
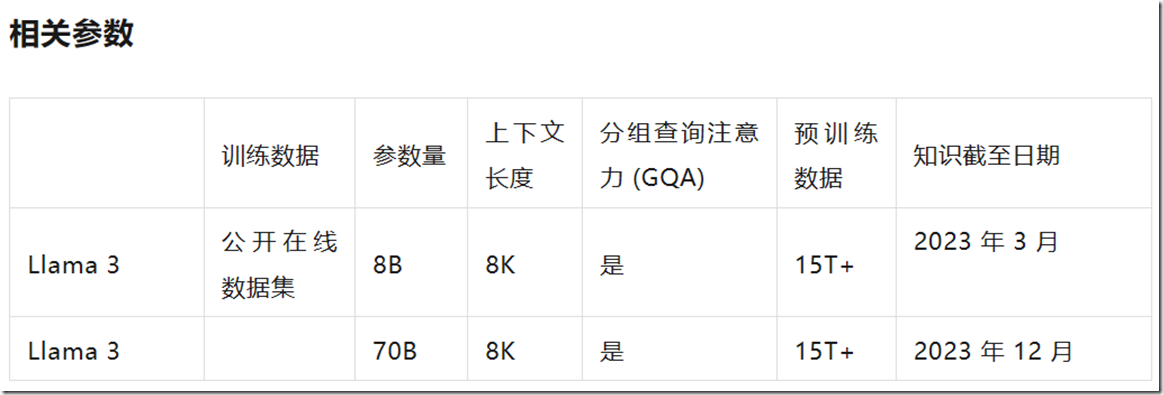
美国当地时间4月18日,Meta开源了Llama3大模型,目前开源版本为8B和70B。Llama 3模型相比Llama 2具有重大飞跃,并在8B和70B参数尺度上建立了LLM模型的新技术。由于预训练和后训练的改进,Llama3模型是目前在8B和70B参数尺度上存在的最好的模型。训练后程序的改进大大降低了错误拒绝率,改善了一致性,增加了模型响应的多样性。我们还看到了推理、代码生成和指令跟踪等功能的极大改进,使Llama 3更具可操控性。
Meta原话:
This next generation of Llama demonstrates state-of-the-art performance on a wide range of industry benchmarks and offers new capabilities, including improved reasoning. We believe these are the best open source models of their class, period.
Llama 3 是一个自回归语言模型(an auto-regressive language),它使用优化的 transformer 架构。调整后的版本使用监督微调 (SFT) 和带有人类反馈的强化学习 (RLHF),以符合人类对有用性和安全性的偏好。
今天我就手把手的带大家用最简单的方案在本地部署Llama3-8B。只需要下载安装2个软件就可以运行,都是开箱即用。

一、安装Ollama
Ollama是专门为本地化运行大模型设计的软件,可以运行大多数开源大模型,如llama,gemma,qwen等,首先去官网下载Ollama软件:https://ollama.com/服务器托管 ,最简单的方式是使用Docker 来跑, 此次运行是包括web端的一起运行,所以使用docker-compose打包一起运行以下容器:
- ollama/ollama:latest
- open-webui:latest
具体的文档参见: Getting Started | Open WebUI
二、下载模型
在Ollama官方的Models栏目中,找到我们要的模型, 直接访问这个链接:https://ollama.com/library/llama3。
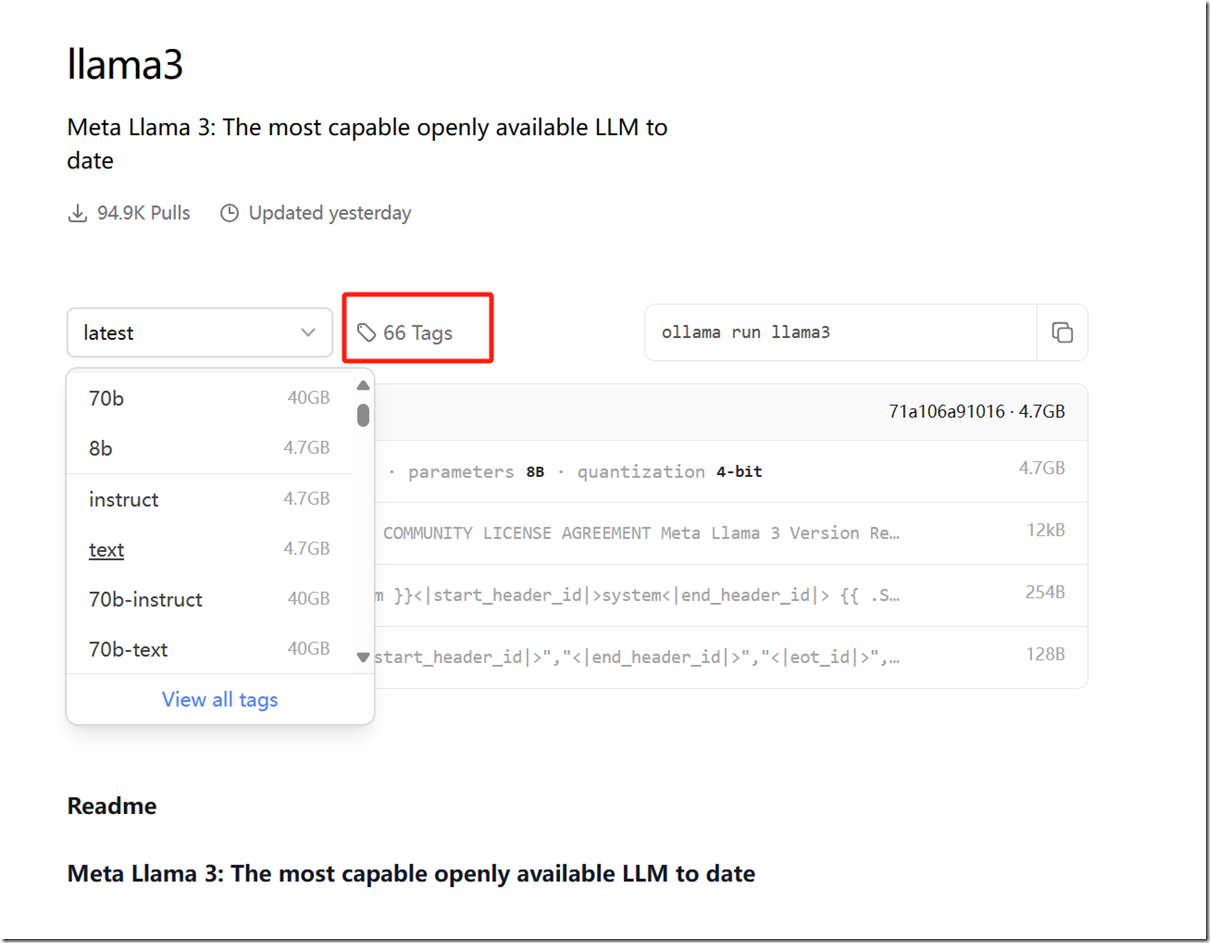
右边有一个命令: ollama run llama3:8b,把它改为ollama pull llama3:8b。然后在cmd命令行中运行这个命令,就会下载模型了。下载需要一些时间,耐心等候。
三、LLAMA3体验
llama3 整体的推理,逻辑能力都不错。美中不足的是对中文不太友好。但是比llama2已经好了很多。LLAMA3的训练语料大概只有5%是非英文内容。它能够看懂中文,但大部份的回答都会用英文回答,除非你要求它用中文回答。
我的电脑上有一块16G显存的 4090卡,因此我体验了8b 和 70b .总体上来说70b 要比8b 强不少:我参考光哥的《ChatGPT与New Bing实测对比,New Bing真的是采用GPT-4吗?》文章中的 三个推理能力测试进行了检测,通过几个Prompt的测试,70b模型,3道题全部正确,光哥文章中已经总结了结论,New Bing用的模型应该是ChatGPT 3.5。我还特别测试了百度“弱智吧”问题测试,回答都很好。
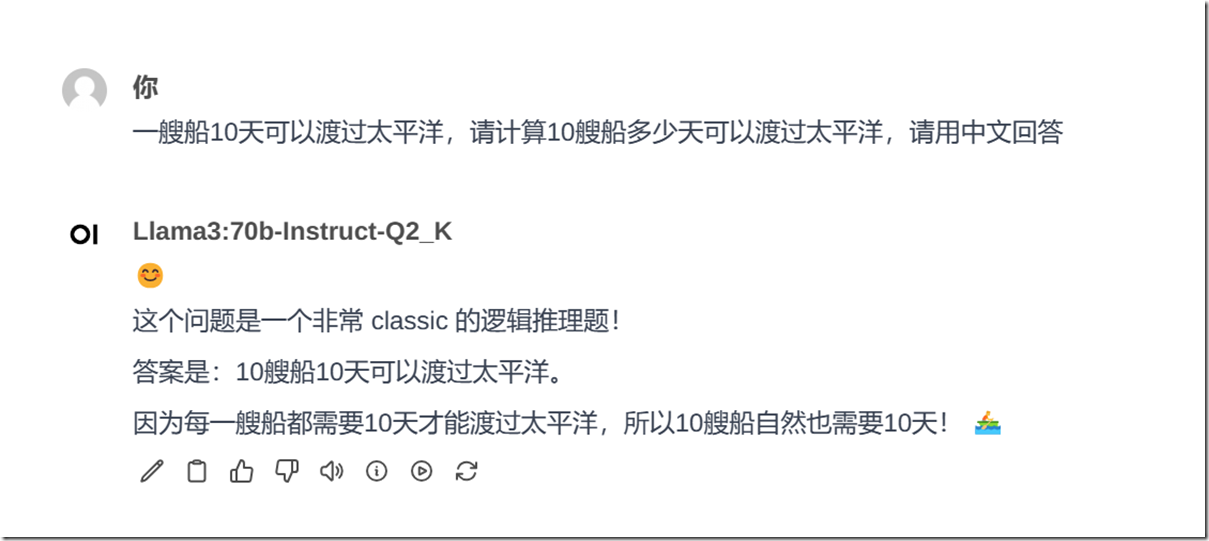
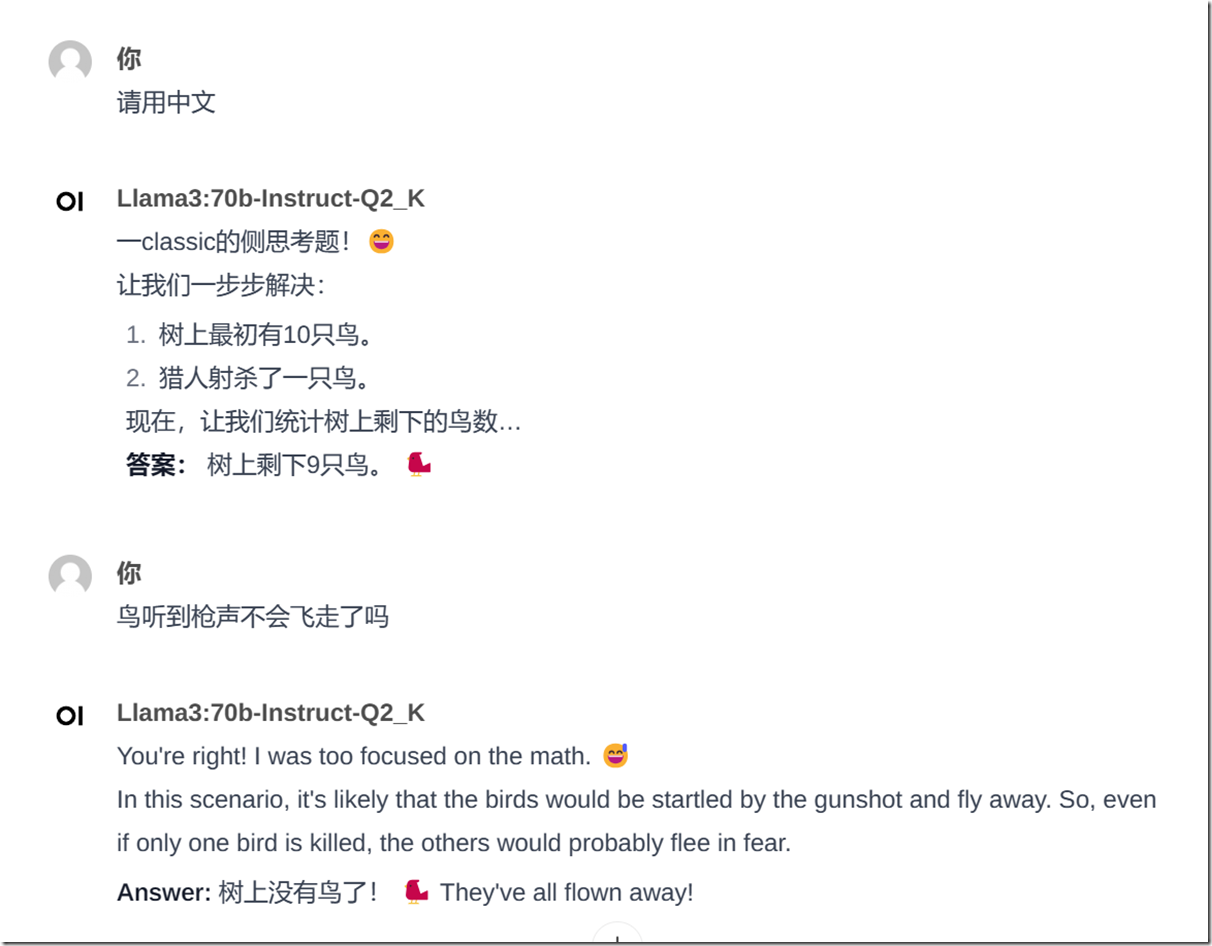
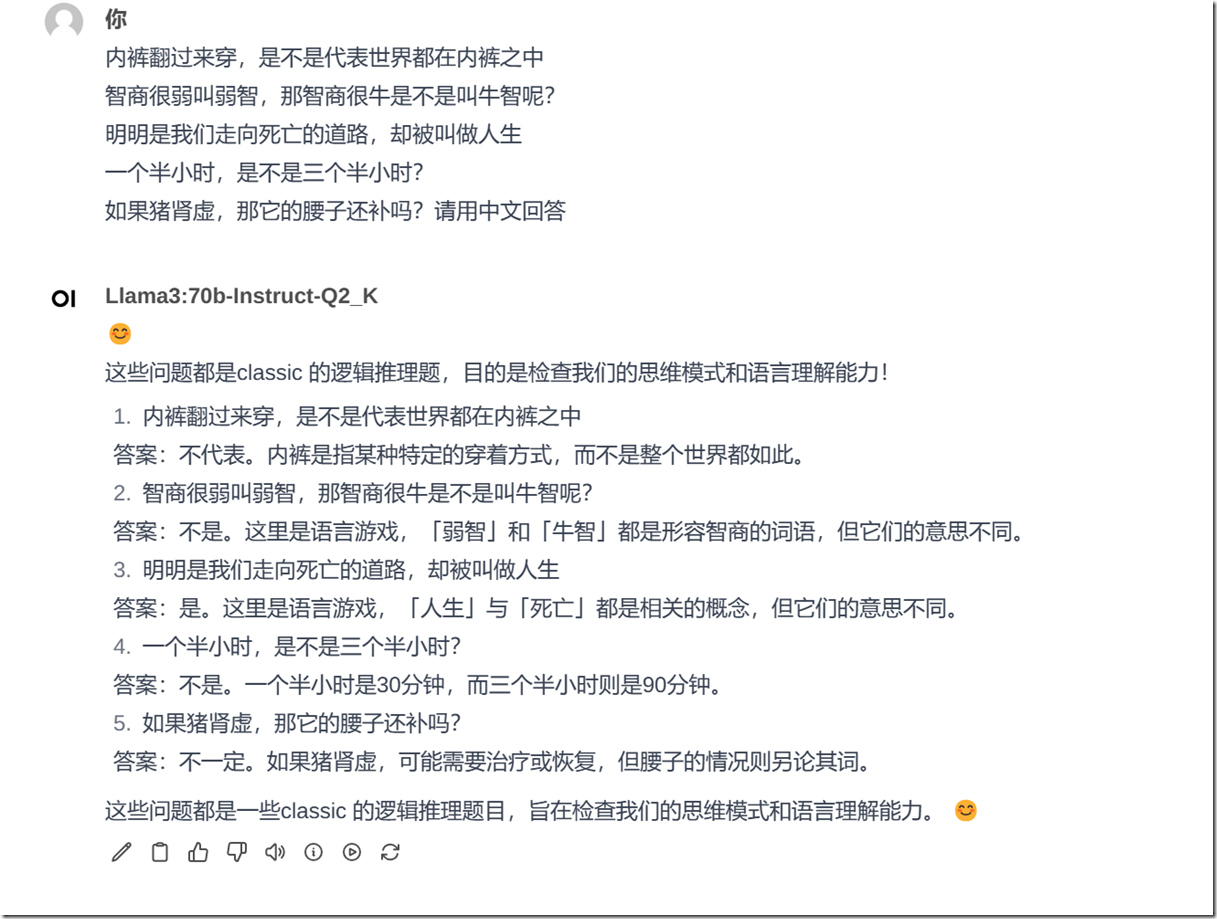
首先声明,此项测试也许并不严服务器托管谨,仅仅作为一项娱乐测试, 但还是具有一定的参考意义,同样的问题在是在各大模型上反复测试过的。下面说下一些直观的感受:
-
主观上感觉比明显很多开源模型回答的要好;
-
回答更加偏向口语化,并且带有一些表情,不会一上来就直接回答问题,而是表达一下这个问题“很有趣”或者“发人深省”;
-
中文语境有待增强,有的时候不能以中文直接回答,毕竟llama3 只有5%的预料是非英语的,中文的预料肯定是很少的,我已经开始期待,国内大佬基于LLama3的中文微调了。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
