
目录
摘要
一、引言
二、 数据源介绍
三、 数据清洗和预处理
3.1 缺失值处理
3.2异常值处理
3.3 数据编码
四、 探索性数据分析
4.1 可视化相关统计量
4.2 目标数据的分布情况
4.3 Pearson 相关性分析
五、 特征工程
5.1 特征构造
5.1.1 总饮酒量
5.1.2 整体关系质量
5.1.3 总休闲时间
5.1.4 总教育支持
六、 模型选择
6.1 建立baseline
6.2 选择训练模型
6.2.1 逻辑回归
6.2.2 SVM支持向量机
6.2.3 朴素贝叶斯分类器
6.2.4 决策树
6.2.5 随机森林分类
6.2.6 梯度提升分类
6.2.7 人工神经网络
6.3 查看模型得分
七、 模型调参
7.1 随机搜索——缩小超参数范围
7.2网格搜索——精确超参数范围
7.3 学习曲线
7.4 验证曲线
八、特征筛选
8.1 特征重要性排序
8.2 特征选择
九、 评估指标
9.1 模型性能
9.2 模型评估
十、 结论
10.1 影响因素
10.2 期望
参考文献
写在前面:本文的数据分析的文件来源:Student Performance Prediction
摘要
本报告旨在利用机器学习方法,对包含学生成绩、人口统计、社会和学校相关特征的数据集进行分析和预测,预测学生在数学和葡萄牙语两个科目中的成绩。数据通过学校报告和问卷收集。报告将详细阐述数据预处理、特征选择、模型训练、结果评估等步骤,并给出分析结论。
在数据预处理阶段,本文对数据进行了统计分析,可视化相关统计量,以了解数据的整体特征和规律。同时,本文还分析了目标数据的分布情况,判断数据集是否失衡。为了进一步优化数据,本文进行了特征工程,对部分特征变量进行了编码。
在模型选择方面,本文对比了多种机器学习模型,包括逻辑回归、支持向量机、朴素贝叶斯分类器、决策树、随机森林分类、梯度提升分类和人工神经网络等。通过对比基础模型的得分,本文初步评估并选择了梯度提升分类树模型来预测“数学”数据集, 而“葡萄牙语”数据集则选择了逻辑回归模型。
在模型参数调整阶段,本文针对每个模型进行了重要的超参数调整。通过随机搜索和网格搜索的方法,本文缩小了超参数的范围并最终确定了最优的超参数组合。此外,本文还绘制了学习曲线和验证曲线,以进一步优化模型性能。
在模型评估阶段,本文对原始模型以及经过参数调整优化后的模型进行了全面评估。本文对数据集的特征进行了重要性排序,并重新检测了特征选择后的模型是否优化并进行了评估。最后,本文确定了模型最终的特征变量,并得出了结论,提供了有价值的参考信息。
关键词: 机器学习 梯度提升分类树 逻辑回归 随服务器托管网机搜索 网格搜索
一、引言
基于机器学习的学生成绩预测已成为一个研究热点。机器学习能够通过分析大量的历史数据,找出数据之间的潜在关联和规律,进而对学生未来的成绩进行准确预测。本报告将利用机器学习的方法,对两所葡萄牙学校的学生成绩进行深入的分析和预测。我们将利用已有的数据集,包括学生成绩、人口统计、社会和学校相关特征等,构建和训练预测模型。这些数据通过学校报告和问卷收集,涵盖了多个维度,为我们的预测提供了全面的信息。
在教学过程中,教师难以了解每位学生的知识掌握情况;而且,传统的统计挂科方式一般在课程结束后进行预警,具有滞后性,已无法满足高校培养新时代高质量人才的需求。随着数字化校园的建设,高校积累了大量的学生数据,通过分析学生生活学习数据,预判学生未来的学习成绩,实现从简单的查询到预测性分析的转变,可以提前为在校生提供预警,从而提高教学质量,促进智慧校园的发展。[1]
二、 数据源介绍
| 变量 | 描述 |
|---|---|
| school | 学生的学校 |
| sex | 学生的性别 |
| age | 学生的年龄 |
| address | 学生的家庭住址类型 |
| famsize | 家庭规模 |
| Pstatus | 父母同居状况 |
| Medu | 母亲的教育 |
| Fedu | 父亲的教育 |
| Mjob | 母亲的工作 |
| Fjob | 父亲的工作 |
| reason | 选择学校的理由 |
| guardian | 学生监护人 |
| traveltime | 从家到学校的时间 |
| studytime | 每周学习时间 |
| failures | 过去的类失败次数 |
| schoolsup | 额外的教育支持 |
| famsup | 家庭教育支持 |
| paid | 课程科目内的额外付费课程 |
| activities | 课外活动 |
| nursery | 就读托儿所 |
| higher | 想接受高等教育 |
| internet | 在家上网 |
| romantic | 与恋爱关系 |
| famrel | 家庭关系质量 |
| freetime | 放学后的空闲时间 |
| goout | 与朋友外出 |
| Dalc | 工作日饮酒量 |
| Walc | 周末饮酒量 |
| health | 当前健康状况 |
| absences | 缺勤人数 |
该数据接近两所葡萄牙学校在中学教育中的学生成绩。数据属性包括学生成绩、人口统计、社会和学校相关特征,并使用学校报告和问卷收集。
提供了两个关于两个不同科目表现的数据集:数学和葡萄牙语。这两个数据集在二元分类下进行建模。
三、 数据清洗和预处理
# 导入所需库
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from functools import reduce
from sklearn.model_selection import train_test_split
# 机器学习模型
from sklearn.linear_model import LogisticRegression#逻辑回归
from sklearn.svm import SVC, LinearSVC#支持向量机
from sklearn.neighbors import KNeighborsClassifier#KNN
from sklearn.naive_bayes import GaussianNB#朴素贝叶斯
from sklearn.neural_network import MLPClassifier#人工神经网络
from sklearn.tree import DecisionTreeClassifier#决策树
from sklearn.ensemble import GradientBoostingClassifier#梯度提升分类树
from sklearn.ensemble import RandomForestClassifier#随机森林
from sklearn.model_selection import KFold, cross_validate
# 超参数调整
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
#分层交叉验证
from sklearn.model_selection import StratifiedKFold
#评估分类性能
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_curve,auc
from sklearn.metrics import classification_report
from sklearn.metrics import precision_score, recall_score, f1_score
#绘制学习曲线、验证曲线
from sklearn.model_selection import learning_curve,validation_curve
# 忽略警告
import warnings
warnings.filterwarnings("ignore")# 数学
data_mat = pd.read_csv("mat2.csv")
# 葡萄牙语
data_por = pd.read_csv("por2.csv")3.1 缺失值处理
在缺失值处理方面,本文利用Python的isnan函数寻找两个数据集的缺失值,最终没有发现缺失值。
# 检查数据
# data_mat.info()
# data_por.info()
# 检查缺失值
print(data_mat.isnull().sum())
print(data_por.isnull().sum())3.2异常值处理
在异常值处理方面,经过 3- 原则的处理,认为该数据集无异常值。
3.3 数据编码
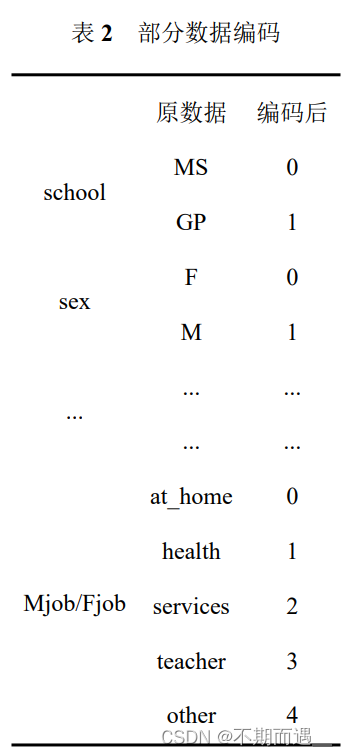
为了适应分析工具的要求和确保数据的一致性,本文对某些变量进行了转换,保持数据类型的一致。
# 将类别转换为数值型
# 数学
data_mat['school']=data_mat['school'].replace({'GP':1,'MS':0})
data_mat['sex']=data_mat['sex'].replace({'M':1,'F':0})
data_mat['address']=data_mat['address'].replace({'U':1,'R':0})
data_mat['famsize']=data_mat['famsize'].replace({'GT3':1,'LE3':0})
data_mat['Pstatus']=data_mat['Pstatus'].replace({'T':1,'A':0})
data_mat['Mjob']=data_mat['Mjob'].replace({'at_home':0,'health':1,'services':2,'teacher':3,'other':4})
data_mat['Fjob']=data_mat['Fjob'].replace({'at_home':0,'health':1,'services':2,'teacher':3,'other':4})
data_mat['reason']=data_mat['reason'].replace({'home':0,'course':1,'reputation':2,'other':3})
data_mat['guardian']=data_mat['guardian'].replace({'mother':0, 'father':1, 'other':2})
feature = ['schoolsup','famsup','paid','activities','nursery','higher','internet','romantic']
data_mat[feature]=data_mat[feature].replace({'no':0, 'yes':1})
# 葡萄牙语
data_por['school']=data_por['school'].replace({'GP':1,'MS':0})
data_por['sex']=data_por['sex'].replace({'M':1,'F':0})
data_por['address']=data_por['address'].replace({'U':1,'R':0})
data_por['famsize']=data_por['famsize'].replace({'GT3':1,'LE3':0})
data_por['Pstatus']=data_por['Pstatus'].replace({'T':1,'A':0})
data_por['Mjob']=data_por['Mjob'].replace({'at_home':0,'health':1,'services':2,'teacher':3,'other':4})
data_por['Fjob']=data_por['Fjob'].replace({'at_home':0,'health':1,'services':2,'teacher':3,'other':4})
data_por['reason']=data_por['reason'].replace({'home':0,'course':1,'reputation':2,'other':3})
data_por['guardian']=data_por['guardian'].replace({'mother':0, 'father':1, 'other':2})
feature = ['schoolsup','famsup','paid','activities','nursery','higher','internet','romantic']
data_por[feature]=data_por[feature].replace({'no':0, 'yes':1})
# 也可以进行标签编码或独热编码等本文展示部分特征变量的编码过程如下所示。
四、 探索性数据分析
4.1 可视化相关统计量
本文首先计算了一系列描述性统计量,包括均值、中位数等,以了解各变量的分布情况。
# 数学
# 去除'Unnamed: 0'列
data_mat = data_mat.drop(['Unnamed: 0'],axis = 1)
# 查看数据描述
data_desc = data_mat.describe()
# 去除'count'行
data_desc = data_desc.drop(['count'],axis=0)
# 控制画布大小
plt.figure(figsize=(15,5))
# _,color_lists=generate_colors(7,'Paired')
i = 0
for col in data_desc.columns:
i+=1
ax = plt.subplot(2,7,i)
ax.set_title(col)
# plt.bar(data_desc.index,data_desc[col],color=color_lists)
# 对每个特征绘制describe柱状图
for j in data_desc.index:
plt.bar(j, data_desc.loc[j,col])
# 防止文字遮挡
plt.tight_layout()
plt.savefig('./可视化相关统计量(数学).png', bbox_inches = 'tight')
plt.show()# 葡萄牙语
# 去除'Unnamed: 0'列
data_por = data_por.drop(['Unnamed: 0'],axis = 1)
# 查看数据描述
data_desc1 = data_por.describe()
# 去除'count'行
data_desc1 = data_desc1.drop(['count'],axis=0)
# 控制画布大小
plt.figure(figsize=(15,5))
# _,color_lists=generate_colors(7,'Paired')
i = 0
for col in data_desc1.columns:
i+=1
ax = plt.subplot(2,7,i)
ax.set_title(col)
# plt.bar(data_desc.index,data_desc[col],color=color_lists)
# 对每个特征绘制describe柱状图
for j in data_desc1.index:
plt.bar(j, data_desc1.loc[j,col])
# 防止文字遮挡
plt.tight_layout()
plt.savefig('./可视化相关统计量(葡萄牙语).png', bbox_inches = 'tight')
plt.show()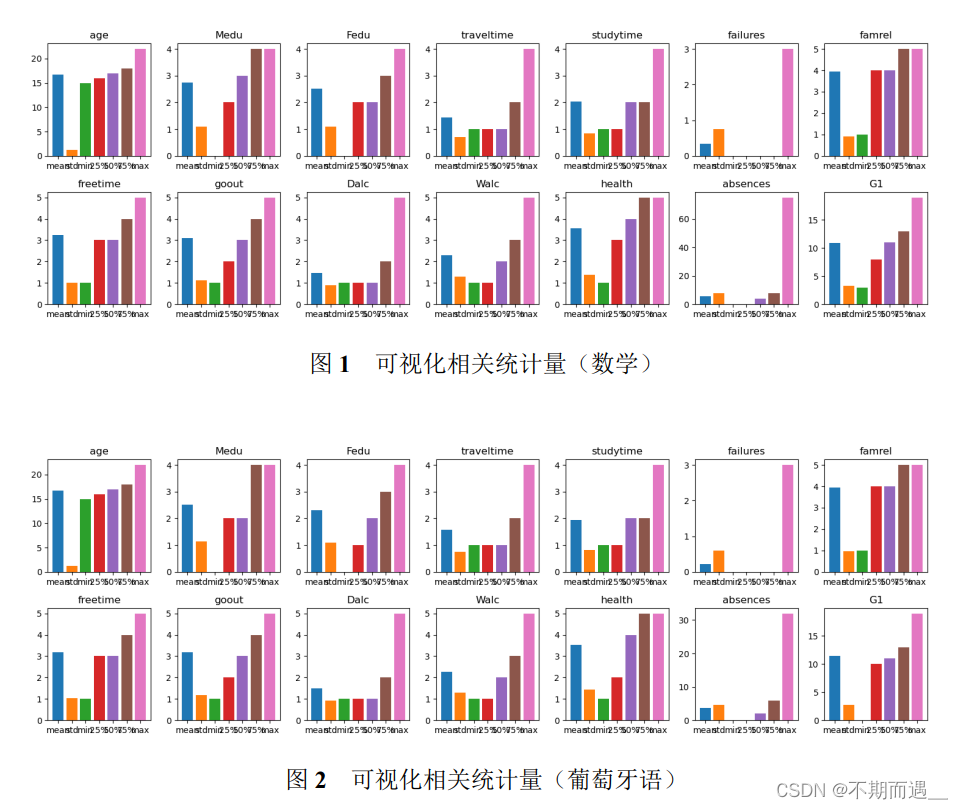
各特征数据分布较为正常,最小值、中位数、最大值是错落分布、正常分布的,未发现方差极小(接近0)的特征。
这些统计量可以帮助了解数据的整体特征和规律,为后续的数据处理和分析提供基础和支持。
4.2 目标数据的分布情况
在本次数据分析中,主要关注目标数据集的分布情况。本文选取了G1列数据,以及格分——12为分界点对数据进行二分类,以此为基础进行建模。
# 二分类
# 数学
data_mat['G1'] = data_mat.G1.apply(lambda x : '1' if x >= 12 else '0')
data_mat['G1']
# 葡萄牙语
data_por['G1'] = data_por.G1.apply(lambda x : '1' if x >= 12 else '0')
data_por['G1']
# 字体、符号设置
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 数学
# 绘制直方图
plt.style.use('fivethirtyeight')
plt.hist(data_mat['G1'],bins=3,edgecolor='k',density=False)
# 设置坐标轴标签
plt.xlabel('分数')
plt.ylabel('数量')
# 标题
plt.title('分布')
plt.savefig('./目标数据的分布情况(数学).png', bbox_inches = 'tight')
# 类别比例
# 数学
class_more = data_mat['G1'].value_counts().values[0]
class_less = data_mat['G1'].value_counts().values[1]
print('类别比例:',data_mat['G1'].value_counts().values/len(data_mat))
print('多数类与少数类比例:',class_more/class_less)
# 葡萄牙语
# 绘制直方图
plt.style.use('fivethirtyeight')
plt.hist(data_por['G1'],bins=3,edgecolor='k',density=False)
# 设置坐标轴标签
plt.xlabel('分数')
plt.ylabel('数量')
# 标题
plt.title('分布')
plt.savefig('./目标数据的分布情况(葡萄牙语).png', bbox_inches = 'tight')
# 类别比例
# 葡萄牙语
class_more1 = data_por['G1'].value_counts().values[0]
class_less1 = data_por['G1'].value_counts().values[1]
print('类别比例:',data_por['G1'].value_counts().values/len(data_por))
print('多数类与少数类比例:',class_more1/class_less1)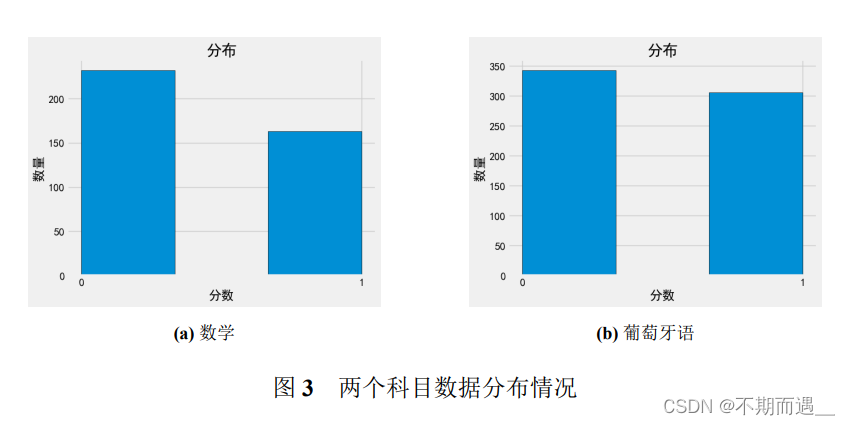
从上图中可以粗略看出目标数据的分布情况,类别比例展示如下。
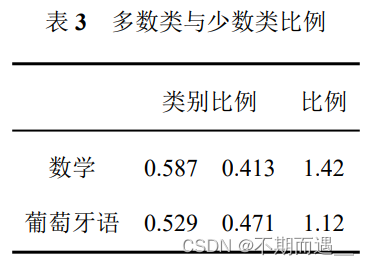
这样可以很明显看出所给数据是否失衡。 一般可以把失衡分为 3 个程度:
• 轻度:0.2-0.4
• 中度:0.01-0.2
• 极度:
目标变量是二元分类变量,从整体上看,样本在目标变量上的分布相当均匀,没有出现某一类别的样本数量远远超过其他类别的情况。
这说明数据没有明显的倾斜性,每一种类别都有足够的样本供分析和建模。这种分布均衡的数据集更有可能产生稳定和可靠的模型。
4.3 Pearson 相关性分析
按照统计学的定义,相关分析时研究两个或两个以上处于同等地位的随机变量的相关关系的统计分析方法。在数据分析中,相关分析常用来探测两组数据之间的相关关系,如变化趋势是否一致、是否存在正向或者负向联系以及关系的强弱如何等。
相关性分析是对变量两两之间的相关程度进行分析的一种统计方法。[2]本文选择Pearson相关系数对数据集进行分析,通过Python编程可以得出各特征变量之间的相关性。通过判断两个或多个变量之间的统计学关联,可以进一步分析关联强度和方向。
# 数学
data_corr = data_mat.corr()['G1'].sort_values()
# 打印相关性
# print(data_corr)
#相关性强度(绝对值)排序:降序
print(data_corr.abs().sort_values(ascending=False))
# 葡萄牙语
data_corr1 = data_por.corr()['G1'].sort_values()
# 打印相关性
# print(data_corr1)
#相关性强度(绝对值)排序:降序
print(data_corr1.abs().sort_values(ascending=False))本文仅展示两个数据集中相关程度较高的前五个特征变量。
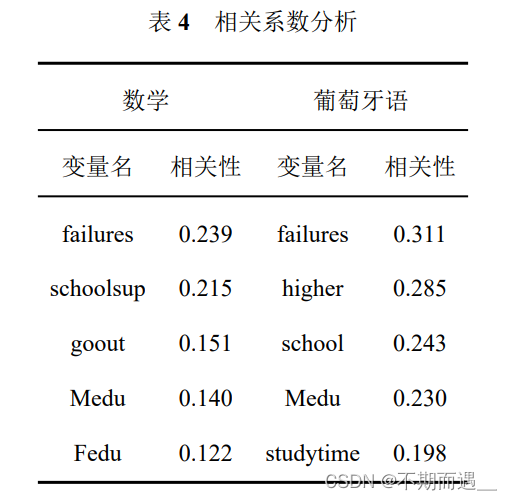
五、 特征工程
探索了数据集中各变量的关系后,可以根据上一步的结果来构建特征工程。
5.1 特征构造
data_mat['Talc'] = data_mat['Walc']+data_mat['Dalc']
data_mat = data_mat.drop(['Walc'],axis = 1)
data_mat = data_mat.drop(['Dalc'],axis = 1)
data_mat['TReq'] = data_mat['famrel']+data_mat['romantic']
data_mat = data_mat.drop(['famrel'],axis = 1)
data_mat = data_mat.drop(['romantic'],axis = 1)
data_mat['Tleisure'] = data_mat['freetime']+data_mat['goout']
data_mat = data_mat.drop(['freetime'],axis = 1)
data_mat = data_mat.drop(['goout'],axis = 1)
data_mat['Tsup'] = data_mat['schoolsup']+data_mat['famsup']
data_mat = data_mat.drop(['schoolsup'],axis = 1)
data_mat = data_mat.drop(['famsup'],axis = 1)
data_por['Talc'] = data_por['Walc']+data_por['Dalc']
data_por = data_por.drop(['Walc'],axis = 1)
data_por = data_por.drop(['Dalc'],axis = 1)
data_por['TReq'] = data_por['famrel']+data_por['romantic']
data_por = data_por.drop(['famrel'],axis = 1)
data_por = data_por.drop(['romantic'],axis = 1)
data_por['Tleisure'] = data_por['freetime']+data_por['goout']
data_por = data_por.drop(['freetime'],axis = 1)
data_por = data_por.drop(['goout'],axis = 1)
data_por['Tsup'] = data_por['schoolsup']+data_por['famsup']
data_por = data_por.drop(['schoolsup'],axis = 1)
data_por = data_por.drop(['famsup'],axis = 1)
data_mat.columns5.1.1 总饮酒量
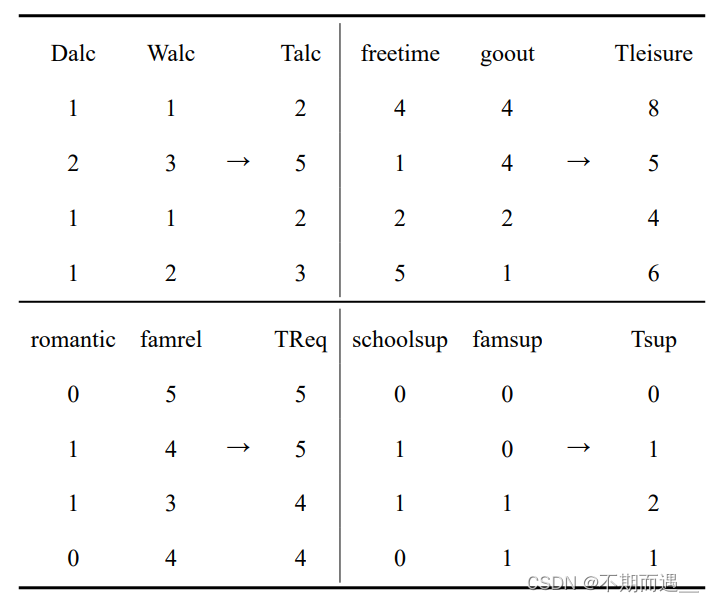
Dalc列(工作日饮酒量)和Walc列(周末饮酒量)都是关于饮酒量的描述,本文将这两列相加,得到总体饮酒量Talc。
5.1.2 整体关系质量
famrel列(家庭关系质量)和romantic列(恋爱关系)都是关于个人社会关系的描述,本文将这两列相加,得到整体关系质量TReq。
5.1.3 总休闲时间
freetime列(放学后的空闲时间)和goout列(与朋友外出时间)都是关于休闲时间的描述,本文将这两列相加,得到总休闲时间Tleisure。
5.1.4 总教育支持
schoolsup列(额外的教育支持)和famsup列(家庭教育支持)都是关于是否有教育支持的描述,本文将这两列相加,得到总教育支持Tsup。
新特征的构造转换展示部分如下所示:
六、 模型选择
对于此类机器学习问题,纵观全局共有60多种预测建模算法可供选择。为将范围缩小到可以评估的少数几个模型,必须了解问题的类型和解决方案的需求。
本次报告的题目类型是一个分类问题,如果想要确定输出(label)与其他变量或特征(性别、年龄、学校等)之间的关系。当我们用给定的数据集训练我们的模型时,我们也在进行一类被称为监督学习的机器学习。有了这两个标准——监督学习加上二元分类问题,我们可以缩小我们的模型选择。
在经过整理之后,本文认为可以运用的模型包括以下几种:
• 逻辑回归
• SVM 支持向量机
• 朴素贝叶斯分类器
• 决策树
• 随机森林分类
• 梯度提升分类
• 人工神经网络
# 模型准备
# 数学
features = ['school', 'sex', 'age', 'address', 'famsize', 'Pstatus', 'Medu', 'Fedu',
'Mjob', 'Fjob', 'reason', 'guardian', 'traveltime', 'studytime',
'failures', 'paid', 'activities', 'nursery', 'higher', 'internet',
'health', 'absences', 'Talc', 'TReq', 'Tleisure', 'Tsup']
X = data_mat[features]
Y = data_mat['G1']
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.3, random_state=33)
X_train = X_train.astype('int')
X_test = X_test.astype('int')
Y_train = Y_train.astype('int')
Y_test = Y_test.astype('int')
# 模型准备
# 葡萄牙语
features = ['school', 'sex', 'age', 'address', 'famsize', 'Pstatus', 'Medu', 'Fedu',
'Mjob', 'Fjob', 'reason', 'guardian', 'traveltime', 'studytime',
'failures', 'paid', 'activities', 'nursery', 'higher', 'internet',
'health', 'absences', 'Talc', 'TReq', 'Tleisure', 'Tsup']
X1 = data_por[features]
Y1 = data_por['G1']
X_train1, X_test1, Y_train1, Y_test1 = train_test_split(
X1, Y1, test_size=0.3, random_state=33)
X_train1 = X_train1.astype('int')
X_test1 = X_test1.astype('int')
Y_train1 = Y_train1.astype('int')
Y_test1 = Y_test1.astype('int')而在我们开始制作机器学习模型之前,建立一个基础模型是很重要的。如果构建的模型不能胜过基础模型,那么机器学习就不适合这个问题。
对于分类任务,本文选取一种机器学习模型,使用默认超参数以及评分标准,并使用分层交叉验证评估模型选取平均分。
6.1 建立baseline
通过创建一个基础模型,可以将改进的模型与之进行比较。基础模型可以作为评估不同模型性能的基准,帮助我们了解模型改进的程度和效果。我们可以通过对比基线模型和改进后的模型的效果,来确定模型改进的有效性,进而定位需要改进的方面。
# 数学
# 预测值选取真实值的中位数
Y_pre=np.array([np.median(Y_train)]*len(Y_train))
# 直接根据预测结果评估模型
# micro:全局指标,macro:算数平均,weighted:加权平均
baseline_score=f1_score(Y_train,Y_pre,average='weighted')
# 取平均得分
baseline_score = round(baseline_score.mean()*100,2)
print(baseline_score)
# 葡萄牙语
# 预测值选取真实值的中位数
Y_pre1=np.array([np.median(Y_train1)]*len(Y_train1))
# 直接根据预测结果评估模型
# micro:全局指标,macro:算数平均,weighted:加权平均
baseline_score1 = f1_score(Y_train1,Y_pre1,average='weighted')
# 取平均得分
baseline_score1 = round(baseline_score1.mean()*100,2)
print(baseline_score1)6.2 选择训练模型
# 多分类ROC曲线画图
def pltROC(model, model_name, x_train, y_train, x_test, y_test, draw=True):
# 去重+升序
y_lists = np.unique(np.insert(y_train, -1, y_test, axis=0))
# 多分类问题
if len(y_lists) > 2:
# 计算每一类的FPR、TPR
FPR, TPR, AUC, Gini = {}, {}, {}, {}
# 将类别转换为二元分类,然后计算FPR,TPR
for li in y_lists:
y_train_copy = copy.deepcopy(y_train)
y_test_copy = copy.deepcopy(y_test)
# 将类别转换为正负类或0/1或1/2......
y_train_copy[y_train_copy != li], y_train_copy[y_train_copy == li] = 0, 1
y_test_copy[y_test_copy != li], y_test_copy[y_test_copy == li] = 0, 1
# 训练数据
model.fit(x_train, y_train_copy)
# 预测测试集类别概率/到决策边界的距离
try:
# 概率估计。所有类的返回估计值按类的标签排序(升序)。[:,1]表示最后1列为正类
y_pre = model.predict_proba(x_test)[:, -1]
except:
# 决策边界估计
y_pre = model.decision_function(x_test)
# 计算ROC
fpr, tpr, threasholds = roc_curve(y_test_copy, y_pre)
FPR[li], TPR[li] = fpr, tpr
# 计算AUC
AUC[li] = metrics.auc(fpr, tpr)
# 计算基尼系数
Gini[li] = round((2 * AUC[li] - 1) * 100, 2)
if draw:
# 画图:ROC曲线画图
plt.figure(figsize=(8, 8))
for li in y_lists:
plt.plot(FPR[li], TPR[li], lw=2, label=str(li) + '类别,AUC=%.3f,Gini=%.0f%%' % (AUC[li], Gini[li]))# lw:线宽
else:
AUC, Gini = None, None
# 训练数据
model.fit(x_train, y_train)
# 预测测试集类别概率/到决策边界的距离
try:
# 概率估计。所有类的返回估计值按类的标签排序(升序)。[:,1]表示最后1列为正类
y_pre = model.predict_proba(x_test)[:, 1]
except:
# 决策边界估计
y_pre = model.decision_function(x_test)
# 计算ROC
fpr, tpr, threasholds = roc_curve(y_test, y_pre)
# 计算AUC
AUC = auc(fpr, tpr)
# 计算基尼系数
Gini = round((2 * AUC - 1) * 100, 2)
if draw:
plt.plot(fpr, tpr, lw=2, label='AUC=%.3f,Gini=%.0f%%' % (AUC, Gini))# lw:线宽
if draw:
plt.plot((0, 1), (0, 1), c='#a0a0a0', lw=2, ls='--')
plt.xlim(-0.01, 1.02)
plt.ylim(-0.01, 1.02)
plt.xlabel('FPR', fontsize=16)
plt.ylabel('TPR', fontsize=16)
plt.title(model_name + '模型测试样本的ROC/AUC', fontsize=18)
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
# 保存图片
# plt.savefig('人工神经网络(葡萄牙语).png', bbox_inches = 'tight')
plt.show()
return AUC, Gini6.2.1 逻辑回归
逻辑回归是一个非常经典的算法,虽然被称为回归,但其实际上是一个分类模型,并常用于二分类。
# 逻辑回归
# 数学
log = LogisticRegression(random_state=123)
#分层交叉验证评估
log_score = cross_val_score(log, X_train, Y_train, scoring='f1_weighted',cv=15)
#取平均得分
log_score = round(log_score.mean()*100,2)
print(log_score)
pltROC(log,'逻辑回归',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
log1 = LogisticRegression(random_state=123)
#分层交叉验证评估
log_score1 = cross_val_score(log1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
#取平均得分
log_score1 = round(log_score1.mean()*100,2)
print(log_score1)
pltROC(log1,'逻辑回归',X_train1,Y_train1,X_test1, Y_test1)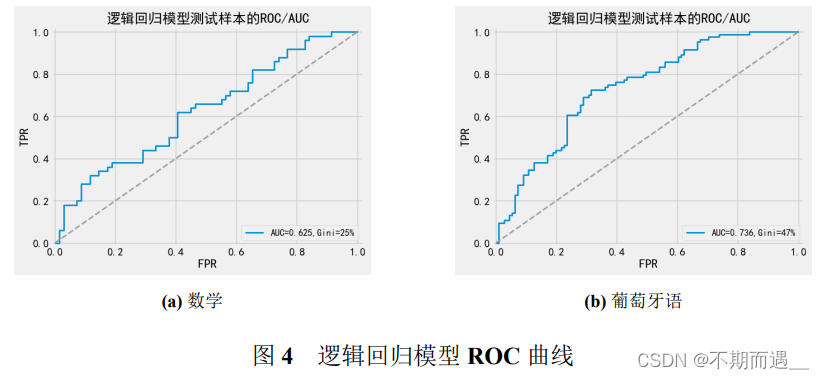
6.2.2 SVM支持向量机
支持向量机的理论基础是统计学习理论,即在已知训练点类别的情况下,求训练点和类别之间的对应关系,以便将训练集按照类别分开,或是预测新的训练点所对应的类别。cite{bib:three}
已监督学习方式对数据进行二元分类的广义线性分类器,简单来说就是进行一个二分类,求解最优的那个分类面,然后用这个最优解进行分类。
# svm
# 数学
svm = SVC(random_state=123)
# 分层交叉验证评估
svm_score = cross_val_score(svm, X_train, Y_train, scoring='f1_weighted',cv=10)
# 取平均得分
svm_score = round(svm_score.mean()*100,2)
print(svm_score)
pltROC(svm,'支持向量机',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
svm1 = SVC(random_state=123)
# 分层交叉验证评估
svm_score1 = cross_val_score(svm1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
svm_score1 = round(svm_score1.mean()*100,2)
print(svm_score1)
pltROC(svm1,'支持向量机',X_train1,Y_train1,X_test1, Y_test1)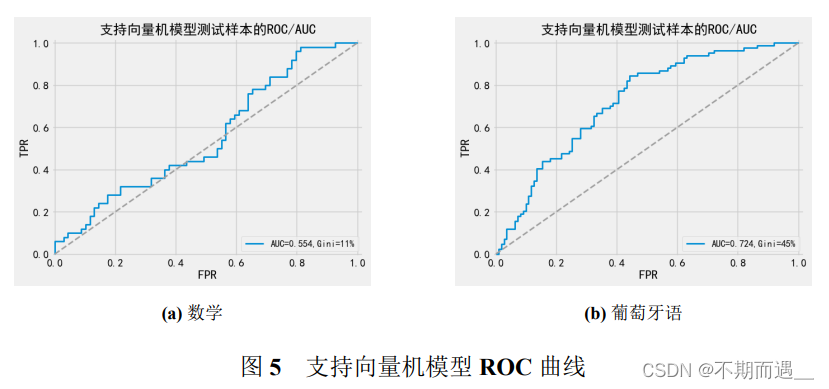
6.2.3 朴素贝叶斯分类器
贝叶斯模型非常特殊,是一个概率模型,通过事件属性相关事件发生的概率(先验概率)去推测该事件发生的概率。
# 朴素贝叶斯
# 数学
bys = GaussianNB()
# 分层交叉验证评估
bys_score = cross_val_score(bys, X_train, Y_train, scoring='f1_weighted',cv=10)
# 取平均得分
bys_score = round(bys_score.mean()*100,2)
print(bys_score)
pltROC(bys,'朴素贝叶斯',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
bys1 = GaussianNB()
# 分层交叉验证评估
bys_score1 = cross_val_score(bys1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
bys_score1 = round(bys_score1.mean()*100,2)
print(bys_score1)
pltROC(bys1,'朴素贝叶斯',X_train1,Y_train1,X_test1, Y_test1)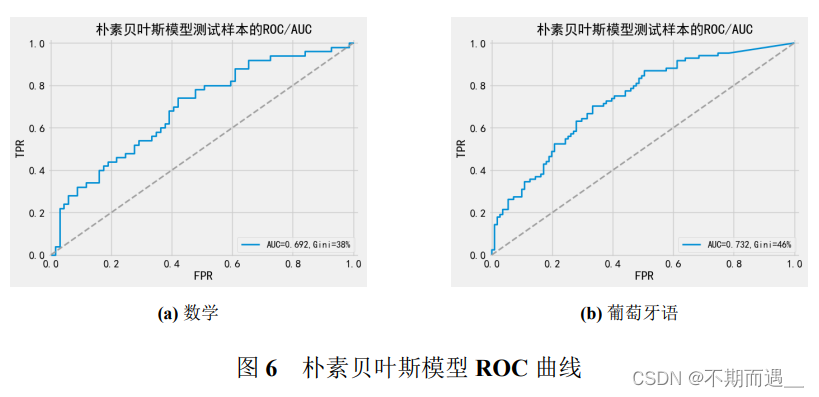
6.2.4 决策树
决策树(分类树)是一种十分常用的分类方法,使用信息熵增益、信息熵增益率、Gini系数等进行剪枝寻求最优解。
# 决策树
# 数学
decision_tree = DecisionTreeClassifier(random_state=123)
# 分层交叉验证评估
decision_tree_score = cross_val_score(decision_tree, X_train, Y_train, scoring='f1_weighted',cv=10)
# 取平均得分
decision_tree_score = round(decision_tree_score.mean()*100,2)
print(decision_tree_score)
pltROC(decision_tree,'决策树',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
decision_tree1 = DecisionTreeClassifier(random_state=123)
# 分层交叉验证评估
decision_tree_score1 = cross_val_score(decision_tree1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
decision_tree_score1 = round(decision_tree_score1.mean()*100,2)
print(decision_tree_score1)
pltROC(decision_tree1,'决策树',X_train1,Y_train1,X_test1, Y_test1)
6.2.5 随机森林分类
随机森林是以决策树为基学习器,通过集成方式构建而成的有监督机器学习方法,通过在决策树的训练过程引入随机性,使其具备优良的抗过拟合与抗噪能力。[4]
# 随机森林
# 数学
random_forest = RandomForestClassifier(random_state=123)
# 分层交叉验证评估
random_forest_score = cross_val_score(random_forest, X_train, Y_train, scoring='f1_weighted',cv=10)
# 取平均得分
random_forest_score = round(random_forest_score.mean()*100,2)
print(random_forest_score)
pltROC(random_forest,'随机森林',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
random_forest1 = RandomForestClassifier(random_state=123)
# 分层交叉验证评估
random_forest_score1 = cross_val_score(random_forest1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
random_forest_score1 = round(random_forest_score1.mean()*100,2)
print(random_forest_score1)
pltROC(random_forest1,'随机森林',X_train1,Y_train1,X_test1, Y_test1)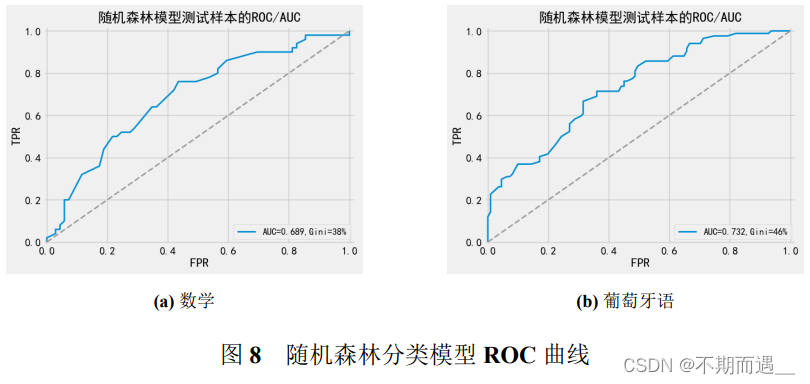
6.2.6 梯度提升分类
分类决策树模型是一种描述对实例进行分类的树形结构,模型的学习算法通常是一个递归的选择最优特征,并根据该特征对训练数据进行分割的过程,树构建的过程中往往对应着特征空间的划分。[5]而梯度提升是一种用于回归和分类问题的机器学习技术,其产生的预测模型是弱预测模型的集成,如采用典型的决策树作为弱预测模型,这时则为梯度提升树。
# 梯度提升分类树
GB_forest = GradientBoostingClassifier(random_state=123)#n_estimators:默认100
# 分层交叉验证评估
GB_forest_score = cross_val_score(GB_forest, X_train, Y_train, scoring='f1_weighted',cv=10)
# 取平均得分
GB_forest_score = round(GB_forest_score.mean()*100,2)
print(GB_for服务器托管网est_score)
pltROC(GB_forest,'梯度提升分类树',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
GB_forest1 = GradientBoostingClassifier(random_state=123)#n_estimators:默认100
# 分层交叉验证评估
GB_forest_score1 = cross_val_score(GB_forest1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
GB_forest_score1 = round(GB_forest_score1.mean()*100,2)
print(GB_forest_score1)
pltROC(GB_forest1,'梯度提升分类树',X_train1,Y_train1,X_test1, Y_test1)
6.2.7 人工神经网络
人工神经网络就是模拟人思维的第二种方式。这是一个非线性动力学系统,其特色在于信息的分布式存储和并行协同处理。
# 人工神经网络
# 数学
ann = MLPClassifier(random_state=123)
# 分层交叉验证评估
ann_score = cross_val_score(ann, X_train, Y_train, scoring='f1_weighted',cv=10)
# 取平均得分
ann_score = round(ann_score.mean()*100,2)
print(ann_score)
pltROC(ann,'人工神经网络',X_train,Y_train,X_test, Y_test)
# 葡萄牙语
ann1 = MLPClassifier(random_state=123)
# 分层交叉验证评估
ann_score1 = cross_val_score(ann1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
ann_score1 = round(ann_score1.mean()*100,2)
print(ann_score1)
pltROC(ann1,'人工神经网络',X_train1, Y_train1, X_test1, Y_test1)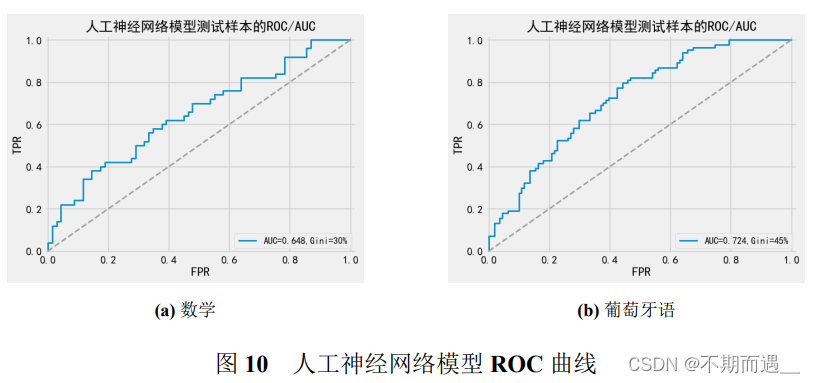
6.3 查看模型得分
# 数学
models = pd.DataFrame({
'Model': ['SVC', '逻辑回归',
'随机森林', '朴素贝叶斯',
'人工神经网络',
'决策树','梯度提升分类树','base_model'],
'train_Score': [svm_score, log_score,
random_forest_score, bys_score,
ann_score,decision_tree_score,GB_forest_score,
baseline_score]
})
index=models.sort_values(by='train_Score', ascending=True).index
data_plot=models.loc[index,:]
plt.barh(data_plot.Model,data_plot.train_Score,color='r') # 对每个特征绘制总数状图
plt.legend(['F1-Score'])
plt.savefig('./模型得分(数学).png', bbox_inches = 'tight')
# 葡萄牙语
models1 = pd.DataFrame({
'Model': ['SVC', '逻辑回归',
'随机森林', '朴素贝叶斯',
'人工神经网络',
'决策树','梯度提升分类树','base_model'],
'train_Score': [svm_score1, log_score1,
random_forest_score1, bys_score1,
ann_score1,decision_tree_score1,GB_forest_score1,
baseline_score1]
})
index1=models1.sort_values(by='train_Score', ascending=True).index
data_plot=models1.loc[index1,:]
plt.barh(data_plot.Model,data_plot.train_Score,color='r') # 对每个特征绘制总数状图
plt.legend(['F1-Score'])
plt.savefig('./模型得分(葡萄牙语).png', bbox_inches = 'tight')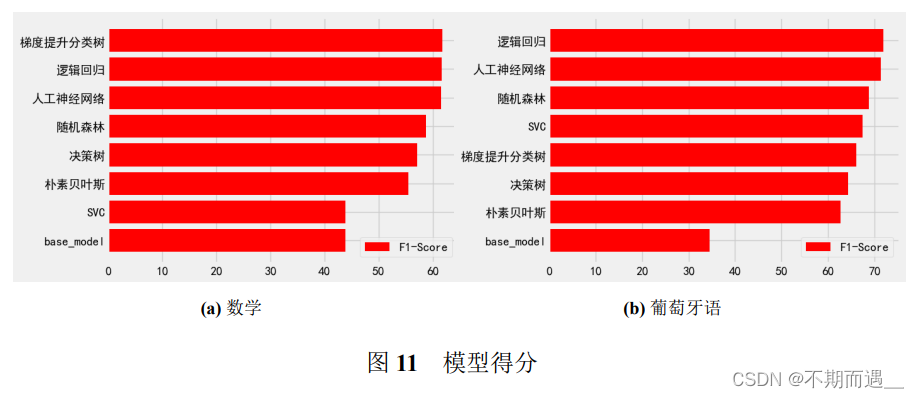
当前的机器模型均优于基础模型。
• 综合“数学”数据集上的训练集和测试集得分,在梯度提升分类树表现最好, 其次是逻辑回归。
• 综合“葡萄牙语”数据集上的训练集和测试集得分,在逻辑回归表现最好, 其次是人工神经网络。
当前模型使用默认的超参数情况下做了初步评估,需要进一步调整超参数以客观评估模型。
七、 模型调参
鉴于此处的结果,从这里开始,本文将专注于使用梯度提升分类树和逻辑回归。
7.1 随机搜索——缩小超参数范围
本文选择了多个不同的超参数来调整模型。 这些都将以不同的方式影响模型,由于这些方法很难提前确定,所以找到特定问题的最佳组合的唯一方法是测试它们。
本文创建了随机搜索对象,并传递以下参数:
• estimator: 估计器,也就是模型
• param_distributions: 我们定义的参数
• cv:用于k−fold 交叉验证的 folds 数量,若是cv=k,表示k−fold;若是cv=StratifiedKF old(n_splits = k), 表示分层 k − fold 交叉验证
• n_iter: 不同的参数组合的数量
• scoring: 评估指标
• n_jobs: 同时工作的 cpu 个数(-1 代表全部)
• verbose: 日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,>1:对每个子模型都输出
• return_train_score: 每一个 cross − validationfold 返回的分数
• random_state: 修复使用的随机数生成器,因此每次运行都会得到相同的结果
# 数学
# 要优化的损失函数
loss = ['deviance','exponential']
#deviance: 对数似然损失函数
#exponential:指数损失函数
# 梯度增强过程中使用的树的数量(估算器数量)
n_estimators = [2,5,10,20,50,80,100,150,200,300,400,500,600]
# 树的最大深度
max_depth = [2,3,5,10,15]
# 每片叶子的最小样本数
min_samples_leaf = [1,2,4,6,8]
# 拆分节点的最小样本数
min_samples_split = [2,4,6,10,16,20,25,30,35,40]
# 进行拆分时要考虑的最大特征数
max_features = ['auto', 'sqrt', 'log2', None]
# 定义要进行搜索的超参数网格
hyperparameter = {'loss': loss,
'n_estimators': n_estimators,
'max_depth': max_depth,
'min_samples_leaf': min_samples_leaf,
'min_samples_split': min_samples_split,
'max_features': max_features}
#创建用于调整超参数的模型:梯度提升回归树
model = GradientBoostingClassifier(random_state=123)
#使用分层5折交叉验证设置随机搜索
random_cv=RandomizedSearchCV(estimator=model,
param_distributions=hyperparameter,
cv=StratifiedKFold(n_splits=5),
n_iter=100,
scoring='f1_weighted',
n_jobs=-1,
verbose = 1,
return_train_score = True,
random_state=123)
# 拟合随机搜索
random_cv.fit(X_train,Y_train)
# 使用分层交叉验证随机搜索获得的最佳模型参数
random_cv.best_estimator_
# 葡萄牙语
# 逻辑回归损失函数的优化方法
solver = ['liblinear','lbfgs','newton-cg','sag']
# 最大迭代次数,默认是100
max_iter = [2,5,10,20,50,80,100,150,200]
# 分类方式
multi_class = ['ovr', 'multinomial']
# 各种类型的权重
class_weight = [{0:0.5, 1:0.5},'balanced']
# 定义要进行搜索的超参数网格
hyperparameter1 = {'solver': solver,
'max_iter': max_iter,
'multi_class': multi_class,
'class_weight': class_weight}
#创建用于调整超参数的模型:逻辑回归
model1 = LogisticRegression(random_state=123)
#使用分层5折交叉验证设置随机搜索
random_cv1 = RandomizedSearchCV(estimator=model1,
param_distributions=hyperparameter1,
cv=StratifiedKFold(n_splits=5),
n_iter=100,
scoring='f1_weighted',
n_jobs=-1,
verbose = 1,
return_train_score = True,
random_state=123)
# 拟合随机搜索
random_cv1.fit(X_train1,Y_train1)
# 使用分层交叉验证随机搜索获得的最佳模型参数
random_cv1.best_estimator_随机搜索对象的训练方式与其他机器学习模型相同。训练之后,可以比较所有不同的超参数组合,找到效果最好的组合。
7.2网格搜索——精确超参数范围
使用随机搜索是缩小可能的超参数以尝试的好方法。最初,虽然不知道哪种组合效果最好,但这至少缩小了选项的范围。网格搜索是指将变量区域网格化, 遍历所有网格点, 求解满足约束函数的目标函数值, 最终比较选择出最优点。[6]本文选择通过使用随机搜索结果来创建具有超参数的网格来进行网格搜索,这些参数接近于在随机搜索期间最佳的参数。
# 数学
# n_estimators
# 创建一系列要评估的树
trees_grid = {'n_estimators': list(range(150,250,2))}
# 使用随机搜索得到的最佳参数创建模型:
model = GradientBoostingClassifier(loss='exponential', max_features='log2',
min_samples_leaf=8, min_samples_split=40,
random_state=123)
# 使用树的范围和梯度提升分类树模型的网格搜索对象
grid_search = GridSearchCV(estimator = model,
param_grid=trees_grid,
cv=StratifiedKFold(n_splits=10),
scoring = 'f1_weighted',
verbose = 1,
n_jobs = -1,
return_train_score = True)
# 拟合网格搜索
grid_search.fit(X_train,Y_train)
# 使用分层交叉验证网络搜索获得的最佳模型参数
grid_search.best_estimator_
# max_depth
trees_grid = {'max_depth': [6,7,8,9,10,11,12,13,14]}
# 使用随机搜索得到的最佳参数创建模型:
model = GradientBoostingClassifier(loss='exponential',
n_estimators=174,
max_features='log2',
min_samples_leaf=8,
min_samples_split=40,
random_state=123)
# 使用树的范围和梯度提升分类树模型的网格搜索对象
grid_search = GridSearchCV(estimator = model,
param_grid=trees_grid,
cv=StratifiedKFold(n_splits=10),
scoring = 'f1_weighted',
verbose = 1,
n_jobs = -1,
return_train_score = True)
# 拟合网格搜索
grid_search.fit(X_train,Y_train)
# 使用分层交叉验证网络搜索获得的最佳模型参数
grid_search.best_estimator_
# min_samples_split
trees_grid = {'min_samples_split': list(range(36,50,1))}
# 使用随机搜索得到的最佳参数创建模型:
model = GradientBoostingClassifier(loss='exponential',
n_estimators=174,
max_depth=8,
max_features='log2',
min_samples_leaf=8,
random_state=123)
# 使用树的范围和梯度提升分类树模型的网格搜索对象
grid_search = GridSearchCV(estimator = model,
param_grid=trees_grid,
cv=StratifiedKFold(n_splits=10),
scoring = 'f1_weighted',
verbose = 1,
n_jobs = -1,
return_train_score = True)
# 拟合网格搜索
grid_search.fit(X_train,Y_train)
# 使用分层交叉验证网络搜索获得的最佳模型参数
grid_search.best_estimator_
# min_samples_leaf
trees_grid = {'min_samples_leaf': [7,8,9,10,11,12]}
# 使用随机搜索得到的最佳参数创建模型:
model = GradientBoostingClassifier(loss='exponential',
n_estimators=174,
max_depth=8,
max_features='log2',
min_samples_split=48,
random_state=123)
# 使用树的范围和梯度提升分类树模型的网格搜索对象
grid_search = GridSearchCV(estimator = model,
param_grid=trees_grid,
cv=StratifiedKFold(n_splits=10),
scoring = 'f1_weighted',
verbose = 1,
n_jobs = -1,
return_train_score = True)
# 拟合网格搜索
grid_search.fit(X_train,Y_train)
# 使用分层交叉验证网络搜索获得的最佳模型参数
grid_search.best_estimator_
# 葡萄牙语
# 创建一系列要评估的树
trees_grid1 = {'max_iter': list(range(11,50,1))}
# 使用随机搜索得到的最佳参数创建模型:
model1 = LogisticRegression(class_weight={0: 0.5, 1: 0.5},multi_class='multinomial', solver='sag', random_state=123)
# 使用树的范围和梯度提升分类树模型的网格搜索对象
grid_search1 = GridSearchCV(estimator = model1,
param_grid=trees_grid1,
cv=StratifiedKFold(n_splits=10),
scoring = 'f1_weighted',
verbose = 1,
n_jobs = -1,
return_train_score = True)
# 拟合网格搜索
grid_search1.fit(X_train1,Y_train1)
# 使用分层交叉验证网络搜索获得的最佳模型参数
grid_search1.best_estimator_在训练完成之后,本文得到了结果如下所示:
最佳梯度提升分类树模型具有以下超参数:
• loss=’exponential’
• max_features=’log2’
• max_depth=8
• min_samples_leaf = 10
• min_samples_split = 48
• n_estimators = 174
最佳逻辑回归模型具有以下超参数:
• class_weight=0: 0.5, 1: 0.5
• max_iter=41
• multi_class=’multinomial’
• solver=’sag’
7.3 学习曲线
学习曲线是横轴为训练集大小,由此来看不同训练集大小设置下的模型准确率。学习曲线可以帮助理解训练数据集的大小对机器学习模型的影响。
# 使用随机搜索+网络搜索得到的最佳参数创建模型:
model = GradientBoostingClassifier(loss='exponential', max_depth=8, max_features='log2',
min_samples_leaf=10, min_samples_split=48,
n_estimators=174, random_state=123)
# 生成学习曲线
size_grid = np.array([0.2,0.4,0.6,0.8,1])
_,train_scores,validation_scores = learning_curve(model,X_train,Y_train,
train_sizes = size_grid,
scoring='balanced_accuracy',
cv =StratifiedKFold(n_splits=10))
# 学习曲线可视化
plt.figure()
l=X_train.shape[0]+X_test.shape[0]
plt.plot(size_grid*l,1-np.average(train_scores, axis = 1),label="Training score", color = 'red')
plt.plot(size_grid*l, 1-np.average(validation_scores ,axis = 1),label="validation score",color = 'black')
plt.title('学习曲线')
plt.xlabel('训练集样本大小')
plt.ylabel('误差')
plt.legend()
plt.savefig('./学习曲线(数学).png', bbox_inches = 'tight')
plt.show()
# 使用随机搜索+网络搜索得到的最佳参数创建模型:
model1 = LogisticRegression(class_weight={0: 0.5, 1: 0.5}, max_iter=41,
multi_class='multinomial', random_state=123, solver='sag')
# 生成学习曲线
size_grid1 = np.array([0.2,0.4,0.6,0.8,1])
_,train_scores1,validation_scores1 = learning_curve(model1,X_train1,Y_train1,
train_sizes = size_grid1,
scoring='balanced_accuracy',
cv =StratifiedKFold(n_splits=8))
# 学习曲线可视化
plt.figure()
l=X_train1.shape[0]+X_test1.shape[0]
plt.plot(size_grid1*l,1-np.average(train_scores1, axis = 1),label="Training score", color = 'red')
plt.plot(size_grid1*l, 1-np.average(validation_scores1 ,axis = 1),label="validation score",color = 'black')
plt.title('学习曲线')
plt.xlabel('训练集样本大小')
plt.ylabel('误差')
plt.legend()
plt.savefig('./学习曲线(葡萄牙语).png', bbox_inches = 'tight')
plt.show()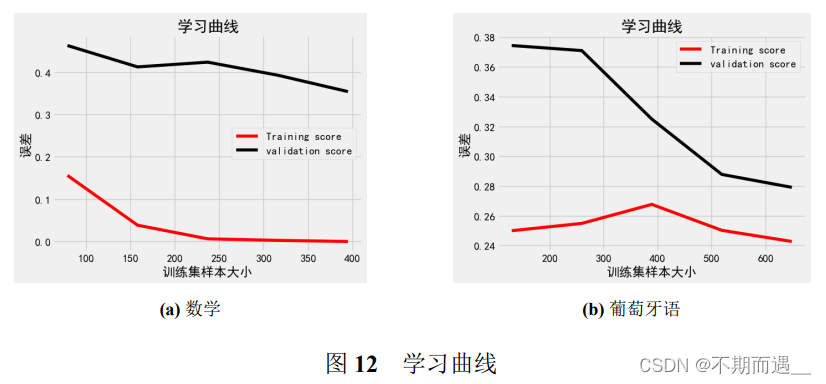
从图中可以看出两个训练集对于模型的最佳样本数量。
7.4 验证曲线
验证曲线是横轴为某个超参数的一系列值,由此来看不同参数设置下模型准确率。从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适再到过拟合的过程,进而选择一个合适的位置,来提高模型的性能。
# 生成验证曲线
# 创建一系列要评估的树
params_grid= list(range(10,200,10))
# 使用
train_scores,validation_scores = validation_curve(model,X_train,Y_train,
param_name='n_estimators',param_range=params_grid,
scoring='balanced_accuracy',
cv=12)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
validation_scores_mean = np.mean(validation_scores, axis=1)
validation_scores_std = np.std(validation_scores, axis=1)
# 可视化生成训练、验证曲线
plt.figure()
# plt.plot(params_grid, train_scores_mean,color = 'red')
# plt.plot(params_grid,test_scores_mean,color = 'black')
plt.plot(params_grid, 1-train_scores_mean, label='Training score',color='r')
plt.plot(params_grid, 1-validation_scores_mean, label='validation score',color='k')
plt.title('验证曲线')
plt.xlabel('number of estimator')
plt.ylabel('Error')
plt.legend()
plt.savefig('./验证曲线(数学).png', bbox_inches = 'tight')
plt.show()
# 生成验证曲线
params_grid1= list(range(10,200,10))
# 使用
train_scores,validation_scores = validation_curve(model1,X_train1,Y_train1,
param_name='max_iter',param_range=params_grid1,
scoring='balanced_accuracy',
cv=8)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
validation_scores_mean = np.mean(validation_scores, axis=1)
validation_scores_std = np.std(validation_scores, axis=1)
# 可视化生成训练、验证曲线
plt.figure()
# plt.plot(params_grid, train_scores_mean,color = 'red')
# plt.plot(params_grid,test_scores_mean,color = 'black')
plt.plot(params_grid, 1-train_scores_mean, label='Training score',color='r')
plt.plot(params_grid, 1-validation_scores_mean, label='validation score',color='k')
plt.title('验证曲线')
plt.xlabel('max_iter')
plt.ylabel('Error')
plt.legend()
plt.savefig('./验证曲线(葡萄牙语).png', bbox_inches = 'tight')
plt.show()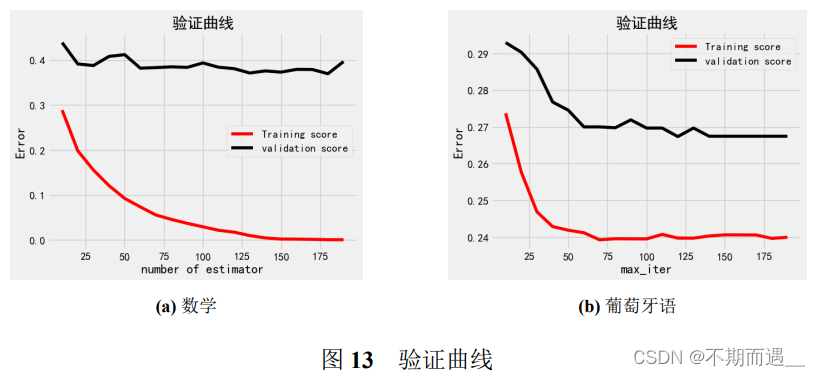
八、特征筛选
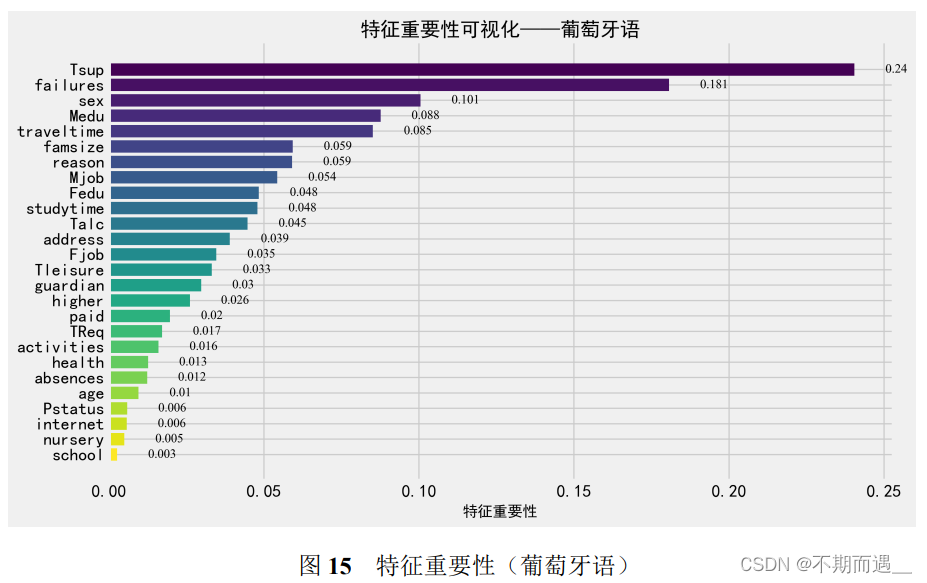
8.1 特征重要性排序
特征重要性分析作为机器学习中经常使用的一种方法,用于了解每个特征变量对于做出预测的有用性或价值,目标是确定对模型输出影响最重要的特征。
# 数学
# 将特征重要性提取到数据结构中
feature_results = pd.DataFrame({'feature': list(X_train.columns),
'importance': final_model.feature_importances_})
# 显示最重要的前十名
feature_results = feature_results.sort_values('importance', ascending = False).reset_index(drop=True)
feature_results.head(10)
# 葡萄牙语
model1 = model1.fit(X_train, Y_train)
coef_LR = pd.DataFrame({'feature':list(X_train1.columns),'importance':abs(model1.coef_.flatten())})
coef_LR = coef_LR.sort_values('importance', ascending = False)
coef_LR.head(10)因此我们对数据集中的所有特征变量进行了重要性分析并可视化。可以发现影响因素有相关之处但也略有不同。
# 颜色映射
colors = plt.cm.viridis(np.linspace(0, 1, len(feature_results)))
# 可视化特征重要性
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(feature_results['feature'], feature_results['importance'], color=colors)
ax.invert_yaxis() # 翻转y轴,使得最大的特征在最上面
ax.set_xlabel('特征重要性', fontsize=12) # 图形的x标签
ax.set_title('特征重要性可视化——数学',fontsize=16)
for i, v in enumerate(feature_results['importance']):
ax.text(v + 0.01, i, str(round(v, 3)), va='center', fontname='Times New Roman', fontsize=10)
# 设置图形样式
# plt.style.use('default')
ax.spines['top'].set_visible(False) # 去掉上边框
ax.spines['right'].set_visible(False) # 去掉右边框
# ax.spines['left'].set_linewidth(0.5)#左边框粗细
# ax.spines['bottom'].set_linewidth(0.5)#下边框粗细
# ax.tick_params(width=0.5)
# ax.set_facecolor('white')#背景色为白色
# ax.grid(False)#关闭内部网格线
# 保存图形
plt.savefig('./特征重要性(数学).png', dpi=400, bbox_inches='tight')
plt.show()
# 颜色映射
colors = plt.cm.viridis(np.linspace(0, 1, len(coef_LR)))
# 可视化特征重要性
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(coef_LR['feature'], coef_LR['importance'], color=colors)
ax.invert_yaxis() # 翻转y轴,使得最大的特征在最上面
ax.set_xlabel('特征重要性', fontsize=12) # 图形的x标签
ax.set_title('特征重要性可视化——葡萄牙语',fontsize=16)
for i, v in enumerate(coef_LR['importance']):
ax.text(v + 0.01, i, str(round(v, 3)), va='center', fontname='Times New Roman', fontsize=10)
# 设置图形样式
# plt.style.use('default')
ax.spines['top'].set_visible(False) # 去掉上边框
ax.spines['right'].set_visible(False) # 去掉右边框
# ax.spines['left'].set_linewidth(0.5)#左边框粗细
# ax.spines['bottom'].set_linewidth(0.5)#下边框粗细
# ax.tick_params(width=0.5)
# ax.set_facecolor('white')#背景色为白色
# ax.grid(False)#关闭内部网格线
# 保存图形
plt.savefig('./特征重要性(葡萄牙语).png', dpi=400, bbox_inches='tight')
plt.show()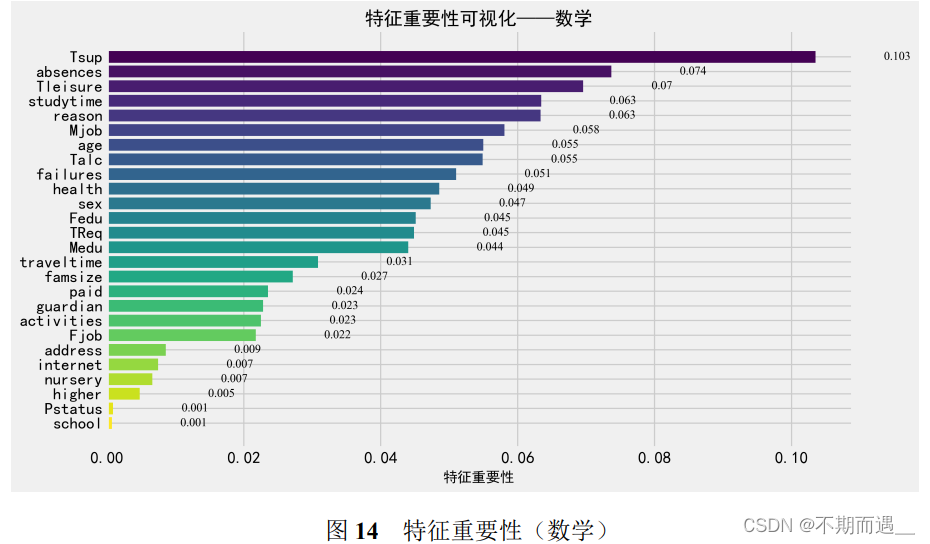
8.2 特征选择
特征选择旨在通过去除不相关、冗余或嘈杂的特征,从原始特征中选择一小部分相关特征,以减少算力和存储消耗并简化模型,以便于实际应用过程中的特征构建。[7]
# 数学
# 提取最重要特征的名称
most_important_features = feature_results['feature'][:6]
# 数据集中只保留最重要的特征
X_reduced = X_train[most_important_features]
X_test_reduced = X_test[most_important_features]
print('Most important training features shape: ', X_reduced.shape)
print('Most important testing features shape: ', X_test_reduced.shape)
# 逻辑回归
log = GradientBoostingClassifier(loss='exponential', max_depth=13,
max_features='log2', min_samples_leaf=11,
min_samples_split=3, n_estimators=216,
random_state=123)
#分层交叉验证评估
log_score = cross_val_score(log, X_train, Y_train, scoring='f1_weighted',cv=12)
#取平均得分
log_score = round(log_score.mean()*100,2)
print('全部特征')
print('得分:',log_score)
# 在6个最重要的特征上拟合并测试(即减少后的特征上)
#分层交叉验证评估
log_score = cross_val_score(log, X_reduced, Y_train, scoring='f1_weighted',cv=12)
#取平均得分
log_score = round(log_score.mean()*100,2)
print('减少特征')
print('得分:',log_score)
# 葡萄牙语
# 提取最重要特征的名称
most_important_features1 = coef_LR['feature'][:6]
# 数据集中只保留最重要的特征
X_reduced1 = X_train1[most_important_features1]
X_test_reduced1 = X_test1[most_important_features1]
print('Most important training features shape: ', X_reduced1.shape)
print('Most important testing features shape: ', X_test_reduced1.shape)
log1 = LogisticRegression(class_weight='balanced', max_iter=12,
multi_class='multinomial', random_state=123, solver='sag')
# 分层交叉验证评估
log_score1 = cross_val_score(log1, X_train1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
log_score1 = round(log_score1.mean()*100,2)
print('全部特征')
print('得分:',log_score1)
# 在6个最重要的特征上拟合并测试(即减少后的特征上)
# 分层交叉验证评估
log_score1 = cross_val_score(log, X_reduced1, Y_train1, scoring='f1_weighted',cv=8)
# 取平均得分
log_score1 = round(log_score1.mean()*100,2)
print('减少特征')
print('得分:',log_score1)因此我们选择了两个数据集中对于预测结果最重要的前六个特征进行检验,最终模型得分如下所示:
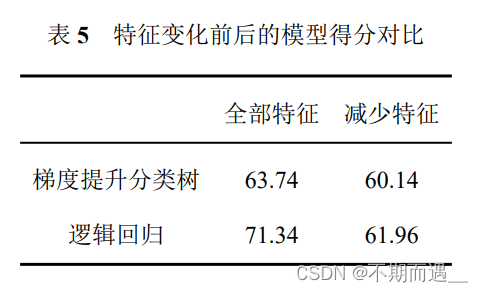
可以看出,对于两个模型来说,减少特征都没有改善最终的预测结果。事实证明,低重要性特征中的额外信息确实可以提高性能。鉴于此,我们将保留最终模型的所有特征。
九、 评估指标
9.1 模型性能
我们将使用超参数调整中的最佳模型来对测试集进行预测。该性能是模型在部署时的表现的一个很好的指标。为了比较,我们还可以查看默认模型的性能。
# 默认模型
default_model = GradientBoostingClassifier(random_state=123)
# 选择最佳模型参数
final_model = grid_search.best_estimator_
final_model
%%timeit -n 1 -r 5
default_model.fit(X_train, Y_train)
%%timeit -n 1 -r 5
final_model.fit(X_train, Y_train)
default_model.fit(X_train, Y_train)#梯度提升分类默认超参数
f1_default=cross_val_score(default_model, X_test, y=Y_test, scoring='f1_weighted', cv=12).mean()
print(f1_default)
final_model.fit(X_train, Y_train)#梯度提升分类优化超参数
f1_final=cross_val_score(final_model, X_test, y=Y_test, scoring='f1_weighted', cv=12).mean()
print(f1_final)
round((f1_final-f1_default)/f1_default*100,2)# 默认模型
default_model1 = LogisticRegression(random_state=123)
# 选择最佳模型参数
final_model1 = grid_search1.best_estimator_
final_model1
%%timeit -n 1 -r 5
default_model1.fit(X_train1, Y_train1)
%%timeit -n 1 -r 5
final_model1.fit(X_train1, Y_train1)
default_model1.fit(X_train1, Y_train1)#梯度提升分类默认超参数
f1_default1=cross_val_score(default_model1, X_test1, y=Y_test1, scoring='f1_weighted', cv=8).mean()
print(f1_default1)
final_model1.fit(X_train1, Y_train1)#梯度提升分类优化超参数
f1_final1=cross_val_score(final_model1, X_test1, y=Y_test1, scoring='f1_weighted', cv=8).mean()
print(f1_final1)
round((f1_final1-f1_default1)/f1_default1*100,2)最终的优化结果如下:
• 对于“数学”数据集,最终的模型比基础模型的性能提高了大约 16%。
• 对于“葡萄牙语”数据集,最终的模型比基础模型的性能提高了大约 1%。
对于为何“葡萄牙语”提升比较低的原因,笔者猜测可能是上述调参步骤中关于该 模型的参数调整并不大,所以优化的效果也不是很明显。
9.2 模型评估
# 数学
final_model.fit(X_train, Y_train)
Y_test_pred = final_model.predict(X_test)
print(classification_report(Y_test,Y_test_pred))
# 葡萄牙语
final_model1.fit(X_train1, Y_train1)
Y_test_pred1 = final_model1.predict(X_test1)
print(classification_report(Y_test1,Y_test_pred1))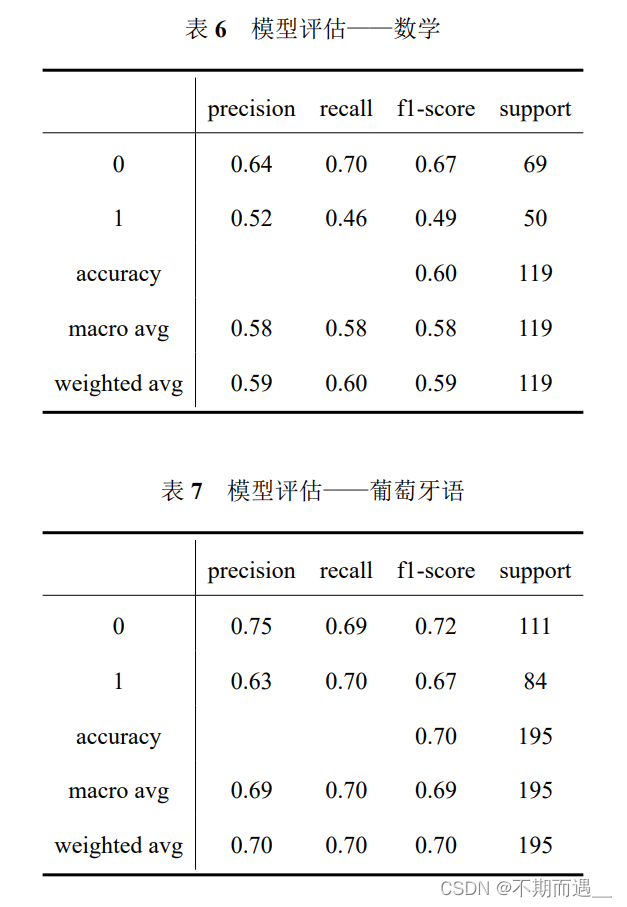
从模型的评估中我们可以得到两个模型的精确率(precision)、召回率(recall)、F1-score,可以看出梯度提升分类树在数学数据集上预测的准确率为60%,而逻辑回归在葡萄牙语数据集上预测的准确率为70%。
十、 结论
10.1 影响因素
通过上述分析,对于两个科目的学习成绩影响因素,本文可以得出一些结论:
• 学习时间:对于数学成绩和葡萄牙语成绩,学习时间(studytime)都是一个相对重要 的特征。这表明学习时间对成绩有显著影响,投入更多的学习时间有助于提高成绩。
• 休闲时间:休闲时间(Tleisure)在数学成绩的特征中排名第三,影响较大。这表明 休闲时间的多少会影响数学成绩,但过多的休闲时间也会对数学学习成绩产生不利 影响。可以看出休闲时间的多少对葡萄牙语成绩的影响较小。
• 家庭支持:在两种成绩的特征中,总教育支持(Tsup)都是一个非常重要的特征。这 表明家庭和学习对孩子的教育支持对成绩有显著影响。
• 缺勤:缺席人数(absences)在数学成绩的特征中排名第二,这表明缺勤对数学成绩 的影响非常大。
• 个人和家庭特征:性别(sex)、母亲的教育(Medu)、家庭规模(famsize)、母亲的 工作(Mjob)、父亲的教育(Fedu)等特征在两种成绩的特征中都有出现,但重要度 较低。这表明这些特征对成绩有一定影响,但影响较小。
• 选择学校的原因:选择学校的原因在两种成绩的特征中都出现了,且排名都相对较 高。这从侧面说明了家长和孩子对于学习的态度,对成绩有显著影响。
综上所述,学习时间、家庭支持、休闲时间、缺勤和选择学校的原因都是影响学生 成绩的重要因素。为了提高成绩,学生需要合理安排学习时间,同时获得足够的教育支 持。学校和家长应当通过关注这些因素来帮助提高学生的学习成绩。
10.2 期望
通过本报告的分析和预测,笔者希望能够为教育机构、教师和学生提供有价值的参考信息。希望教育机构能够根据预测结果制定更为科学的教学计划和管理策略;教师能够更好地理解学生的学习需求,并制定更为个性化的教学方案;学生能够更好地了解自己的学习状况,并为未来的学习制定更为明确的目标。
同时,笔者也希望本报告的分析结果能够对未来的研究提供有益的启示。笔者期待未来有更多的研究关注学生成绩预测领域,进一步优化预测模型,提高预测准确性,为学生、教师和教育机构提供更为精准的服务和支持。
参考文献
[1] 李凯伟. 基于机器学习的高校学生成绩预测 [J]. 计算机时代,2023(12):220- 223.10.16644/j.cnki.cn33-1094/tp.2023.12.049.
[2] 王灿星, 朱杰勇, 喻聪骏等. 基于皮尔逊 Ⅲ 型曲线的不同降雨工况下的崩滑地质灾 害危险性评价 [J/OL]. 地质科技通报:1-11[2024-01-01].
[3] 陈元峰, 马溪原, 程凯等. 基于气象特征量选取与 SVM 模型参数优化的新 能源超短期功率预测 [J]. 太阳能学报,2023,44(12):568-576.DOI:10.19912/j.0254- 0096.tynxb.2022-1401.
[4] 曹晓勇, 胡秀珍, 张晓瑾. 融合物化特征及结构信息的随机森林算法识别 Ca2+,Mg2+ 和 Mn2+ 结合残基 [J]. 内蒙古工业大学学报 (自然科学版),2018.37(1):22-27.
[5] 韩启迪, 张小桐, 申维. 基于梯度提升决策树 (GBDT) 算法的岩性识别技术 [J]. 矿物岩 石地球化学通报,2018,37(06):1173-1180.DOI:10.19658/j.issn.1007-2802.2019.38.009.
[6] 温博文, 董文瀚, 解武杰等. 基于改进网格搜索算法的随机森林参数优化 [J]. 计算机 工程与应用,2018,54(10):154-157.
[7] 赵小艳, 蒋海昆, 孟令媛等. 基于决策树的川滇地区地震序列类型判定特征重要 性研究 [J/OL]. 地震研究:1-17[2024-01-03].https://doi.org/10.20015/j.cnki.ISSN1000- 0666.2024.0039.
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 旁门左道:借助 HttpClientHandler 拦截请求,体验 Semantic Kernel 插件
前天尝试通过 one-api + dashscope(阿里云灵积) + qwen(通义千问)运行 Semantic Kernel 插件(Plugin) ,结果尝试失败,详见前天的博文。 今天换一种方式尝试,选择了一个旁门左道走走看,看能不能在不使用大模型的情况…
