
大家好,我是sulny_ann,这期想跟大家分享一下我之前在面试里面问过比较难的数据库相关的问题。
大家经常也在调侃后端好像就是技术数据库的增删改查,所以作为后端开发,你对应数据库这一块掌握的怎么样,是非常能看出你整个开发的技术能力水平。
接下来就分享 3 个我之前问到的关于数据库的 3 个问题。
第一个问题就是如果一个事务当中有更新操作,也有查询操作,那我是先更新好呢?还是先查询好?
很多小伙伴一听到这个问题不知道我想考啥,我印象比较深刻就是这个候选人他还是比较聪明的,他还先问我一下,你这个更新操作依不依赖这个查询的操作。我也提示了这两个是没有什么依赖关系的,所以这里我的重点是开启了一个事物,那对于事物它肯定是要消耗资源的,那消耗的资源有哪些东西?
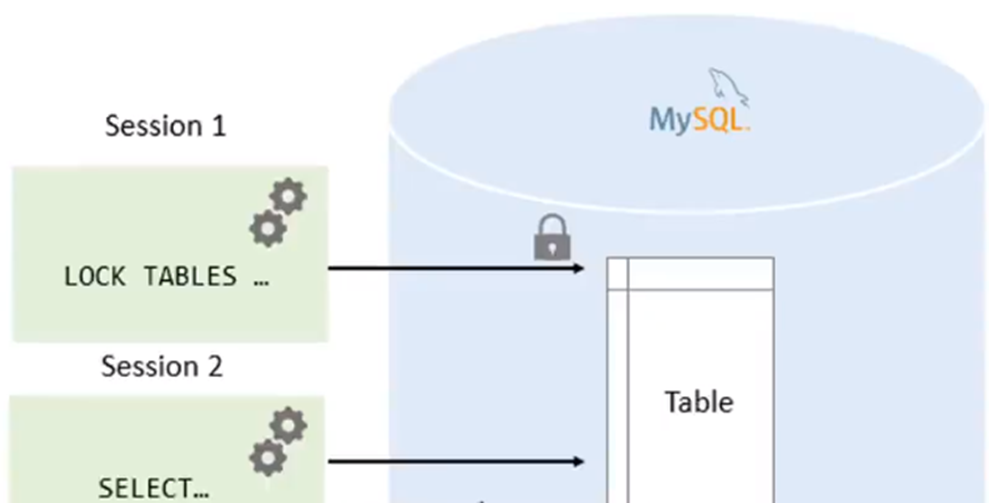
有连接池,还有底层的锁,那大家想一下,更新它可能是会持有什么锁呢?有可能是行锁,也有可能是间隙锁,甚至可能是表锁。那既然这个事物加锁,那其他的事物只能在这些资源上去做一个等待,这就可能降低整个数据库的并发性能。
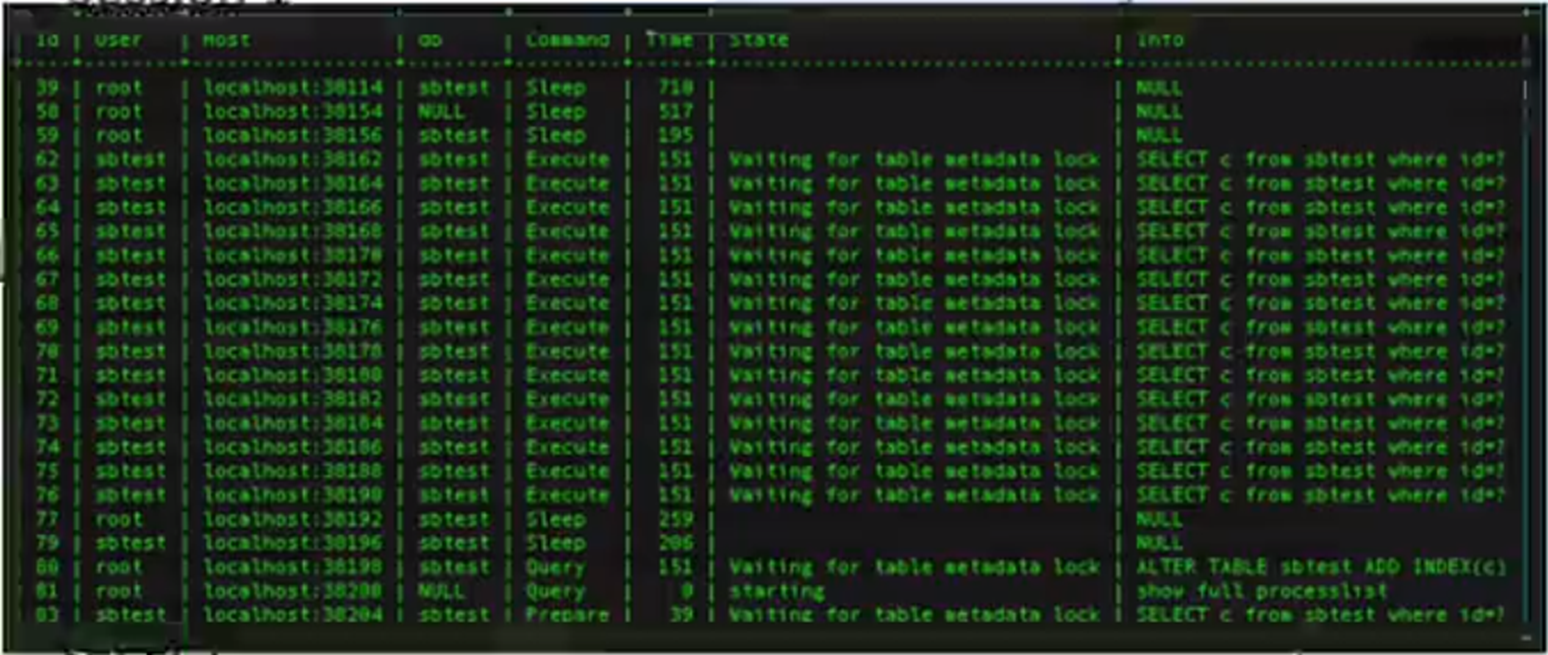
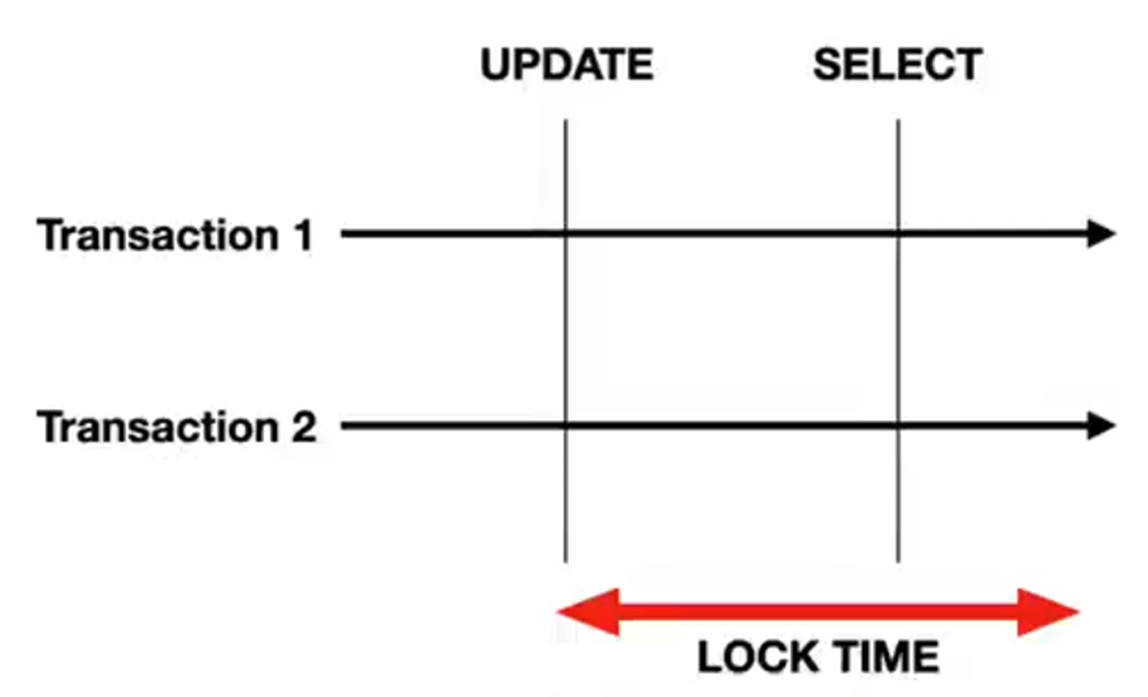
所以这个问题应该怎么去回答呢?其实在大部分的情况就应该先去查询,再去更新,但这里的查询默认是不会去加锁的。如果先更新,再去查询,如果这个查询是一个慢SQL,那这个更新操作它持有的资源是会一直阻塞在这里。
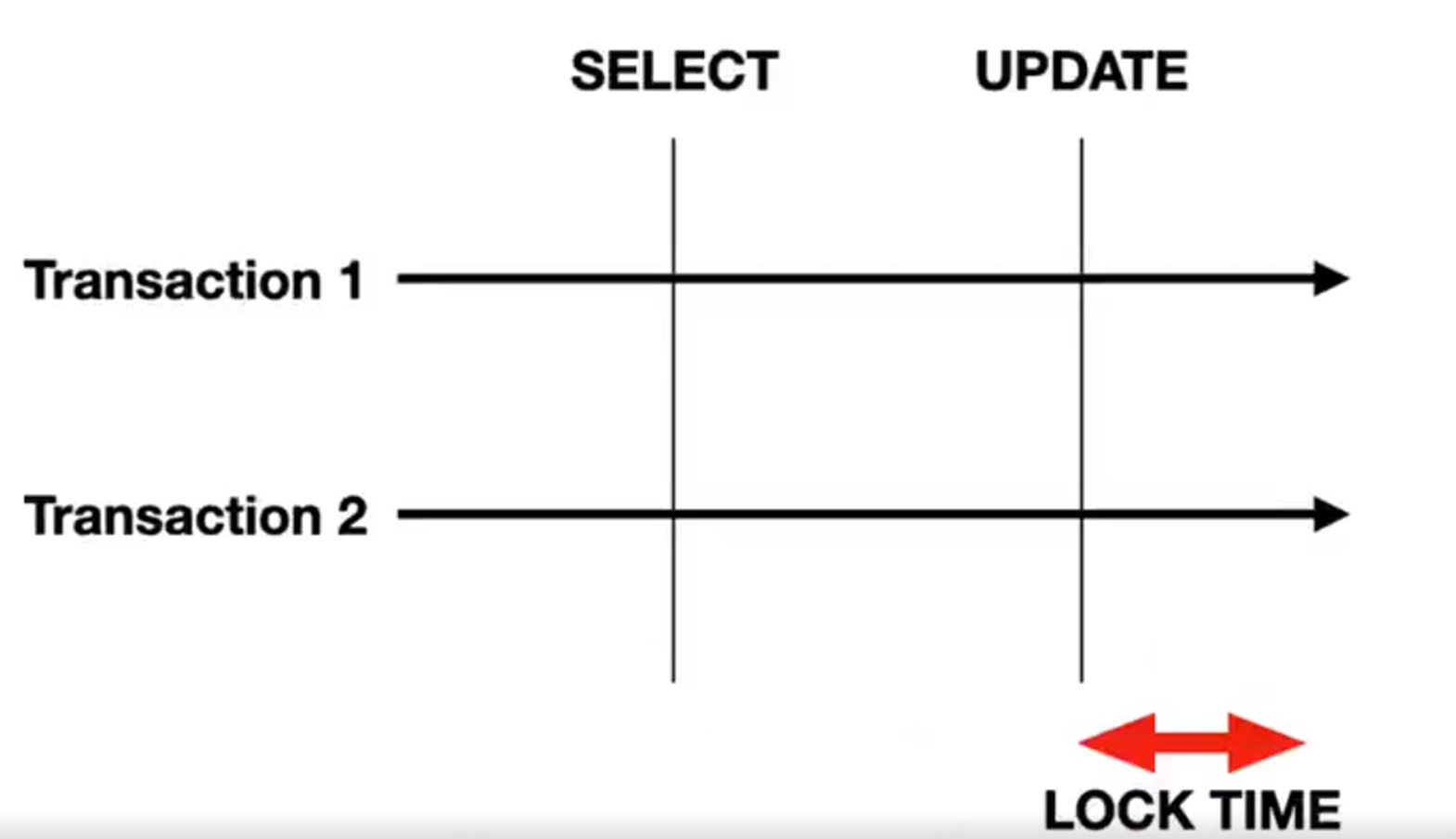
那先查询再更新,那你 select 就算是一个慢SQL,在这个查询执行过程当中其实是没有加锁的,这能够一定程度提升整个数据库的并发能力。我之前在线上确实也做过类似的优化,只要把他们执行的顺序稍微改一下,在一些并发比较高的接口确实能够提升很大的性能。
第二个问题就是我们经常在设计数据库表的时候,经常会做一些字段的冗余,你觉得这样做有什么优缺点?
这其实也是非常常见的一种反范式设计。做字段冗余大部分情况下是为了便于去查询,例如商品跟店铺之间的关系,我可能有一个关系表,但是我在业务上有很多查询,就是要基于店铺去查询他所有的商品,那难道每一次查询都要去做一个join吗?或者查两次吗?如果说我在商品这个表里面去加一个店铺的字段,做这么一个字段的冗余就能够很大程度提升整个查询的性能。
那做字段冗余有什么缺点吗?也有就是如果你要去更新这个关系,你可能要改多个地方,这个就有点类似于缓存的一致性问题,而且这种问题如果在同一个数据库可能还比较好控制,如果是在多个数据库,那你这个风险就非常大了。
所以这里你还要看你的业务场景,就是查询的占比比较高,还是写的占比比较高。如果说是写的占比比较高,那你这个带来事物还有不一致的风险可能会更大。
第三个问题确实也比较有挑战,就是我们的 MySQL 里面的 binlog 跟redolog,哪一个是先产生的?
这个问题大家又觉得我是想问什么东西呢?要回答好这个问题,你首先要知道 binlog 跟 read log 它们分别是用来干嘛的,解决什么问题的。
简单介绍一下, MySQL 底层其实是分了好几个结构的,其中有 Server 层,还有 engine 层。
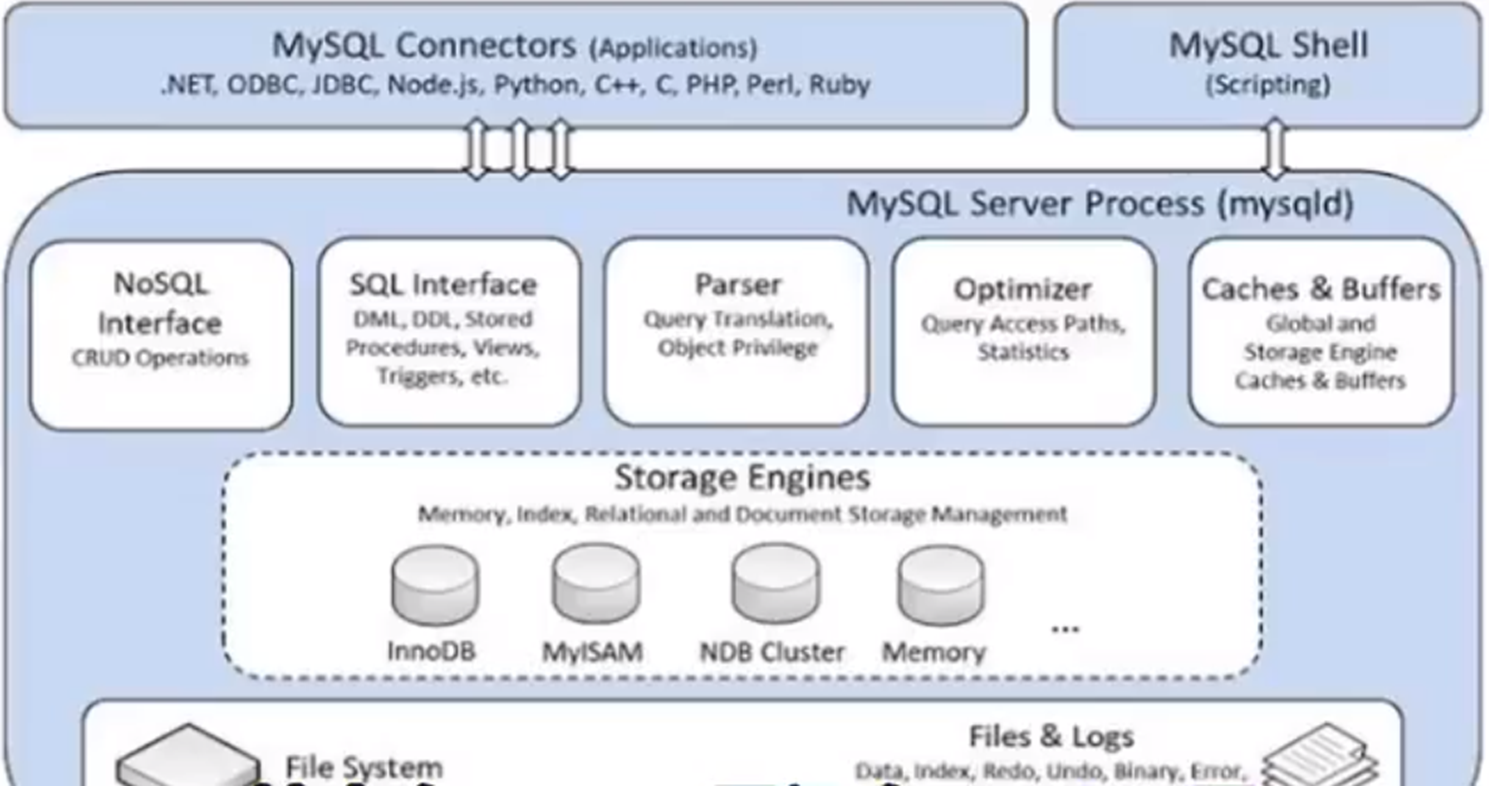
binlog它就是产生在 Server 层,是用来记录数据库DML 产生的二进制日志,主要是用来做主从主备他们之间的一些数据备份。
那 redolog 它是产生在 MySQL 的engine层的,主要是用来保证数据操作的原子性。那这两种日志他们其实都有自己的一个缓冲区。
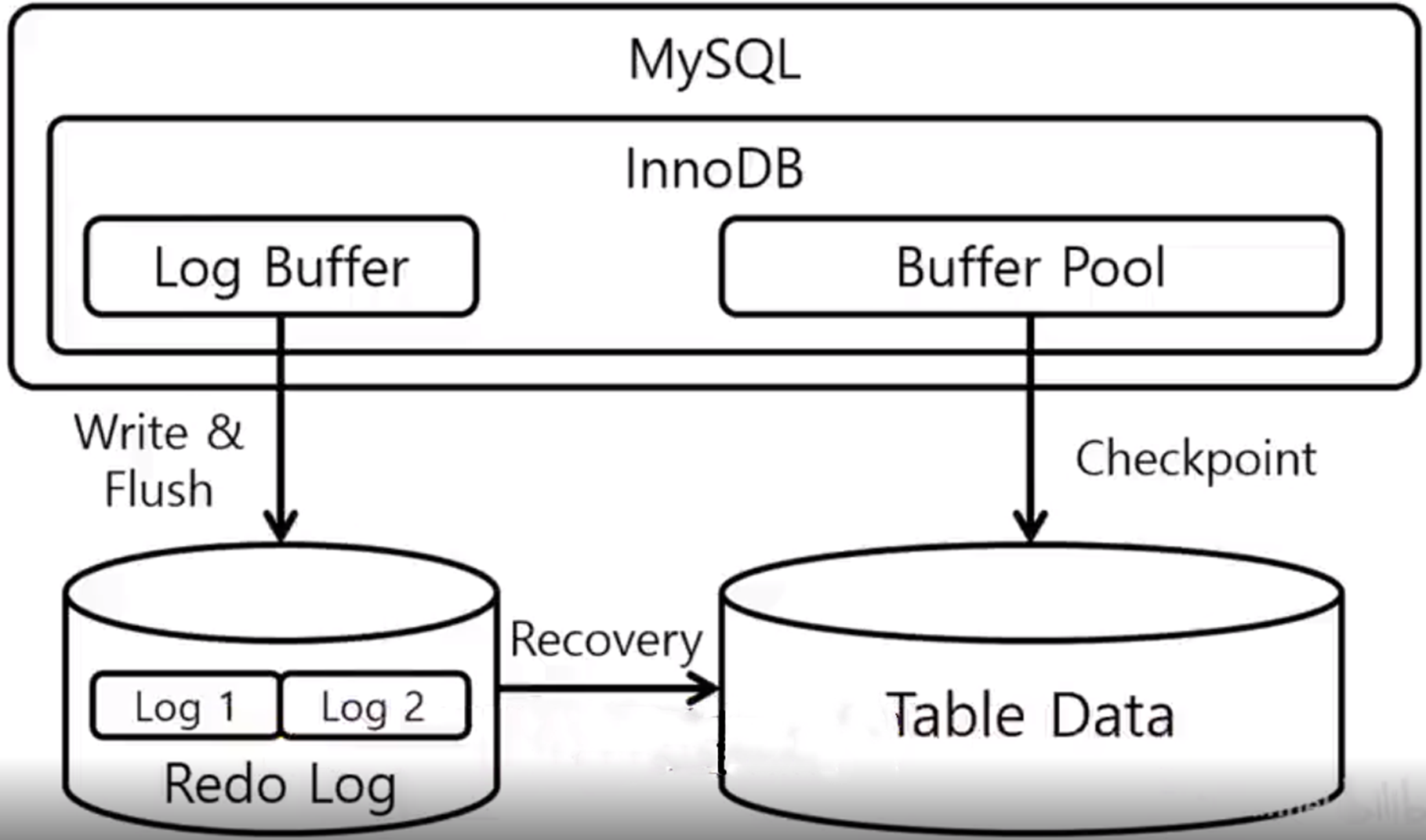
但是他们持久化一般都是分两个步骤:先写在操作系统的内核区,再去做一个刷盘操作。
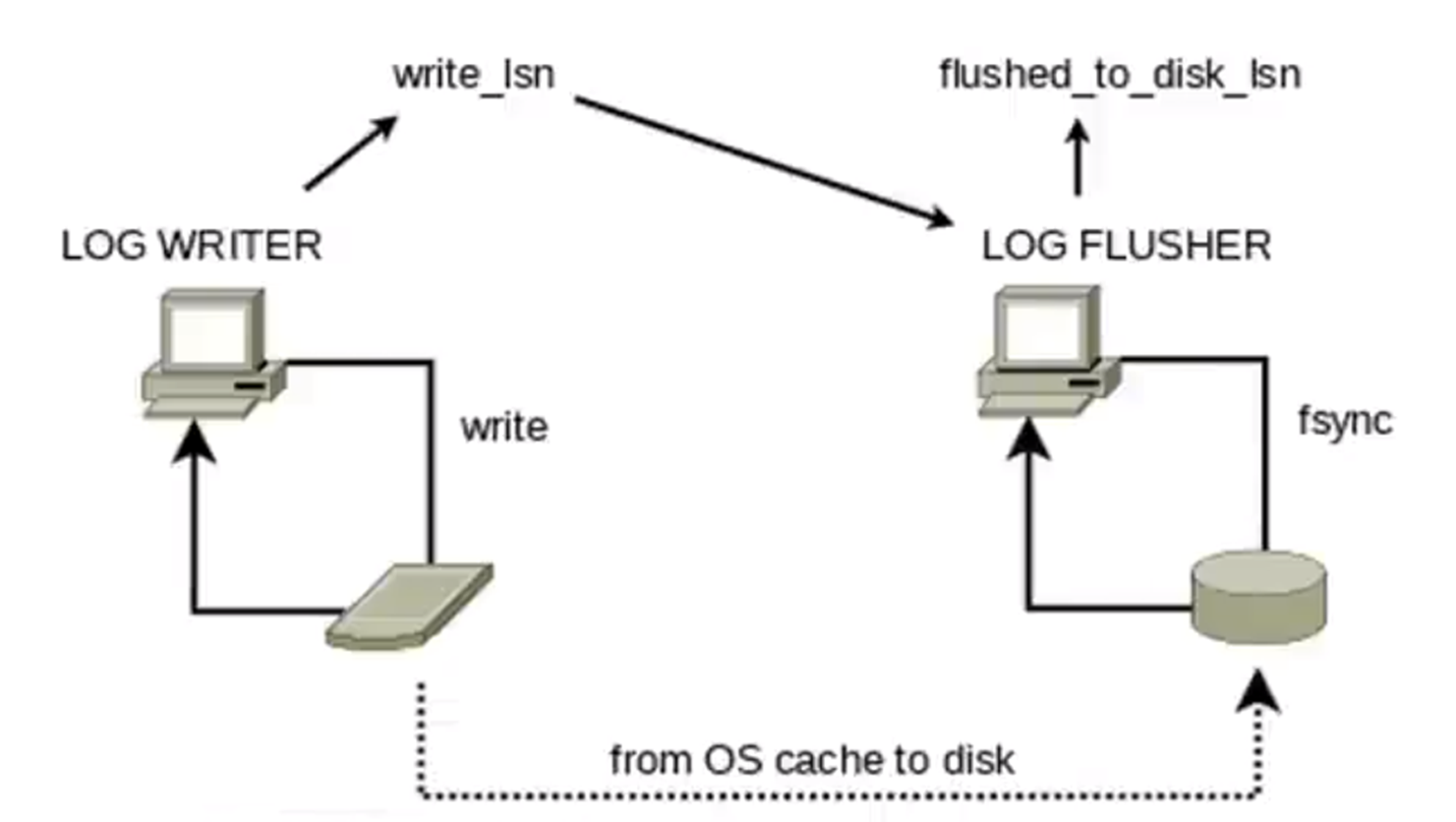
如果对可行性要求比较高,那我们每次产生事物的时候都是去做一个持久化,但是我们一般情况只会考虑把它刷在操作系统的内核层,因为这种情况是性能跟它的数据可靠性做一个折中,只要操作系统层面没有宕机,那这个数据一般是不会丢失的。
说到这里我们好像并没回答这个问题,就是这两个操作哪个先产生?那这里产生是站在什么角度?是站在磁盘的角度,还是说站在 MySQL 进程的角度?如果说服务器托管网是进程,他们两个基本上是同时产生的,但是坐在磁盘的角度,其实redolog 它可能先产生,为什么说是可能呢?因为 binlog 他一定说是事物提交之后才会去做一个持久化。
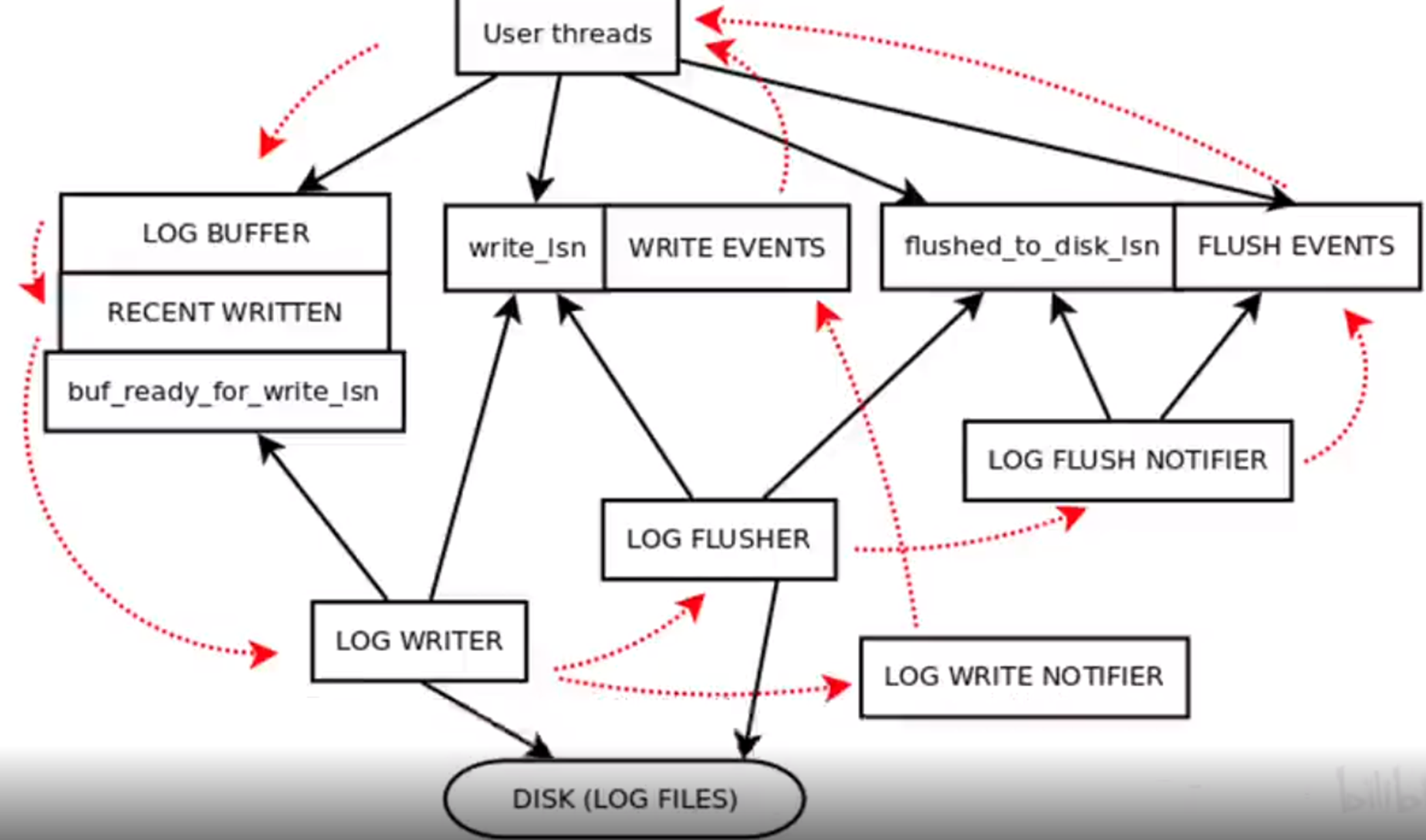
但是 Redo log 它其实有多种刷盘的机制,例如 MySQL 层面,它提供了一个同步的参数,你只要每次事务都操作,都去做一个提交,这个性能可能是比较差的。
但是它还有另外两种刷盘的机制,它默认有一个 1 秒钟去刷新整个内核缓冲区的一个进程,那这个时候你就算事务没有提交,它也会把缓冲区的这个redolog进行刷盘操作。
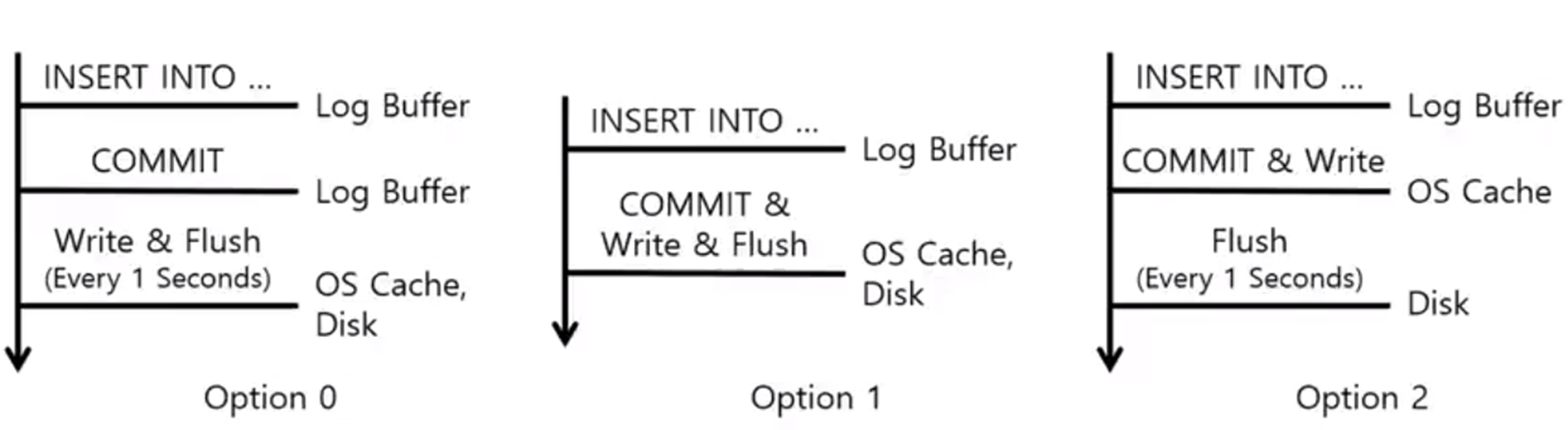
那在这个过程当中,可能事务还没有提交,那 redolog 已经放在磁盘上了。
当然有些小伙伴可能会觉得如果这个过程当中断电了怎么办?那会不会有 redolog,然后binlog不一致?这就是 MySQL 它为什么要去实现一个二阶段提交这么一个过程,这里时间有限,就不去做过多展开了。
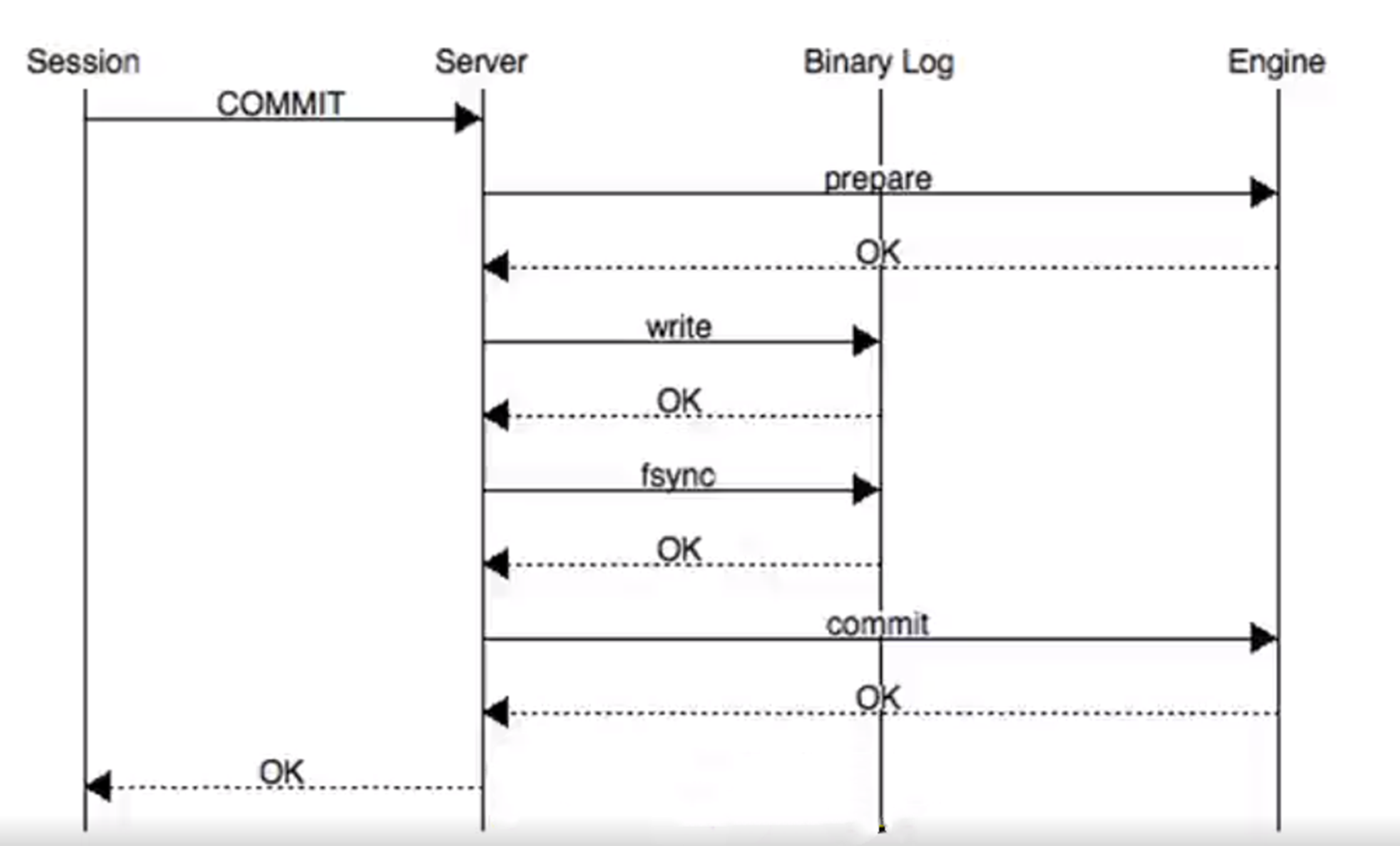
当然不同的 MySQL 它底层的版本参数也会有一些不一样,比如说它有些可能还是基于你事物提交多少个它就进行一个刷盘,或者中间你可以去设计一个缓冲区,容量达到多少它也会进行一个强制刷盘。
这个在不同的 MySQL 版本之间,它们的默认值,还有这些缓冲区的参数可能都不太一样。然后这里很多同学可能就会想,我学这些有什么用,平时在工作当中又用不上。
怎么说呢,还是有一定用途的,你会发现这些很多参数基本上都是在可用性跟性能之间去做一个选择,所以如果你在特定的业务场景下,你确实是可以在数据库层面去做这么一些调优。这也是为什么很多高级的DBA,他必须要去了解一定的业务场景。可能站在开发的角度就觉得 DBA 你只要管好运维就行了,你不用去关心我的业务。那同样呢,开发其实也可以去基于你的业务场景去反向给 DBA 提供一些建议,可以去调整哪些参数?可能在大部分小伙伴的工作环境下,其实并没有必要去调整这些东西,你的业务也可以正常的运行,所以大家就没有学习这些东西的积极性了。
但是我认为作为后端开发,你还是要去了解底层的一些结构的,这些配置的参数名你没必要去记,但是你至少知道大概有这么一个东西,然后用的时候你可以快速的去查,然后学到这些东西,你还可以把这种比较好的思想应用在你的项目实际的工作当中,他很多思想跟设计哲学其实是可以借鉴过来的,这也是我们对于技术专家和架构师他需要的一个通用能力。
好,这一期就分享我之前在面试当中问到这几个数据库比较复杂的问题,如果大家认为写的还不错,也希望大家点赞转发,没关注的小伙伴也别忘了关注下,后面就不会错过很多技术的干货了。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 如何在一个不能连公网的Ubuntu服务器上安装一个软件
前言 在Ubuntu服务器中,很多人习惯使用 apt-get 命令安装各种工具或者依赖,但是如果遇到一个不能连公网的服务器,那该怎么办呢? apt-get 工具下载dep包 先找一台可以联网的Ubuntu服务器,使用下面命令下载某个dep包,其中 xxxx 是…
