
特征递归消除(RFE, recursive feature elimination)
RFE 算法通过增加或移除特定特征变量获得能最大化模型性能的最优组合变量。
RFE基本算法
- 使用所有特征变量训练模型
- 计算每个特征变量的重要性并进行排序
- 对每一个变量子集
S_{i}, i=1...S:
- 提取前
S_{i}个最重要的特征变量 - 基于新数据集训练模型
- 重计算每个特征变量的重要性并进行排序(可选)
- 计算比较每个子集获得的模型的效果
- 决定最优的特征变量集合
- 选择最优变量集合的模型为最终模型

https://topepo.github.io/caret/premade/Algo1.png
注:每次筛选子集特征变量构建模型时是否对变量在进行重新排序和选择是可选的。之前有评估表示对随机森林模型不建议每次都计算变量重要性,这会降低最终的性能。对基于高度共线性变量构建的线性模型,每一次重新计算变量重要性可以略微提高模型性能。
在使用RFE算法时需要注意过拟合问题。假如在一个很大数目的无意义特征变量组成的数据集中有一个变量正好与分类结果完全吻合。RFE算法将会给这个变量很好的重要性得分和排序,包括这个变量的模型在构建评估时错误率也较低。需要一个独立的测试集或验证集才能发现这个被选出的特征变量是无意义的。这也被称为选择偏好 (selection bias)。
在当前的 RFE 算法中,训练集被至少用于 3 个目的:特征变量筛选、模型拟合和性能评估。单一的静态训练集不能满足这些需求,除非训练集中的样品特别多(尤其是显著多于变量数目)。
为了更好地评估特征选择过程中的性能波动,需要在前述算法的外层再增加一层重抽样过程(如10-折交叉验证)。这可以提供很好地性能评估,但也增加了很多计算压力,建议使用并行计算加快速度。
交叉验证RFE算法
- 对每一次重采样迭代
- 提取前
S_{i}个最重要的特征变量 - 基于新数据集训练模型
- 采用验证集评估模型
- 重计算每个特征变量的重要性并进行排序(可选)
- 把训练集拆分为新训练集和验证集
- 采用新训练集和所有特征变量训练模型
- 使用验证集评估模型
- 计算所有特征变量重要性并进行排序
- 对每一个变量子集
S_{i}, i=1...S:
- 决定合适数目的特征变量
- 估计用于最终模型构建的特征变量集合
- 选择最优变量集合采用全部训练集构建最终模型
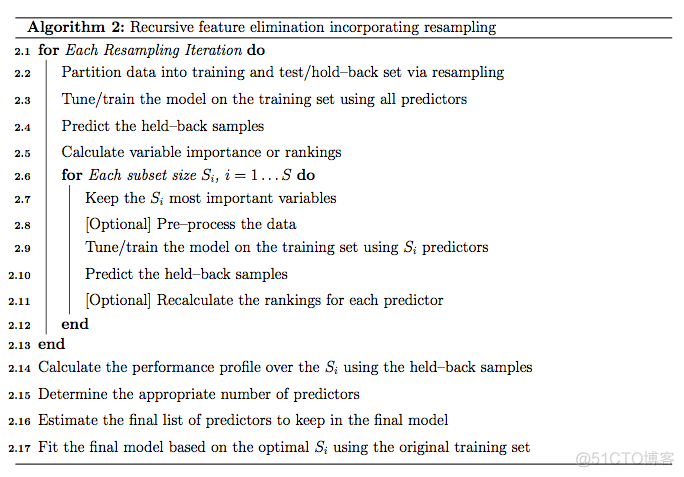
https://topepo.github.io/caret/premade/Algo2.png
在caret中rfe使用的是第二种算法。
机器学习系列教程
从随机森林开始,一步步理解决策树、随机森林、ROC/AUC、数据集、交叉验证的概念和实践。
文字能说清的用文字、图片能展示的用、描述不清的用公式、公式还不清楚的写个简单代码,一步步理清各个环节和概念。
再到成熟代码应用、模型调参、模型比较、模型评估,学习整个机器学习需要用到的知识和技能。
- 机器学习算法 – 随机森林之决策树初探(1)
- 机器学习算法-随机森林之决策树R 代码从头暴力实现(2)
- 机器学习算法-随机森林之决策树R 代码从头暴力实现(3)
- 机器学习算法-随机森林之理论概述
- 随机森林拖了这么久,终于到实战了。先分享很多套用于机器学习的多种癌症表达数据集 https://file.biolab.si/biolab/supp/bi-cancer/projections/。
- 机器学习算法-随机森林初探(1)
- 机器学习 模型评估指标 – ROC曲线和AUC值
- 机器学习 – 训练集、验证集、测试集
- 机器学习 – 随机森林手动10 折交叉验证
- 一个函数统一238个机器学习R包,这也太赞了吧
- 基于Caret和RandomForest包进行随机森林分析的一般步骤 (1)
- Caret模型训练和调参更多参数解读(2)
- 机器学习相关书籍分享
- 基于Caret进行随机森林随机调参的4种方式
- 送你一个在线机器学习网站,真香!
- UCI机器学习数据集
- 机器学习第17篇 – 特征变量筛选(1)
- 机器学习第18篇 – 基于随机森林的Boruta特征变量筛选(2)
- 机器学习系列补充:数据集准备和更正YSX包
- 机器学习第20篇 – 基于Boruta选择的特征变量构建随机森林
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
