
很多同学会通过收集问卷的方式获取论文研究需要的数据,但是收集到的问卷应该如何分析呢?问卷一般可以分为两类:非量表类与量表类问卷。不同类型的问卷有不同的分析思路,今天和大家探讨一下拿到一份问卷后,一般的分析思路是怎样的。
一、量表问卷分析思路
SPSSAU提供以下五类量表数据分析思路供参考。分别是量表类问卷影响关系研究、量表类问卷中介调效应和调节效应研究、量表类问卷权重研究、“类实验”类问卷差异研究、聚类样本类问卷研究:
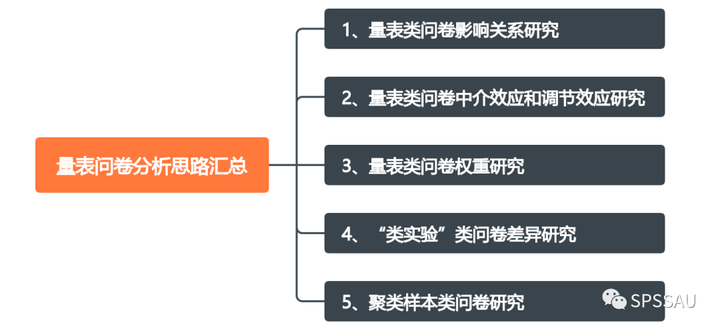
1、量表类问卷影响关系研究
影响关系研究十分常见,其核心问题是探究不同变量之间的相互影响和关系。通常可以使用相关分析研究变量之间的关系情况,如研究变量之间是否存在关系、关系紧密程度如何等,然后使用回归模型研究变量之间的回归影响关系情况。
量表类问卷影响关系研究分析思路如下:
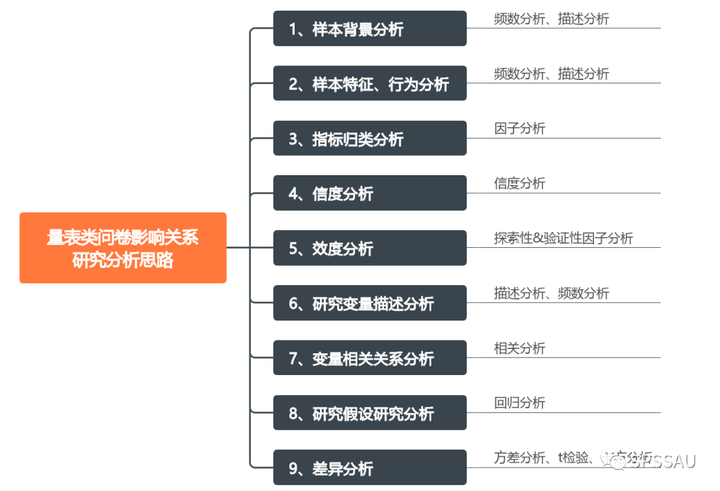
1.1样本背景分析
首先对收集数据进行基本的频数分析,比如统计性别,年龄、月收入水平,职业的分布情况如何等。SPSSAU频数分析结果如下:
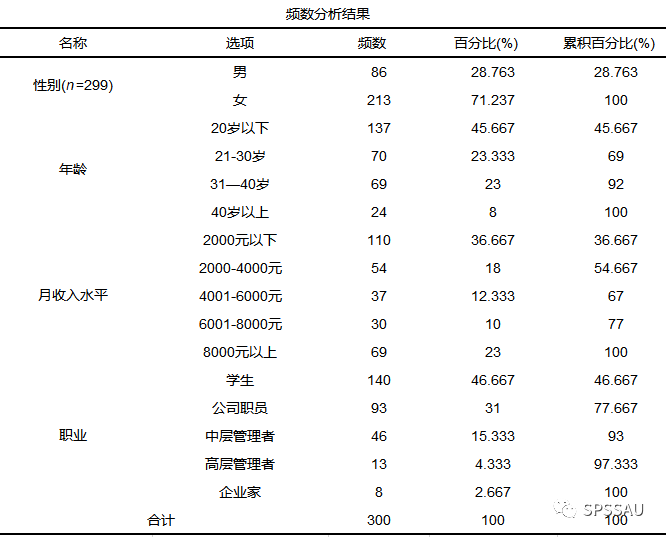
此部分的分析应先描述样本量,然后分别对样本背景信息进行描述,尤其是对重要信息点进行说明。
举例说明:本次调查共有299份问卷,其中参与调查的女性占比71.237%;20岁以下人群占比最高45.667%;月收入2000元以下人群占比最高为36.667%;学生人群占比最高为46.667%。
1.2 样本特征、行为分析
在对研究样本背景信息进行统计、描述后,要进一步对研究样本的基本态度、特征、行为等方面进行分析。
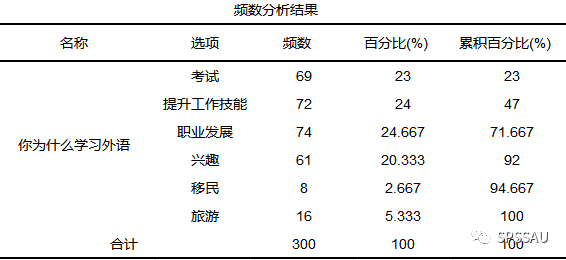
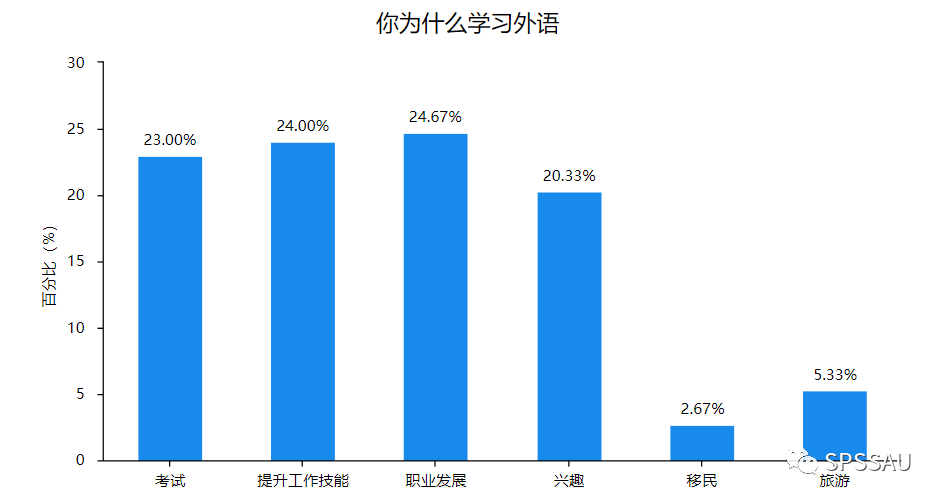
比如分析问卷中与样本基本态度有关的问题:“你为什么学习外语?”,“你有多长在线学习语言的经验?”,“你购买过多少门课程?”。这3个题均为单选题,因此分别统计频数选择情况(参考下图)。在进行报告时,首先应该关注选择比例较高的选项,突出重点。
1.3指标归类分析——探索性因子分析
影响关系研究时,问卷中通常会涉及非常多的量表题,如果量表题具体应该分成多少个维度,并不完全确定,此时可使用因子分析进行浓缩,得出几个维度(因子),并且找到维度与题项的对应关系情况。
1.4 信度分析
信度分析的目的在于研究样本数据是否真实可靠,通俗来讲就是研究受访者是否真实地回答了各个题。如果受访者没有真实回答,则信度不达标。信度仅针对量表题进行研究,无法针对比如性别,年龄之类的背景服务器托管网信息项进行分析。信度可分为以下服务器托管网5类,其中克隆巴赫信度系数最为常用:

1.5 效度分析——探索性因子分析、验证性因子分析
效度分析的目的在于判断研究题是否可以有效地测量研究人员需要测量的变量,通俗来讲就是测量问卷题是否准确有效。当信度分析不达标时,效度分析必然也不能达标。效度仅针对量表题进行研究。效度可分为以下4类:

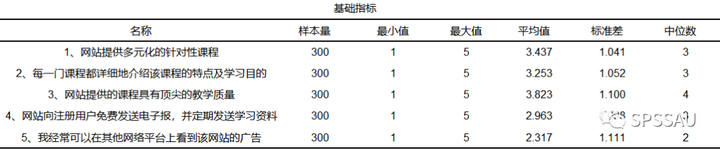
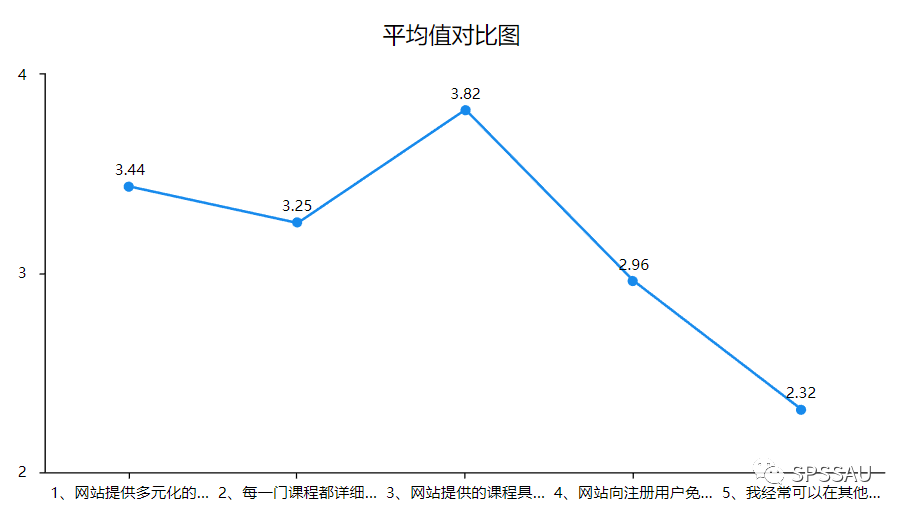
1.6 研究变量描述分析
研究变量描述分析的目的在于研究样本对变量的整体态度情况。在研究变量描述分析时,需要将反向题进行反向处理(习惯上的处理方式是分值越大越满意)。例如,当1分代表“非常同意”,5分代表“非常不同意时”,就需要将其反向处理为5分代表“非常同意”,1分代表“非常不同意”。通过计算变量的平均值或中位数进行分析,或者用折线图形式展示变量的平均值排序情况等。
SPSSAU描述分析结果如下:
1.7 变量相关关系分析——相关分析通过相关分析研究变量之间的关系情况,包括是否有关系和关系紧密程度。通常一个变量由多个题表示,因此在进行相关分析之前需要计算出多个题的平均值用于代表对应变量(SPSSAU生成变量—平均值进行处理)。
1.8 研究假设检验分析——回归分析
在数据有着相关的前提之下,再研究回归影响关系才具有意义。因而回归分析需要放在相关分析之后,并且通常情况下需要使用回归分析去验证假设。如果因变量为定量数据,那么可以使用线性回归分析或SEM结构方程模型进行假设验证;如果因变量为定类数据,那么使用logistic回归分析进行假设验证。
1.9 差异分析——方差分析、t检验、卡方分析差异分析的目的在于挖掘出更多有价值的研究结论,如男性和女性样本对研究变量是否有差异性态度。差异分析通常有3种分析方法,分别是方差分析、t检验及卡方分析。量表类问卷通常使用方差分析和t检验较多,非量表一般使用卡方分析较多。
2、量表类问卷中介效应和调节效应研究
在量表类问卷研究中,中介效应和调节效应研究也较为常见,中介效应和调节效应研究是影响关系研究的延伸,这两种研究多用于学术研究,基余部分与“影响关系研究”基本类似。
量表类问卷中介效应和调节效应研究思路如下:

重叠部分不再赘述,补充新增部分说明如下。
2.8.1 中介效应
中介效应是研究X对Y的影响时,是否会先通过中介变量M,再去影响Y;即是否有X->M->Y这样的关系;比如工作满意度(X)会影响到创新氛围(M),再影响最终工作绩效(Y)。
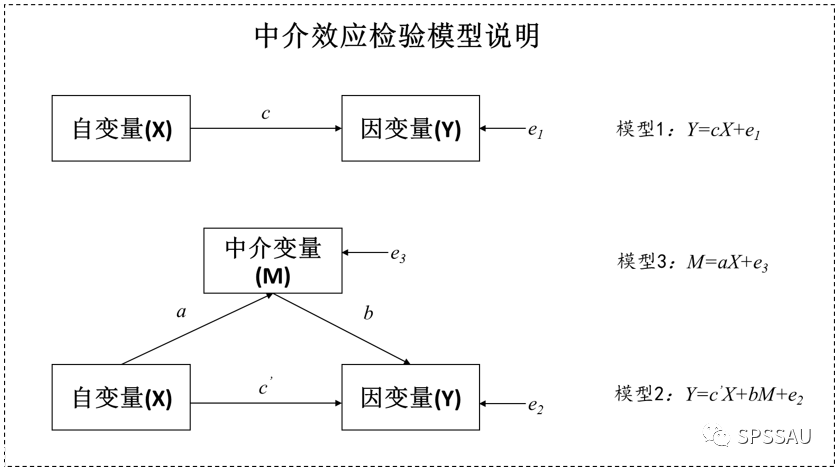
2.8.2 调节效应
调节效应是研究X对Y的影响时,是否会受到调节变量Z的干扰;比如开车速度(X)会对车祸可能性(Y)产生影响,这种影响关系受到是否喝酒(Z)的干扰,即喝酒时的影响幅度,与不喝酒时的影响幅度 是否有着明显的不一样。
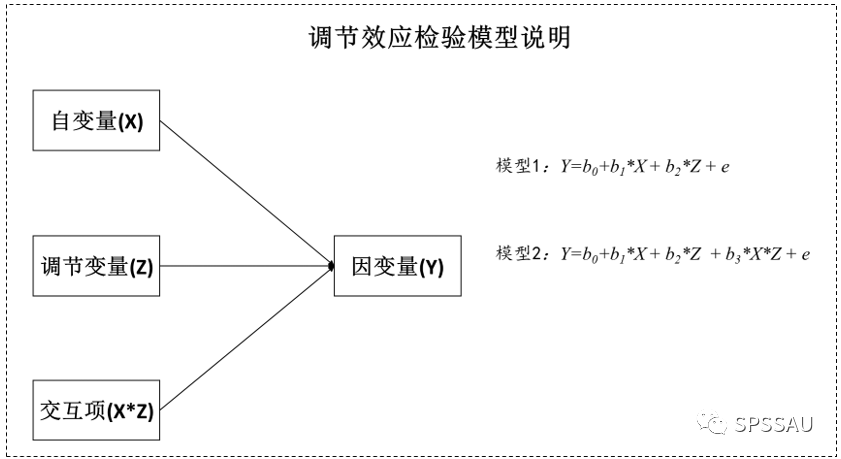
3、量表类问卷权重研究
量表类问卷权重研究的重心在于各个指标的权重得分,而非影响关系,通过计算各个指标或题的权重得分,构建完善的权重体系,并且结合各指标权重情况提出科学的建议。
量表类问卷权重研究分析思路如下:
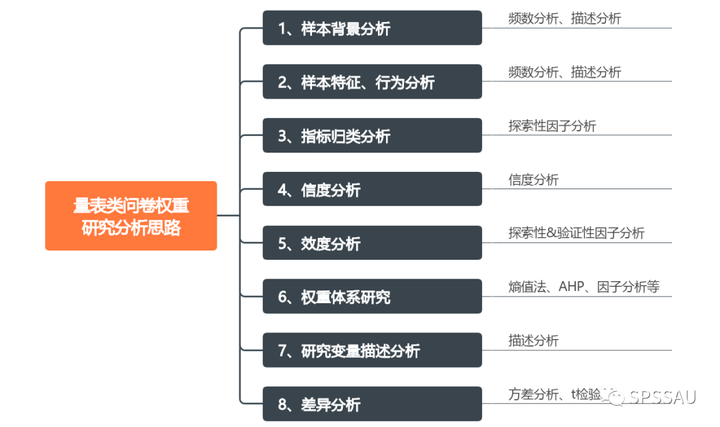
3.6 权重体系研究
指标的权重是指各级指标在整个评价体系中相对重要程度和价值高低的所占比例的量化值,每个指标的权重值将被记为0—1之间的小数,将1作为整个指标体系的权重之和。
4、“类实验”类问卷差异研究
“类实验”类问卷是指带有实验式背景的问卷。“类实验”式问卷通常以研究差异关系作为核心内容,一般使用单因素方差分析、多因素方差分析、t检验等方法进行研究。
“类实验”类问卷差异研究分析思路:
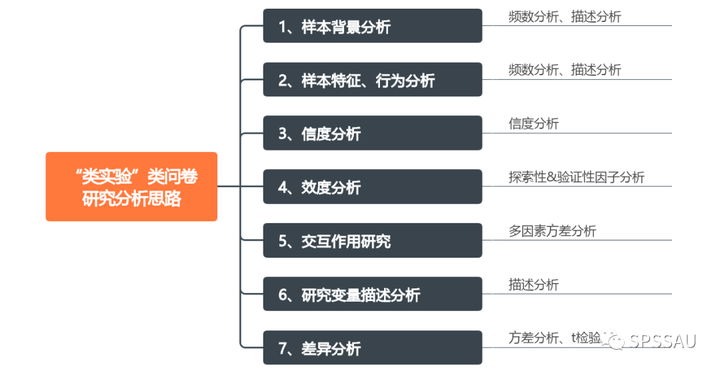
4.5 交互作用研究
交互作用研究是指研究多个分类自变量X对因变量Y(Y为定量数据)的影响,即研究多个分类自变量X分别在不同水平时,对Y的影响幅度的差异。例如现在想要研究不同施肥方式和不同品种水稻之间产量是否有差异,以及施肥方式和品种的交互作用对水稻产量是否有影响。类似上述说明的研究即为交互作用研究。
5、聚类样本类问卷研究
聚类样本研究时,第一想到的应该是样本“分类”,即样本人群应该分成几个类别;分了类别之后,通常肯定是需要对比不同类别人群的差异性,比如不同类别群体在态度,行为上的差异性等。
聚类样本类问卷研究分析思路如下:
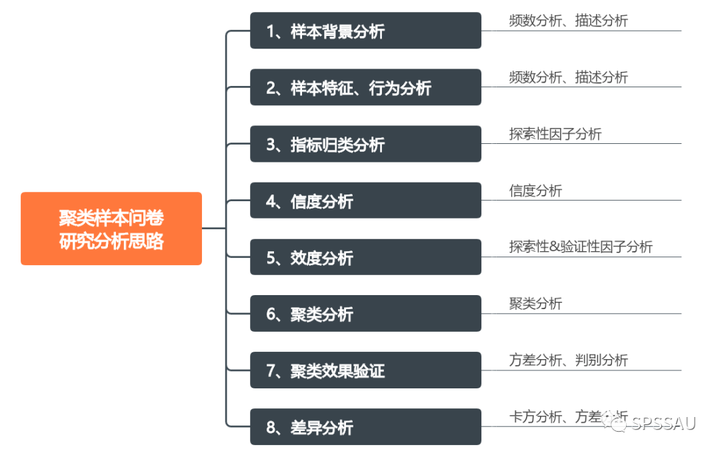
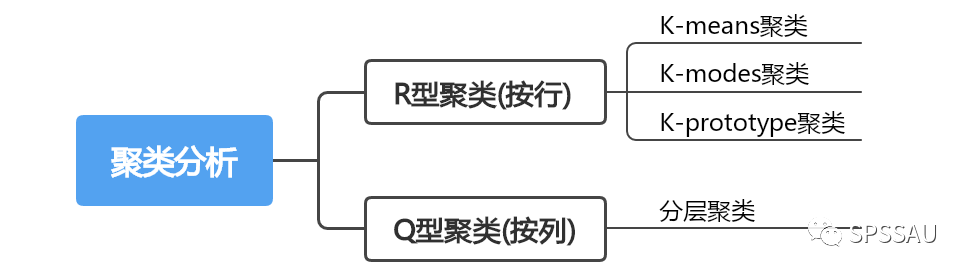
5.6 聚类分析
聚类分析可以对样本进行聚类分析(Q型聚类),也可以对变量进行聚类分析(R型聚类)。聚类分析分类如下:
5.7 聚类效果验证
聚类效果验证不同于其他分析方法,其他分析方法可以通过p值进行检验,聚类效果验证则需要一定的研究经验,并且结合专业知识进行综合判断。良好的聚类效果可以有效识别样本特征,聚类样本的特征差异对比通常使用方差分析进行,有时也可以通过判别分析判断聚类效果。
二、非量表问卷分析思路
在通常情况下,非量表类问卷是针对某个话题进行现状分析,并且了解样本的基本态度情况,研究不同类别样本的现状或态度差异,然后结合分析结论提供有意义的建议措施等。
非量表问卷分析思路框架如下图所示:

与量表问卷分析思路重叠部分不在进行赘述,补充新增部分。
3、基本现状分析
充分了解样本现状情况,以及样本的态度情况,结合结果可以对不同群体的态度差异情况、现状差异情况进行分析,或者进一步研究影响关系。
在进行研究时,不应该拘泥于分析方法的使用,此部分更多会使用简单易懂的频数和百分比描述,最好结合各种图形展示,比如多选题可以使用条形图,单选题可以使用柱形图展示等。
举例说明:比如对多选题“影响购买课程的因素”进行分析,SPSSAU多选题分析结果如下:
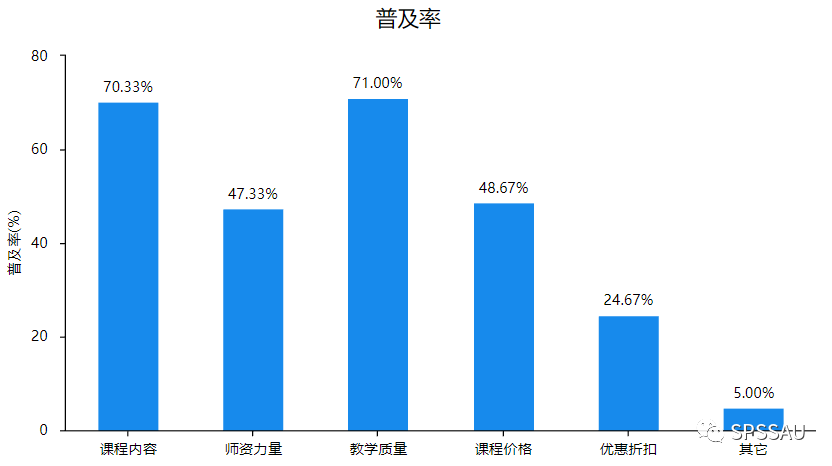
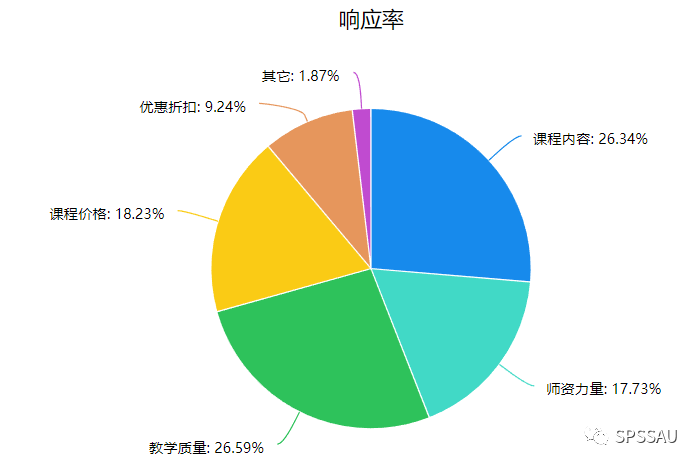
在文字分析过程中,研究人员需要更多关注选择比例较高选项。从分析结果可以看出,“教学质量”和“课程内容”这两项的选择比例明显高于其他各项,“优惠折扣”和“其他”的选择比例相对少很多。
4、样本态度分析
如果问卷中涉及样本的认知态度相关问题,可使用频数分析或多选题分析进行汇总,进一步了解清楚样本特征情况(分析参照以上过程)。
5、差异分析
在上一部分打好基础后,就可以开始比较差异了。可以分析不同样本人群在题项上的态度差异,也或者不同人群在基本现状题项上的差异情况进行差异对比分析。
研究方法上看,针对非量表类题项关系研究,即分类与分类数据之间的关系研究,应该使用卡方分析。
举例说明:研究不同职业为什么学习英语的差异?SPSSAU卡方分析结果如下:
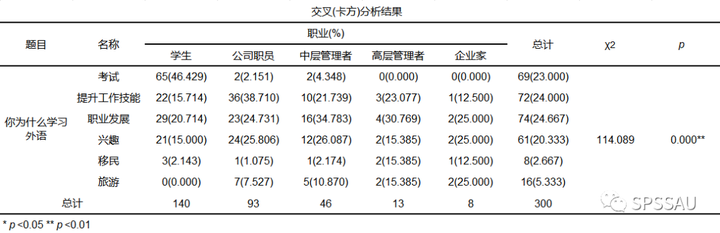
从卡方分析结果可以知道,不同职业人群学习英语的原因存在显著差异(chi=114.089, p=0.000
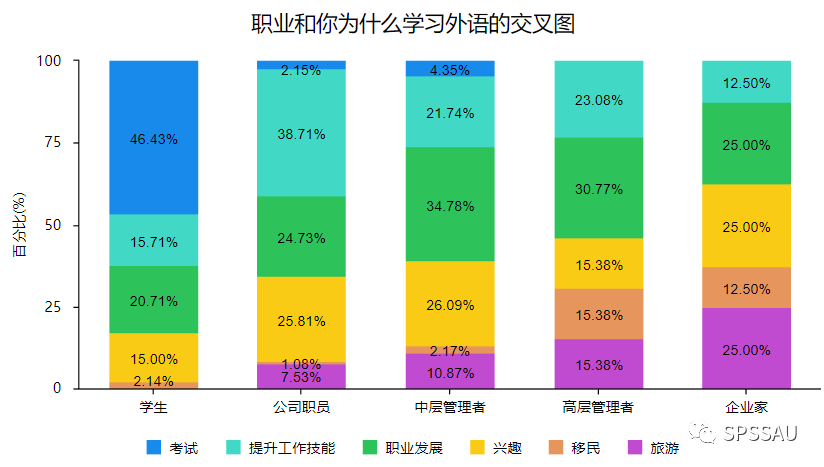
从上图可以直观看出,学生人群学习外语主要为了考试(占比46.43%),公司职员主要为了提升工作技能(占比38.71%)等等,在此不再进行赘述。
6、影响关系分析
接下来,可以研究某种因素对样本态度的影响关系。当因变量Y为定类数据时,应该使用logistic回归分析进行影响关系研究。logistic回归分析有以下三类,说明如下:
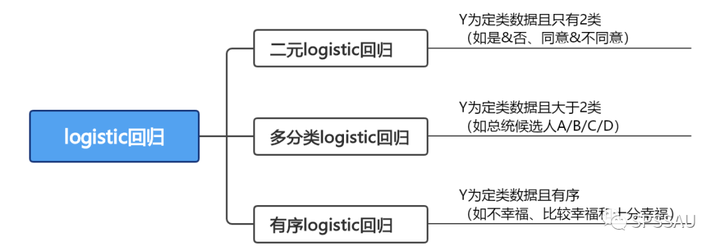
举例说明:你要研究哪些因素会对因变量—“你是否愿意将课程分享给其他人?”产生影响。此时因变量为二分类变量,所以应该使用二元logistic回归分析进行研究。
7、其他
如果问卷中含有定量变量存储的数据,如身高、体重等,可以进行相关分析研究。或者使用方差分析或t检验进行差异性分析等。
- 非量表问卷分析思路核心
此类研究框架的核心在于“分组”。
- 第一件事情为“分组”,也就是给每个题分组,比如问卷有30个题,那这30题可以被归纳为几个方面呢?比如基本背景,认知,态度,行为,原因等五个方面。
- 第二件事情是将“分组”分别作为一个部分进行分析,比如上面提到的样本基本背景,就可以用频数分析来统计分析数据。
- 第三件事情是分组题项与分组题项之间进行交叉。比如基本背景分别与“认知”,“态度”,“行为”,“原因”上的差异性。通常是使用交叉分析。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
总结了几个很有意思的基础题目,分享一下。 为什么 0.1 + 0.1 !== 0.2 看到这个问题,不得不想到计算机中的数据类型,其中浮点数表示有限的精度。那么它就无法精确的表示所有的十进制小数,所以在在某些情况下,浮点数的运算可能会导致微小的精度误差。这就是…
