

作者简介
谢怡,网易有道高级大数据开发工程师,目前主要参与实时计算和湖仓一体方向的研发
王涛,网易资深平台开发工程师,主要从事大数据和湖仓平台建设
业务背景
有道的数据层架构可分为离线和实时两部分,离线计算主要采用Hive、Spark,采用批处理的方式定时调度。实时部分采用 Flink+Doris(版本 0.14.0)构建实时数仓,用于处理实时埋点日志、业务库变更数据。ODS 层数据源为 Kafka 埋点日志、数据库业务数据,DWD、DWS层数据通过Flink计算引擎加工,写入 Doris 中。同时将 Doris 数据定时同步至 Hive,用于离线调度计算。该架构存在如下问题:
- 开发和运维成本高:Flink SQL 与 Hive/Spark 语法差异大,Hive/Spark 向 Flink 迁移成本高,Flink 大状态任务运维服务器托管网和优化难度高。
- 在全增量流式读取场景的支持性较弱,难以满足有道场景下 Flink 全量读取 Hive 历史数据及 Kafka 增量数据的需求。
- 流批存储不统一,造成双倍的数据开发和存储成本,且容易造成数据口径不一致。
- Doris 作为数据孤岛,采用 SSD 存储,成本较高,不适合大规模词典日志数据存储,长期两套存储方案不利于成本优化。
- 需要持续地在 Hive 和 Doris 之间导入导出数据,链路过长容易引入不稳定因素,比如大规模数据写入时,Doris 导出 Hive 偶发数据丢失,并且不支持储存长 String 类型的字符串。
 结合上述问题,有道希望从 Hive 升级为湖仓一体方案,支持流批读写,统一数据存储。并基于 Spark/Trino/Hive ETL 搭建分钟/小时级近实时数仓,降低开发和运维成本,在绝大多数场景下替换 Doris 的分钟级数仓场景,减少数据库数据同步成本,有效降本增效。
结合上述问题,有道希望从 Hive 升级为湖仓一体方案,支持流批读写,统一数据存储。并基于 Spark/Trino/Hive ETL 搭建分钟/小时级近实时数仓,降低开发和运维成本,在绝大多数场景下替换 Doris 的分钟级数仓场景,减少数据库数据同步成本,有效降本增效。
引入 Amoro Mixed Hive
Amoro Mixed H服务器托管网ive 提供了Hive 读写兼容、数据自优化的能力,基于此提供了两种不同时效性读取的能力:
- Merge on read 可以达到分钟级数据新鲜度
- Hive 读可以达到小时级新鲜度 同时也实现了对 Hive 数据的更新和删除,下游老 Hive 任务无需作任何修改即可享受数据时效性提升到小时级,对于习惯使用 Hive 的分析师来讲可以做到无感,降低了新技术的使用门槛。
Hive 表格式兼容
Amoro 为了兼容 Hive 设计了 Mixed Hive,Mixed Hive 的存储结构如图, BaseStore 是一张独立的 iceberg 表,Hive 表作为 BaseStore 的一部分,ChangeStore 是一张独立的 iceberg 表, Mixed Hive 支持:
- schema、partition、types 与 Hive format 保持一致
- 使用 Hive connector 将 Mixed Hive 表当成 Hive 表来读写
- 可以将 Hive 表原地升级为 Mixed Hive 表,升级过程没有数据重写和迁移,秒级响应
- 具备湖仓一体的特性,包括基于主键 upsert,流式读写,ACID,time travel 等功能
Hive 读写兼容的特性实现 Hive 表向 Mixed Hive 的无缝迁移, 并且可以做到上下游无感知。 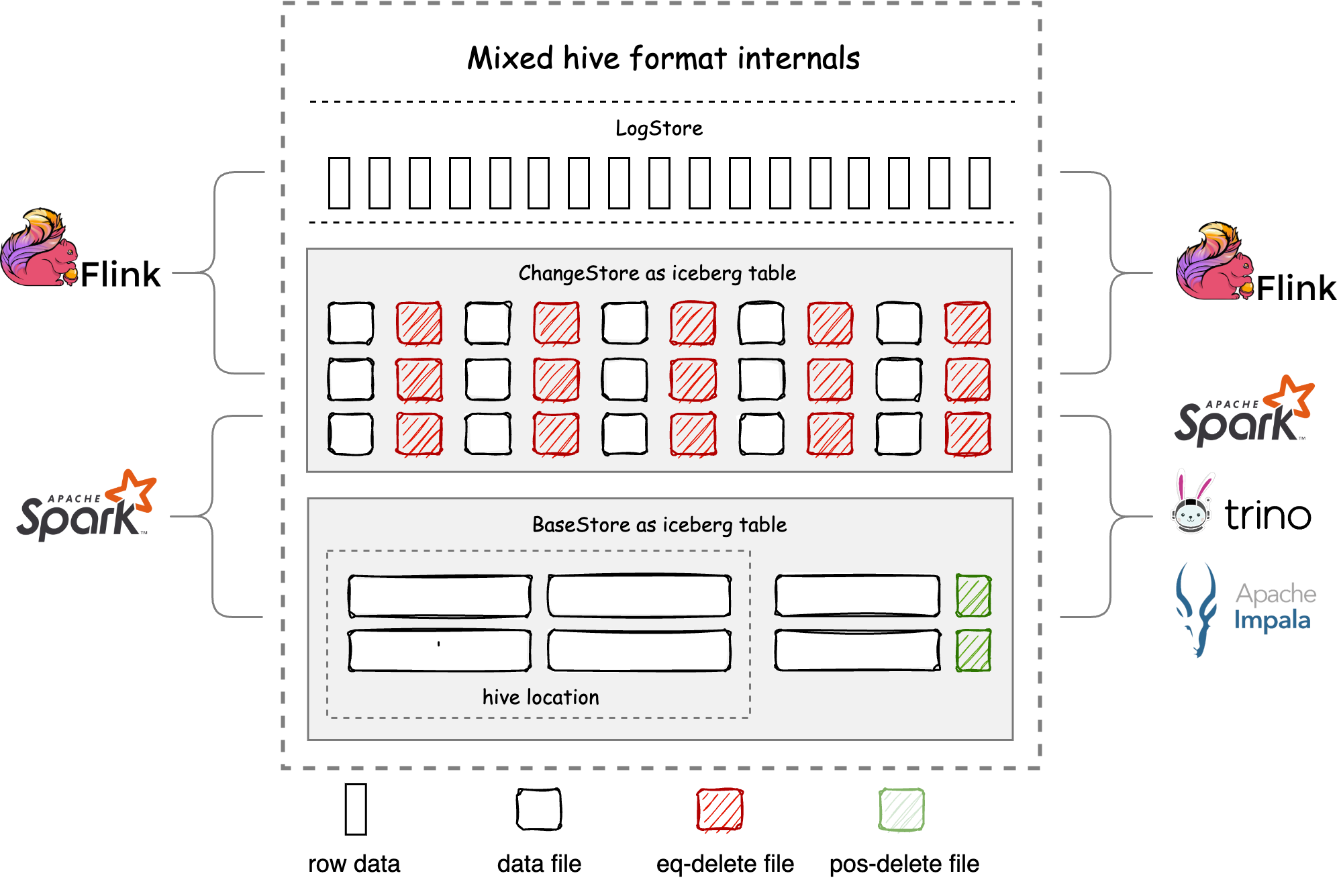
Hive 数据更新
Amoro 借助 Self-optimizing 将实时写入的变更合并到 Hive, 实现了 Hive 数据更新。Self-optimizing目标是基于新型数据湖表格式打造像数据库,传统数仓一样开箱即用的流式湖仓服务,Self-optimizing 包含但不限于文件合并,去重,排序。 Amoro 将表中的文件按照大小分为了两类: 
- Fragment File:碎片文件,默认配置下小于 16 MB 的文件,此类文件需要及时得合并成更大的文件,以提升读取性能
- Segment File:默认配置下大于 16MB 的文件,此类文件已经具备一定的大小,但还不到理想的 128MB。
基于文件分类,Amoro 将文件优化任务分为三类:Minor optimizing、Major optimizing、Full optimizing,应对写友好、读友好的场景,在保证写入性能同时,保证读性能的平衡。特别地 Full optimizing 会将实时写入的数据定时合并到 Hive 目录,实现 Hive 数据视图的更新,提高 Hive 数据的时效性。 持续的 Self-optimizing 可以有效优化表内文件的大小分布,降低小文件数,减少 AP 查询的性能开销。
落地方案
数据链路改造
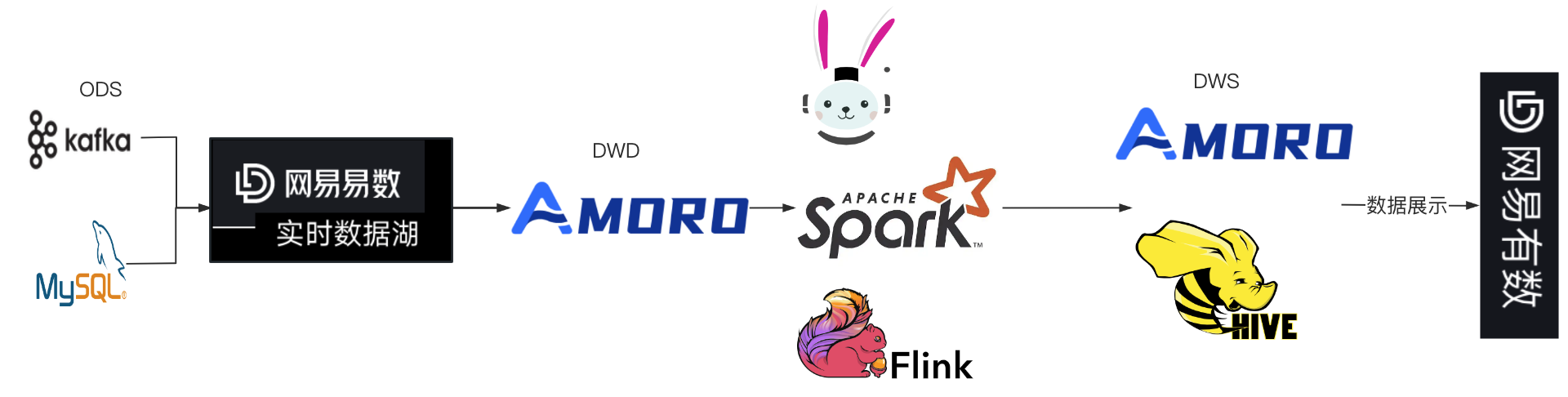 基于 Amoro,我们对于传统链路进行了以下改造:
基于 Amoro,我们对于传统链路进行了以下改造:
- 开发方式上,贴源层的数据导入从 Flink SQL 方式改造成基于实时数据湖平台,业务通过简单的交互即可完成Hive 升级和入湖链路的构建。
- 通过数据传输定时同步数据库到 Hive 的链路,改造成实时 Mixed Hive format 表,数据时效性提升的同时,也提前了离线 workflow 基线,数据产出时间大大提前。
- Amoro 替换 Doirs,降低数据链路的复杂度,做到存储的流批统一,提高了稳定性。
- 数据查询端,通过直接查询 Mixed Hive format 表实现数据时效性的提升,数据报表时效性可以达到分钟级;原来查询 Hive 的报表链路时效性可以提升到小时级。
实时数据湖平台共建
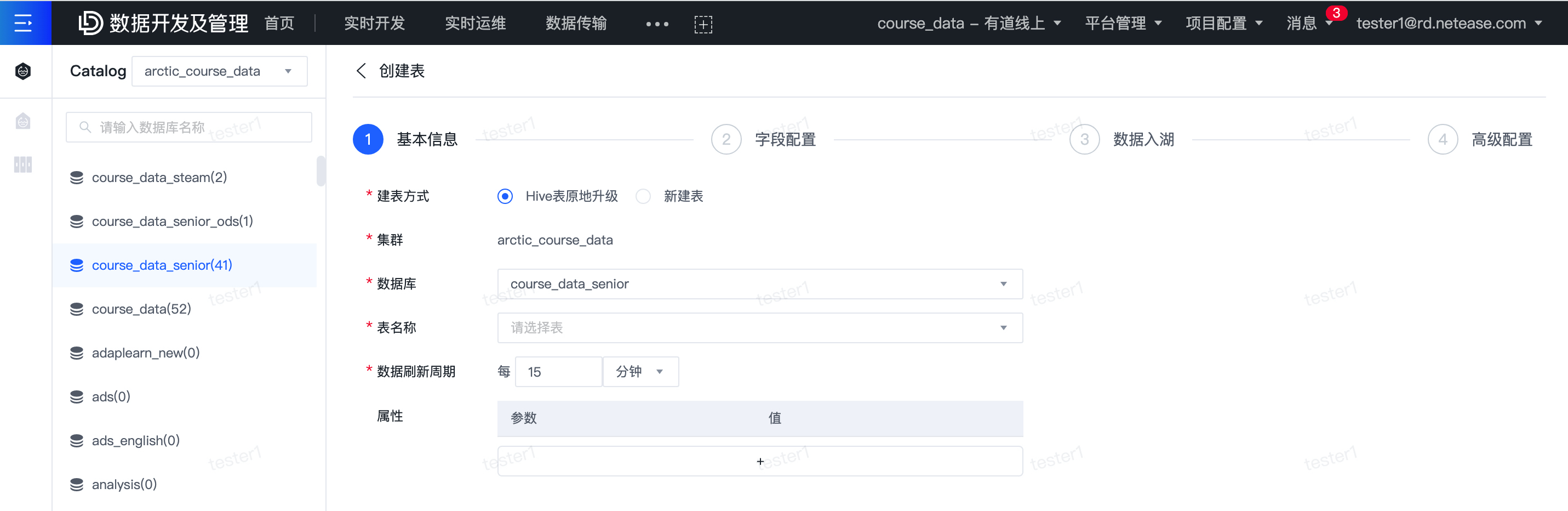
为了屏蔽底层存储变更对于业务开发的学习成本, 网易杭研基于 Amoro 在内部提供了实时数据湖开发平台,封装了从 Hive 表升级到构建数据入湖全流程,帮助用户一站式完成开发和运维,降低用户的使用门槛和成本。
- Hive 表升级到 Mixed Hive 表,包含主键配置、分区键配置。
- 创建源端到 Mixed Hive 表的入湖任务, 支持数据库 cdc 入湖、日志入湖。
- 基于NDC(网易数据运河) 打通从源端数据库 binlog 直接输出到 Mixed Hive 表全增量入湖链路。
- 支持配置日志kakfa 到 Mixed Hive 表的实时入湖链路。
 通过用户调研,相对于引入 Amoro 之前基于Flink 实时入湖的架构,用户的开发成本下降 65%, 运维成本下降40%。 通过实时数据湖平台实现 Flink 入湖、用户编写 Spark/Trino sql 实现 DWD、DWS 层的 ETL 加工,构建分钟、小时级近实时数仓,极大降低了用户的开发成本。并且该方案存储流批统一的特点,也降低了用户数据开发和数据修复的成本。同时,Amoro 全量/增量 Flink 流式读取的特性,也可以满足对时效性要求更高的流式处理场景。
通过用户调研,相对于引入 Amoro 之前基于Flink 实时入湖的架构,用户的开发成本下降 65%, 运维成本下降40%。 通过实时数据湖平台实现 Flink 入湖、用户编写 Spark/Trino sql 实现 DWD、DWS 层的 ETL 加工,构建分钟、小时级近实时数仓,极大降低了用户的开发成本。并且该方案存储流批统一的特点,也降低了用户数据开发和数据修复的成本。同时,Amoro 全量/增量 Flink 流式读取的特性,也可以满足对时效性要求更高的流式处理场景。
在开源 Amoro 和杭研实时数据湖平台之上,有道也深度参与了社区贡献和平台共建,包括:
- 贡献 Mixed Format 支持 ORC 格式,解决 Amoro 只支持 Parquet 格式 Hive表的限制,避免 ORC 到 Parquet 表的拷贝才能升级的流程, 预计节省冗余存储 20TB 存储
- 搭建 Amoro 平台监控体系、自动运维优化,保障线上表质量、数据时效性、集群稳定性
- Trino 引擎查询 Amoro 支持 Hadoop-proxy,基于有道 HDFS ranger 实现权限管理
- 多项 Amoro Optimizer 优化以提高 Optimizer 稳定性,如:Flink Optimizer 任务重试上报 AMS
- 多项实时数据湖平台优化以提升可靠性和用户体验,如:实时数据湖平台支持Amoro高可用
查询优化
目前有道主要使用 MPP 引擎 Trino 对 Mixed Hive 表进行分钟级时效性的 OLAP 查询。在大多数场景下,默认的查询性能符合要求。对于查询响应要求较高的一些场景,发现 Mixed Hive 查询性能达不到业务要求,并且比其它业务环境的查询性能差。Amoro 和有道同学分析 Trino 的查询 profile 和 底层 HDFS 性能,发现了三个优化点,优化后 Mixed Hive 表的查询性能提升明显,查询耗时下降了92%,基本接近 Hive 静态数据查询,并且已经可以满足业务的要求。三个优化如下:
- 对 Query Plan 阶段,Amoro 改写了原本的 Plan 逻辑,将需要用来判断数据是否被删除的 Sequence Number 直接从一次多线程的 Plan 中获取,减少了之前单独使用一个额外的单线程 Plan 去获取该变量的开销;
- 对于数据倾斜的问题,Amoro 对 delete 文件开销较小但文件数量较多的任务进行了更细粒度的拆分,通过提高并行度,性能提升50%。
- 有道对 HDFS 的优化,在分析过程中发现通过 Router 访问的 RPC 响应时长 .95 达到 262ms, 远超正常集群的 5ms 以内,通过将 HDFS 访问切到直连 HDFS集群,rpc 响应时间降为 .95耗时 15ms,Mixed Hive 表平均查询耗时下降 83.3%。 另外,在可以降低时效性要求的场景,直接查询 Mixed Hive 的 BaseStore 也可达到分钟级的时效性,查询性能更好,可以与 Hive 查询静态数据相当。
应用情况
2023年初,Amoro 在有道开始上线应用,目前线上表数量500+张、100+ TB存储、日存储增量200GB/天,Spark/Trino日均查询量6000+,覆盖有道10+业务部门,在续报、投放等多个场景落地了分钟级近实时数仓,并且通过 Amoro 托管的数据自优化功能,有效避免数仓业务中的小文件问题,达到持续降本提效的效果。
在替换 Doris 的实践上, 有道词典已经完成了 Amoro 替换 Doris,下掉了 Doris 集群的节点。有道精品课也逐步以 Amoro 替代 Doris,预计明年上半年完成替换。
在构建近实时数仓实践上,三个业务部门已经完成了基于 Amoro 搭建近实时数仓,整条链路的延迟最低可达3mins。同时,实时增量写 Mixed Hive 表替代传统的全量数据传输任务,提前了离线 workflow 基线,ADS 表产出时间最快可提前6小时。
业务收益上,数据产出效率由 T+1 提升到小时级/分钟级, 实现更快更有效的决策分析(投放、销售策略等),为有道多个部门带来了成本降低或效率提升,比如词典社区视频播放时长提升10%, 点击率提升4.6%。
社区贡献
在Amoro开源社区,有道已有 13 个PR合并,包括:
- Mix Table Format 支持 ORC 文件格式
- Flink DDL支持计算列和 Watermark
- Trino引擎支持 hadoop-proxy
- 支持 HTTP 请求创建 optimizer group
- 删表操作优化
- Flink Optimizer failover 重试上报 AMS
未来规划
- 在查询性能方面,目前 Amoro 在查询响应要求高的绝大部分场景下 AP 查询性能已基本满足用户需求。平台层目标是保证90%查询响应耗时响应在5s 以内,基于 SSD 的 Doris 平均查询时间为1.8s,Amoro 优化后的平均查询时间在5s ,可以满足绝大部分查询场景。未来将持续优化查询性能,比如 Full optimize 中引入 Z-order 提升 data skiping 的命中率等。
- 当前入湖任务是单表单任务,有大量的变更少的数据库表,入湖任务资源利用率相对较低。杭研实时数据湖平台已上线 Flink Session 入湖,复用Session的JM/TM 资源,优化入湖任务的资源利用率。预计将减少入湖任务的内存、CPU 资源约 30%~50% 左右。
- Paimon 在 Flink partial update 的场景下有较好的可用性,未来计划通过 Amoro 尝试落地。我们希望借助 Amoro 的 Unified Catalog,统一管理 Mixed Hive 表、Paimon 表、Mixed Iceberg 表,像使用 Mixed Hive 一样使用 Paimon 表,保留用户当前基于 Amoro 的开发体验。
End~
如果你对数据湖,湖仓一体、table format 或 Amoro 社区感兴趣,欢迎联系我们深入交流。
关于 Amoro 的更多资讯可查看:
- 官网:https://amoro.netease.com/
- 源码:https://github.com/NetEase/amoro
社群交流:搜索 kllnn999,添加芦田爱菜小助手微信加入社群

作者:谢怡 & 王涛
编辑:Viridian
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: SpringCloud(三) Ribbon负载均衡
SpringCloud(二) Eureka注册中心的使用-CSDN博客 在SpringCloud(二)中学习了如何通过Eureka实现服务的注册和发送,从而通过RestTemplate实现不同微服务之间的调用,加上@LoadBalance注解之后实现负载均衡,…
