语言模型会首先计算词汇表中所有词元的概率分布。
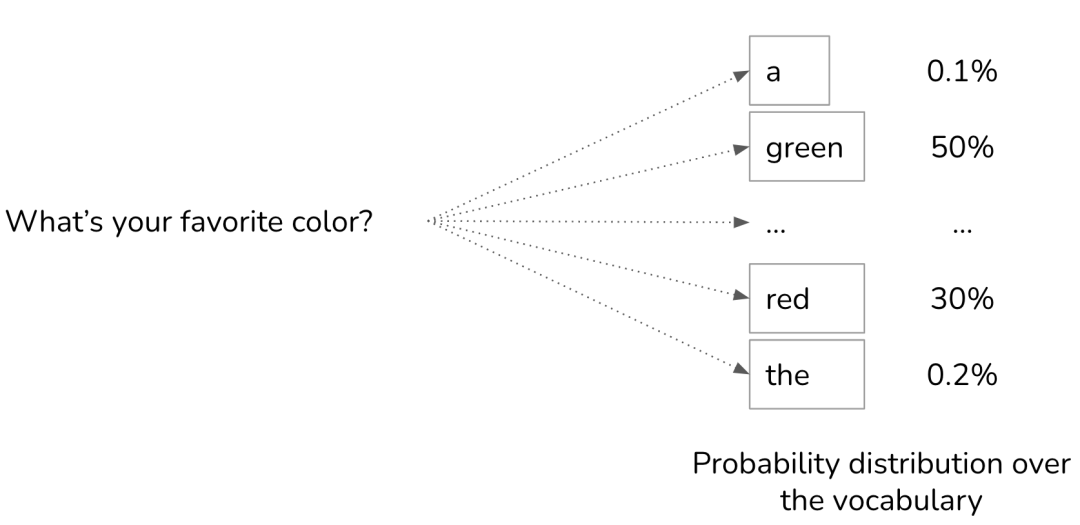
对于垃圾邮件分类任务,可以输出具有最高概率的值,如果是垃圾邮件的概率达到服务器托管了90%,那么就可以将其分类为垃圾邮件。然而,对于语言模型来说,总是选择概率最高的词元,即“贪婪采样”(greedy sampling),会导致输出缺乏变化和创造性。试想这样一个模型:无论你问什么问题,它的回答都大同小异,这将是一种怎样的体验。
因此,与其总是选择下一个最可能的词元,我们可以根据所有可能值的概率分布采样生成下一个词元。例如,在给定上下文“我最喜欢的颜色是…”中,如果“红色”是下一个词元的概率为30%,“绿色”为50%,那么“红色”被选中的概率即为30%,“绿色”为50%。
温度
根据概率分布采样生成下一个词元存在一个问题,即模型可能缺乏创造力。在之前的例子中,红、绿、紫等常见颜色词具有最高概率。语言模型的答案最后听起来就像是一个五岁孩子说的话:即我最喜欢的颜色是绿色。由于“the”等修饰限定词出现的概率较低,模型不太可能生成“我最喜欢春日清晨平静湖面的颜色”等富有创意的句子。
温度(temperature)是一种用于重新分配可能的值概率的技术。直观地说,它会降低常见词元的概率,从而增加罕见词元的概率,使模型能够生成更具创意的回应。
为理解温度的工作原理,我们需要先理解模型计算概率的方式。给定一个输入,神经网络处理这个输入并输出一个logit向量。每个logit对应一个可能性。对于语言模型而言,每个logit对应模型词汇表中的一个词元。logit向量的大小即为词汇表大小。
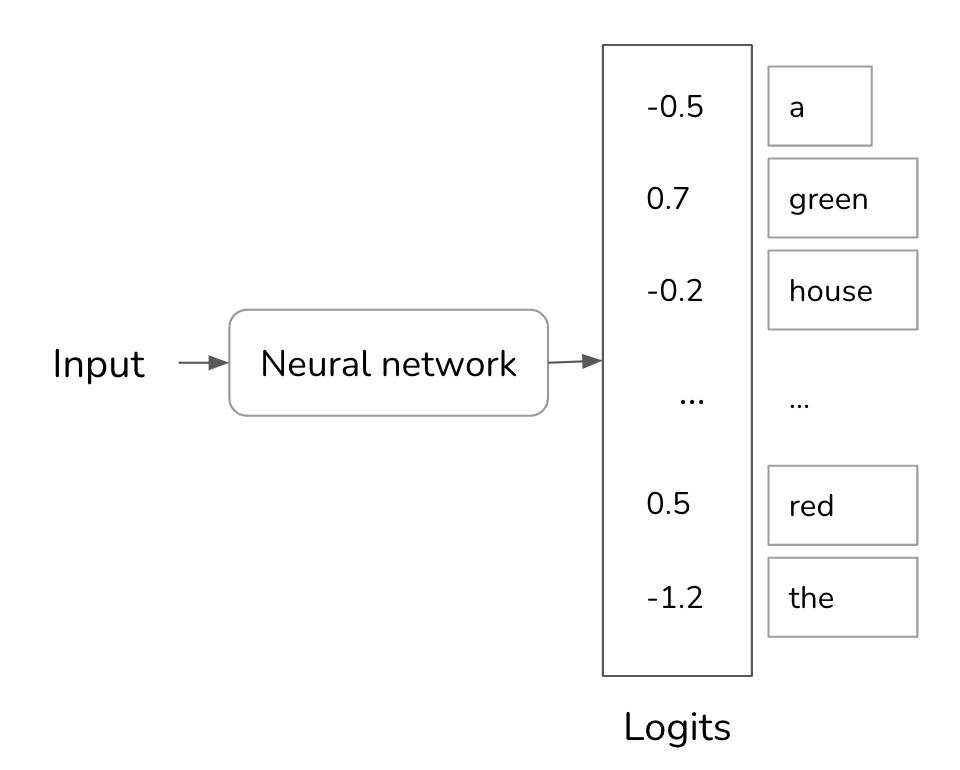
虽然更大的logit对应着更高的概率,但logit本身并不代表概率。logit的总和并不是1,它甚至可能是负数,但概率必须为非负数。为了将logit转换为概率,通常会使用一个softmax层。假设模型的词汇表大小为N,logit向量为
[x1, x2, …, xN]
,则
i^{th}
词元的概率
pi
的计算公式为:
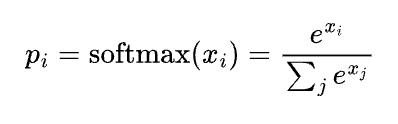
温度是一个常数,用于在softmax转换之前调整logit值。温度会除以logits。对于给定的温度
T
,词元
i^{th}
调整后的logit为
{xi}/{T}
。然后,会在这个经调整的logit上应用softmax,而不是在
xi
上应用softmax。
让我们通过一个简单的例子来理解温度对概率的影响。假设我们有一个模型,这个模型只有两个可能的输出:A和B。从最后一层计算得到的logit值为[1, 3],其中A的logit值为1,B的logit值为3。
-
不使用温度时(相当于温度为1),softmax概率分别为[0.12, 0.88]。模型选择B的概率为88%。
-
当温度为0.5时,概率为[0.02, 0.98]。模型选择B的概率为98%。
-
当温度为2时,概率为[0.27, 0.73]。模型选择B的概率为73%。
温度越高,模型选择最明显的值(logit最高的值)的可能性就越低,这会使模型输出更具创造性,但会潜在降低输出的一致性。温度越低,模型选择最明显的值的可能性就越高,这会使模型输出更加一致,但同时也会使模型输出更加单一。
下图展示了不同温度下,词元B的softmax概率。随着温度接近于0,模型选择词元B的概率越来越接近1。在我们的例子中,当温度低于0.1时,模型几乎总是输出B。模型提供者通常会将温度限制在0到2之间。如果有自己的模型,你可以使用任何非负的温度值。在创造性任务中,人们通常会将温度设置为0.7,这样可以在创造性和确定性之间取得平衡,但你应该进行实验,以此找到最适合自己的温度。
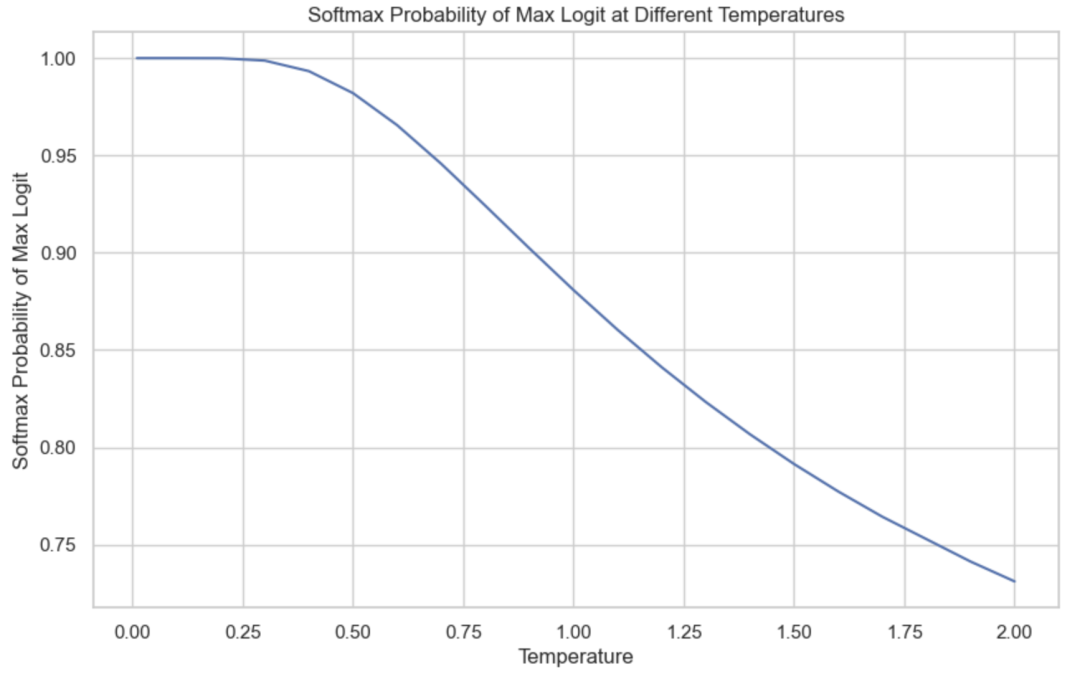
为使模型输出更加一致,我们通常会将温度设置为0。从技术上讲,温度永远不能为0,因为logits不能被0除。在实际操作中,当我们将温度设置为0时,模型总会选择具有最大logit值的词元,例如执行一个argmax操作,而非执行logit调整和softmax计算。
查看模型对给定输入计算的概率是常见的AI模型调试技术。例如,如果概率看起来是随机的,那么该模型并没有学到太多内容。OpenAI返回其模型生成的概率作为logprobs。Logprobs是log probabilities(对数概率)的缩写,是以对数尺度(log scale)表示的概率。在处理神经网络概率时,对数尺度更受欢迎,因为它有助于减少下溢(underflow)问题。语言模型可以处理10万个词汇大小的词汇表,这意味着许多词元的概率可能过小,无法由计算机表示。这些小数可能会被舍入为0。对数尺度有助于减少这一问题。
Top-k
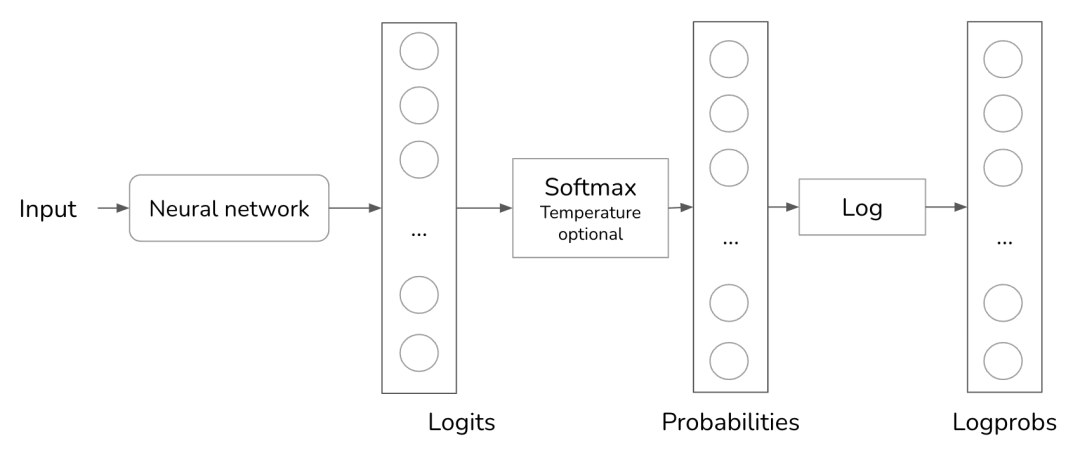
Top-k是一种采样策略,能在不过多牺牲模型响应多样性的情况下减少计算负载。回想一下,为了计算所有可能值的概率分布,需要使用softmax层。Softmax需要两次遍历所有可能的值:一次用于执行指数求和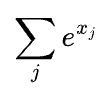 ,另一次用于对每个值执行
,另一次用于对每个值执行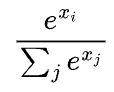 。对于词汇量大的语言模型来说,这个过程的计算成本很高。
。对于词汇量大的语言模型来说,这个过程的计算成本很高。
为避免计算负载过大问题,在模型计算出logit之后,我们会选择排名前k的logit,并仅对这些logit执行softmax。根据应用的多样性需求,k的取值可以在50到500之间,这远小于模型的词汇表大小。然后模型会从这些排名前K的数值中采样。较小的k值会增加文本的可预测性,但相应地,这也会减少文本的趣味性,因为模型只能从一个较小的可能性词汇集中进行选择。
Top-p
在Top-k采样中,考虑的值的数量被固定为k。然而,这一数量应该视具体情况而定。例如,对于给定提示“你喜欢音乐吗?只回答是或否。”应该考虑两个值:是和否,而对于给定提示“生命的意义是什么?”,则应该考虑更多值。
Top-p采样(也称为核心采样)允许更动态地选择要从中采样的值。在Top-p采样中,模型按概率降序对最可能的下一个值求和,并在总和达到p时停止。只有在这个累积概率范围内的值才会被考虑。语言模型中常见的Top-p(核心)采样值通常介于0.9到0.95之间。例如,Top-p值为0.9意味着模型将考虑累积概率超过90%的最小的一组值。
假设所有词元的概率如下图所示。如果top_p=90%,那么只有”yes”和”maybe”会被考虑,因为它们的累积概率大于90%。如果top_p=99%,那么将考虑”yes”、”maybe”和”no”。
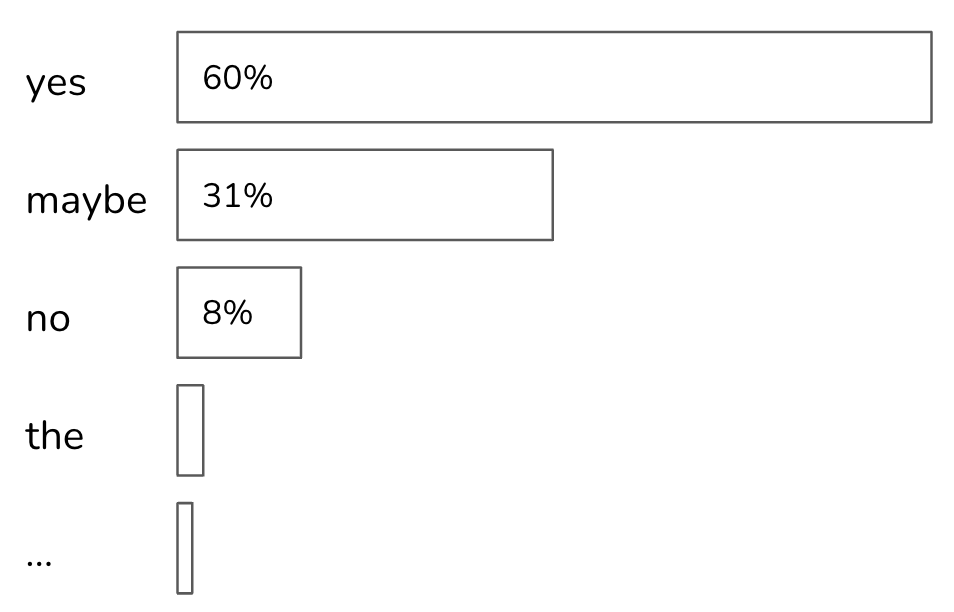
与top-k不同,top-p并不一定会减小softmax计算负载。但它的好处在于,由于它仅关注每个上下文中最相关的一组值,因此能够使输出更符合上下文。从理论上看,top-p采样似乎并没有太多优势。然而,在实践中,top-p已被证明效果良好,其受欢迎程度正不断攀升。
停止条件
自回归语言模型通过逐个生成词元来生成词元序列。较长的输出序列需要更多时间和计算资源(金钱),有时会让用户感到厌烦。因此,我们可能需要为模型设置一个停止生成序列的条件。
有两种简单的方法可以停止生成序列。第一种方法是在生成固定数量的词元后要求模型停止,这种方法的缺点是输出很可能会在句子中途被截断。另一种方法是使用停止词元(stop token),例如,可以要求模型在遇到””时停止生成。停止条件有助于降低时延和成本。
2
测试时采样
提升模型性能的一种简单方法是生成多个输出,并选择其中的一个最佳输出。这种方法名为“测试时采样(test time sampling)”或“测试时计算(test time compute)”。我认为“测试时计算”这个术语会产生歧义,因为它可能被解释为运行测试所需的计算量服务器托管。
你可以向用户展示多个输出,让他们选择最适合自己的输出,或设计一种选择最佳输出的方法。如果你希望模型响应保持一致,就需要保持所有采样变量不变。然而,如果要生成多个输出,并选择最佳输出,就不应该改变采样变量。
选择概率最高的输出是一种输出选择方法。语言模型的输出是一个词元序列,每个词元都由模型计算得出概率。输出的概率是输出中所有词元概率的乘积。
以词元序列[I, love, food]为例:
-
I的概率为0.2
-
给定I的情况下,love的概率为0.1
-
给定I和love的情况下,food的概率为0.3
因此,上述序列的概率为:0.2 * 0.1 * 0.3 = 0.006。
用公式可以表示为:
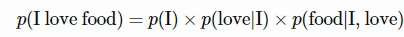
记住,在对数扩展上处理概率更为容易。乘积的对数等于对数之和,因此词元序列的对数概率是序列中所有词元的对数概率之和。
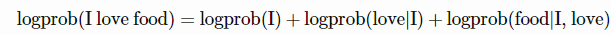
对数概率进行求和,较长的序列可能具有较低的总对数概率(log(1) = 0,而所有小于1的正值的对数均为负数)。为避免输出偏向短序列,我们将总和除以其序列长度来使用平均对数概率。在采样多个输出之后,我们选择具有最高平均对数概率的输出。截至目前,这就是OpenAI API所使用的方法。你可以将参数best_of设置为一个特定值(比如10),以使OpenAI的模型从10个不同输出中,返回具有最高平均对数概率的输出。
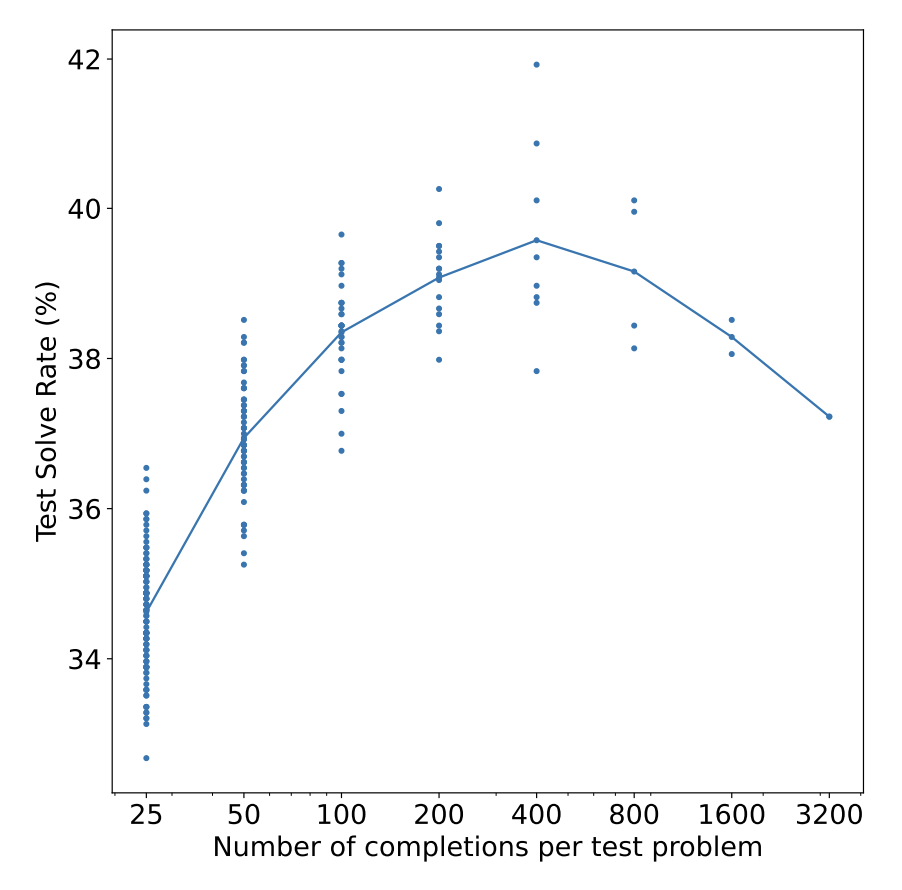
如前文所述,另一种输出选择方法是使用奖励模型为每个输出评分。回顾一下,Stitch Fix和Grab都根据奖励模型或验证器给出高分输出。OpenAI也训练了验证器,以帮助模型选择数学问题的最佳解决方案(Cobbe 等,2021)。他们发现,采样的输出越多,性能就会越好,但这种方式对性能的提升有限,只能达到某个特定的点。在他们的实验中,性能提升上限为400个输出,超过400,性能就会开始下降,如下图所示。他们假设随着采样输出数量的增加,找到欺骗验证器的对抗性输出的概率也会增加。虽然这是一个有趣的实验,但在生产实践中,为每个输入采样400个不同输出并不现实,因为这样做的成本过于高昂。
你还可以根据应用需求,选择启发式方法。如果你的应用程序受益于更短的回复,就可以选择最短的回复;如果应用程序是将自然语言转换为SQL查询,就可以选择最高效的有效SQL查询。
对于期望得到确切答案的任务,采样多个输出可能会很有用。例如,给定一个数学问题,模型可以多次求解,并选择出现频率最高的答案作为最终解决方案。同样地,对于多选题,模型可以选择出现频率最高的选项作为输出。这就是谷歌在MMLU(多项选择题基准)上评估Gemini模型性能时采用的方法。他们为每个问题采样了32个输出。虽然这样做有助于Gemini在这一基准测试中获得高分,但尚不清楚他们的模型是否比另一个模型好(后者只为每个问题生成一个输出)。
模型越反复无常,采样多个输出的收获就越多。然而,对于一个反复无常的模型,最好的做法是将其替换为另一个模型。在一个项目中,我们使用人工智能从产品图像中提取特定信息,发现对于相同图像,我们的模型只能在50%的情况下读取信息。另外50%的情况下,模型会报告图像太模糊或文字太小无法读取。对于每张图像,我们最多向模型查询三次,直到它能够提取信息。
虽然我们通常可以通过采样多个输出来提升模型性能,但这一成本十分高昂。平均而言,生成两个输出的成本大约是生成一个的两倍。
3
结构化输出
在实际生产中,我们经常需要模型按照特定格式生成文本。结构化输出在以下两种场景中至关重要。
-
输出需要遵循特定语法的任务。例如,对于文本转SQL或文本转正则表达式,输出必须是有效的SQL查询和正则表达式。对于分类任务,输出必须是有效的类别。
-
输出随后将由下游应用程序解析的任务。例如,假设你使用AI模型撰写产品描述,只希望提取单纯的产品描述,不包括“这是描述”或“作为语言模型,我不能……”等冗余文本。对于这种场景,理想情况下模型应该生成结构化输出,例如带有特定键的JSON,以便解析。
OpenAI是第一个在其文本生成API中引入JSON模式的模型供应商。需要注意的是,他们的JSON模式仅保证输出是有效的JSON格式,而不保证JSON的内容。截至目前,OpenAI的JSON模式尚不适用于视觉模型,但这只是时间问题。
因为模型的停止条件(例如达到最大输出词元长度),生成的JSON也可能被截断。如果最大词元长度设置得太短,输出的JSON可能会被截断,因此无法被解析。如果设置得太长,模型的响应会变得慢且昂贵。
guidance(github.com/guidance-ai/guidance)和outlines(github.com/outlines-dev/outlines)等独立工具可帮助结构化某些模型输出。以下是使用guidance生成受限于一组选项和正则表达式的输出的两个示例。

如何生成结构化输出
你可以在人工智能技术栈的不同层级上引导模型生成受限的输出,例如在提示、采样和微调过程中。目前,提示是最简单但效果最差的方法。你可以指示模型输出遵循特定模式的有效JSON。然而,并不能保证模型总是会遵循这一指令。
目前,微调是使模型生成想要的风格和格式化输出的首选方法。改变或不改变模型架构都可微调。例如,可以在具有所需输出格式的示例上对模型进行微调。虽然这仍不能保证模型总是能够输出预期的格式,但相比提示要可靠得多。此外,这还可以降低推理成本,因为不需要在提示中包含所需格式的说明和示例。
对于某些任务,你可以通过修改模型架构来进行微调,以保证输出格式。例如,对于分类任务,可以将分类器head加到基础模型的架构中,以确保模型仅输出预先指定的类别之一。在微调过程中,你可以重新训练整个架构或仅训练这个分类器head。
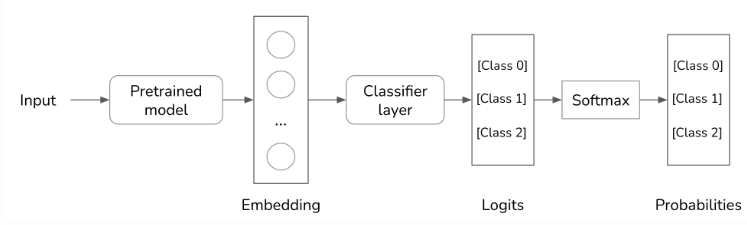
由于我们假设模型本身无法完成此任务,因此需要采用采样和微调技术。随着模型变得更加强大,我们可以期待它能够更好地遵循指令。在未来,使模型在最少的提示下输出我们所需的内容将变得更为容易,这些技术(提示、采样、微调)将不再那么重要。
约束采样
约束采样是一种用于引导文本生成朝向特定约束的技术。正如在“测试时采样”一节中所讨论的,持续生成输出直至找到符合约束条件的输出是最简单的方式,但成本高昂。
约束采样也可以在词元采样过程中进行。据我所知,目前介绍公司如何进行约束采样的文献并不多。以下内容是我的个人见解,可能存在错误,欢迎反馈和指正!
总的来说,为生成一个词元,模型会在满足约束条件的值中采样。回想一下,为了生成一个词元,你的模型首先会输出一个逻辑向量,其中每个逻辑对应一个可能的值。通过约束采样,我们会过滤这个逻辑向量,只保留符合约束条件的值。然后从这些有效值中采样。
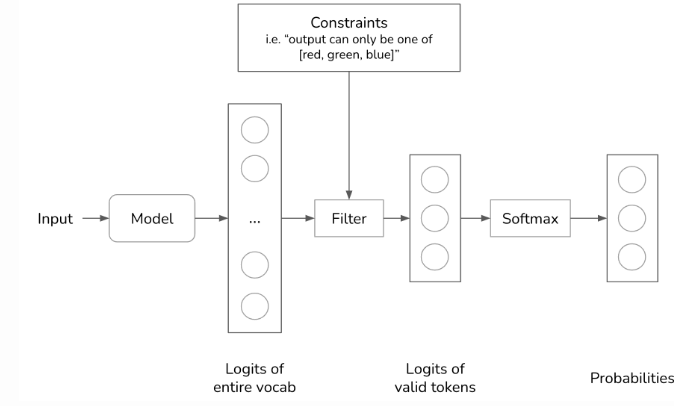
在上述例子中,约束条件很容易过滤。然而,在大多数情况下,过滤并非如此简单。我们需要一种语法规则来明确每个步骤能做什么、不能做什么。例如,JSON语法规定,在 { 后面不能出现另一个 {,除非它是字符串的一部分,例如{“key”: “”}。
建立这种语法规则并将其纳入采样过程中是一项非常复杂的任务。我们需要为每种所需的输出格式(如JSON、正则表达式、CSV等)建立一种单独的语法。一些人反对约束采样,因为他们认为最好将约束采样所需资源用于训练模型,让模型更好地遵循指令。
4
结论
我相信,对于那些希望利用人工智能解决问题的人来说,理解AI模型采样输出的方式十分重要。概率很神奇,但也可能令人困惑。撰写本文的过程非常有趣,因为它让我有机会深入探讨长期以来一直很感兴趣的众多概念。

本文分享自微信公众号 – OneFlow(OneFlowTechnology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
本文分享自华为云社区《Go并发范式 流水线和优雅退出 Pipeline 与 Cancellation》,作者:张俭。 介绍 Go 的并发原语可以轻松构建流数据管道,从而高效利用 I/O 和多个 CPU。 本文展示了此类pipelines的示例,强调了操作失败时…
