

作者 | 文燕
导读
在互联网行业里,业务迭代很快,系统变更频繁,尤其长青业务随着时间会积累越来越多历史包袱。阿拉丁作为百度搜索垂直化的产品,业务历经多年更迭,历史包袱很多,在应对大事件比如高考、东京奥运会、北京冬奥会的大流量时业务集群面临很大挑战。以高考来说,从2013年开始百度做高考,经过11年的坚持和沉淀,如今高考阿拉丁直接承接用户搜索高考相关内容的数十亿pv的流量,积累多年的系统因其复杂度而面临巨大的稳定性风险。为了应对高考等大事件的巨大流量,联合多方快速建立了保障机制,本文结合实践做了归纳和总结。
全文3087字,预计阅读时间8分钟。
01 保障思路
大事件的流量很大且有很强时效性,在保障时尤其要注意系统瞬时扛压能力。像每年高考的作文题,总是社会舆论热点,每个省份的高考查分、分数线公布的时间点都是瞬时热度极高。而奥运会这类体育赛事的热点事件难以预料,有时候是乒乓球半决赛焦灼,有时候是弱势项目突然夺冠,关注事件的用户不仅仅是平时活跃的几百万运动爱好群体,也有热点爆发后大量新增关注的用户,也就导致瞬时流量峰值难以预料,用户对我们赛事数据的时效性要求也很高,最好的体验是赛事数据实时更新,这些方方面面汇聚到一起,使得大事件保障比寻常保障工作难度大。常规思路包含3个方面:
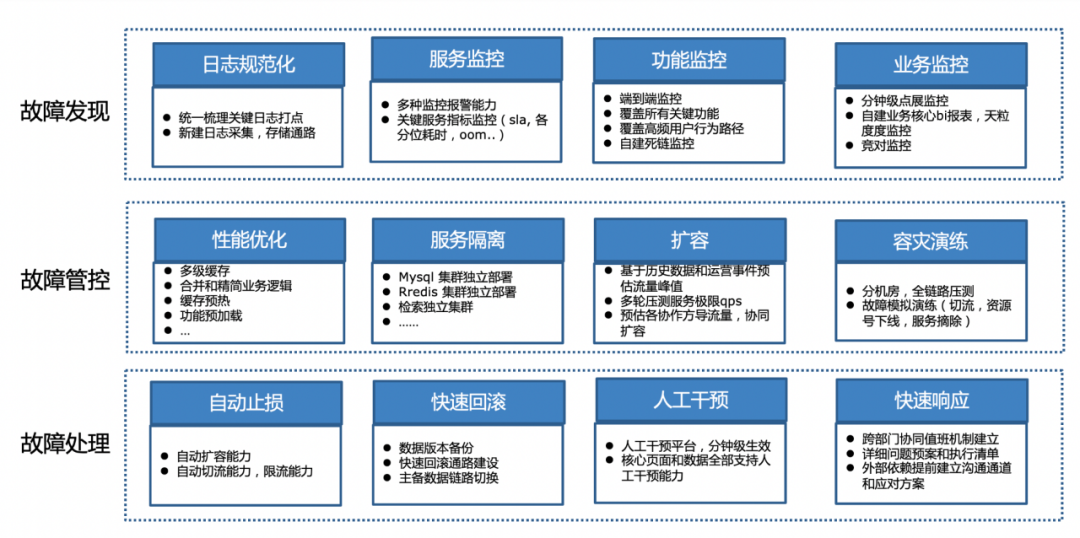
02 故障发现
常规做法首先是详细梳理业务模型、依赖的上下游、依赖强弱程度、数据链路,同时做好隐患排查和修复、日志的规范这些方面。在大事件保障时,需要针对不同的热点事件单独梳理其独特的依赖链路:
(1)上下游负责人,提前通告热点时间和影响范围、做好紧急预案。
(2)依赖的功能点,明确热点事件里用户关注的哪些功能点用了哪个业务方或架构提供的哪个能力,在热点发生前就密切关注流量走势。
(3)预估不同热点事件的峰值QPS,根据依赖程度和功能点评估上下游的峰值QPS,提前做好扩容和准备降级方案,预留紧急扩容的资源。
(4)排查不同热点事件对应的核心功能点的代码是否足够健壮,梳理上下游瓶颈点,做好风险预案、降级预案。
(5)为快速定位热点事件的业务、数据链路故障点,规划日志打点,方便构建针对性的业务监控和报警。
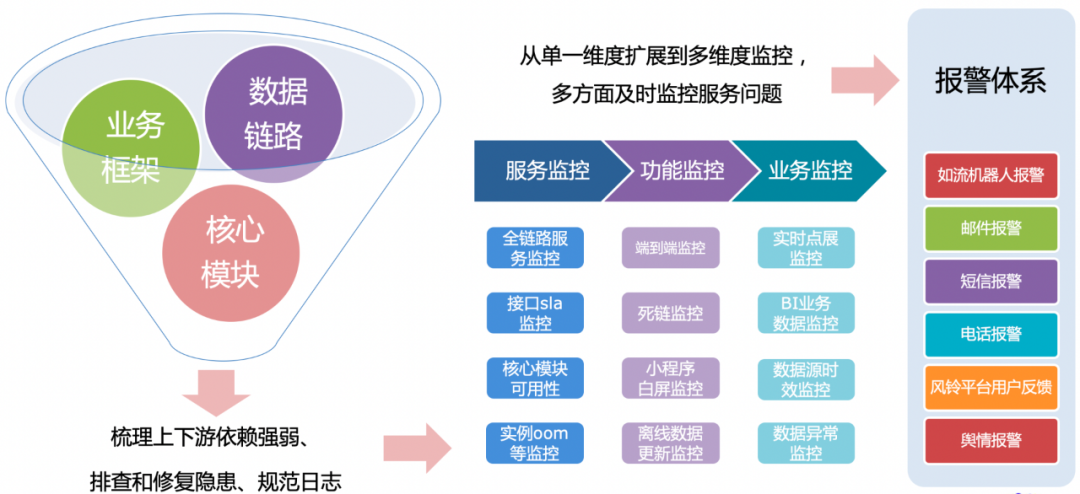
常规保障的第二方面是构建多维度多视角地监控体系,如上图所示的功能、业务等监控。大事件不仅要做到及时发现故障,更需要快速感知用户体验问题,同时能实时关注与官方数据的差异。所以,我们围绕热点事件及其核心功能包含的数据时效来设定监控的内容、频率。从数据源头开始设定尽可能短的更新时间,在数据处理过程的各个环节做好异常的实时报警和应对预案,实时监控多地域多机房在端到端效果上的差异,实现了整个数据链路的时效感应和保障。
03 故障管控
在做到及时发现故障的同时,还需要做到能有效控制故障影响范围,也就是故障管控。常规的管控措施包括故障隔离、性能优化、问题预案、故障演练。大事件时期,各方面都围绕热点事件展开。
(1)故障隔离
在大事件过程中,围绕热点事件相关核心模块做故障隔离,包含业务的隔离、还有依赖的各服务的隔离、存储层的隔离。除了常规的存储和业务隔离,还针对性地补强了核心模块。
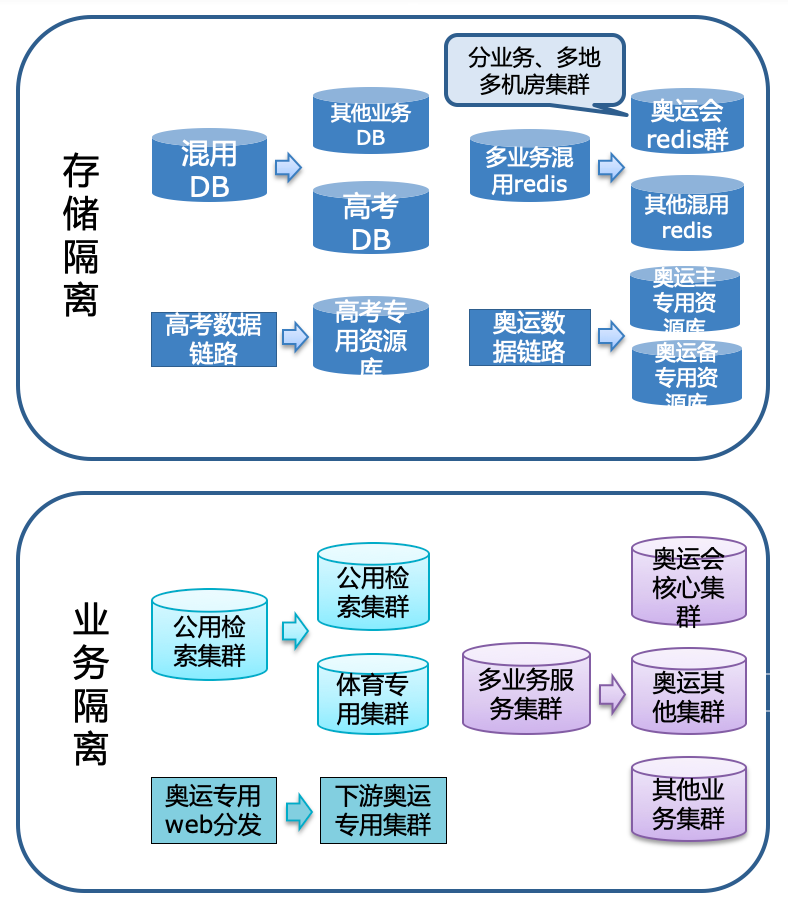
比如奥运会的核心模块预估qps达到数十万qps,这个流量超出NBA最热门赛事峰值、对部分服务来说超出2019年百度APP红包活动的流量,服务集群乃至相关架构都很难直接承接这么大的流量,而且核心服务的下游还有流量被放大的特性。为此,我们做了全链路多级缓存,在核心服务里利用redis来直接承接流量。考虑到redis在单集群模式下承担的流量达不到预估峰值,所以依据业务特点、流量分布、现有redis集群性能上限,为奥运搭建了多地多redis集群来一起承接奥运总体流量。
(2)性能优化
当前服务集群能否支撑大事件峰值流量,依赖的上下游又能否支撑峰值流量?我们要确保这些方面不存在问题,就需要将前面梳理的内容运用起来,通过预估大事件不同热点事件的峰值流量,评估各服务状态怎么支撑预估的流量,对服务链路的瓶颈做性能优化。
首先基于历史数据、运营活动安排、梳理热点事件等评估搜索链路的各模块流量峰值。比如我们预估东京奥运会流量时,发现2016年奥运的数据太久远、参考性不高,做预估时就参考了2021年NBA等热点赛事的流量,同时针对奥运业务框架和产品特点分别对各种搜索场景、前端页面做了细致的流量预估。
确定预估的峰值之后,就开始评估服务链路上各模块是否需要扩容、需要扩多少,然后在大事件之前做好扩容。扩容的范围不只是当前服务链路,还有各业务协同方的服务集群。
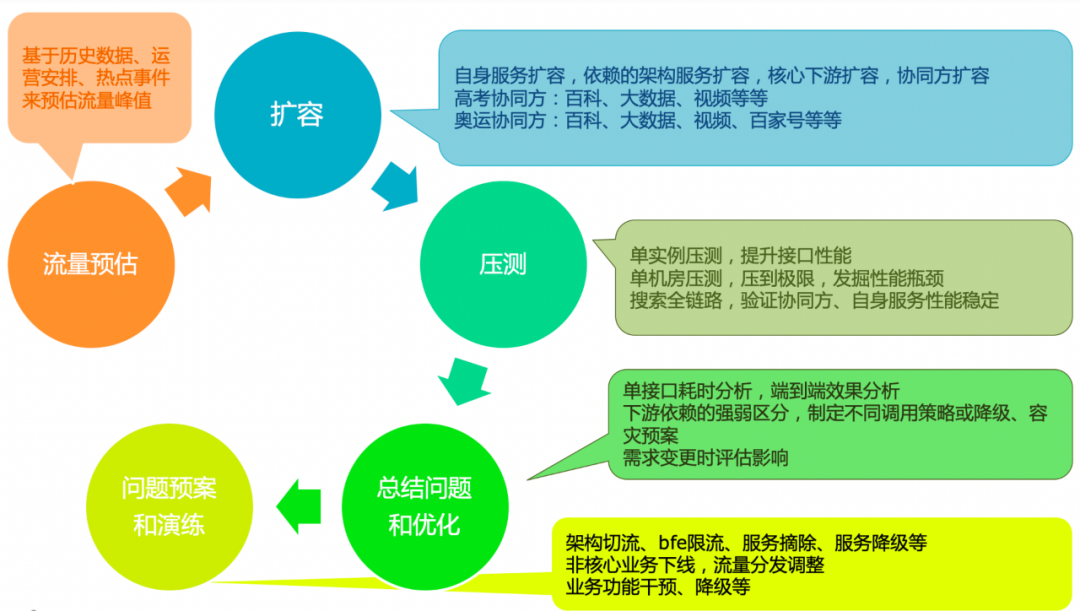
为了验证扩容后能支撑预估流量,我们根据预估qps做了分阶段的多轮压测,模拟真实流量来进一步排查服务中的风险点,发掘性能瓶颈点。发现瓶颈点后,做核心业务算法或业务逻辑优化、清除冗余代码、业务逻辑瘦身、数据拆分、分级缓存等,结合搜索架构的优化一起提升性能。
(3)问题预案
通过前面的工作,汇总出不同热点事件相关服务全链路的问题预案,应对系统的各个风险。问题预案包含服务、风险、降级、干预这4个方面,从数据到功能、服务都有针对性的应对措施。
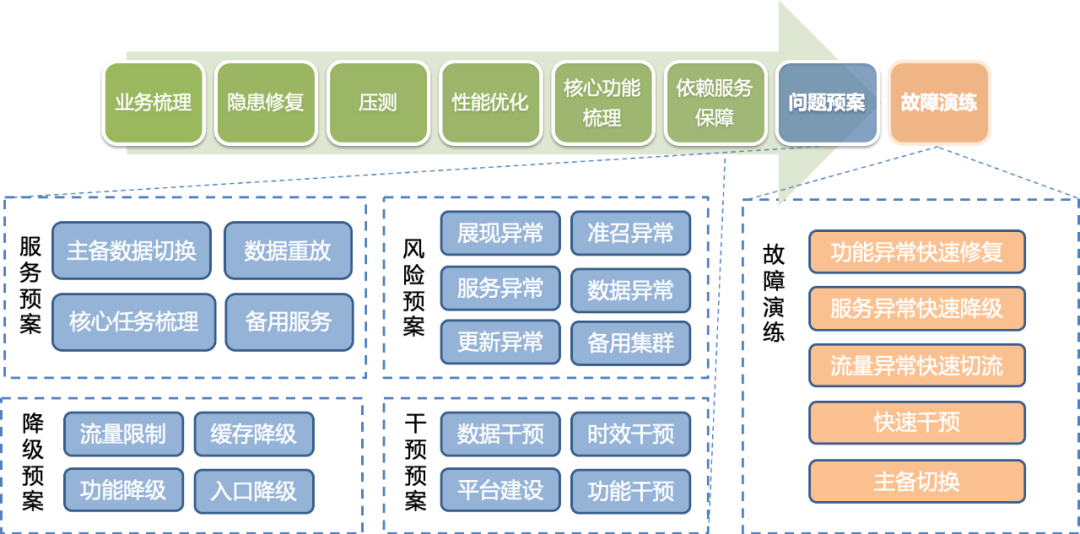
(4)故障演练
梳理完问题预案后,围绕热点事件的核心功能做故障注入、故障修复演练,验证预案有效性和生效速度。
04 故障处理
在做到及时发现故障、有效故障管控后,在大事件过程中还要做到故障处理有效得当。首先要成立大事件快速响应值班群,与服务链路各方负责人、协同方负责人提前沟通热点事件前后的故障响应预案。然后服务器托管网与运维部门合作做好服务集群运维、故障实例自动下线,在热点流量突增时随时根据各方面监控情况做切流、限流甚至是部分功能降级。大事件期间会收到各方面包括用户的反馈,遇到反馈功能出问题等在前面已经做好了人工干预预案的方面,就可通过干预快速解决。一些人工干预覆盖不了的问题、一些紧要产品迭代仍然需要开发后上线,这时候快速拉齐协同团队配合上线。
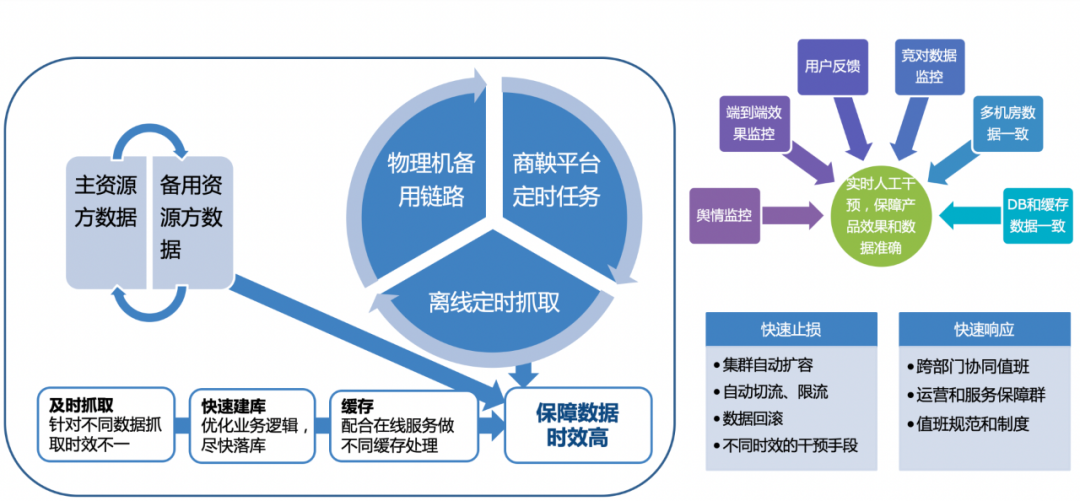
除了上面提到的常规故障处理,我们还要考虑大事件的核心功能特性而制定对应方案。在高考、奥运会、冬奥这些大事件中,数据时效性是用户最关注的方面,也是产品竞争力的核心体现。除了前面提到的监控和预案,我们准备了主备两条数据资源方、快速切换并混合使用各自时效性最高的内容,同时搭建3种离线处理平台、故障时快速切换。我们建立了实时人工干预平台,根据产品效果监控、用户反馈、服务监控等各方面指标判断是否人工干预,最大程度保障产品效果和数据准确。
05 总结与思考
通过上面的举措,高考、东京奥运会、北京冬奥会期间,搜索阿拉丁相关服务的稳定性保持在99.99%+,数据更新速度与官方数据几乎同步,不仅仅保障了大事件的稳定性,还确保了我们的产品有很好的用户体验。
搜索阿拉丁涉及很多服务,面对大事件时需要考虑和准备的方面也很多,本文从故障发现、故障管控、故障处理三方面阐述了如何做稳定性保障。大事件各有特点,核心业务服务链路也有不同程度的技术负债和改造难点,如果平时业务迭代时就注重稳定性建设,能减少应对大事件的峰值流量而改造的难度。
目前『搜索产品研发工程师』岗位正在热招,主要为搜索产研后端,AI生态与架构方向工作。
欢迎有兴趣的同学投递简历至 yangye01@baidu.com
——END——
推荐阅读
百度搜索万亿规模特征计算系统实践
通过Python脚本支持OC代码重构实践(三):数据项使用模块接入数据通路的适配
百度搜索智能化算力调控分配方法
UBC SDK日志级别重复率优化实践
百度搜索深度学习模型业务及优化实践
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
