
从数据分析角度,DM分为两类,描述式数据挖掘,预测式数据挖掘。描述式数据挖掘是以简介概要的方式描述数据,并提供数据的一般性质。预测式数据挖掘分析数据建立模型并试图预测新数据集的行为。
DM的分类:
- 描述式DM:以简洁、概要的方式描述数据、提供数据的有趣的一般性质。
- 用以产生数据的特征化和比较描述:
- 特征化:提供给定数据集的简洁汇总(一个数据集)。
- 比较(区分):提供两个或多个数据集的比较描述,其中一个为主数据集,其他数据集与其进行对比分析。
- 预测式DM:分析数据,建立模型,试图预测新数据集的行为。
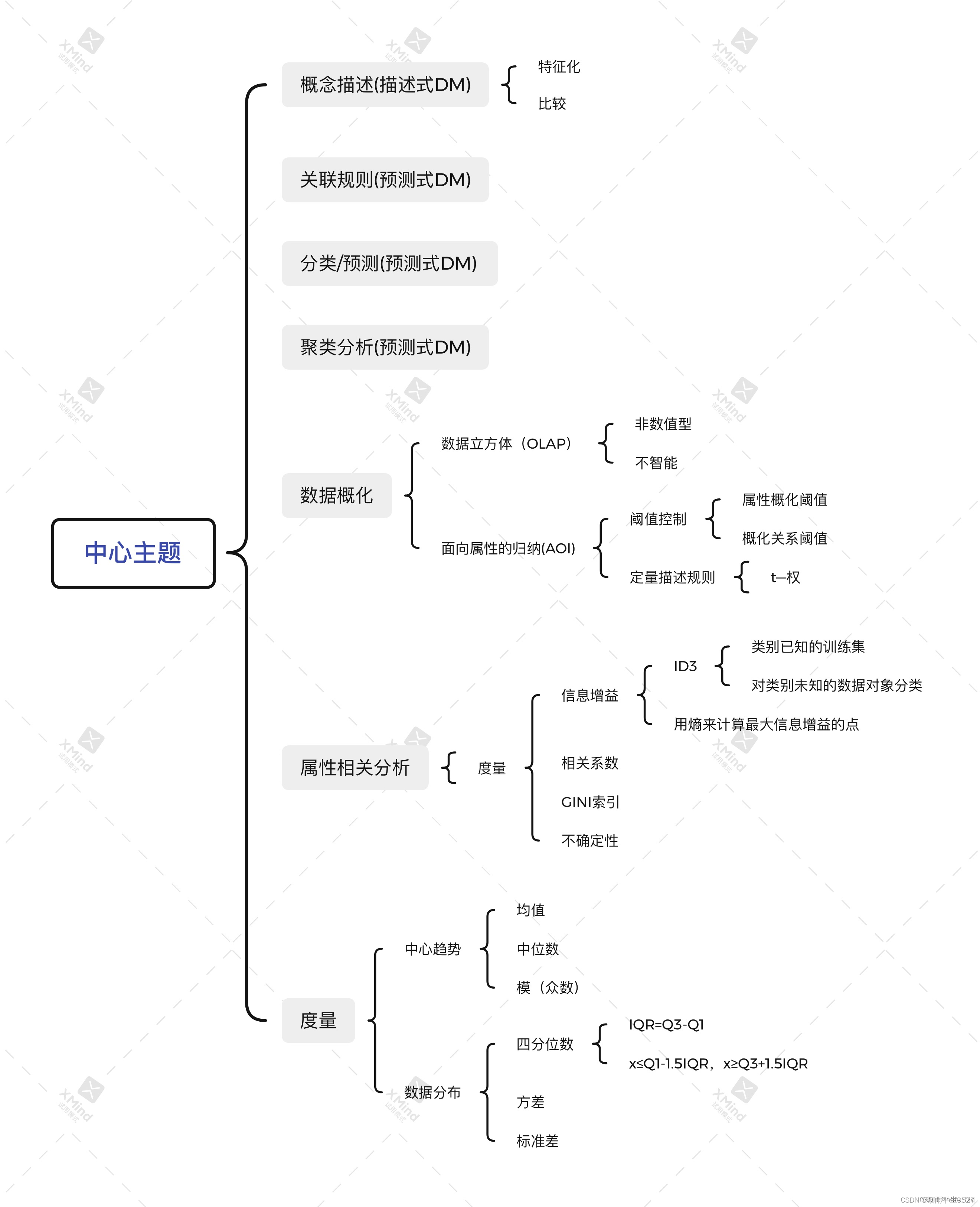
一、数据概化与基于汇总的特征化
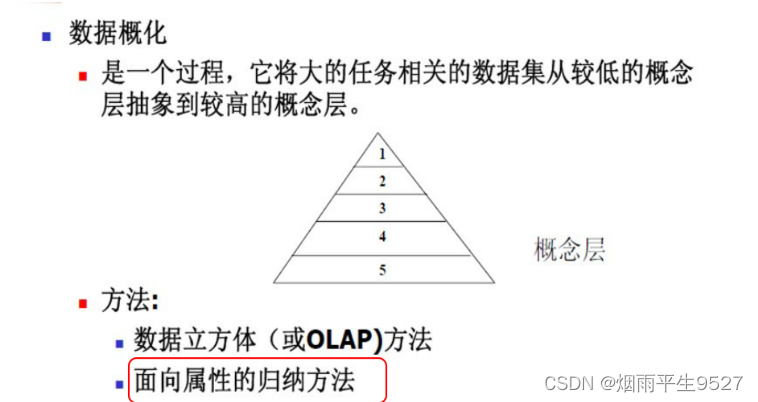
1. 数据概化
- 以更一般的(而不是较低的)抽象层描述数据。
- 将大量的相关数据从一个较低的概念层次转化到一个比较高的层次。
- 例如:把location维度上将地区概化为城市,甚至是省份
- 方法
- 数据立方体(或OLAP)方法
- 面向属性的归纳方法
2. 数据立方体(OLAP)方法
- 在数据立方体上进行计算和存储结果
- 优点:
- 数据概化的一种有效实现。
- 能计算多种不同的度量值。(count、ave、sum、min、max)
- 概化与特征分析通过一系列的数据立方体操作完成,上钻、下钻操作。

- 限制:
* 只能为非数值类型(离散的)维产生的概念分层。
* 非数值类型:名义型、序数型(属于离散化的属性)。
*缺乏智能分析,不能自动确定分析中该使用哪些维,概化到哪个层次。
3. 面向属性归纳(AOI)(重点)
- 前提:有大量不同的取值
- 可处理连续性数据,比数据立方体更加智能
- 基本思想:
- 首先使用DB 收集任务相关的数据。
- 对每个属性的不同值的个数进行概化(属性删除、属性概化)。
- 基本思想:
- 首先使用DB 收集任务相关的数据。
- 对每个属性的不同值的个数进行概化(属性删除、属性概化)。
- 属性删除(重点)
- 一个属性有许多不同数值:且
- 该属性没有定义概化操作符(没有概念分层)。
- 一个属性拥有许多不同的数值,却没有定义对他的泛化操作。
- 或较高层概念可以用其他属性表示。
- eg:出生日期:birth_date:1995-1-1,出生日期是年龄的更高层次,可以将其表现,所以可以将birth_date删除。
- 该属性没有定义概化操作符(没有概念分层)。
- 一个属性有许多不同数值:且
- 属性概化(重点)
- 若一个属性有许多不同数值,且:在该属性上存在概化操作符(有概念分层),则应当选择该概化操作符,并逐层进服务器托管网行概化。
- 概化操作符:层次性,比如birth_day:年月日。
4.特征化(面向属性归纳)
两种方法:
- 属性概化阈值控制:(控制属性取值个数)
- 取值范围:[2-8]
- 属性的不同值个数大于属性概化阈值,则应当删除或概化。
- 概化层次太高,可加大阈值(属性下钻);反之,减小阈值(属性上卷)。
- 概化关系阈值控制:(控制最后的广义元组数量)
- 控制最后关系、规则的大小。(最后生成广义元组)
- 设置阈值:[10-30]
- 概化关系中不同元组的个数超过属性概化阈值,则概化。
- 概化关系太少,可加大阈值(属性下钻服务器托管网);反之,减小阈值(属性上卷)。
- 概化到最高层(最底层)也不满足,则需要将其删除。


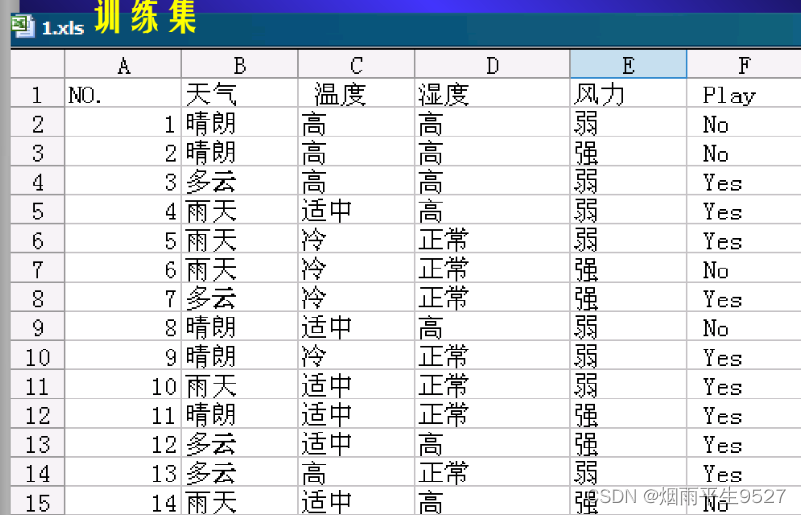
5.例子分析

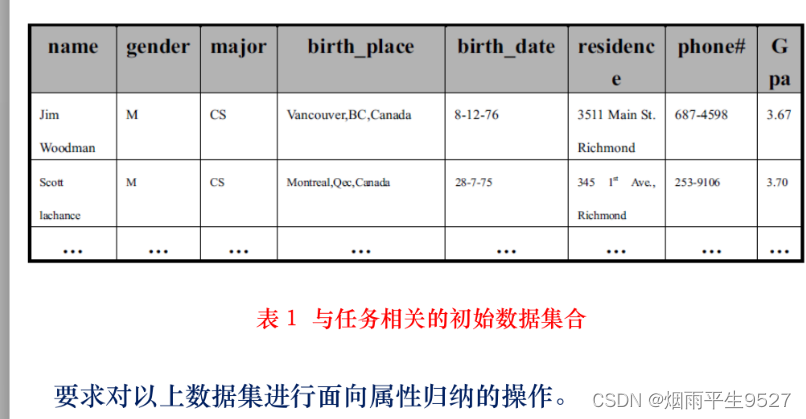
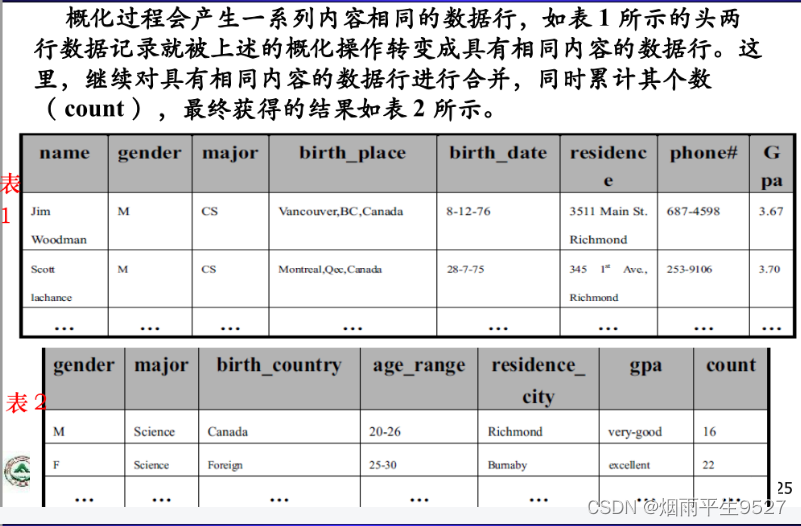
二、属性相关分析(重点)
- 在处理数据中,包含很多与挖掘任务不相关或弱相关的属性,引入属性相关分析。
- 如果某个属性可以很好区分该类与其他类,则该属性是任务高度相关的。
- 在处理数据中,包含很多与挖掘任务不相关或弱相关的属性,引入属性相关分析。
- 如果某个属性可以很好区分该类与其他类,则该属性是任务高度相关的。
1. 属性相关分析法基本思想
- 基本思想:给定的数据集,计算某种度量,用于量化属性与给定的类或概念间的相关性。
- 常用的度量:信息增益、相关系数、GINI索引、不确定性
2.信息增益法(重点)
-
信息增益法:
- 决策树归纳学习算法(ID3,C4.5),删除信息量较少的属性,保留信息量较大的属性。
-
ID3算法
-
熵概念为启发函数。
-

-
熵越大、携带的信息量越大、越不容易被预测
-
- 选择具有最大信息增益的属性作为当前划分节点。
- 基本原理:
- 根据类别已知的训练数据集构造一颗决策树;根据决策树再对类别未知的数据对象进行分类。
- 每一步选择都是选择最大信息增益。
- 决策树:每个节点的选择:选择信息增益最大的属性为当前节点。
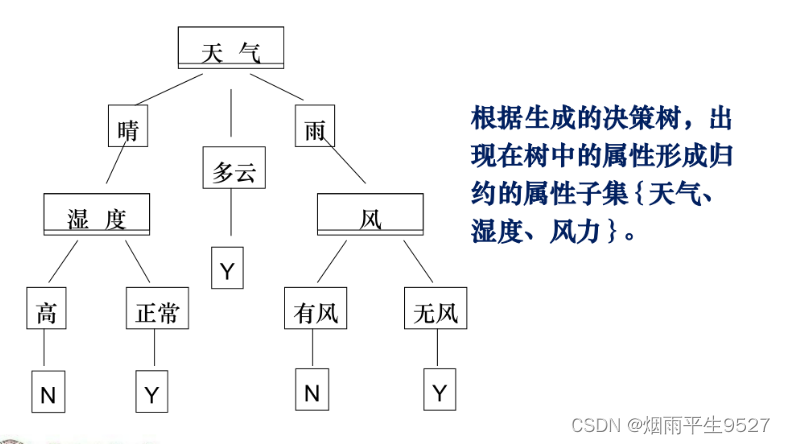
- 本步骤只是求出不确定性


-
熵概念为启发函数。
3. 通过熵来进行选择



4.属性相关分析步骤
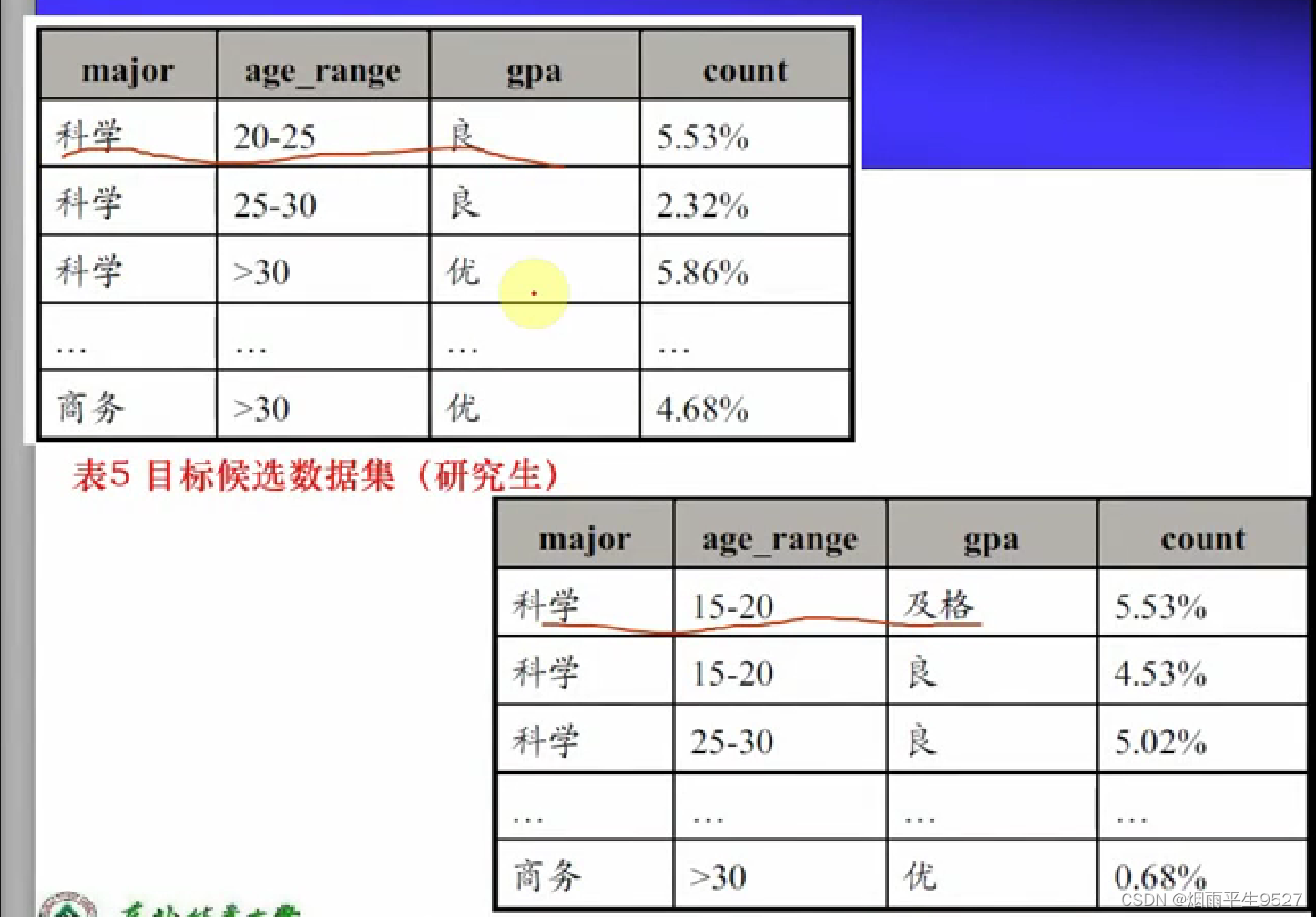
- 数据收集:建立目标数据集,以及对比数据集,目标数据集与对比数据集不相交。
- 利用保守的AOI方法进行属性相关分析。对初始的数据集进行删除、概化等操作形成候选数据集。
- 删除不相关、弱相关的属性。如信息增益度量
- 使用AOI产生概念描述:利用更严格的属性概化控制阈值进行属性的归纳。
- 任务是:概念描述,使用初始目标数据集。
- 任务是:比较概念描述,使用初始目标数据集,对比数据集。
三、挖掘类比较:区分不同的类


- 比较概念中,同一个属性要概化到同一个层次。
- d—权
- qa所包含的Cj中数据行数与qa所涵盖的所有数据行数(包括目标数据集及所有对比数据集)之比
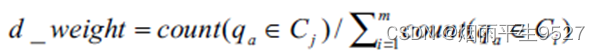
- qa所包含的Cj中数据行数与qa所涵盖的所有数据行数(包括目标数据集及所有对比数据集)之比
 四、常见的统计度量指标
四、常见的统计度量指标

- 中心趋势:均值、中位数、模(众数)
- 众数:如果每个数值仅出现1次则无众数
- 数据分布:四分位数、方差、标准差
- 四分位数:
- 数值下数据集合的第k个百分位数。
- 中位数:第50个百分位数
- 第一个四分位数
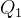 第25个百分位数;第三个百分位数
第25个百分位数;第三个百分位数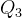 :第75个百分位数
:第75个百分位数 - 中间四分位区间
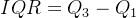
- 识别孤立点:
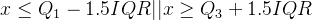

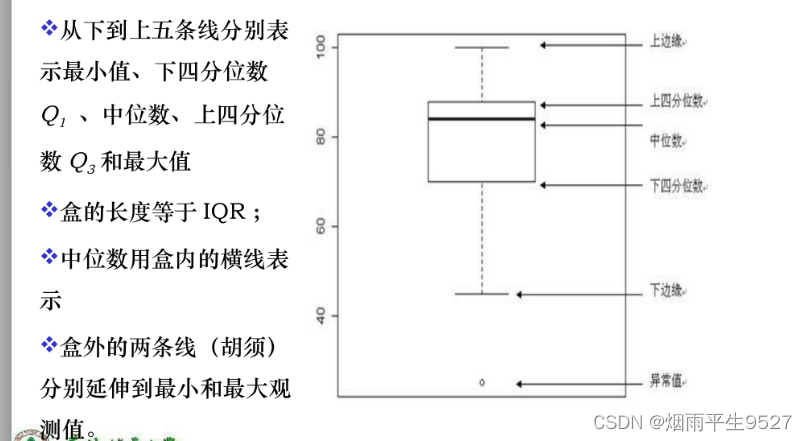
- 四分位数:
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
