
✅作者简介:热爱科研的算法开发者,Python、Matlab项目可交流、沟通、学习。
个人主页:算法工程师的学习日志
算法简介
邻近算法,又叫K近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。个人感觉KNN算法(K-NearestNeighbor)一种极其简单粗暴的分类方法,举一个例子,比如说你想知道一个人是不是喜欢打游戏,就可以观察他最亲密的几个朋友是不是都喜欢打游戏,如果大多数都喜欢打游戏,可以推测这个人也喜欢打游戏。KNN就是基于这种有点“物以类聚,人以群分”的简单粗暴的想法来进行分类的。
- kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
- 该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
- kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
算法思路
如果一个样本在特征空间中的 服务器托管网k 个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。通常 K 的取值比较小,不会超过20。
- 计算测试数据与各个训练数据之间的距离
- 按照升序(从小到大)对距离(欧氏距离)进行排序
- 选取距离最小的前k个点
- 确定前k个点所在类别出现的频率
- 返回前k个点中出现频率最高的类别作为测试数据的分类
关于k值的选取
- 当K的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影响,例如取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差,K值的减小就意味着整体模型变得复杂,容易发生过拟合。
- 如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大。这时与输入目标点较远实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单。
- K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
- 常用的方法是从k=1开始,估计分类器的误差率。重复该过程,每次K增值1,允许增加一个近邻,直到产生最小误差率的K。
一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。
KNN算法实现
鸢尾花数据集
Iris 鸢尾花数据集内包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于哪一品种。
iris数据集包含在sklearn库当中,具体在sklearndatasetsdata文件夹下,文件名为iris.csv。以本机为例。其路径如下:
C:ProgramDataAnaconda3Libsite-packagessklearndatasetsdatairis.csv
其中数据如下格式:
第一行数据意义如下:
150:数据集中数据的总条数
4:特征值的类别数,即花萼长度、花萼宽度、花瓣长度、花瓣宽度。
setosa、versicolor、virginica:三种鸢尾花名
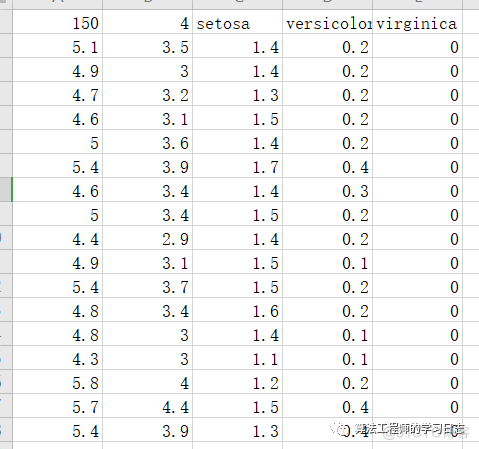
从第二行开始:
第一列为花萼长度值
第二列为花萼宽度值
第三列为花瓣长度值
第四列为花瓣宽度值
第五列对应是种类(三类鸢尾花分别用0,1,2表示)
算法实现
①利用slearn库中的load_iris()导入iris数据集
②使用train_test_split()对数据集进行划分
③KNeighborsClassifier()设置邻居数
④利用fit()构建基于训练集的模型
⑤使用predict()进行预测
⑥使用score()进行模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 载入数据集
iris_dataset = load_iris()
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
# 设置邻居数
knn = KNeighborsClassifier(n_neighbors=3)
# 构建基于训练集的模型
knn.fit(X_train, y_train)
服务器托管网# 一条测试数据
X_new = np.array([[10.2, 10.1, 10.2, 20.2]])
# 对X_new预测结果
prediction = knn.predict(X_new)
print("预测值%d" % prediction)
prediction1 = knn.predict(X_test)
print('predict data')
print(prediction1)
print('ground truth')
print(y_test)
# 得出测试集X_test测试集的分数
print("score:{:.2f}".format(knn.score(X_test, y_test)))服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
