
深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解
1.SpanBERT: Improving Pre-training by Representing and Predicting Spans
1.1. SpanBERT的技术改进点
相比于BERT,SpanBERT主要是在预训练阶段进行了调整,如图1所示,具体包含以下几部分:
- 随机地Masking一段连续的token
- 增加了一项新的预训练任务:Span boundary Objective (SBO)
- 去掉了NSP任务
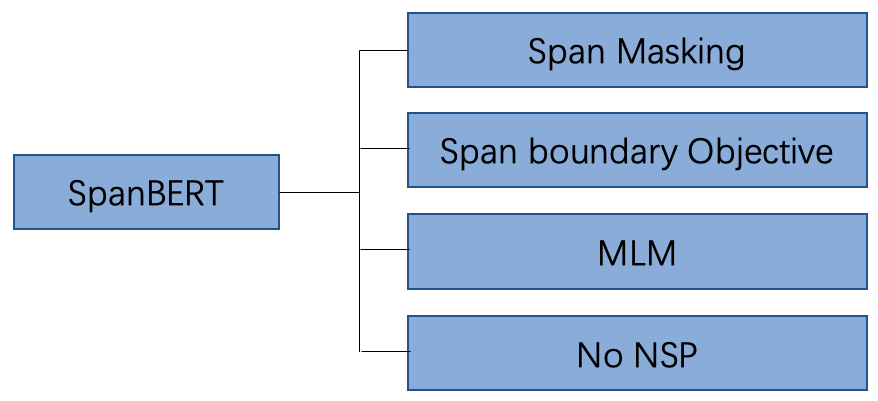
图1 SpanBERT改进点汇总图
在接下来的内容中,我们将对这些预训练任务进行详细探讨,特别是前两个改进点。但是在正式讨论之前,我们先来回顾一下经典的BERT模型中的预训练任务。
1.2. BERT模型中的预训练任务
在BERT模型预训练阶段,主要使用了两项预训练任务Masking Language Model (MLM)以及Next Word Prediction (NSP)。
1.2.1 Masking Language Model (MLM)
在训练语料中,会选择一批token替换为Mask token,MLM任务旨在利用语句的上下文双向信息,恢复语句中被Mask的token,以帮助模型学习语言知识。图2给出了关于MLM任务一个示例,其中在预测单词model的时候,模型将会利用model前后的信息进行推断被Masking的单词,特别是在看到pre-training和natural language processing等信息时,比较容易能够推断出这个单词就是model。

图2 MLM样例图
在BERT模型预训练阶段,总共Masking掉语料中15%的token,但是这里存在一个问题:在fine-tune阶段以及预测时的输入文本中并不包含Mask token,这样就造成了预训练阶段和fine-tune/预测阶段的GAP。所以BERT在这批被Mask的token中采用了不同的Masking策略,具体如下:
- 80%的token被替换为Mask token
- 10%的token被随机替换为其他词
- 10%的token保持不变
1.2.2 Next Word Prediction (NSP)
在BERT的训练语料中,部分输入文本是由无关的两段语句进行拼接而成,部分输入文本是由本来就前后相邻的两段语句拼接而成。NSP任务旨在去识别一个输入文本是否是相邻的两句话拼接而成。图3给出了关于NSP的一个语料文本示例。

图3 NSP样例图
1.3. SpanBERT的预训练任务
1.3.1 Span Masking
在BERT的Masking策略中,每个被mask的token被随机选择,所以被选择的这些token是比较分散的。然而Span Masking则是需要随机地Mask连续的多个token。
具体来讲,首先SpanBERT根据几何分布$Geo(p)$采样一个Span的长度$l$,该几何分布倾向于选择短Span。然后在文本中随机选择起始点,即从起始点开始的$l$长度token将会被Mask。图4展示了Span采样长度图。
这里需要注意一点,SpanBERT在采样时,选择的是完整的word序列,而不是subword序列。
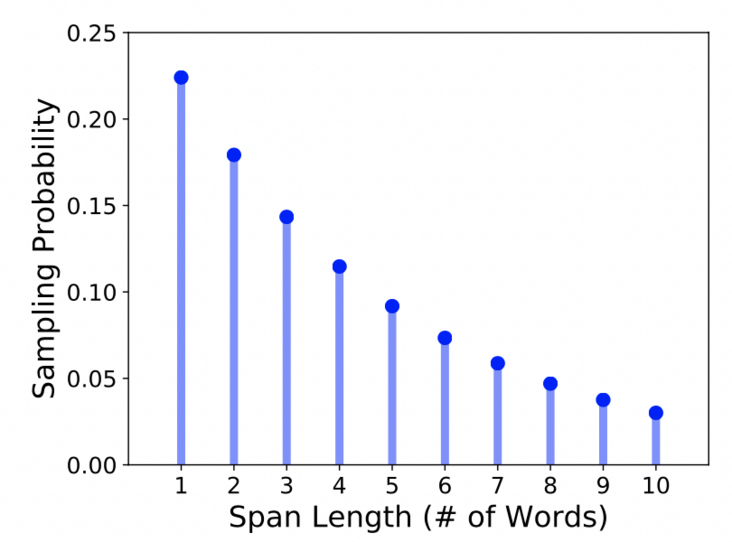
图4 Span采样长度图
1.3.2 Span Boundary Object (SBO)
SpanBERT期望Span边界的token能够尽可能多地汇总Span内部的信息,所以引入了SBO预训练目标。如图5所示,masking的连续token为””an American football game”,SBO任务期望使用Span的边界token$x_4$和$x_9$来预测Span内容。
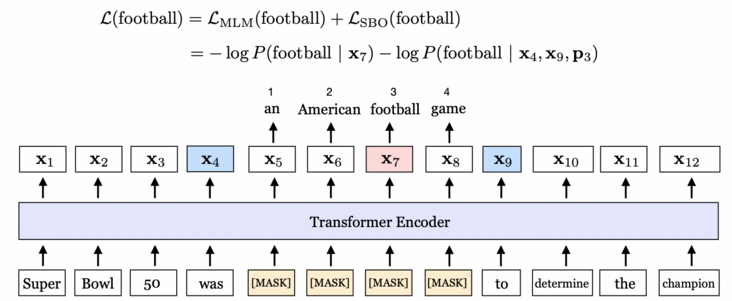
图5 SBO样例图
具体来讲,给定一串序列$text{X}={x_1, x_2, …, x_n}$,假设Mask的连续token为$(x_s,…,x_e)$, $x_s$和$x_e$代表起始token和末端token。SpanBERT将使用边界token $x_{s-1}$和$x_{e+1}$来计算Span内部的每个token。
$$y_i = f(x_{s-1}, x_{e+1}, P_{i-s+1})$$
其中,$P_{i-s+1}$代表Span内部的token$x_i$相对于边界token$x_{s-1}$的相对位置编码。以上公式具体是这么计算的。
$$begin{split} begin{align} h_0 &= [x_{s-1};x_{e+1};P_{i-s+1}] h_1 &= text{LayerNorm}(text{GeLU}(W_1h_0)) y_i &= text{LayerNorm}(text{GeLU}(W_2h_1)) end{align} end{split}$$
1.3.3 MLM与SBO融合计算
如上图所示, 在预测单词football的时候,即使用了MLM任务去预测单词football,同时又使用了SBO任务去预测football,最终将二者进行相加。相应公式为:
$$begin{split} begin{align} L(x_i) &= L_{text{MLM}}(x_i)+L_{text{SBO}}(x_i) & = -text{log}P(x_i|text{x}_i) – text{log}P(x_i|y_i) end{align} end{split}$$
1.3.4 去掉NSP任务
SpanBERT去掉了NSP任务,即输入文本是一个比较长的句子,大部分情况下这样的设置,实验效果会更好。
- 相关资料
- SpanBERT: Improving Pre-training by Representing and Predicting Spans
- SpanBERT Github
2.RoBERTa: A Robustly Optimized BERT Pretraining Approach
从模型结构上讲,相比BERT,RoBERTa基本没有什么创新,它更像是关于BERT在预训练方面进一步的探索。其改进了BERT很多的预训练策略,其结果显示,原始BERT可能训练不足,并没有充分地学习到训练数据中的语言知识。
图1展示了RoBERTa主要探索的几个方面,并这些方面进行融合,最终训练得到的模型就是RoBERTa。
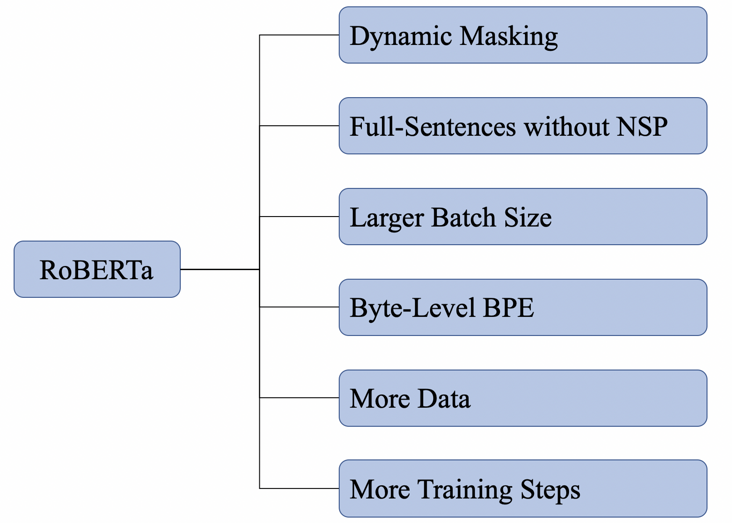
图1 RoBERT的改进点
2.1. Dynamic Masking
BERT中有个Masking Language Model(MLM)预训练任务,在准备训练数据的时候,需要Mask掉一些token,训练过程中让模型去预测这些token,这里将数据Mask后,训练数据将不再变化,将使用这些数据一直训练直到结束,这种Mask方式被称为Static Masking。
如果在训练过程中,期望每轮的训练数据中,Mask的位置也相应地发生变化,这就是Dynamic Masking,RoBERTa使用的就是Dynamic Masking。
在RoBERTa中,它具体是这么实现的,将原始的训练数据复制多份,然后进行Masking。这样相同的数据被随机Masking的位置也就发生了变化,相当于实现了Dynamic Masking的目的。例如原始数据共计复制了10份数据,共计需要训练40轮,则每种mask的方式在训练中会被使用4次。
2.2. Full-Sentences without NSP
BERT中在构造数据进行NSP任务的时候是这么做的,将两个segment进行拼接作为一串序列输入模型,然后使用NSP任务去预测这两个segment是否具有上下文的关系,但序列整体的长度小于512。
然而,RoBERTa通过实验发现,去掉NSP任务将会提升down-stream任务的指标,如图2所示。
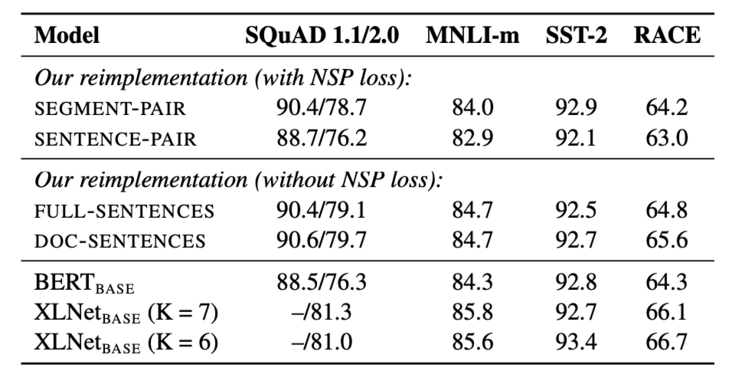
图2 NSP实验
其中,SEGMENT-PAIR、SENTENCE-PAIR、FULL-SENTENCES、DOC-SENTENCE分别表示不同的构造输入数据的方式,RoBERTa使用了FULL-SENTENCES,并且去掉了NSP任务。这里我们重点讨论一下FULL-SENTENCES输入方式,更多详情请参考RoBERTa。
FULL-SENTENCES表示从一篇文章或者多篇文章中连续抽取句子,填充到模型输入序列中。也就是说,一个输入序列有可能是跨越多个文章边界的。具体来讲,它会从一篇文章中连续地抽取句子填充输入序列,但是如果到了文章结尾,那么将会从下一个文章中继续抽取句子填充到该序列中,不同文章中的内容还是按照SEP分隔符进行分割。
2.3. Larger Batch Size
RoBERTa通过增加训练过程中Batch Size的大小,来观看模型的在预训练任务和down-stream任务上的表现。发现增加Batch Size有利于降低保留的训练数据的Perplexity,提高down-stream的指标。
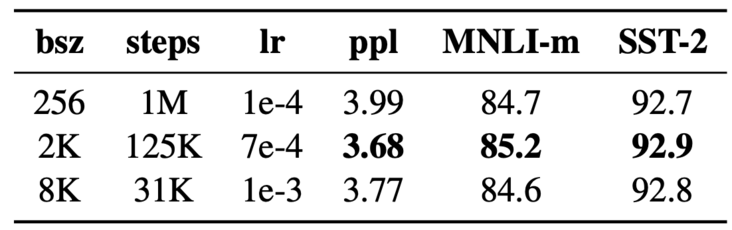
图3 batch size 实验
2.4. Byte-Level BPE
Byte-Pair Encodeing(BPE)是一种表示单词,生成词表的方式。BERT中的BPE算法是基于字符的BPE算法,由它构造的”单词”往往位于字符和单词之间,常见的形式就是单词中的片段作为一个独立的”单词”,特别是对于那些比较长的单词。比如单词woderful有可能会被拆分成两个子单词”wonder”和”ful”。
不同于BERT,RoBERTa使用了基于Byte的BPE,词表中共计包含50K左右的单词,这种方式的不需要担心未登录词的出现,因为它会从Byte的层面去分解单词。
2.5. More Data and More Training Steps
相比BERT, RoBERTa使用了更多的训练数据,详情如图4所示。

图4 RoBERTa预训练数据集
图5展示了RoBERTa随着训练数据增加和训练步数增加的实验效果,显然随着两者的增加,模型在down-stream的表现也不断提升。
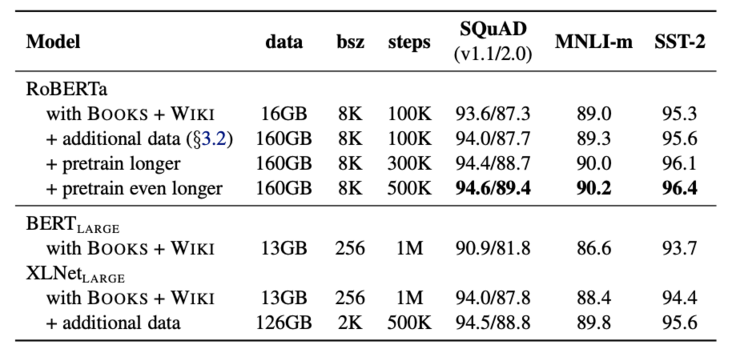
图5 增加数据和训练步数实验效果图
- 相关资料
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- RoBERTa Github
3.KBERT: Enabling Language Representation with Knowledge Graph
3.1. KBERT简介
当前的预训练模型(比如 BERT、GPT 等)往往在大规模的语料上进行预训练,学习丰富的语言知识,然后在下游的特定任务上进行微调。但这些模型基本都没有使用 知识图谱(KG) 这种结构化的知识,而 KG 本身能提供大量准确的知识信息,通过向预训练语言模型中引入这些外部知识可以帮助模型理解语言知识。基于这样的考虑,作者提出了一种向预训练模型中引入知识的方式,即 KBERT,其引入知识的时机是在 fine tune 阶段。在引入知识的同时,会存在以下两个问题:
- Heterogeneous Embedding Space (HES): 通俗来讲,及时文本的词向量表示和 KG 实体的表示是通过独立不相关的两种方式分别训练得到的,这造成了两种向量空间独立不相关。
- Knowledge Noise (KN):向原始的文本中引入太多知识有可能会造成歪曲原始文本的语义。
为了解决上边的两个问题,KBERT 采用了一种语句树的形式向原始文本序列中注入知识,并在预训练模型的表示空间中获取向量表示;另外其还使用了 soft-position 和 visible matrix 的方式解决了 KN 问题。
3.2. KBERT 的模型结构
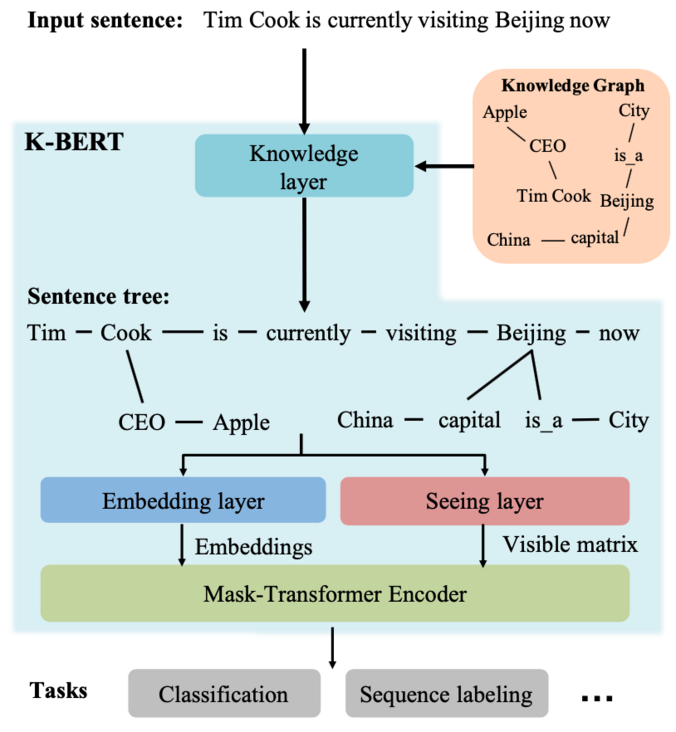
图 1 KBERT 的模型结构
图 1 展示了 KBERT 的模型结构,其中主要包含 4 个组件:Knowledge layer, Embedding layer, Seeing layer 和 Mask-Transformer Encoder。
对于输入的文本序列,KBERT 会根据序列中存在的实体,在 Knowledge Graph (KG) 中找到相应的 fact,例如 ,然后在 Knowledge layer 中进行融合,并输出相应的 Sentence tree。然后将其分别输入至 Embedding layer 和 Seeing layer 后分别得到 token 对应的 Embedding 和 Visible matrix, 最后将两者传入 Mask-Transformer Encoder 中进行计算,并获得相应的输出向量。这些输出向量接下来将被应用于下游任务,比如文本分类,序列标注等。
这是关于 KBERT 整个的处理流程,其中比较核心的,也就是预训练模型和知识图谱融合的地方在 Knowledge layer。下面我们来详细讨论 KBERT 模型的细节内容。
3.2.1 Knowledge layer: 构造 Sentence tree 融合 KG 知识
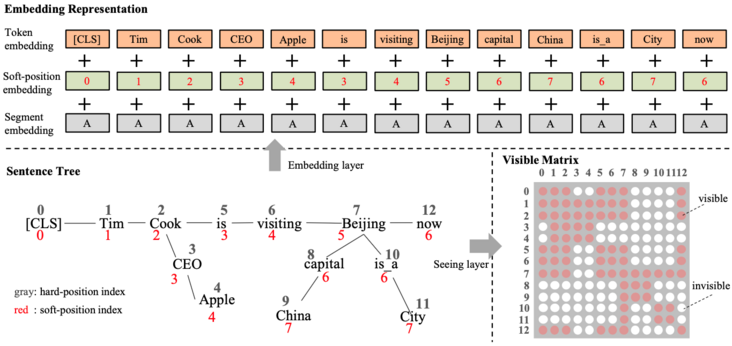
图 2 Sentence tree 转换成 Embedding 和 Visible matrix 的流程
图 2 展示了 KBERT 整体的从构造 Sentence tree 到生成相应的 Embedding 和 Visible Matrix 的过程。我们先来看 Sentence tree 生成这部分,其大致分为两个步骤:
- 找出文本序列中存在的实体,然后根据这些实体在 KG 中找出相应的事实三元组 (fact triples)。
- 将找出的三元组注入到原始的文本序列中,生成 Sentence tree。
给定一串文本序列 [CLS, Time, Cook, is, visiting, Beijing, now], 序列中存在两个实体:Cook 和 Beijing,这两个实体在 KG 中的 fact triples 分别是 、 和 ,最后将这些三元组注入到原始的文本序列中生成 Sentence Tree,如图 2 所示。
但这里需要注意的是,KBERT 采用的 BERT 作为模型骨架,BERT 的输入形式是一串文本序列,并不是上述的 Sentence tree 的形式,所以在实际输入的时候,我们需要对 Sentence tree 进行拉平,形成一串文本序列。这样的操作同时会带来一些问题:
- 直接拉平 Sentence tree 造成句子本身穿插 fact triples,破坏了句子本身的语义顺序和结构,造成信息的混乱。
- fact triples 的插入造成上述的 KN 问题,歪曲原始句子本身的语义信息。
基于这些考虑,KBERT 提出了 soft-position 和 visible matrix 两种技术解决这些问题。这些将会在以下两小节中进行展开讨论。
3.2.2 Embedding layer:引入 soft-position 保持语句本身的语序
从图 2 中可以看到,KBERT 在 Embedding 层延用了 BERT Embedding layer 各项相加的方式,共包含三部分数据:token embedding、position embedding 和 segment embedding。不过为了将 Sentence tree 拉平转换成一个文本序列输入给模型,KBERT 采用了一种 soft-position 位置编码的方式。
图 2 中红色的标记表示的就是 soft-position 的索引,黑色的表示的是拉平之后的绝对位置索引。在 Embedding 层使用的是 soft-position,从而保持原始句子的正常的语序。
3.2.3 Seeing layer: Mask 掉不可见的序列部分
Seeing layer 将产生一个 Visible Matrix,其将用来控制将 Sentence tree 拉平成序列后,序列中的词和词之间是否可见,从而保证想原始文本序列引入的 fact triples 不会歪曲原始句子的语义,即 KN 问题。
还是以图 2 展示的案例进行讨论,原始文本序列中的 Beijing 存在一个 triple ,将这 triple 引入到原始文本序列后在进行 Self-Attention 的时候,China 仅仅能够影响 Beijing 这个单词,而不能影响到其他单词(比如 Apple);另外 CLS 同样也不能越过 Cook 去获得 Apple 的信息,否则将会造成语义信息的混乱。因此在这种情况下,需要有一个 Visible Matrix 的矩阵用来控制 Sentence tree 拉平之后的各个 token 之间是否可见,互相之间不可见的 token 自然不会有影响。
如图 2 中展示的 Visible Matrix,给出了由 Sentence tree 拉平之后的序列 token 之间的可见关系。
3.2.4 Mask-Transformer: 使用拉平后融入 KG 知识的序列进行 transofmer 计算
由于 Visible Matrix 的引入,经典的 transofmer encoder 部分无法直接去计算,需要做些改变对序列之间的可见关系进行 mask, 这也是 Mask-Transfomer 名称的由来。详细公式如下:
$$begin{split} Q^{i+1}, K^{i+1}, V^{i+1} = h^iW_q, ; h^iW_k, ; h^iW_v S^{i+1} = softmax(frac{Q^{i+1}{K^{i+1}}^text{T} + M}{sqrt{d_k}}) h^{i+1} = S^{i+1}V^{i+1} end{split}$$
其中, $W_q$,$W_k$和 $W_v$是可训练的模型参数,$h_i$是第 $i$层 Mask-Transformer 的输出向量,$d_k$用于缩放计算的 Attention 权重,$M$是 Seeing layer 计算的 Visible Matrix,它将会使得那些不可见的 token 之间的 Self-Attention 权重置 0。
相关资料:
- KBERT: Enabling Language Representation with Knowledge Graph
- KBERT Github
4.ALBERT
谷歌的研究者设计了一个精简的BERT(A Lite BERT,ALBERT),参数量远远少于传统的 BERT 架构。BERT (Devlin et al., 2019) 的参数很多,模型很大,内存消耗很大,在分布式计算中的通信开销很大。但是 BERT 的高内存消耗边际收益并不高,如果继续增大 BERT-large 这种大模型的隐含层大小,模型效果不升反降。
启发于 mobilenet,ALBERT 通过两个参数削减技术克服了扩展预训练模型面临的主要障碍:
- 第一个技术是对嵌入参数化进行因式分解。大的词汇嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与嵌入层的分离开。这种分离使得隐藏层的增加更加容易,同时不显著增加词汇嵌入的参数量。(不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,先映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。)
- 第二种技术是跨层参数共享。这一技术可以避免参数量随着网络深度的增加而增加。
两种技术都显著降低了 BERT 的参数量,同时不对其性能造成明显影响,从而提升了参数效率。ALBERT 的配置类似于 BERT-large,但参数量仅为后者的 1/18,训练速度却是后者的 1.7 倍。
- 训练任务方面:提出了Sentence-order prediction (SOP)来取代NSP。具体来说,其正例与NSP相同,但负例是通过选择一篇文档中的两个连续的句子并将它们的顺序交换构造的。这样两个句子就会有相同的话题,模型学习到的就更多是句子间的连贯性。用于句子级别的预测(SOP)。SOP 主要聚焦于句间连贯,用于解决原版 BERT 中下一句预测(NSP)损失低效的问题。
4.1.ALBERT模型结构
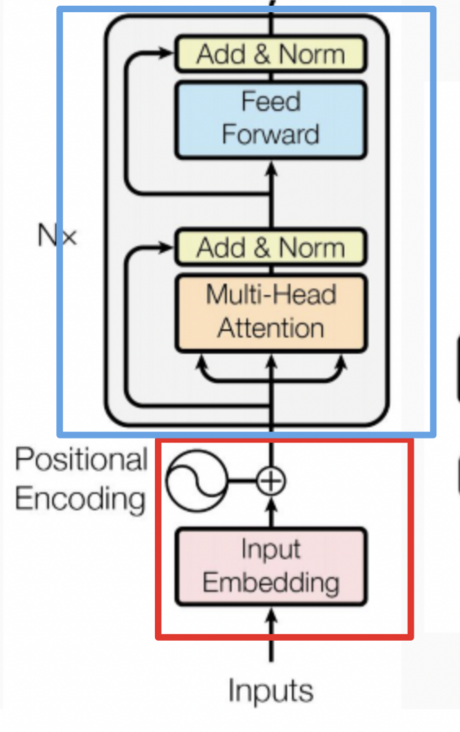
ALBERT 架构的主干和 BERT 类似,都使用了基于 GELU 的非线性激活函数的 Transformer。但是其分别在两个地方减少了参数量。
以下图为例可以看到模型的参数主要集中在两块,一块是 Token embedding projection block,另一块是 Attention feed-forward block,前者占有 20% 的参数量,后者占有 80% 的参数量。
4.1.1Factorized embedding parameterization
在 BERT 中,Token Embedding 的参数矩阵大小为$V times H$,其中V表示词汇的长度,H为隐藏层的大小。即:
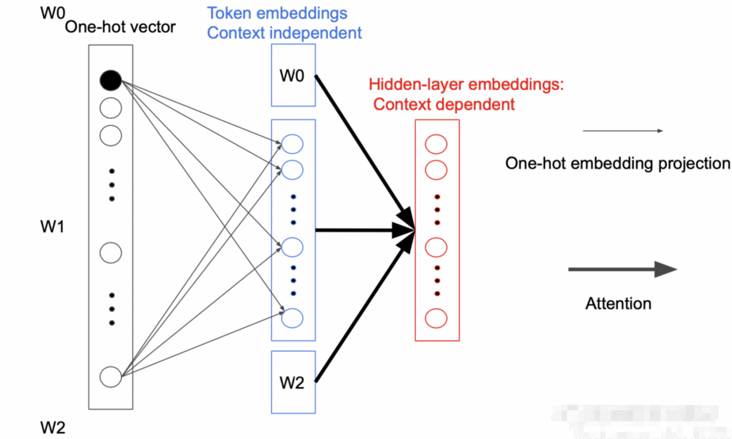
而 ALBERT 为了减少参数数量,在映射中间加入一个大小为E的隐藏层,这样矩阵的参数大小就从$O(V times H)$降低为$O(V times E + E times H)$,而$E ll H$
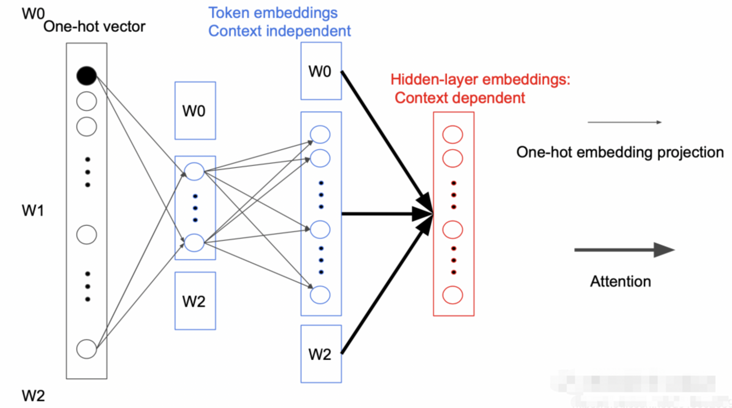
之所以可以这样做是因为每次反向传播时都只会更新一个 Token 相关参数,其他参数都不会变。而且在第一次投影的过程中,词与词之间是不会进行交互的,只有在后面的 Attention 过程中才会做交互,我们称为 Sparsely updated。如果词不做交互的话,完全没有必要用一个很高维度的向量去表示,所以就引入一个小的隐藏层。
4.1.2 Cross-layer parameter sharing
ALBERT 的参数共享主要是针对所有子模块内部进行的,这样便可以把 Attention feed-forward 模块参数量从 $O(12 times L times H times H)$ 降低到$12 times H times H$,其中L为层数,H为隐藏层的大小。
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。
ALBERT 之所以这样做是因为,考虑到每层其实学习到内容非常相似,所以尝试了将其进行参数共享。下图为不同层 Attention 学到的东西:
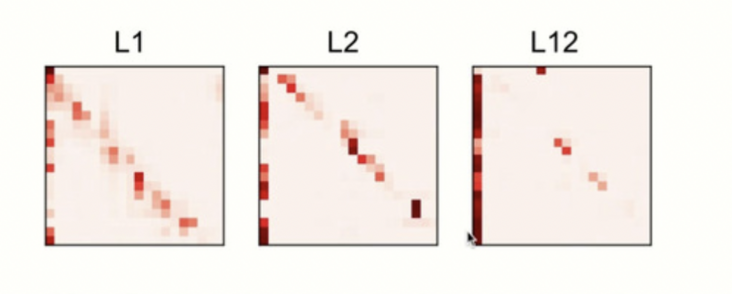
4.1.3 Sentence order prediction
谷歌自己把它换成了 SOP。这个在百度 ERNIE 2.0 里也有,叫 Sentence Reordering Task,而且 SRT 比 SOP 更强,因为需要预测更多种句子片段顺序排列。ERNIE 2.0 中还有一些别的东西可挖,比如大小写预测 Captialization Prediction Task、句子距离 Sentence Distance Task。
- NSP:下一句预测, 正样本=上下相邻的2个句子,负样本=随机2个句子
- SOP:句子顺序预测,正样本=正常顺序的2个相邻句子,负样本=调换顺序的2个相邻句子
- NOP任务过于简单,只要模型发现两个句子的主题不一样就行了,所以SOP预测任务能够让模型学习到更多的信息
SOP任务也很简单,它的正例和NSP任务一致(判断两句话是否有顺序关系),反例则是判断两句话是否为反序关系。
我们举个SOP例子:
正例:1.朱元璋建立的明朝。2.朱元璋处决了蓝玉。
反例:1.朱元璋处决了蓝玉。2.朱元璋建立的明朝。
BERT使用的NSP损失,是预测两个片段在原文本中是否连续出现的二分类损失。目标是为了提高如NLI等下游任务的性能,但是最近的研究都表示 NSP 的作用不可靠,都选择了不使用NSP。
作者推测,NSP效果不佳的原因是其难度较小。将主题预测和连贯性预测结合在了一起,但主题预测比连贯性预测简单得多,并且它与LM损失学到的内容是有重合的。
SOP的正例选取方式与BERT一致(来自同一文档的两个连续段),而负例不同于BERT中的sample,同样是来自同一文档的两个连续段,但交换两段的顺序,从而避免了主题预测,只关注建模句子之间的连贯性。
- 使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
- 避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
4.1.4 No Dropout
RoBERTA 指出 BERT 一系列模型都是” 欠拟合” 的,所以干脆直接关掉 dropout, 那么在 ALBERT 中也是去掉 Dropout 层可以显著减少临时变量对内存的占用。同时论文发现,Dropout 会损害大型 Transformer-based 模型的性能。
5.ELECTRA
掩码语言模型(masked langauge model, MLM),类似BERT通过预训练方法使用[MASK]来替换文本中一些字符,破坏了文本的原始输入,然后训练模型来重建原始文本。尽管它们在下游NLP任务中产生了良好的结果,但是它们通常需要大量计算才有效。作为替代方案,作者提出了一种更有效的预训练任务,称为Replaced Token Detection(RTD),字符替换探测。RTD方法不是掩盖输入,而是通过使用生成网络来生成一些合理替换字符来达到破坏输入的目的。然后,我们训练一个判别器模型,该模型可以预测当前字符是否被语言模型替换过。实验结果表明,这种新的预训练任务比MLM更有效,因为该任务是定义在所有文本输入上,而不是仅仅被掩盖的一小部分,在模型大小,数据和计算力相同的情况下,RTD方法所学习的上下文表示远远优于BERT所学习的上下文表示。
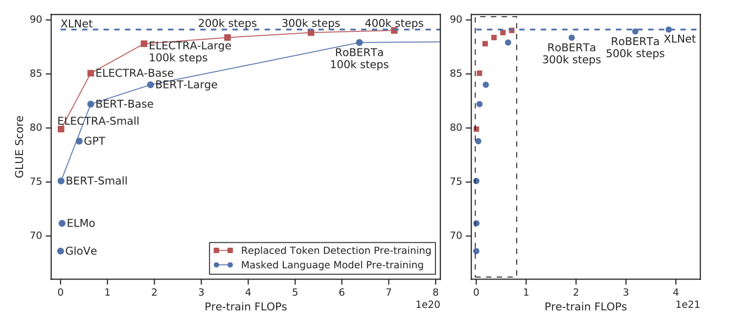
上图中,左边的图是右边的放大版,纵轴是dev GLUE分数,横轴是FLOPs(floating point operations),Tensorflow中提供的浮点数计算量统计。从上图可以看到,同量级的ELECTRA是一直碾压BERT,而且在训练更长的步长步数,达到了当时的SOTA模型RoBERTa的效果。从左边的曲线图上可以看到,ELECTRA效果还有继续上升的空间。
5.1 ELECTRA模型结构
ELECTRA最大的贡献是提出了新的预训练任务和框架,在上述简介中也提到了。将生成式的MLM预训练任务改成了判别式的RTD任务,再判断当前token是否被替换过。那么问题来了,假设,我随机替换一些输入中的字词,再让BERT去预测是否替换过,这样可行吗?有一些人做过实验,但效果并不太好,因为随机替换太简单了。
作者使用一个MLM的G-BERT来对输入句子进行改造,然后丢给D-BERT去判断哪个字被修改过,如下:
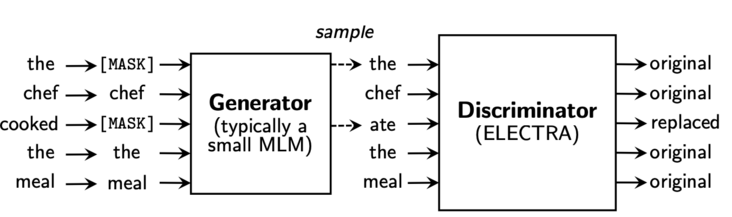
5.1.1 Replaced Token Detection
但上述结构有个问题,输入句子经过生成器,输出改写过的句子,因为句子的字词是离散的,所以梯度无法反向传播,判别器的梯度无法传给生成器,于是生成器的目标还是MLM,判别器的目标是序列标注(判断每个字符是真是假),两者同时训练,但是判别器的梯度不会传给生成器,目标函数如下:
$$min_{theta_{G},theta_{D}} sum_{x in X} L_{MLM}(x,theta_{G})+lambda L_{Disc}(x,theta_{D})$$
因为判别器的任务相对来说简单些,RTD损失相对MLM损失会很小,因此加上一个系数,论文中使用了50。经过预训练,在下游任务的使用中,作者直接给出生成器,在判别器进行微调。
另外,在优化判别器时计算了所有token上的损失,而以往计算BERT的MLM loss时会忽略没被mask的token。作者在后来的实验中也验证了在所有token上进行损失计算会提升效率和效果。
事实上,ELECTRA使用的生成-判别架构与GAN还是有不少差别,作者列出了如下几点:
| ELECTRA | GAN | |
|---|---|---|
| 输入 | 真是文本 | 随机噪声 |
| 目标 | 生成器学习语言模型,判别器学习区分真假文本 | 生成器尽可能欺骗判别器,判别器尽量区分真假图片 |
| 反向传播 | 梯度无法从D传到G | 梯度可以从D传到G |
| 特殊情况 | 生成出了真实文本,则标记为正例 | 生成的都是负例(假图片) |
5.1.2 权重共享
生成器和判别器权重共享是否可以提升效果呢?作者设置了同样大小的生成器和判别器。在不共享权重下的效果为83.6,只共享token embedding层的效果是84.3,共享所有权重的效果是84.4。作者认为生成器对embedding 有更好的学习能力,这是由于判别器只更新由生成器采样生成的token,而softmax是建立在所有vocab上的,之后反向传播时生成器会更新所有的embedding,最后作者只使用了embedding sharing。
5.1.3 更小的生成器
从权重共享的实验中看到,生成器和判别器只需要共享embedding 的权重就足够了。那这样的话是否可以缩小生成器的尺寸进行训练效率的提升呢?作者在保持原有的hidden size的设置下减少了层数,得到了下图所示的关系图:
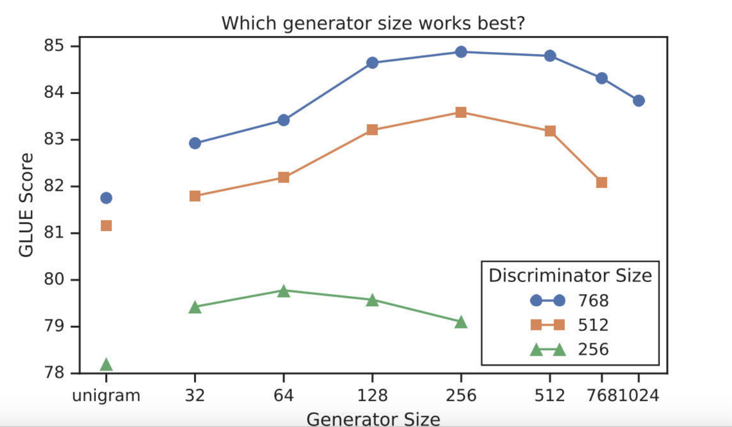
可以看到,生成器的大小在判别器的1/4到1/2之间的效果是最好的。作者认为原因是过强的生成器会增加判别器的难度。
5.2.训练策略
除了MLM损失,作者也尝试了另外两种训练策略:
- Adversarial Contrastive Estimation:ELECTRA因为上述一些问题无法使用GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化MLM损失换成了最大化判别器在被替换token上RTD损失。但还有一个问题,就是新的生成器无法用梯度上升更新生成器,于是作者使用强化学习Policy Gradient思想,最终优化下来生成器在MLM 任务上可以达到54%的准确率,而之前MLE优化下可达到65%。
- Two-stage training:即先训练生成器,然后freeze掉,用生成器的权重初始化判别器,再接着训练相同步数的判别器。
对比三种训练策略,得到下图:
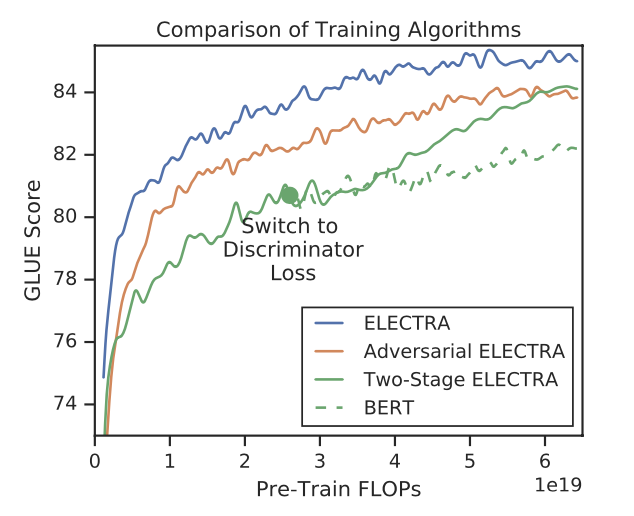
可见“隔离式”的训练策略效果还是最好的,而两段式的训练弱一些,作者猜测是生成器太强了导致判别任务难度增大。不过两段式最终效果也比BERT本身要强,进一步证明了判别式预训练的效果。
5.3.仿真实验
作者的目的是提升预训练效率,于是做了GPU单卡就可以训练ELECTRA-Small和BERT-Small,接着和层数不变的ELMo、GPT等进行对比。结果如下:

表现十分亮眼,仅用14M参数数量,以前13%的体积,在提升训练速度的同时还提升了效果。
大ELECTRA模型的各项表现如下:
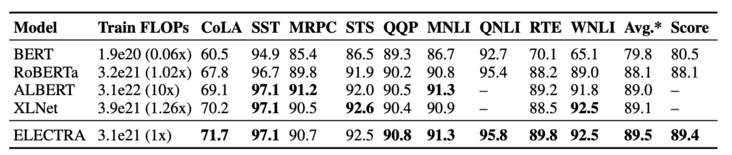
上面是各个模型在GLUE dev/text上的表现,可以看到ELECTRA仅用了1/4的计算量就达到了RoBERTa的效果。而且作者使用的是XLNet的语料,大约是126G,但RoBERTa用了160G。由于时间和精力问题,作者没有把ELECTRA训练更久(应该会有提升),也没有使用各种Trick。
5.4 结果分析
BERT的loss只计算被替换的15%个token,而ELECTRA是全部都计算,所以作者又做了几个对比实验,探究哪种方式更好一些:
- ELECTRA 15%:让判别器只计算15% token上的损失;
- Replace MLM:训练BERT MLM,输入不用[MASK]进行替换,而是其他生成器。这样可以消除pretrain-finetune之间的差别;
- All-Tokens MLM :接着用Replace MLM,只不过BERT的目标函数变为预测所有的token,比较接近ELECTRA。
| Model | ELECTRA | All-Tokens MLM | Replace MLM | ELECTRA 15% | BERT |
|---|---|---|---|---|---|
| GLUE score | 85.0 | 84.3 | 82.4 | 82.4 | 82.2 |
对比ELECTRA和ECLECTRA15%:在所有token上计算loss确实能提升效果;对比Replace MLM 和BERT:[MASK]标志确实会对BERT产生影响,而且BERT目前还有一个trick,就是被替换的10%情况下使用原token或其他token,如果没有这个trick估计效果会差一些;对比All-Tokens MLM和BERT:如果BERT预测所有token的话,效果会接近ELECTRA。
作者还发现,ELECTRA体积越小,相比于BERT就提升的越明显,说明fully trained的ELECTRA效果会更好。另外作者推断,由于ELECTRA是判别式任务,不用对整个数据分布建模,所以更parameter-efficient。
5.5 小结结
BERT虽然对上下文有很强的编码能力,却缺乏细粒度语义的表示。下图可以明显体现出上述问题:
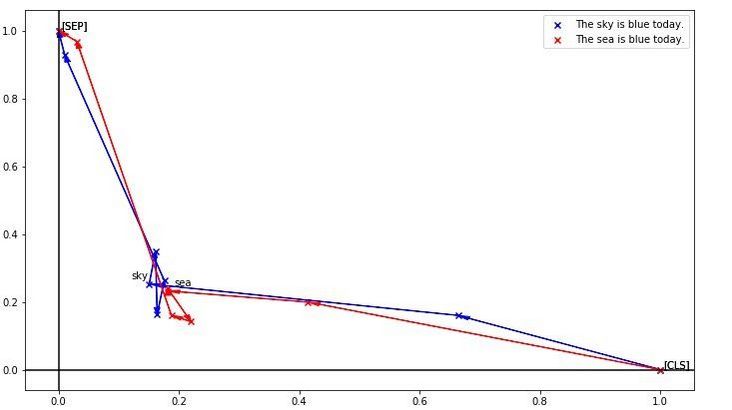
这是把token编码降维后的效果,可以看到sky和sea,明明是天与海的区别,却因为上下文一样而得到了极为相似的编码。细粒度表示能力的缺失会对真实任务造成很大影响,如果被针对性攻击的话更是无力,所以当时就想办法加上更细粒度的任务让BERT去区分每个token,不过同句内随机替换的效果并不好, 需要进一步挖掘。
ELECTRA的RTD任务比MLM的预训练任务好,推出了一种十分适用于NLP的类GAN框架,不再像之前的BERT+模型一样,可以用“more data+parameters+steps+GPU+MONEY”简单概括。
- 参考文献
Electra: Pre-training text encoders as discriminators rather than generators
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
前言 今天要给大家推荐一款由新生命开发团队开源的.NET轻量级分布式服务框架:星尘分布式平台(NewLife.Stardust)。 项目介绍 星尘是一个轻量级分布式服务框架。它的功能包含配置中心、集群管理、远程自动发布、服务治理、服务自动注册和发现、负载均衡、…
