
大家好,我是三友~~
今天来继续探秘系列,扒一扒轻量级的分布式任务调度平台Xxl-Job背后的架构原理
公众号:三友的java日记
核心概念
这里还是老样子,为了保证文章的完整性和连贯性,方便那些没有使用过的小伙伴更加容易接受文章的内容,快速讲一讲Xxl-Job中的概念和使用
如果你已经使用过了,可直接跳过本节和下一节,快进到后面原理部分讲解
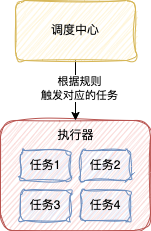
1、调度中心
调度中心是一个单独的Web服务,主要是用来触发定时任务的执行
它提供了一些页面操作,我们可以很方便地去管理这些定时任务的触发逻辑
调度中心依赖数据库,所以数据都是存在数据库中的
调度中心也支持集群模式,但是它们所依赖的数据库必须是同一个
所以同一个集群中的调度中心实例之间是没有任何通信的,数据都是通过数据库共享的

2、执行器
执行器是用来执行具体的任务逻辑的
执行器你可以理解为就是平时开发的服务,一个服务实例对应一个执行器实例
每个执行器有自己的名字,为了方便,你可以将执行器的名字设置成服务名
3、任务
任务什么意思就不用多说了
一个执行器中也是可以有多个任务的
总的来说,调用中心是用来控制定时任务的触发逻辑,而执行器是具体执行任务的,这是一种任务和触发逻辑分离的设计思想,这种方式的好处就是使任务更加灵活,可以随时被调用,还可以被不同的调度规则触发。
来个Demo
1、搭建调度中心
调度中心搭建很简单,先下载源码
https://github.com/xuxueli/xxl-job.git
然后改一下数据库连接信息,执行一下在项目源码中的/doc/db下的sql文件
启动可以打成一个jar包,或者本地启动就是可以的
启动完成之后,访问下面这个地址就可以访问到控制台页面了
http://localhost:8080/xxl-job-admin/toLo服务器托管网gin
用户名密码默认是 admin/123456
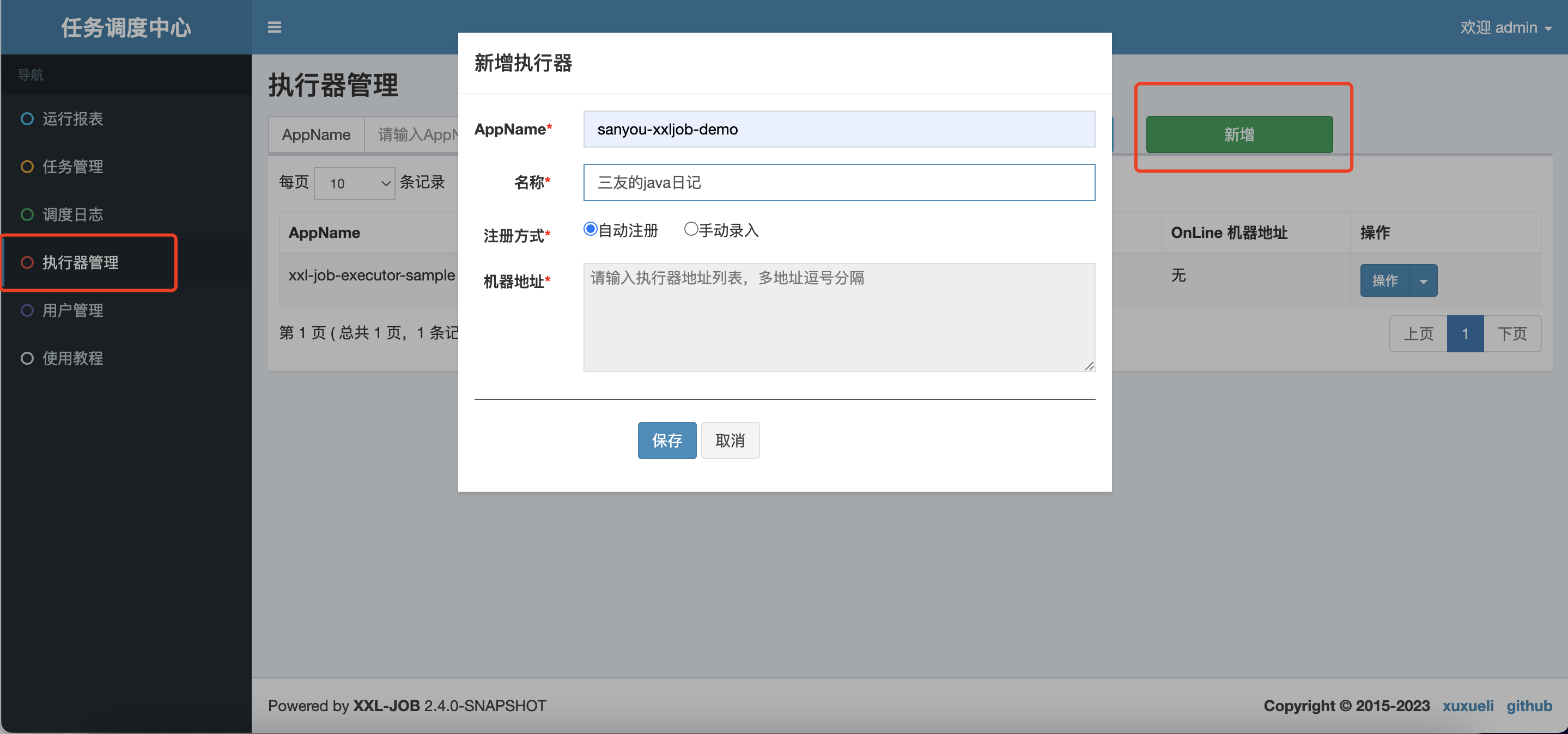
2、执行器和任务添加
添加一个名为sanyou-xxljob-demo执行器
任务添加
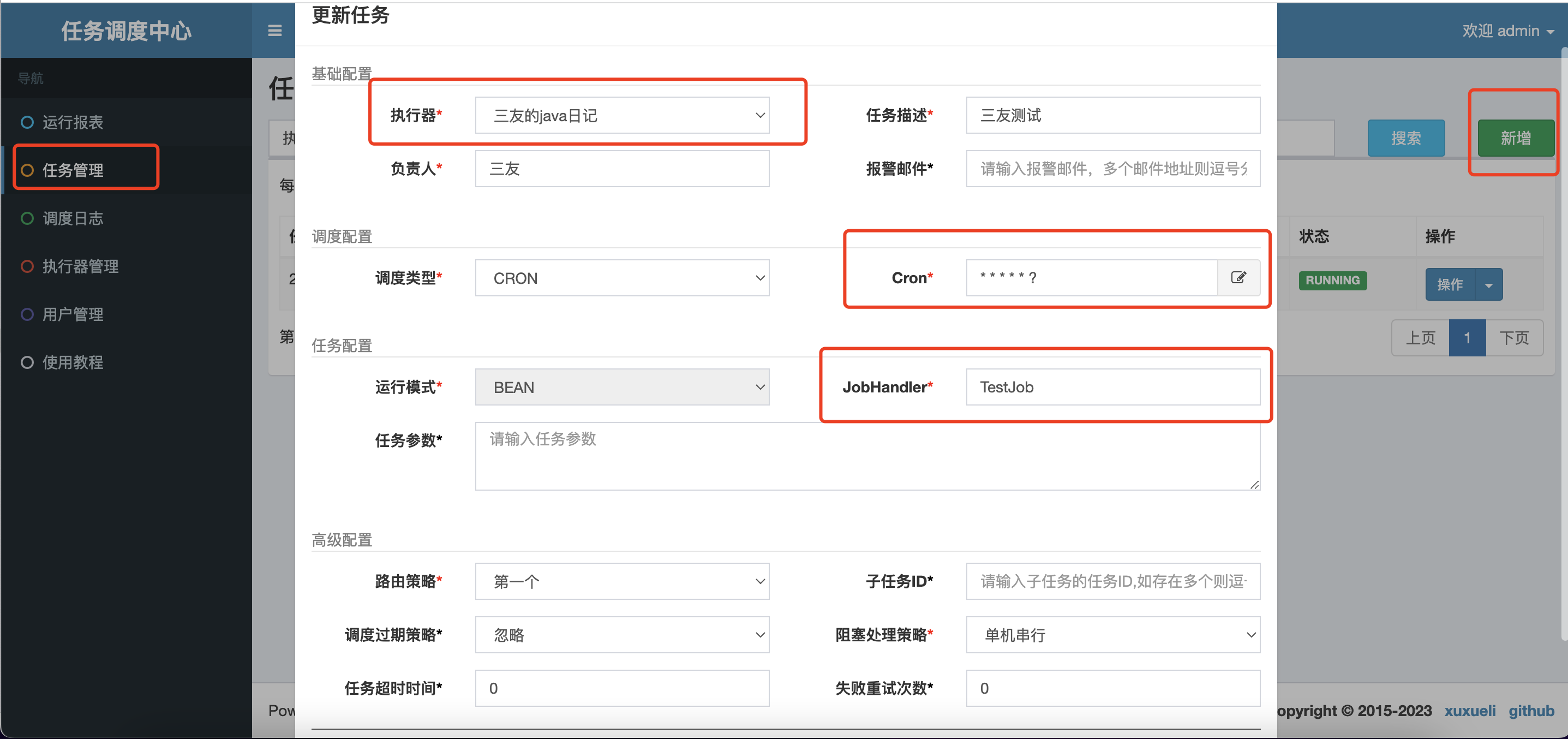
执行器选择我们刚刚添加的,指定任务名称为TestJob,corn表达式的意思是每秒执行一次
创建完之后需要启动一下任务,默认是关闭状态,也就不会执行
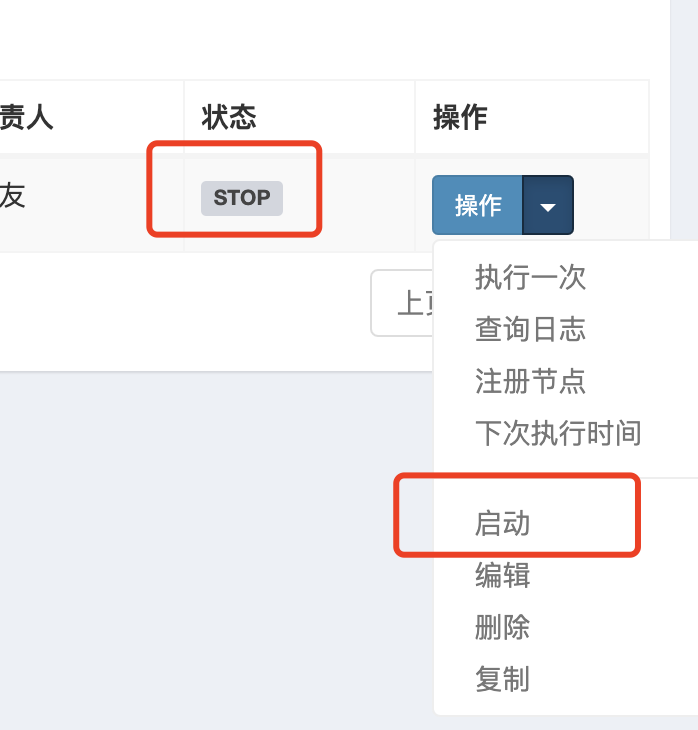
创建执行器和任务其实就是CRUD,并没有复杂的业务逻辑
按照如上配置的整个Demo的意思就是
每隔1s,执行一次sanyou-xxljob-demo这个执行器中的TestJob任务
3、创建执行器和任务
引入依赖
dependencies>
dependency>
groupId>org.springframework.bootgroupId>
artifactId>spring-boot-starter-webartifactId>
version>2.2.5.RELEASEversion>
dependency>
dependency>
groupId>com.xuxueligroupId>
artifactId>xxl-job-coreartifactId>
version>2.4.0version>
dependency>
dependencies>
配置XxlJobSpringExecutor这个Bean
@Configuration
publicclassXxlJobConfiguration{
@Bean
publicXxlJobSpringExecutorxxlJobExecutor(){
XxlJobSpringExecutorxxlJobSpringExecutor=newXxlJobSpringExecutor();
//设置调用中心的连接地址
xxlJobSpringExecutor.setAdminAddresses("http://localhost:8080/xxl-job-admin");
//设置执行器的名称
xxlJobSpringExecutor.setAppname("sanyou-xxljob-demo");
//设置一个端口,后面会讲作用
xxlJobSpringExecutor.setPort(9999);
//这个token是保证访问安全的,默认是这个,当然可以自定义,
//但需要保证调度中心配置的xxl.job.accessToken属性跟这个token是一样的
xxlJobSpringExecutor.setAccessToken("default_token");
//任务执行日志存放的目录
xxlJobSpringExecutor.setLogPath("./");
returnxxlJobSpringExecutor;
}
}
XxlJobSpringExecutor这个类的作用,后面会着重讲
通过@XxlJob指定一个名为TestJob的任务,这个任务名需要跟前面页面配置的对应上
@Component
publicclassTestJob{
privatestaticfinalLoggerlogger=LoggerFactory.getLogger(TestJob.class);
@XxlJob("TestJob")
publicvoidtestJob(){
logger.info("TestJob任务执行了。。。");
}
}
所以如果顺利的话,每隔1s钟就会打印一句TestJob任务执行了。。。
启动项目,注意修改一下端口,因为调用中心默认也是8080,本地起会端口冲突
最终执行结果如下,符合预期

讲完概念和使用部分,接下来就来好好讲一讲Xxl-Job核心的实现原理
从执行器启动说起
前面Demo中使用到了一个很重要的一个类
XxlJobSpringExecutor
这个类就是整个执行器启动的入口
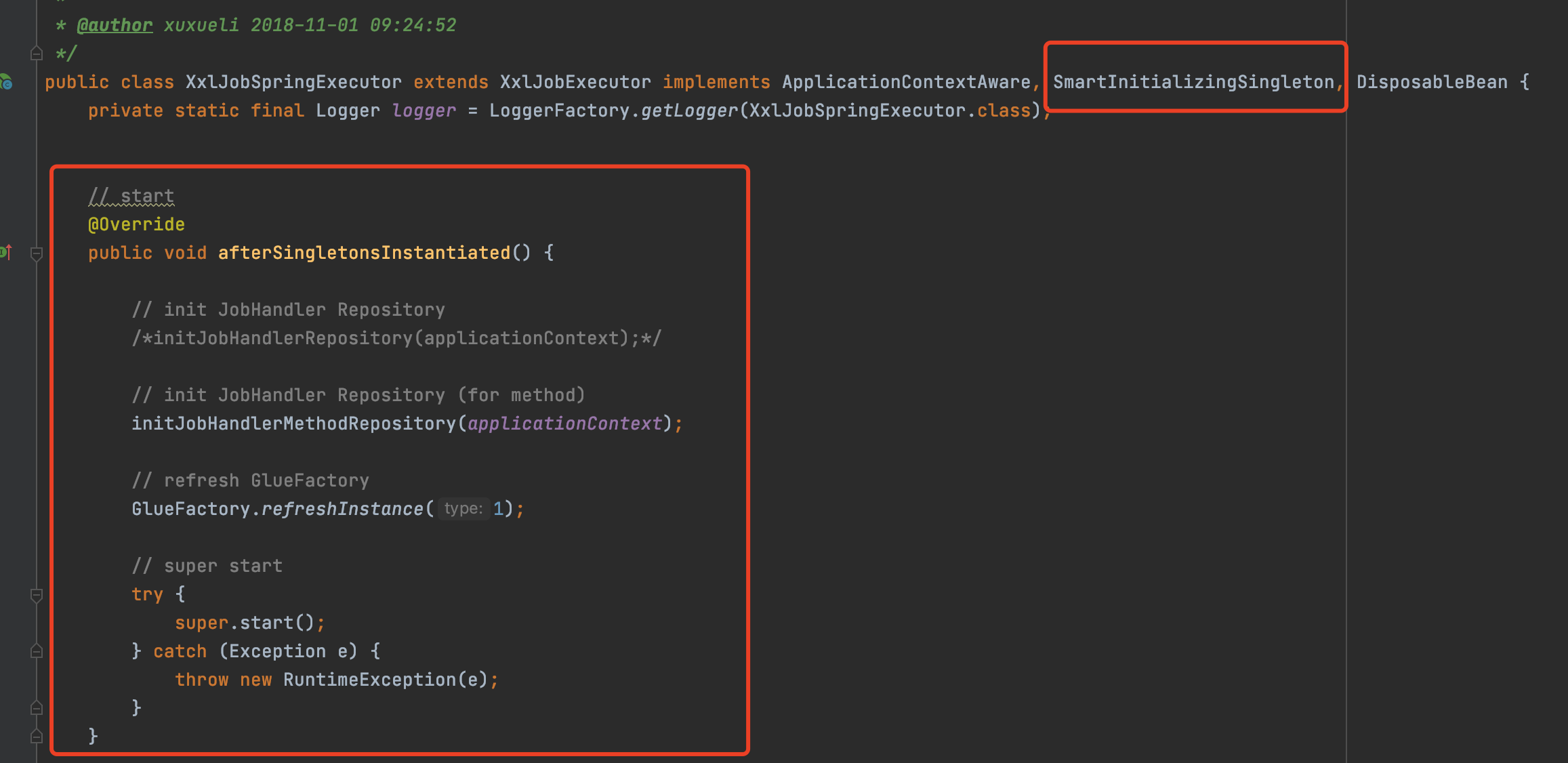
这个类实现了SmartInitializingSingleton接口
所以经过Bean的生命周期,一定会调用afterSingletonsInstantiated这个方法的实现
这个方法干了很多初始化的事,这里我挑三个重要的讲,其余的等到具体的功能的时候再提
1、初始化JobHandler
JobHandler是个什么?
所谓的JobHandler其实就是一个定时任务的封装
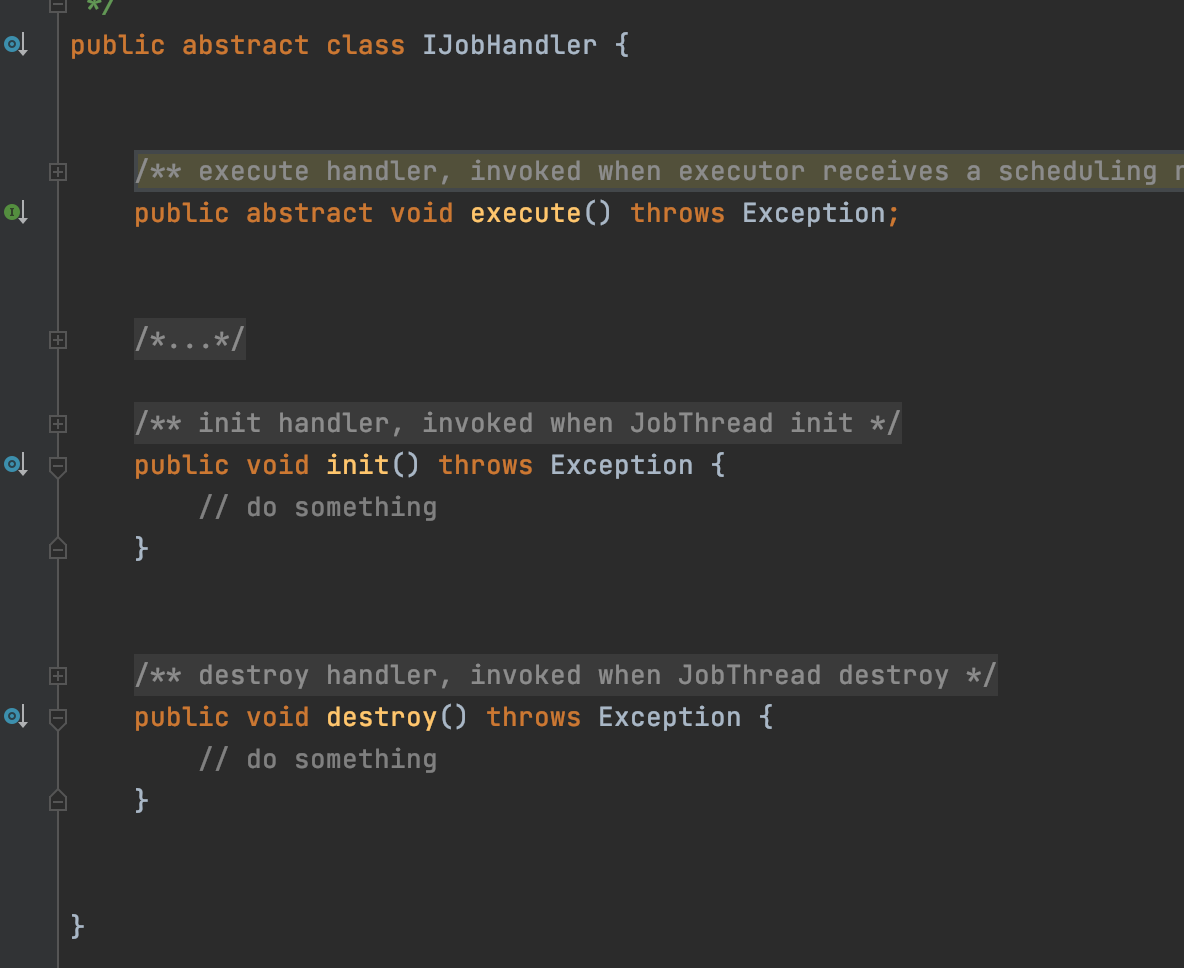
一个定时任务会对应一个JobHandler对象
当执行器执行任务的时候,就会调用JobHandler的execute方法
JobHandler有三种实现:
-
MethodJobHandler -
GlueJobHandler -
ScriptJobHandler
MethodJobHandler是通过反射来调用方法执行任务
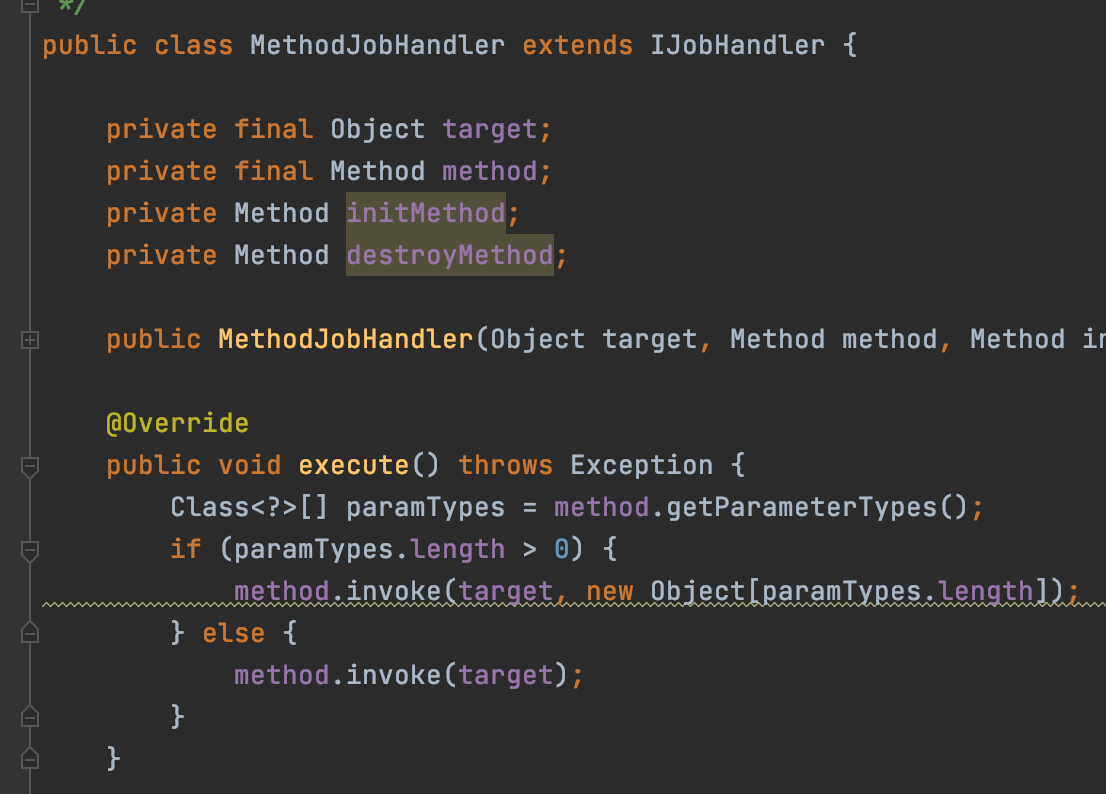
所以MethodJobHandler的任务的实现就是一个方法,刚好我们demo中的例子任务其实就是一个方法
所以Demo中的任务最终被封装成一个MethodJobHandler
GlueJobHandler比较有意思,它支持动态修改任务执行的代码
当你在创建任务的时候,需要指定运行模式为GLUE(Java)
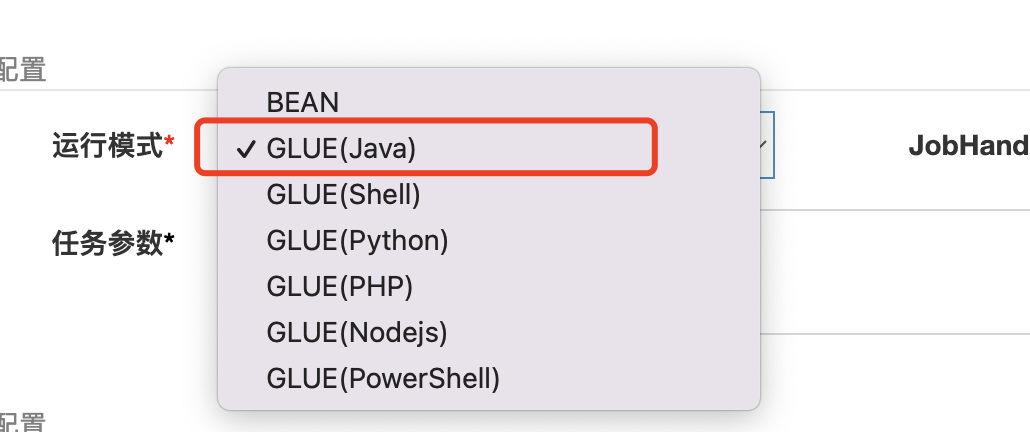
之后需要在操作按钮点击GLUE IDE编写Java代码
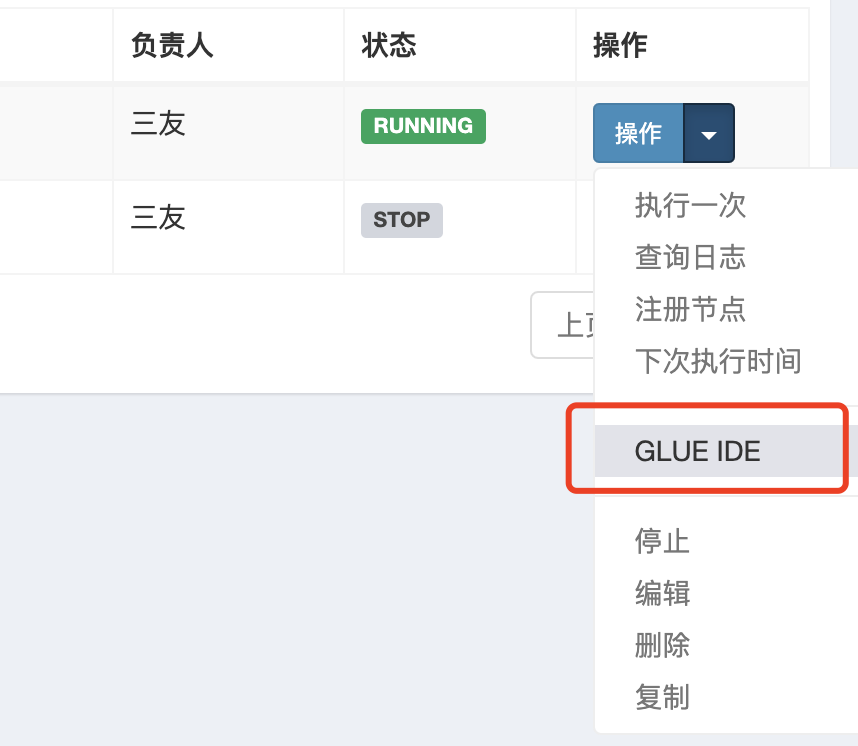
代码必须得实现IJobHandler接口,之服务器托管网后任务执行的时候就会执行execute方法的实现
如果你需要修改任务的逻辑,只需要重新编辑即可,不需要重启服务
ScriptJobHandler,通过名字也可以看出,是专门处理一些脚本的
运行模式除了BEAN和GLUE(Java)之外,其余都是脚本模式
而本节的主旨,所谓的初始化JobHandler就是指,执行器启动的时候会去Spring容器中找到加了@XxlJob注解的Bean
解析注解,然后封装成一个MethodJobHandler对象,最终存到XxlJobSpringExecutor成员变量的一个本地的Map缓存中
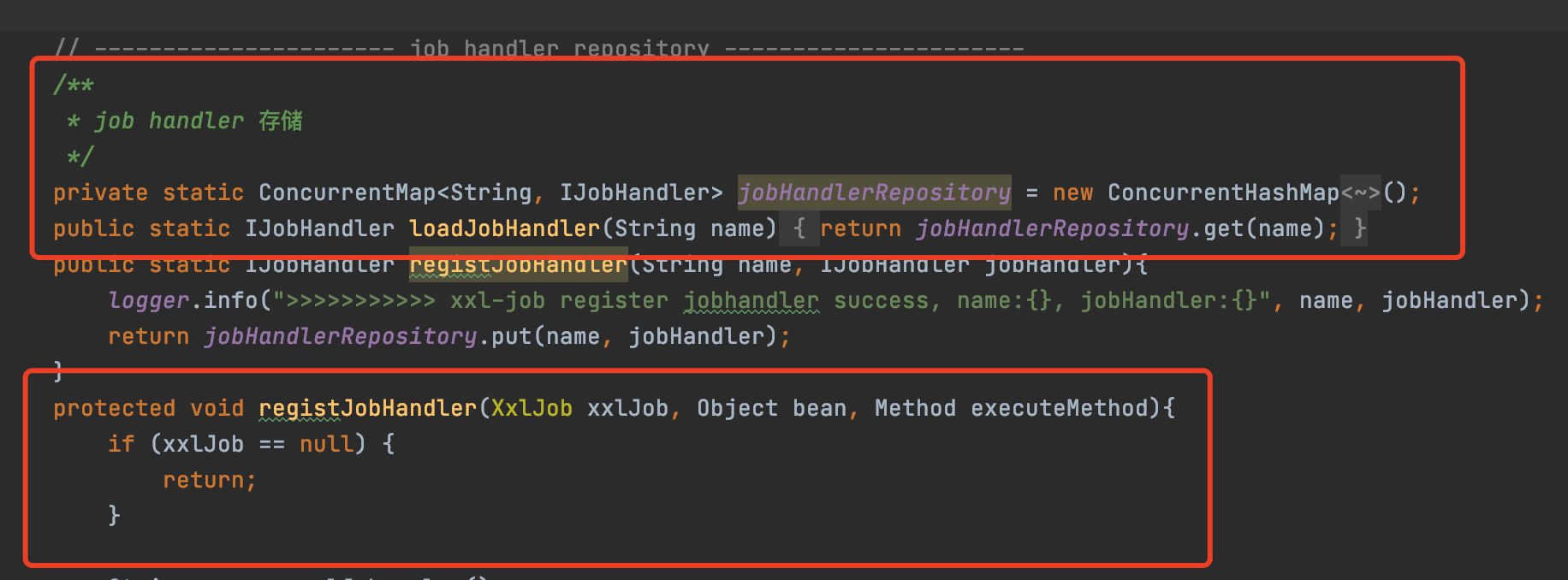
缓存key就是任务的名字
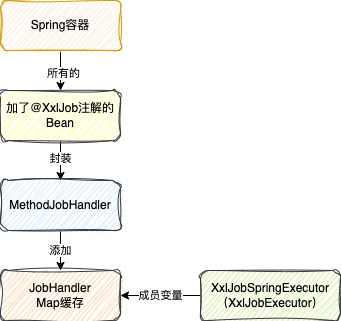
至于GlueJobHandler和ScriptJobHandler都是任务触发时才会创建
除了上面这几种,你也自己实现JobHandler,手动注册到JobHandler的缓存中,也是可以通过调度中心触发的
2、创建一个Http服务器
除了初始化JobHandler之外,执行器还会创建一个Http服务器
这个服务器端口号就是通过XxlJobSpringExecutor配置的端口,demo中就是设置的是9999,底层是基于Netty实现的
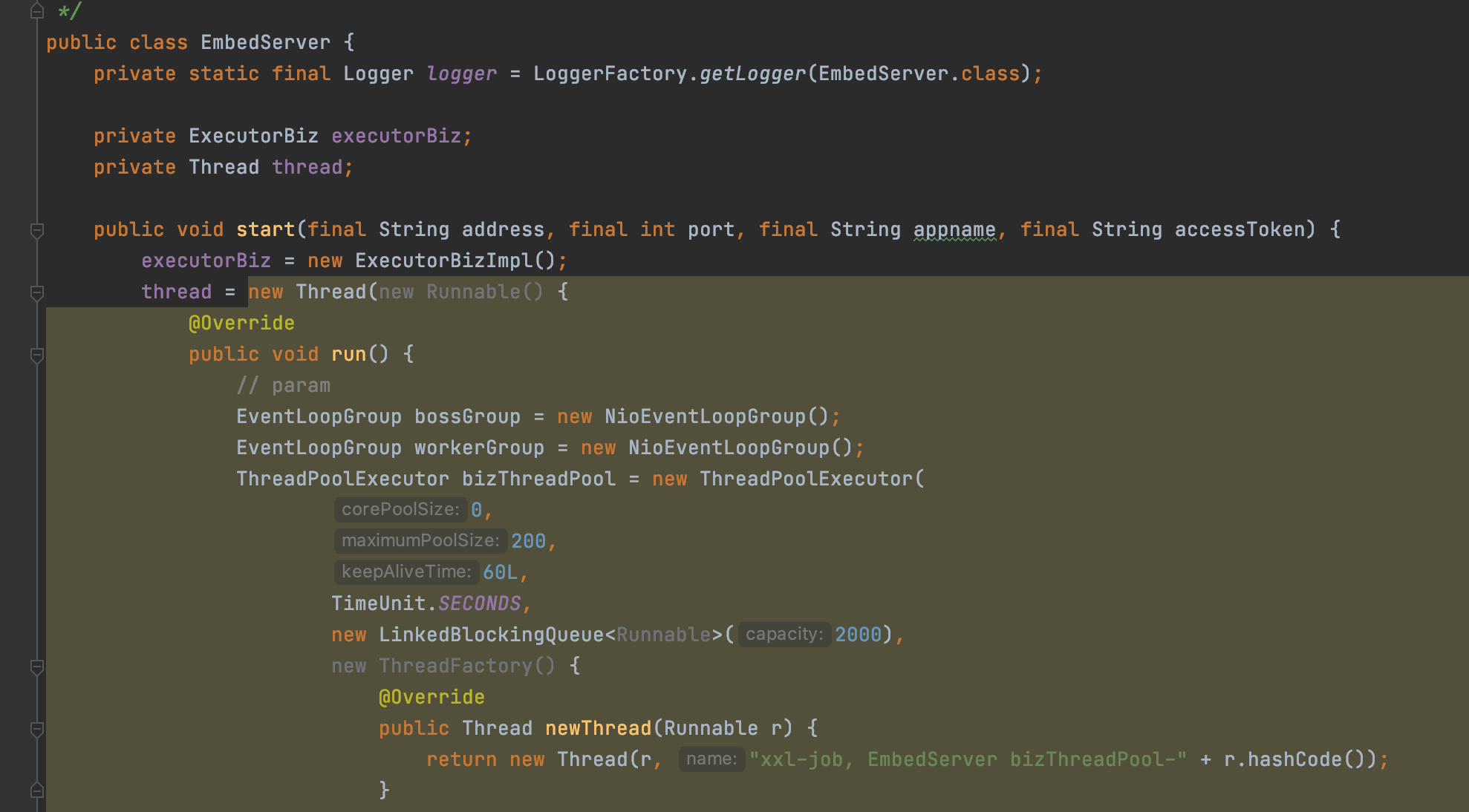
这个Http服务端会接收来自调度中心的请求
当执行器接收到调度中心的请求时,会把请求交给ExecutorBizImpl来处理
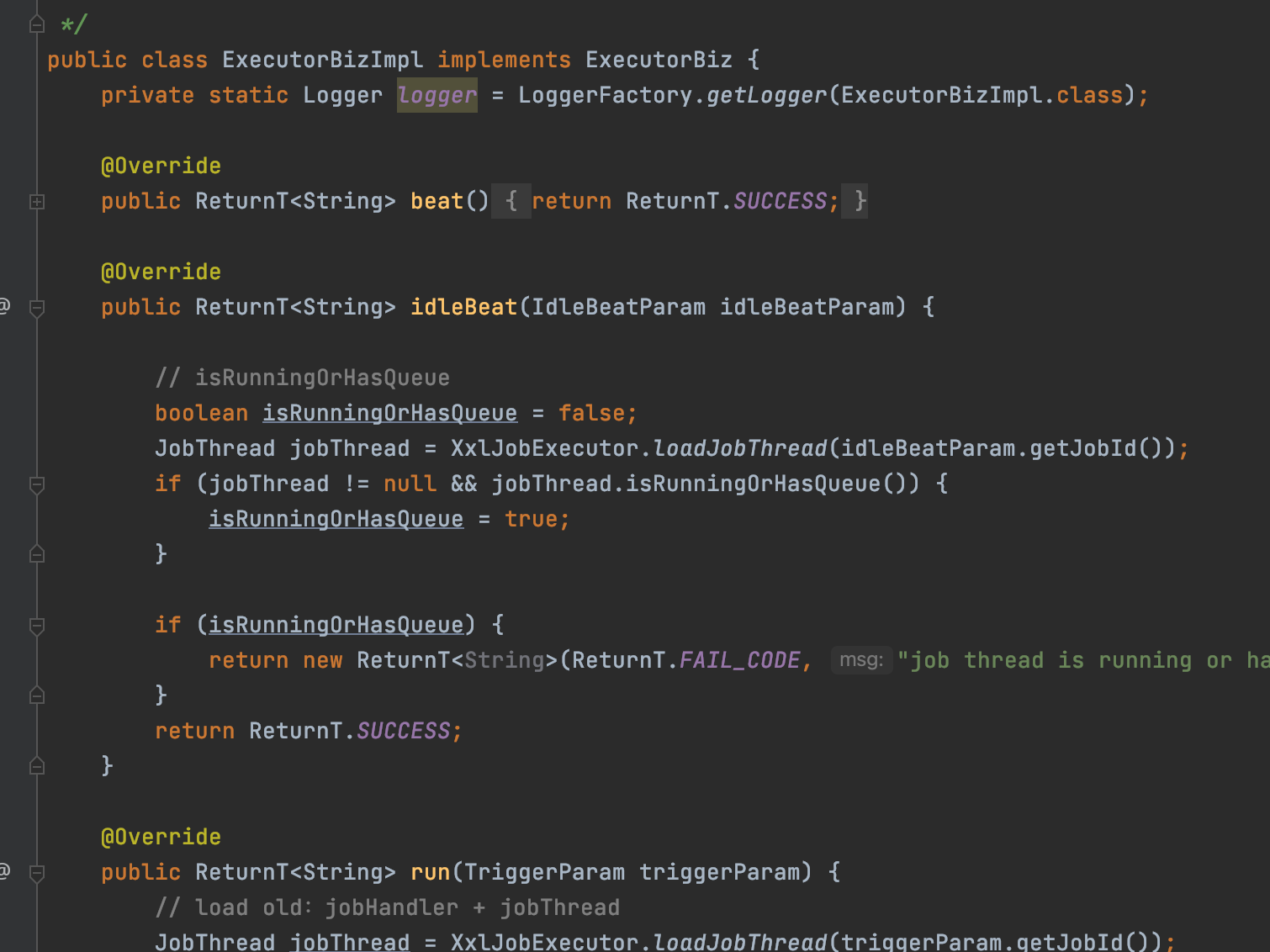
这个类非常重要,所有调度中心的请求都是这里处理的
ExecutorBizImpl实现了ExecutorBiz接口
当你翻源码的时候会发现,ExecutorBiz还有一个ExecutorBizClient实现
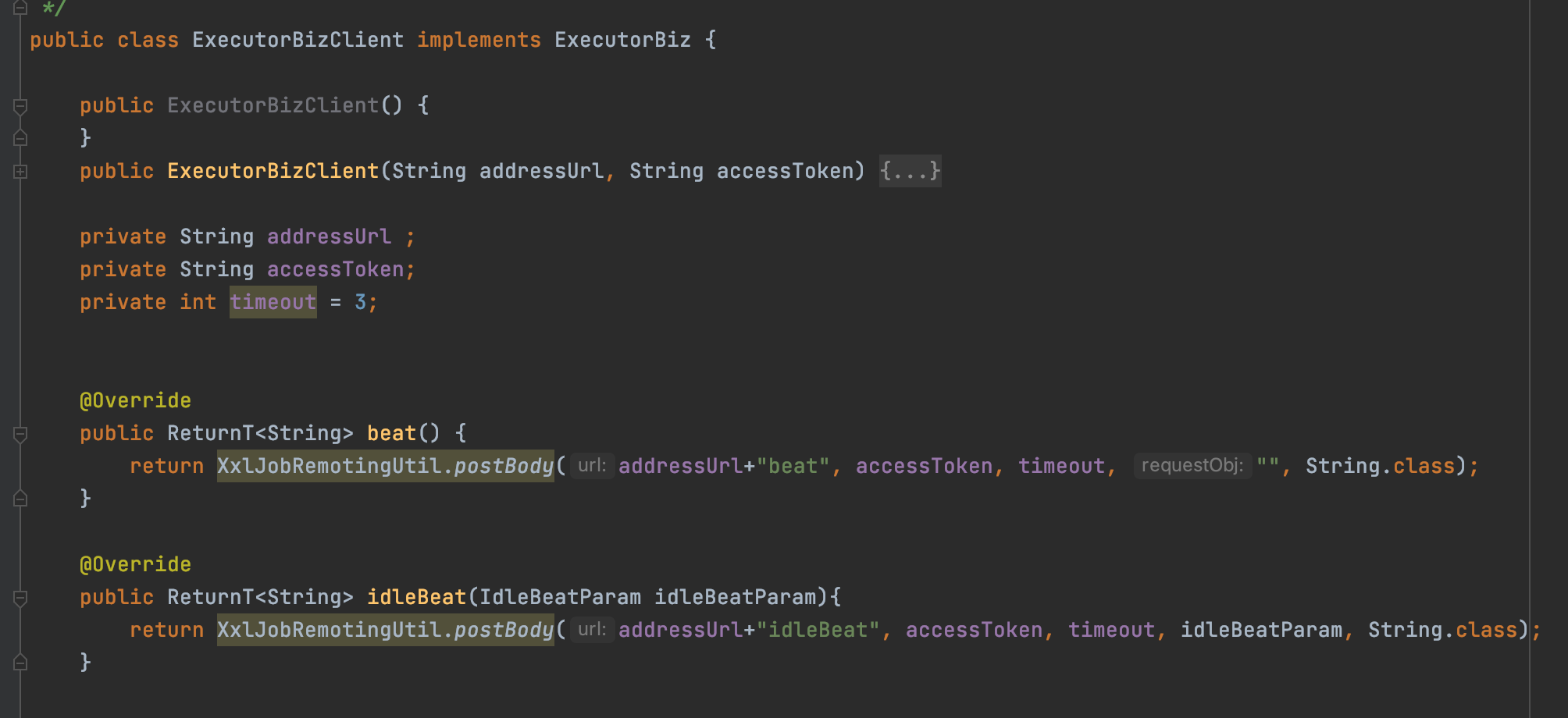
ExecutorBizClient的实现就是发送http请求,所以这个实现类是在调度中心使用的,用来访问执行器提供的http接口

3、注册到调度中心
当执行器启动的时候,会启动一个注册线程,这个线程会往调度中心注册当前执行器的信息,包括两部分数据
-
执行器的名字,也就是设置的appname -
执行器所在机器的ip和端口,这样调度中心就可以访问到这个执行器提供的Http接口
前面提到每个服务实例都会对应一个执行器实例,所以调用中心会保存每个执行器实例的地址
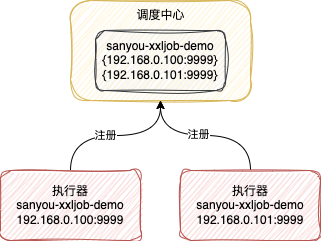
这里你可以把调度中心的功能类比成注册中心
任务触发原理
弄明白执行器启动时干了哪些事,接下来讲一讲Xxl-Job最最核心的功能,那就是任务触发的原理
任务触发原理我会分下面5个小点来讲解
-
任务如何触发? -
快慢线程池的异步触发任务优化 -
如何选择执行器实例? -
执行器如何去执行任务? -
任务执行结果的回调
1、任务如何触发?
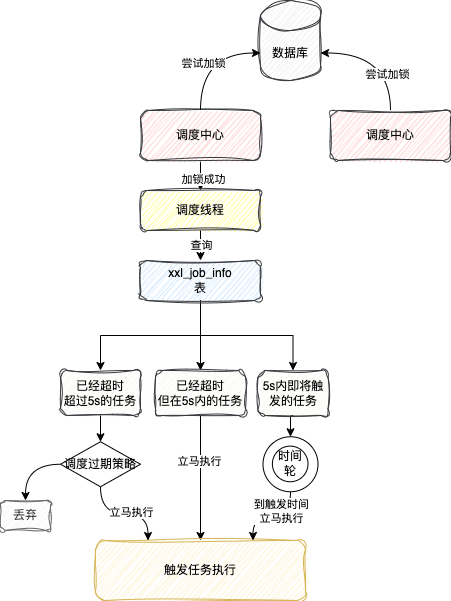
调度中心在启动的时候,会开启一个线程,这个线程的作用就是来计算任务触发时机,这里我把这个线程称为调度线程
这个调度线程会去查询xxl_job_info这张表
这张表存了任务的一些基本信息和任务下一次执行的时间
调度线程会去查询下一次执行的时间 的任务
这个5s是XxlJob写死的,被称为预读时间,提前读出来,保证任务能准时触发
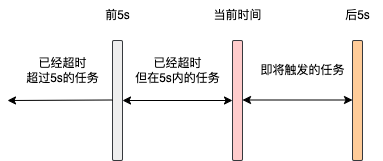
举个例子,假设当前时间是2023-11-29 08:00:10,这里的查询就会查出下一次任务执行时间在2023-11-29 08:00:15之前执行的任务

查询到任务之后,调度线程会去将这些任务根据执行时间划分为三个部分:
-
当前时间已经超过任务下一次执行时间5s以上,也就是需要在 2023-11-29 08:00:05(不包括05s)之前的执行的任务 -
当前时间已经超过任务下一次执行时间,但是但不足5s,也就是在 2023-11-29 08:00:05和2023-11-29 08:00:10(不包括10s)之间执行的任务 -
还未到触发时间,但是一定是5s内就会触发执行的
对于第一部分的已经超过5s以上时间的任务,会根据任务配置的调度过期策略来选择要不要执行
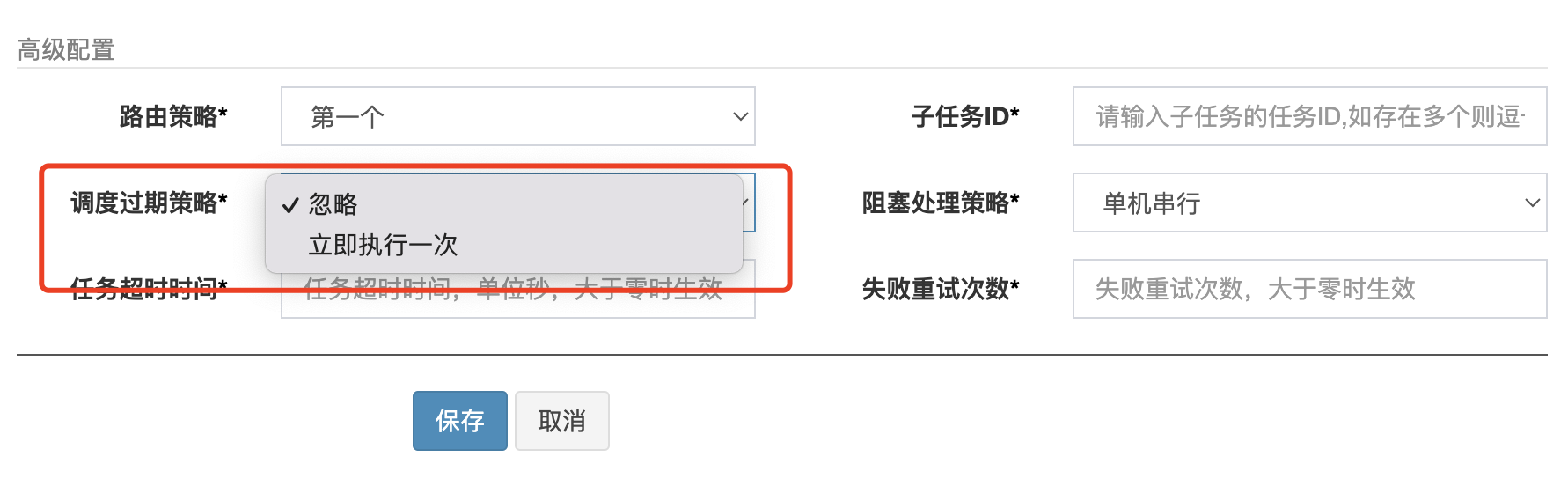
调度过期策略就两种,就是字面意思
-
直接忽略这个已经过期的任务 -
立马执行一次这个过期的任务
对于第二部分的超时时间在5s以内的任务,就直接立马执行一次,之后如果判断任务下一次执行时间就在5s内,会直接放到一个时间轮里面,等待下一次触发执行
对于第三部分任务,由于还没到执行时间,所以不会立马执行,也是直接放到时间轮里面,等待触发执行
当这批任务处理完成之后,不论是前面是什么情况,调度线程都会去重新计算每个任务的下一次触发时间,然后更新xxl_job_info这张表的下一次执行时间
到此,一次调度的计算就算完成了
之后调度线程还会继续重复上面的步骤,查任务,调度任务,更新任务下次执行时间,一直死循环下去,这就实现了任务到了执行时间就会触发的功能
这里在任务触发的时候还有一个很有意思的细节
由于调度中心可以是集群的形式,每个调度中心实例都有调度线程,那么如何保证任务在同一时间只会被其中的一个调度中心触发一次?
我猜你第一时间肯定想到分布式锁,但是怎么加呢?
XxlJob实现就比较有意思了,它是基于八股文中常说的通过数据库来实现的分布式锁的
在调度之前,调度线程会尝试执行下面这句sql
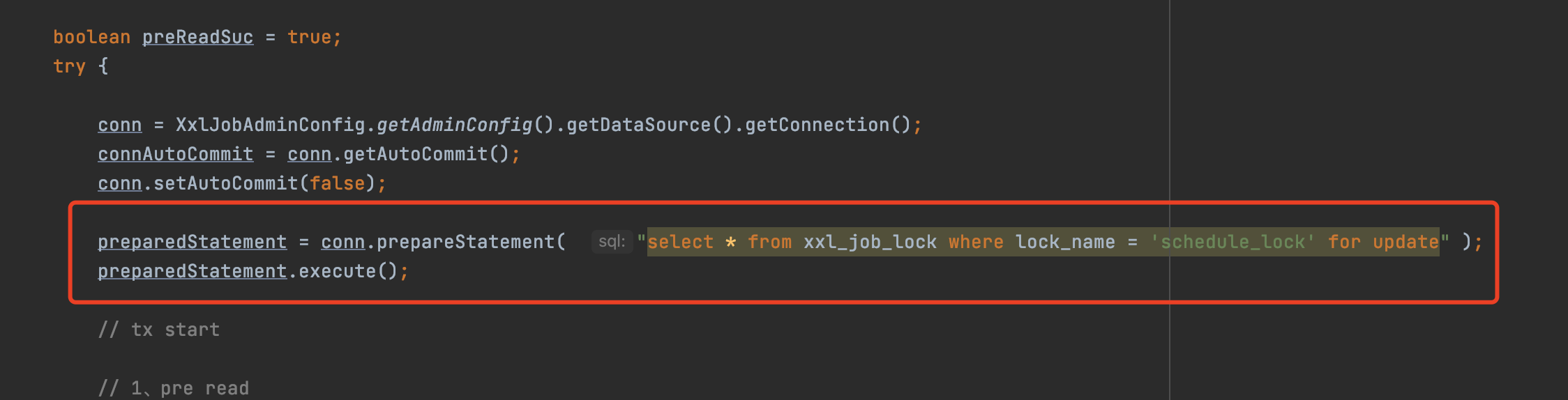
就是这个sql
select * from xxl_job_lock where lock_name = ‘schedule_lock’ for update
一旦执行成功,说明当前调度中心成功抢到了锁,接下来就可以执行调度任务了
当调度任务执行完之后再去关闭连接,从而释放锁
由于每次执行之前都需要去获取锁,这样就保证在调度中心集群中,同时只有一个调度中心执行调度任务
最后画一张图来总结一下这一小节
2、快慢线程池的异步触发任务优化
当任务达到了触发条件,并不是由调度线程直接去触发执行器的任务执行
调度线程会将这个触发的任务交给线程池去执行
所以上图中的最后一部分触发任务执行其实是线程池异步去执行的
那么,为什么要使用线程池异步呢?
主要是因为触发任务,需要通过Http接口调用具体的执行器实例去触发任务

这一过程必然会耗费时间,如果调度线程去做,就会耽误调度的效率
所以就通过异步线程去做,调度线程只负责判断任务是否需要执行
并且,Xxl-Job为了进一步优化任务的触发,将这个触发任务执行的线程池划分成快线程池和慢线程池两个线程池

在调用执行器的Http接口触发任务执行的时候,Xxl-Job会去记录每个任务的触发所耗费的时间
注意并不是任务执行时间,只是整个Http请求耗时时间,这是因为执行器执行任务是异步执行的,所以整个时间不包括任务执行时间,这个后面会详细说
当任务一次触发的时间超过500ms,那么这个任务的慢次数就会加1
如果这个任务一分钟内触发的慢次数超过10次,接下来就会将触发任务交给慢线程池去执行
所以快慢线程池就是避免那种频繁触发并且每次触发时间还很长的任务阻塞其它任务的触发的情况发生
3、如何选择执行器实例?
上一节说到,当任务需要触发的时候,调度中心会向执行器发送Http请求,执行器去执行具体的任务
那么问题来了
由于一个执行器会有很多实例,那么应该向哪个实例请求?
这其实就跟任务配置时设置的路由策略有关了
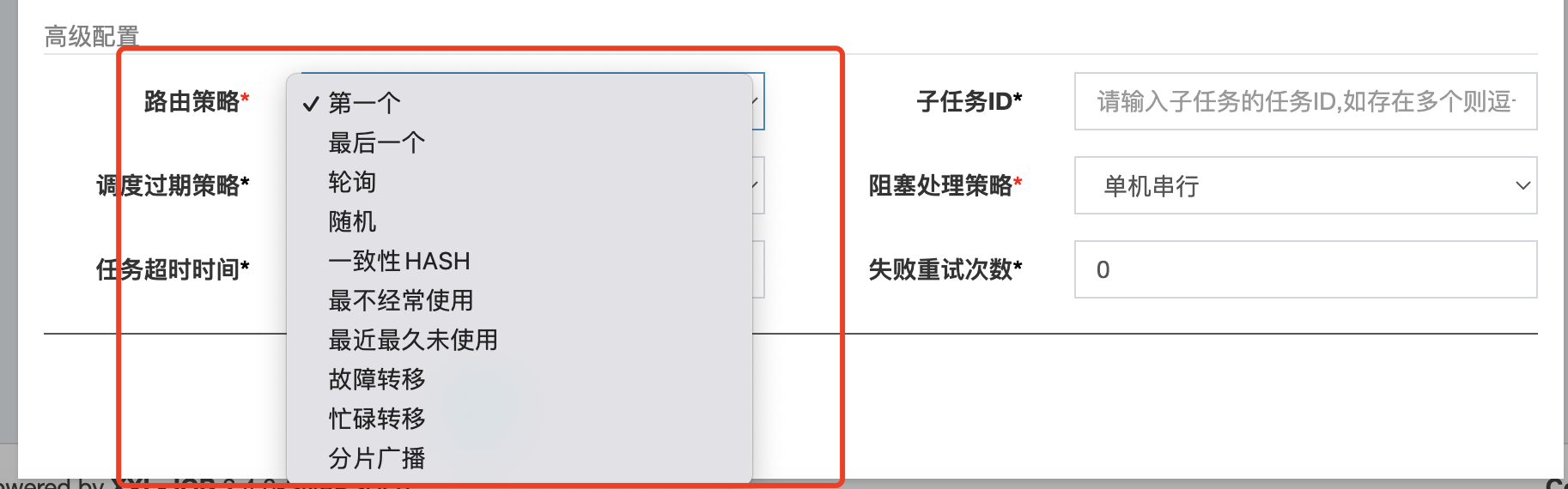
从图上可以看出xxljob支持多种路由策略
除了分片广播,其余的具体的算法实现都是通过ExecutorRouter的实现类来实现的
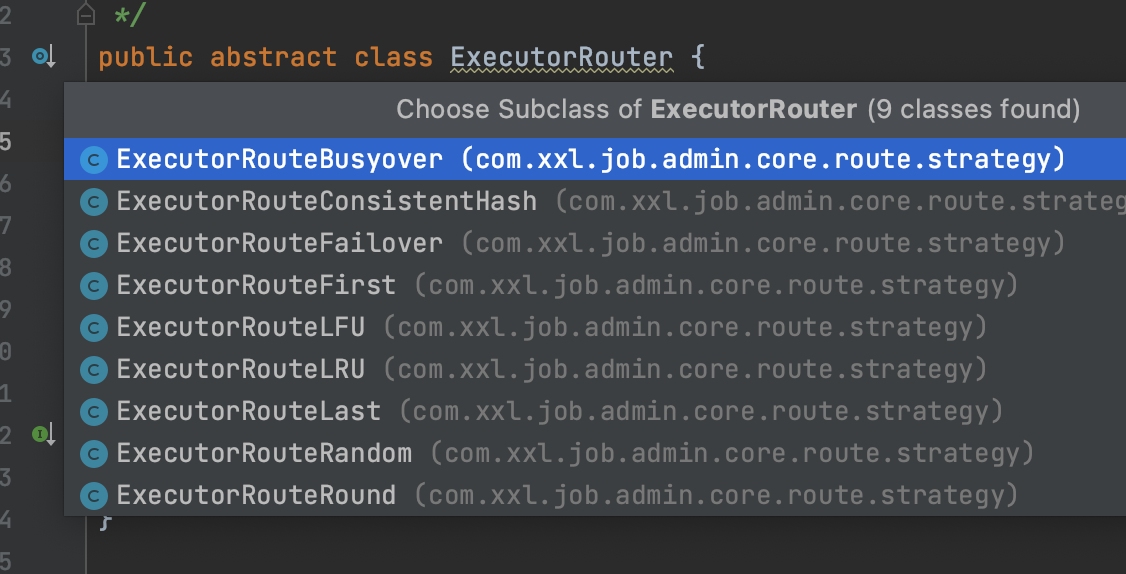
这里简单讲一讲各种算法的原理,有兴趣的小伙伴可以去看看内部的实现细节
第一个、最后一个、轮询、随机都很简单,没什么好说的
一致性Hash讲起来比较复杂,你可以先看看这篇文章,再去查看Xxl-Job的代码实现
https://zhuanlan.zhihu.com/p/470368641
最不经常使用(LFU:Least Frequently Used):Xxl-Job内部会有一个缓存,统计每个任务每个地址的使用次数,每次都选择使用次数最少的地址,这个缓存每隔24小时重置一次
最近最久未使用(LRU:Least Recently Used):将地址存到LinkedHashMap中,它利用LinkedHashMap可以根据元素访问(get/put)顺序来给元素排序的特性,快速找到最近最久未使用(未访问)的节点
故障转移:调度中心都会去请求每个执行器,只要能接收到响应,说明执行器正常,那么任务就会交给这个执行器去执行
忙碌转移:调度中心也会去请求每个执行器,判断执行器是不是正在执行当前需要执行的任务(任务执行时间过长,导致上一次任务还没执行完,下一次又触发了),如果在执行,说明忙碌,不能用,否则就可以用
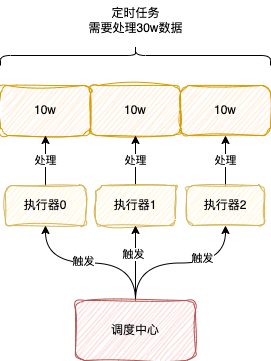
分片广播:XxlJob给每个执行器分配一个编号,从0开始递增,然后向所有执行器触发任务,告诉每个执行器自己的编号和总共执行器的数据
我们可以通过XxlJobHelper#getShardIndex获取到编号,XxlJobHelper#getShardTotal获取到执行器的总数据量
分片广播就是将任务量分散到各个执行器,每个执行器只执行一部分任务,加快任务的处理
举个例子,比如你现在需要处理30w条数据,有3个执行器,此时使用分片广播,那么此时可将任务分成3分,每份10w条数据,执行器根据自己的编号选择对应的那份10w数据处理
当选择好了具体的执行器实例之后,调用中心就会携带一些触发的参数,发送Http请求,触发任务
4、执行器如何去执行任务?
相信你一定记得我前面在说执行器启动是会创建一个Http服务器的时候提到这么一句
当执行器接收到调度中心的请求时,会把请求交给ExecutorBizImpl来处理
所以前面提到的故障转移和忙碌转移请求执行器进行判断,最终执行器也是交给ExecutorBizImpl处理的
执行器处理触发请求是这个ExecutorBizImpl的run方法实现的
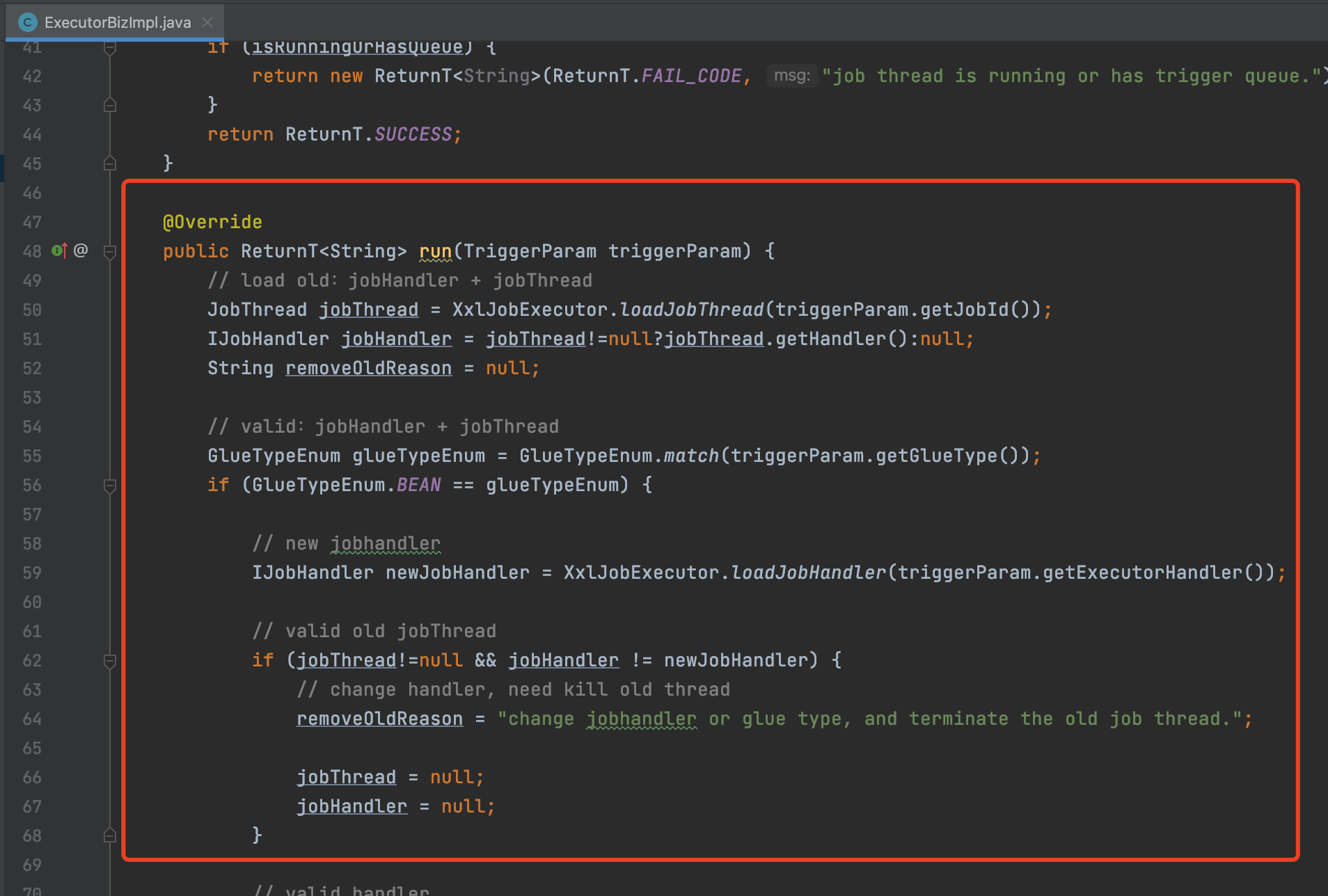
当执行器接收到请求,在正常情况下,执行器会去为这个任务创建一个单独的线程,这个线程被称为JobThread
每个任务在触发的时候都有单独的线程去执行,保证不同的任务执行互不影响
之后任务并不是直接交给线程处理的,而是直接放到一个内存队列中,线程直接从队列中获取任务
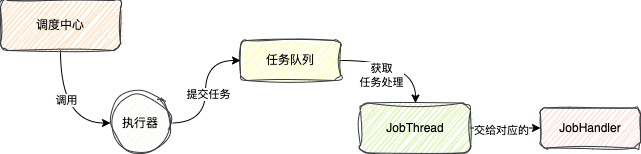
这里我相信你一定有个疑惑
为什么不直接处理,而是交给队列,从队列中获取任务呢?
那就得讲讲不正常的情况了
如果调度中心选择的执行器实例正在处理定时任务,那么此时该怎么处理呢?**
这时就跟阻塞处理策略有关了
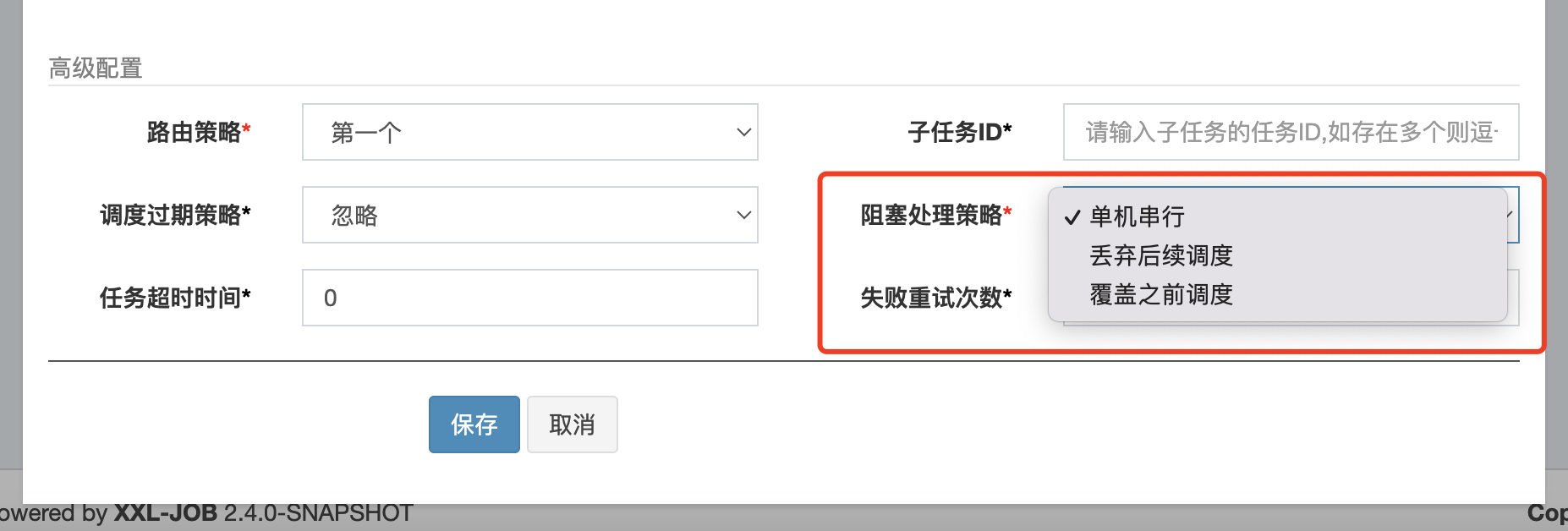
阻塞处理策略总共有三种:
-
单机串行 -
丢弃后续调度 -
覆盖之前调度
单机串行的实现就是将任务放到队列中,由于队列是先进先出的,所以就实现串行,这也是为什么放在队列的原因
丢弃调度的实现就是执行器什么事都不用干就可以了,自然而然任务就丢了
覆盖之前调度的实现就很暴力了,他是直接重新创建一个JobThread来执行任务,并且尝试打断之前的正在处理任务的JobThread,丢弃之前队列中的任务
打断是通过Thread#interrupt方法实现的,所以正在处理的任务还是有可能继续运行,并不是说一打断正在运行的任务就终止了
这里需要注意的一点就是,阻塞处理策略是对于单个执行器上的任务来生效的,不同执行器实例上的同一个任务是互不影响的
比如说,有一个任务有两个执行器A和B,路由策略是轮询
任务第一次触发的时候选择了执行器实例A,由于任务执行时间长,任务第二次触发的时候,执行器的路由到了B,此时A的任务还在执行,但是B感知不到A的任务在执行,所以此时B就直接执行了任务
所以此时你配置的什么阻塞处理策略就没什么用了
如果业务中需要保证定时任务同一时间只有一个能运行,需要把任务路由到同一个执行器上,比如路由策略就选择第一个
5、任务执行结果的回调
当任务处理完成之后,执行器会将任务执行的结果发送给调度中心

如上图所示,这整个过程也是异步化的
-
JobThread会将任务执行的结果发送到一个内存队列中 -
执行器启动的时候会开启一个处发送任务执行结果的线程:TriggerCallbackThread -
这个线程会不停地从队列中获取所有的执行结果,将执行结果批量发送给调度中心 -
调用中心接收到请求时,会根据执行的结果修改这次任务的执行状态和进行一些后续的事,比如失败了是否需要重试,是否有子任务需要触发等等
到此,一次任务的就算真正处理完成了
最后
最后我从官网捞了一张Xxl-Job架构图
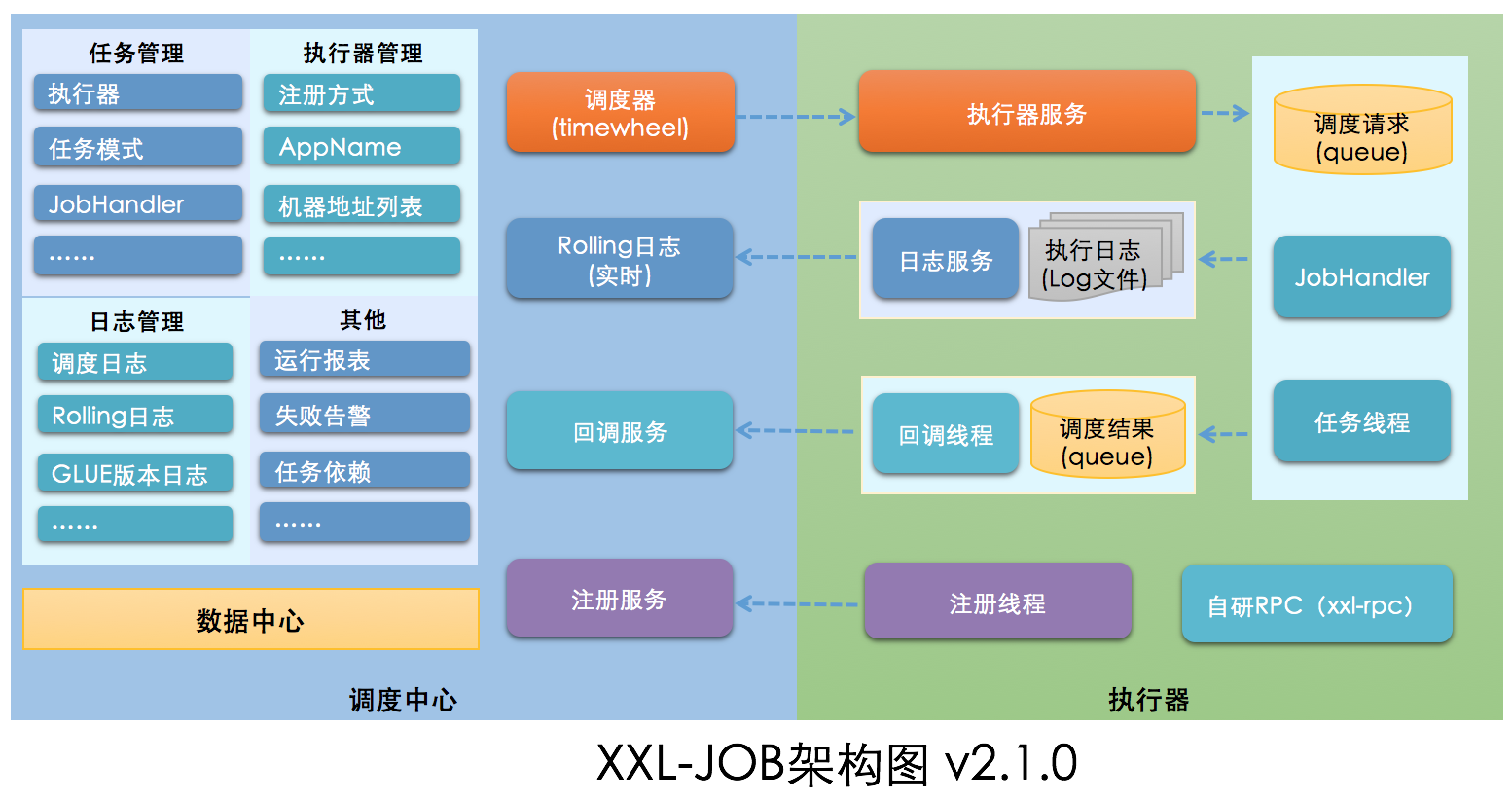
奈何作者不更新呐,导致这个图稍微有点老了,有点跟现有的架构对不上
比如说图中的自研RPC(xxl-rpc)部分已经替换成了Http协议,这主要是拥抱生态,方便跨语言接入
但是不要紧,大体还是符合现在的整个的架构
从架构图中也可以看出来,本文除了日志部分的内容没有提到,其它的整个核心逻辑基本上都讲到了
而日志部分其实是个辅助的作用,让你更方便查看任务的运行情况,对任务的触发逻辑是没有影响的,所以就没讲了
所以从本文的讲解再到官方架构图,你会发现整个Xxl-Job不论是使用还是实现都是比较简单的,非常的轻量级
说点什么
好了,到这又又成功讲完了一款框架或者说是中间件的核心架构原理,不知道你有没有什么一点收获
如果你觉得有点收获,欢迎点赞、在看、收藏、转发分享给其他需要的人
你的支持就是我更新文章最大的动力,非常地感谢!
其实这篇文章我在十一月上旬的时候我就打算写了
但是由于十一月上旬之后我遇到一系列烦心事,导致我实在是没有精力去写
现在到月底了,虽然烦心事只增不少,但是我还是想了想,觉得不能再拖了,最后也是连续肝了几个晚上,才算真正完成
所以如果你发现文章有什么不足和问题,也欢迎批评指正
当这篇文章快写完的时候,我收到了来自阿里云社区的颁发的专家博主的证书,也算为即将过去的十一月画下了一个不太完美的句号

好了,本文就讲到这里了,让我们十二月再见,拜拜!
往期热门文章推荐
如何去阅读源码,我总结了18条心法
如何写出漂亮代码,我总结了45个小技巧
三万字盘点Spring/Boot的那些常用扩展点
三万字盘点Spring 9大核心基础功能
万字+20张图剖析Spring启动时12个核心步骤
1.5万字+30张图盘点索引常见的11个知识点
两万字盘点那些被玩烂了的设计模式
扫码或者搜索关注公众号 三友的java日记 ,及时干货不错过,公众号致力于通过画图加上通俗易懂的语言讲解技术,让技术更加容易学习,回复 面试 即可获得一套面试真题。

服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
