
- 什么是循环依赖?
通俗来讲,循环依赖指的是一个实例或多个实例存在相互依赖的关系(类之间循环嵌套引用)。
举个例子
public class AService {
private BService bService;
}
public class BService {
private AService aService;}
复制代码
上述例子中 AService 依赖了 BService,BService 也依赖了 AService,这就是两个对象之间的相互依赖。当然循环依赖还包括 自身依赖、多个实例之间相互依赖。
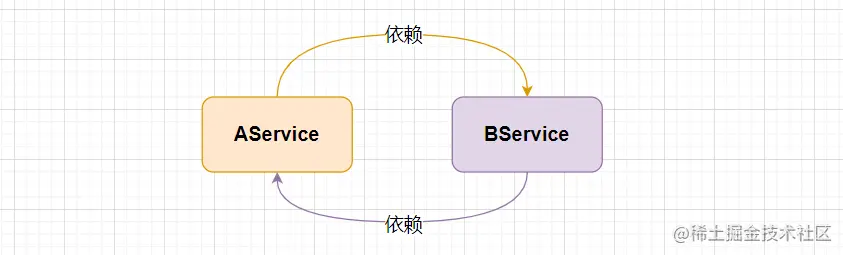
正常运行上面的代码调用 AService 对象并不会出现问题,也就是说普通对象就算出现循环依赖也不会存在问题,因为对象之间存在依赖关系是很常见的,那么为什么被 Spring 容器管理后的对象会出现循环依赖问题呢?
- Spring Bean 的循环依赖问题
被 Spring 容器管理的对象叫做 Bean,为什么 Bean 会存在循环依赖问题呢?
想要了解 Bean 的循环依赖问题,首先需要了解 Bean 是如何创建的。
2.1 Bean 的创建步骤
为了能更好的展示出现循环依赖问题的环节,所以这里的 Bean 创建步骤做了简化:
在创建 Bean 之前,Spring 会通过扫描获取 BeanDefinition。
BeanDefinition就绪后会读取 BeanDefinition 中所对应的 class 来加载类。
实例化阶段:根据构造函数来完成实例化 (未属性注入以及初始化的对象 这里简称为 原始对象)
属性注入阶段:对 Bean 的属性进行依赖注入 (这里就是发生循环依赖问题的环节)
如果 Bean 的某个方法有AOP操作,则需要根据原始对象生成代理对象。
最后把代理对象放入单例池(一级缓存singletonObjects)中。
上面的步骤主要是为了突出循环依赖问题,如果想了解 Bean 的完整生命周期可以看这一篇文章:浅谈 Spring Bean 的生命周期 – 掘金 (juejin.cn)
两点说明:
上面的 Bean 创建步骤是对于 单例(singleton) 作用域的 Bean。
Spring 的 AOP 代理就是作为 BeanPostProcessor 实现的,而 BeanPostProcessor 是发生在属性注入阶段后的,所以 AOP 是在 属性注入 后执行的。
2.2 为什么 Spring Bean 会产生循环依赖问题?
通过上面的 Bean 创建步骤可知:实例化 Bean 后会进行 属性注入(依赖注入)
如上面的 AService 和 BService 的依赖关系,当 AService 创建时,会先对 AService 进行实例化生成一个原始对象,然后在进行属性注入时发现了需要 BService 对应的 Bean,此时就会去为 BService 进行创建,在 BService 实例化后生成一个原始对象后进行属性注入,此时会发现也需要 AService 对应的 Bean。

这样就会造成 AService 和 BService 的 Bean 都无法创建,就会产生 循环依赖 问题。
2.3 三大循环依赖问题场景
Spring 并不能解决所有 Bean 的循环依赖问题,接下来通过例子来看看哪些场景下的循环依赖问题是不能被解决的。
AService 类
/**
- @author 单程车票
*/
public class AService {
private BService bService;
public AService() {
}
public AService(BService bService) {
this.bService = bService;
}
public BService getbService() {
return bService;
}
public void setbService(BService bService) {
this.bService = bService;
}}
复制代码
BService 类
/**
- @author 单程车票
*/
public class BService {
private AService aService;
public BService() {
}
public BService(AService aService) {
this.aService = aService;
}
public AService getaService() {
return aService;
}
public void setaService(AService aService) {
this.aService = aService;
}}
复制代码
测试类
/**
- 测试类
- @author 单程车票
*/
public class Application {
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("application-context.xml");
AService aService = (AService) applicationContext.getBean("aService");
System.out.println("执行成功,获取AService对象为:" + aService);
}}
复制代码
单例作用域下的 Setter方法注入 / field属性注入 出现的循环依赖
application-context.xml 配置文件
使用 property 标签也就是 Setter方法 进行属性注入。
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
复制代码
运行结果

可以看到 Setter方法注入方式 在 Spring 中是不会产生循环依赖问题的,这主要是靠 三级缓存 机制(下文会详细说明)。
单例作用域下的 构造器注入 出现的循环依赖
application-context.xml 配置文件
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
复制代码
运行结果
抛出 BeanCurrentlyInCreationException 异常,说明 Spring 无法解决 构造器注入 出现的循环依赖问题。

原因:因为 构造器注入 发生在 实例化阶段,而 Spring 解决循环依赖问题依靠的 三级缓存 在 属性注入阶段,也就是说调用构造函数时还未能放入三级缓存中,所以无法解决 构造器注入 的循环依赖问题。
原型 作用域下的属性注入出现的循环依赖问题
application-context.xml 配置文件
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
复制代码
运行结果
同样抛出 BeanCurrentlyInCreationException 异常,说明 Spring 无法解决 原型作用域 出现的循环依赖问题。

原因:因为 Spring 不会缓存 原型 作用域的 Bean,而 Spring 依靠 缓存 来解决循环依赖问题,所以 Spring 无法解决 原型 作用域的 Bean。
- Spring 如何解决循环依赖问题?
通过上文的内容能了解到 Spring 为什么会产生循环依赖问题 以及 Spring 能解决什么场景下的循环依赖问题。
上文中也有提到过 Spring 是靠 三级缓存 来解决循环依赖问题的,接下来了解一下 什么是三级缓存 以及 解决循环依赖问题的具体流程。
3.1 三级缓存是什么?
/* Cache of singleton objects: bean name to bean instance. /
private final MapsingletonObjects = new ConcurrentHashMap(256);
/* Cache of singleton factories: bean name to ObjectFactory. /
private final Map
/* Cache of early singleton objects: bean name to bean instance. /
private final Map
复制代码
三级缓存分为:
一级缓存(singletonObjects):缓存的是已经实例化、属性注入、初始化后的 Bean 对象。
二级缓存(earlySingletonObjects):缓存的是实例化后,但未属性注入、初始化的 Bean对象(用于提前暴露 Bean)。
三级缓存(singletonFactories):缓存的是一个 ObjectFactory,主要作用是生成原始对象进行 AOP 操作后的代理对象(这一级缓存主要用于解决 AOP 问题,后续文章中讲解)。
3.2 为什么缓存可以解决循环依赖问题?
(注意这里只是为了说明缓存可以解决循环依赖问题,但是 Spring 实际上并不是这样做的)
上文中可以看到 AService 和 BService 的循环依赖问题是因为 AService的创建 需要 BService的注入,BService的注入 需要 BService的创建,BService的创建 需要 AService的注入,AService的注入 需要 AService的创建,从而形成的环形调用。
想要打破这一环形,只需要增加一个 缓存 来存放 原始对象 即可。
在创建 AService 时,实例化后将 原始对象 存放到缓存中(提早暴露),然后依赖注入时发现需要 BService,便会去创建 BService,实例化后同样将 原始对象 存放到缓存中,然后依赖注入时发现需要 AService 便会从缓存中取出并注入,这样 BService 就完成了创建,随后 AService 也就能完成属性注入,最后也完成创建。这样就打破了环形调用,避免循环依赖问题。
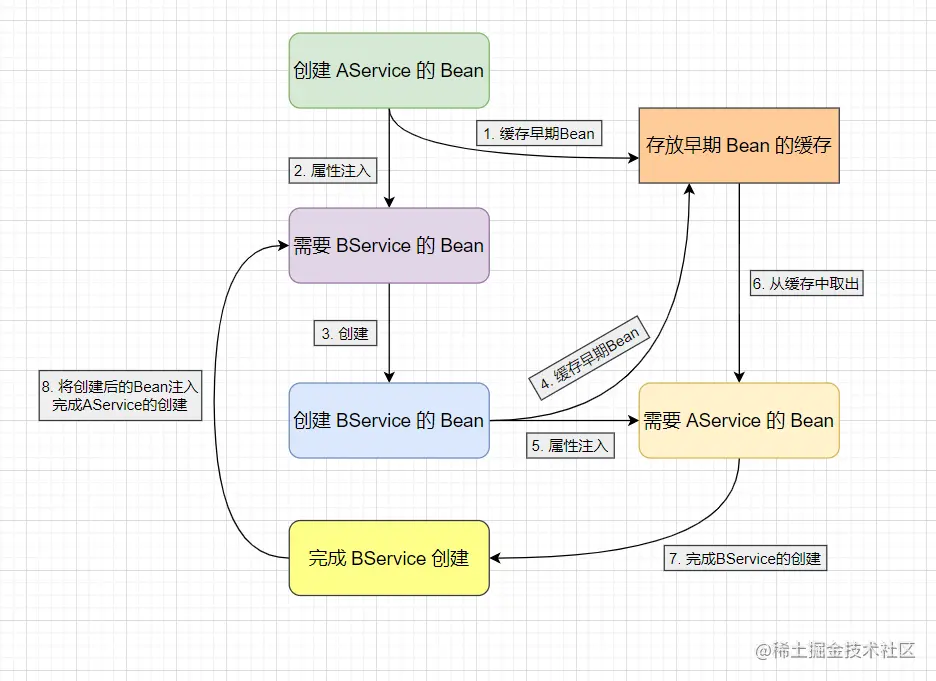
3.3 为什么还需要第三级缓存?
通过上面的分析可以发现只需要一个存放 原始对象 的缓存就可以解决循环依赖问题,也就是说只要二级缓存(earlySingletonObjects)就够了,那么为什么 Spring 还设置了三级缓存(singletonFactories)呢?
其实 第三级缓存(singletonFactories) 是为了处理 Spring 的 AOP的。
如上面的例子如果 AService 中方法没有使用 AOP 操作,会发现 BService 注入的 原始对象 与最后 AService 完成创建后的最终对象是同一个对象。
如果 AService 方法中有 AOP 操作,Bean 的创建会如下图:

所以如果 AService 方法中有 AOP 操作时,当 AService 的原始对象赋值(注入)给 BService,AService 会进行 AOP 操作产生一个 代理对象,这个代理对象最后会被放入单例池(一级缓存)中,也就是说此时 BService 中注入的对象是原始对象,而 AService 最终创建的完成后是代理对象,这样就会导致 BService 依赖的 AService 和 最终的 AService 不是同一个对象。
出现这个问题主要是上文提到过的 AOP 是通过 BeanPostProcessor 实现的,而 BeanPostProcessor 是在 属性注入阶段后 才执行的,所以会导致注入的对象有可能和最终的对象不一致。
3.4 Spring 是如何通过第三级缓存来避免 AOP 问题的?
三级缓存中存放的是 ObjectFactory 对象,那 ObjectFactory 是什么呢?
ObjectFactory 是什么?
深入源码会发现 Spring 在 doCreateBean() 方法中的 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)) 加入缓存。
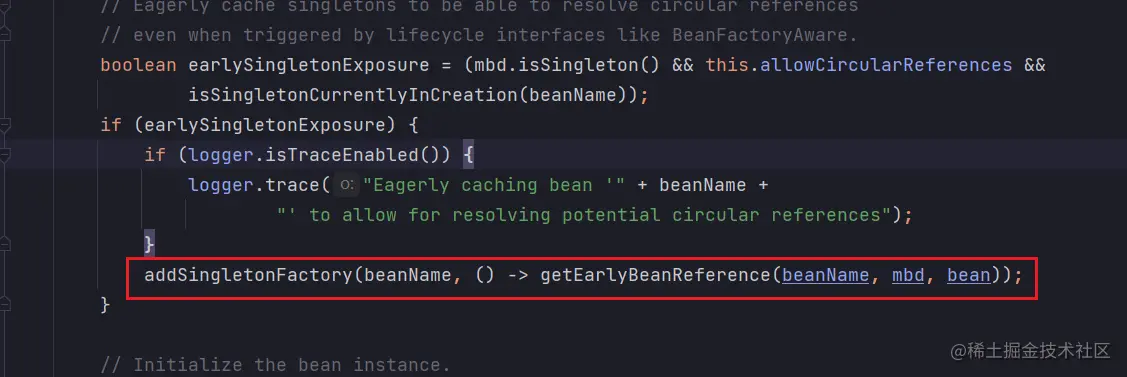
深入 addSingletonFactory 方法:可以看到方法中的第二个参数就是 ObjectFactory 类型,并且将其添加进 三级缓存(singletonFactories) 中。

这里放一下 ObjectFactory 类:
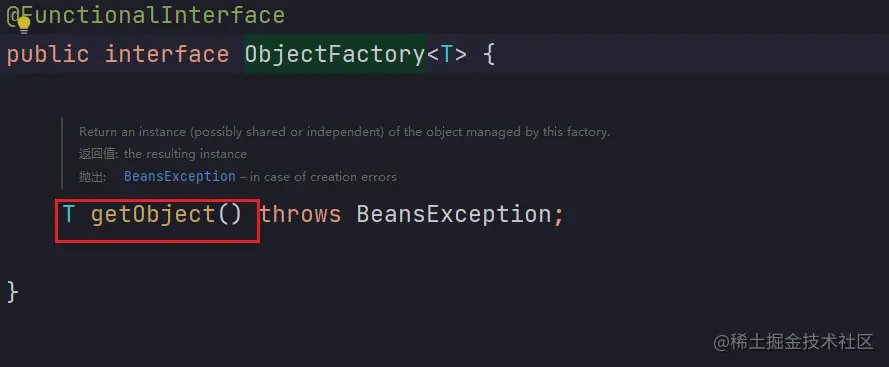
也就是说 Spring 在加入缓存时,会将 实例化后生成的原始对象 通过 lambda 表达式调用 getObject() 方法,getObject() 方法里调用 getEarlyBeanReference() 方法 来封装成 ObjectFactory 对象。
getEarlyBeanReference() 方法的作用
进入 getEarlyBeanReference() 中,会发现调用了 SmartInstantiationAwareBeanPostProcessor 的 getEarlyBeanReference() 方法。

找到 SmartInstantiationAwareBeanPostProcessor 的实现类 AbstractAutoProxyCreator 实现的 getEarlyBeanReference() 方法就可以看到其作用了。
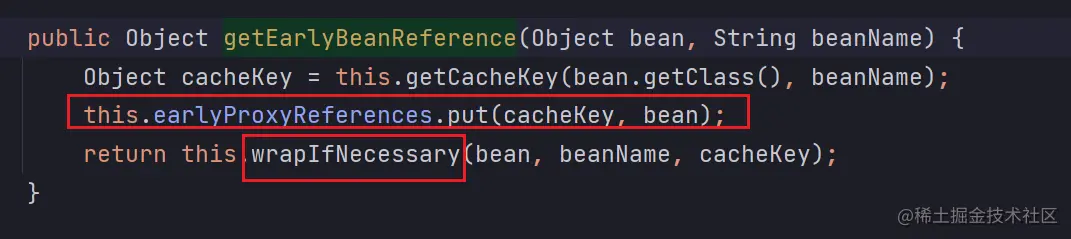
earlyProxyReferences 存储的是 (beanName, bean) 键值对,这里的 bean 指的是原始对象(刚实例化后的对象)。
wrapIfNecessary() 方法用于执行 AOP 操作,生成一个代理对象(也就是说如果有 AOP 操作最后返回的是代理对象,否则返回的还是原始对象)。
Spring 真正意义上地创建 Bean 的流程
先放具体流程图:

要点说明:
并不是马上就执行 ObjectFactory 的 getEarlyBeanReference() 方法(有循环依赖时才执行)。
实例化后的 Bean 会生成原始对象,然后经过 lambda 表达式封装为 ObjectFactory 对象,并且通过 addSingletonFactory() 方法将其放入 三级缓存(singletonFactories)中。
但是这里执不执行 lambda 表达式中的 getEarlyBeanReference() 方法是看程序有没有调用 singletonFactories.get(beanName),只有调用了该方法(其实也就是看是否存在循环依赖需要提前获得该 Bean),才会触发执行 getEarlyBeanReference() 方法。
而 getEarlyBeanReference() 方法会根据 Bean 中是否有 AOP 操作来决定返回的是 原始对象 还是 代理对象,并且会将其上移到二级缓存中(也就是提前暴露出来让别的 Bean 使用)。
如果 Bean 中有 AOP 操作,而 AOP 操作又是在属性注入之后执行的,那么之前的 getEarlyBeanReference() 方法中执行的 AOP 操作会不会重复?
答案是不会,还记得 getEarlyBeanReference() 方法中的 earlyProxyReferences 吗,这个就是用来记录当前 Bean 是否已经执行 AOP 操作。
当属性注入后需要执行 AOP 操作时,会先判断当前的 Bean 是否在 earlyProxyReferences 中,如果在则说明已经提前执行了 AOP 了,不用再执行了,否则就执行当前 AOP 操作。
二级缓存中的对象什么时候会上移到一级缓存?
二级缓存是为了提前暴露 Bean 来解决循环依赖问题,此时的 Bean 可能还没有进行属性注入,只有等完成了属性注入、初始化后的 Bean 才会上移到一级缓存(单例池)中。
为什么可以解决 AOP 的问题?
三级缓存通过利用 ObjectFactory 和 getEarlyBeanReference() 做到了提前执行 AOP 操作从而生成代理对象。
这样在上移到二级缓存时,可以做到如果 Bean 中有 AOP 操作,那么提前暴露的对象会是 AOP 操作后返回的代理对象;如果没有 AOP 操作,那么提前暴露的对象会是原始对象。
这样就能做到出现循环依赖问题时,注入依赖的对象和最终生成的对象是同一个对象。(相当于 AOP 提前在属性注入前完成,这样就不会导致后面生成的代理对象与属性注入时的对象的不一致)
所以 Spring 利用 三级缓存 巧妙地将出现 循环依赖 时的 AOP 操作 提前到了 属性注入 之前,避免了对象不一致问题。
- 梳理 Spring 解决 Bean 的循环依赖的整个流程
还是以 AService 和 BService 的循环依赖为例,完整地看看 Spring 是如何解决 Bean 的循环依赖问题。
源码分析整个流程
由于前面的内容过于繁琐,这里就以文字概括,只关注几个主要的方法:
以 AbstractApplicationContext 的 refresh() 方法出发,进入 finishBeanFactoryInitialization() 方法再进入 preInstantiateSingletons() 方法再进入 getBean() 方法再进入 doGetBean() 方法。
看看 doGetBean() 方法:

其中的第一个 getSingleton(beanName) 是判断 三级缓存 中是否有创建好的 Bean 对象,看看源码:
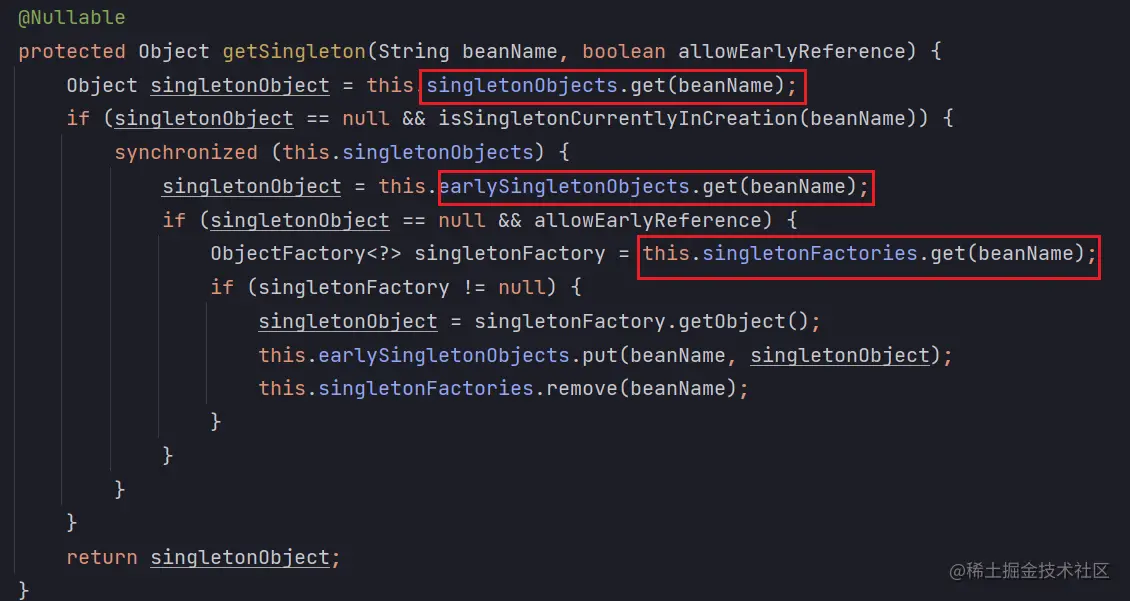
可以看到这里分别去每一级的缓存中取数据,依次从第一级开始取数据,如果取得到则直接返回,取不到则往下一级查找。
可以看到在第三级缓存中调用了 singletonFactories.get(beanName) 按照上文所说的会触发执行有 AOP 操作返回代理对象,没有返回原始对象,并且在这里会判断取出的数据是否存在,存在则上移到二级缓存中并删除三级缓存的数据。
如果都没有的话就会执行第二个 getSingleton() 也就是去执行 createBean() 创建一个 Bean 对象出来。
会执行 createBean() 方法中的 doCreateBean() 方法,看看源码:
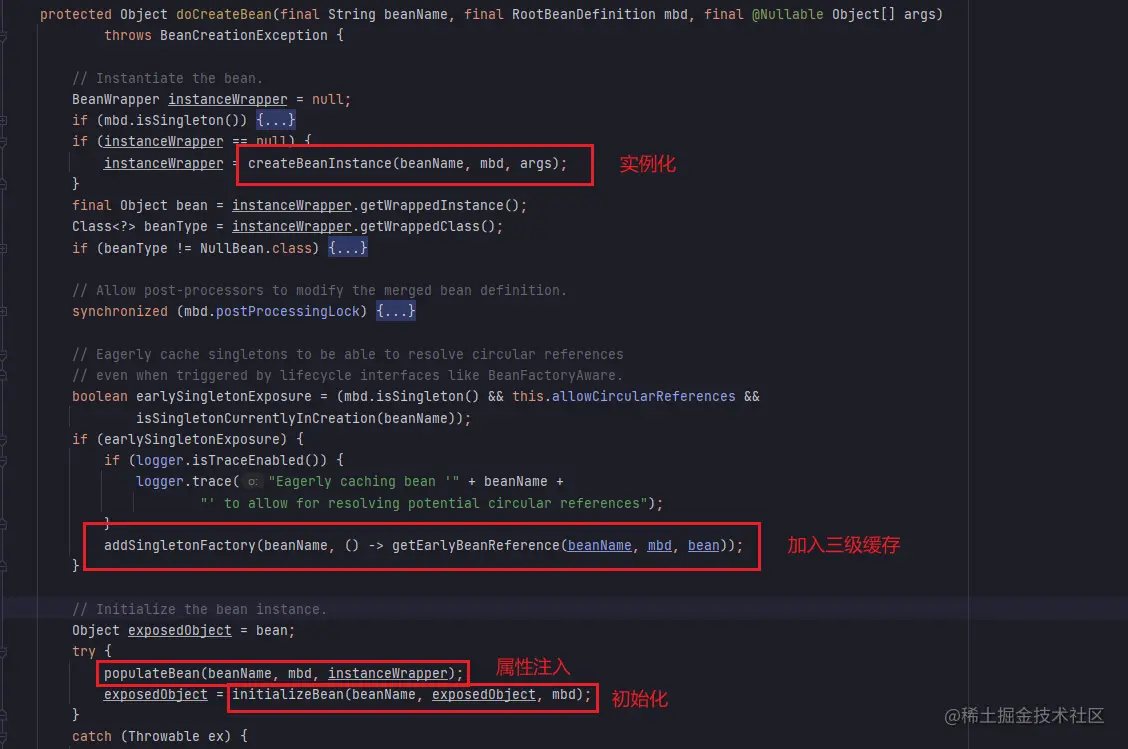
到这里应该就一目了然了。
梳理整个流程
首先会获取 AService 对应的 Bean 对象。
先是调用 doGetBean() 中的第一个 getSingleton(beanName) 判断是否有该 Bean 的实例,有就直接返回了。(显然这里没有)
然后调用 doGetBean() 中的第二个 getSingleton() 方法来执行 doCreateBean() 方法。
先进行实例化操作(也就是利用构造函数实例化),此时实例化后生成的是原始对象。
将原始对象通过 lambda表达式 进行封装成 ObjectFactory 对象,通过 addSingletonFactory 加入三级缓存中。
然后再进行属性注入,此时发现需要注入 BService 的 Bean,会通过 doGetBean() 去获取 BService 对应的 Bean。
同样调用 doGetBean() 中的第一个 getSingleton(beanName) 判断是否有该 Bean 的实例,显然这里也是不会有 BService 的 Bean 的。
然后只能调用 doGetBean() 中的第二个 getSingleton() 方法来执行 doCreateBean() 方法来创建一个 BService 的 Bean。
同样地先进行实例化操作,生成原始对象后封装成 ObjectFactory 对象放入三级缓存中。
然后进行属性注入,此时发现需要注入 AService 的 Bean,此时调用调用 doGetBean() 中的第一个 getSingleton(beanName) 查找是否有 AService 的 Bean。此时会触发三级缓存,也就是调用 singletonFactories.get(beanName)。
因为三级缓存中有 AService 的原始对象封装的 ObjectFactory 对象,所以可以获取到的代理对象或原始对象,并且上移到二级缓存中,提前暴露给 BService 调用。
所以 BService 可以完成属性注入,然后进行初始化后,将 Bean 放入一级缓存,这样 AService 也可以完成创建。
以上就是 Spring 解决 Bean 的循环依赖问题的整个流程了。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
