
树状数组
TODO:
前言
在阅读本文之前,您可能需要先了解位运算、二叉树以及前缀和与差分等相关知识
本文中,若无特殊说明,数列下标均从 (1) 开始
引入
什么是树状数组
树状数组是一种 通过数组来模拟”树形”结构,支持单点修改和区间查询的数据结构
因为它是通过二进制的性质构成的,所以它又被叫做 二进制索引树((Binary Indexed Tree)),也被称作 (FenWick Tree)
用于解决什么问题
树状数组常用于动态维护区间信息
例题
P3374 【模板】树状数组 1 – 洛谷
题目简述:对数列进行单点修改以及区间求和
常规解法
单点修改的时间复杂度为 (O(1))
区间求和的时间复杂度为 (O(n))
共 (m) 次操作,则总时间复杂度为 (O(ntimes m))
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
public static void main(String[] args) throws IOException {
PrintWriter out = new PrintWriter(System.out);
int n = get(), m = get();
int[] a = new int[n];
for (int i = 0; i 前缀和解法
区间求和通过前缀和优化,但单点修改的时候需要修改前缀和数组
单点修改的时间复杂度为 (O(n))
区间求和的时间复杂度为 (O(1))
共 (m) 次操作,则总时间复杂度为 (O(ntimes m))
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
public static void main(String[] args) throws IOException {
PrintWriter out = new PrintWriter(System.out);
int n = get(), m = get();
int[] sum = new int[n + 1];
for (int i = 1; i 树状数组解法
可以发现上述两种方法,不是单点修改的时间复杂度过高,就是区间求和的时间复杂度过高,导致最坏时间复杂度很高。
于是,树状数组出现了,它用来平衡这两种操作的时间复杂度。
树状数组的思想
每个正整数都可以表示为若干个 (2) 的幂次之和(二进制基本原理)
类似的,每次求前缀和,我们也希望将区间 ([1,i]) 分解成 (log_2 i) 个子集的和
也就是如果 (i) 的二进制表示中如果有 (k) 个 (1),我们就希望将其分解为 (k) 个子集之和
树状数组的树形态与二叉树
每一个矩形代表树的一个节点,矩形大小表示所管辖的数列区间范围
一颗二叉树的形态如下图所示
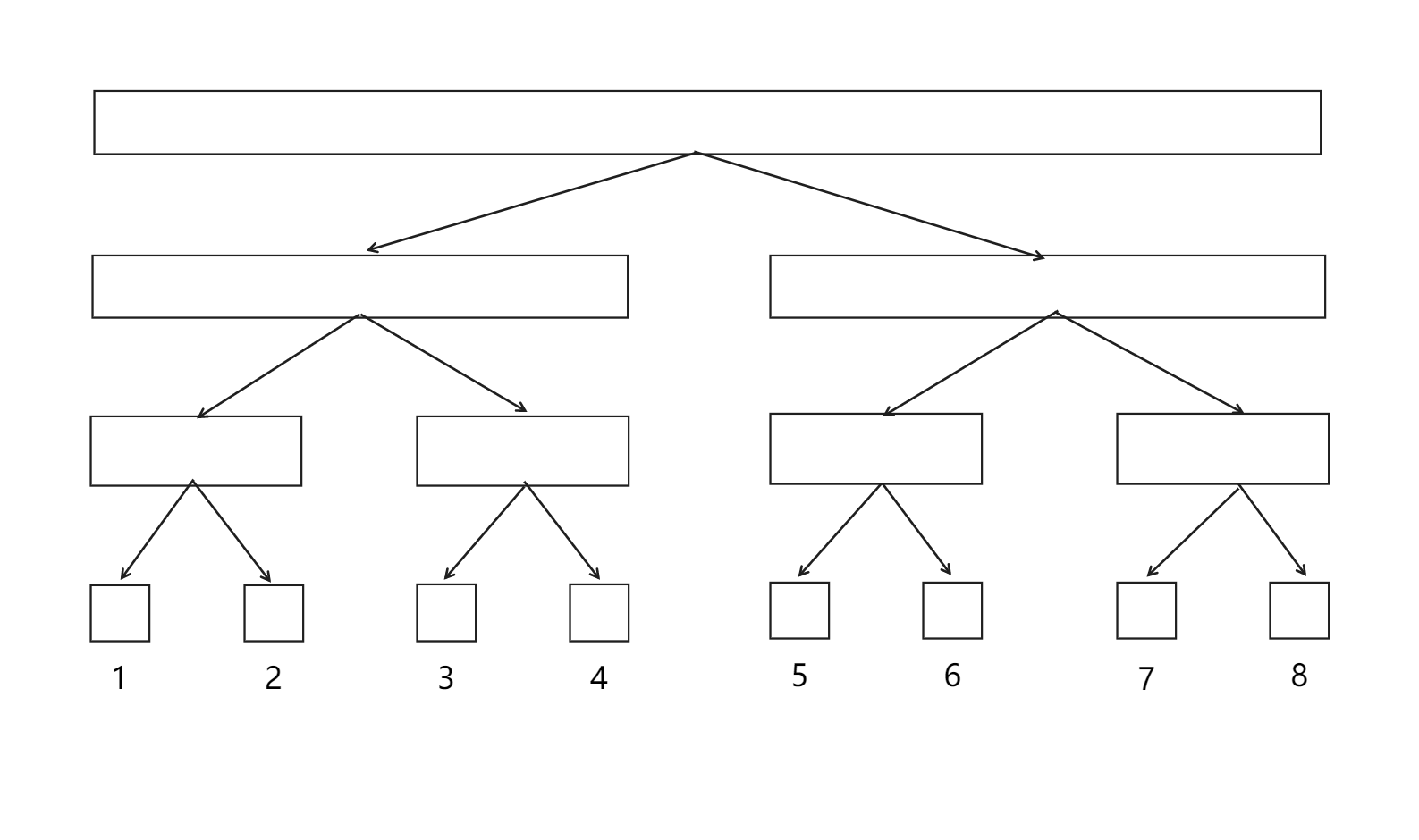
我们发现,对于具有逆运算的运算,如求和运算,有如下式子
sum(k+1,r)=sum(l,r)-sum(l,k)
]
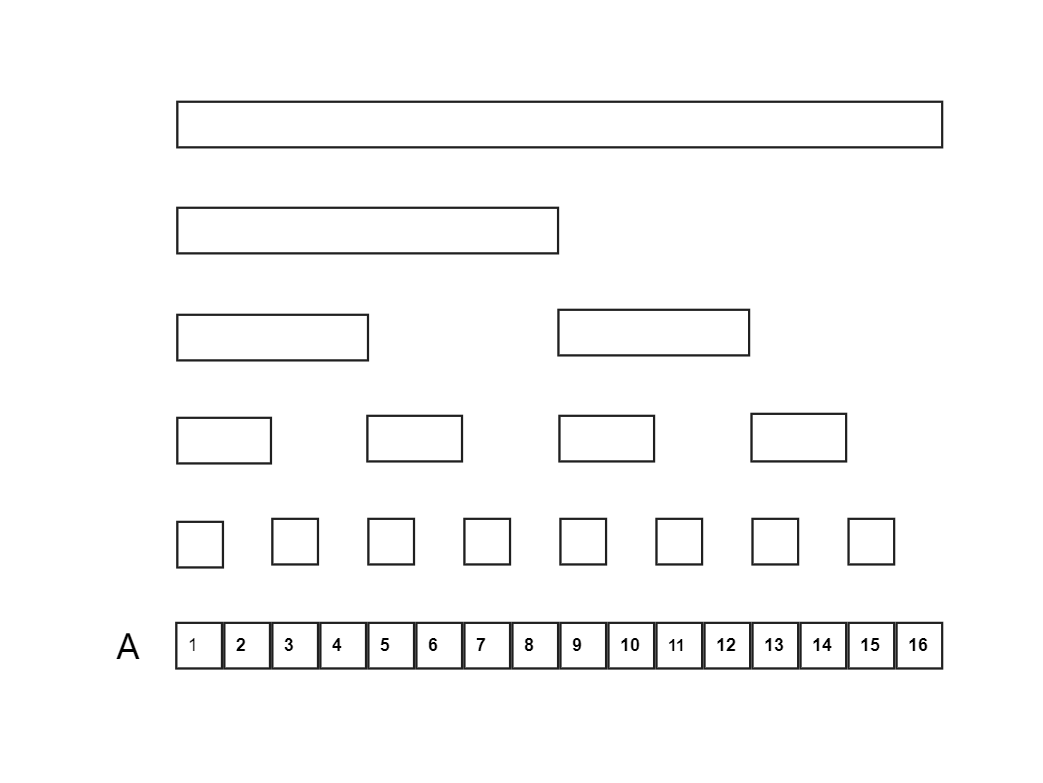
实际上,许多数据可以通过一些节点的差集获得
因此,上述二叉树的一些节点可以进行删除
树状数组的形态如下图所示
管辖区间
对于下图中的树状数组(黑色数字代表原始数组 (A_i) 红色数字代表树状数组中的每个节点数据 (C_i))
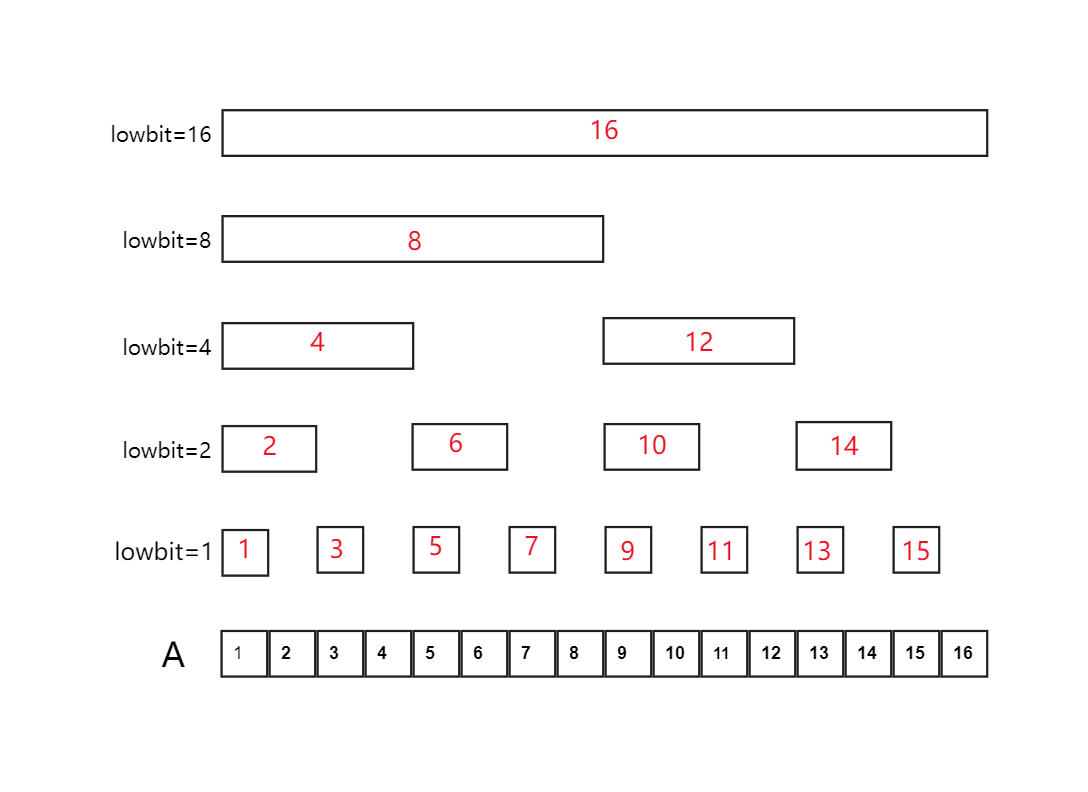
从图中可以看出:
| 树状数组 | 管辖区间 |
|---|---|
| (C_1) | (A[1dots1]) |
| (C_2) | (A[1dots2]) |
| (C_3) | (A[3dots3]) |
| (C_4) | (A[1dots4]) |
| (C_5) | (A[5dots5]) |
| (C_6) | (A[5dots6]) |
| (C_7) | (A[7dots7]) |
| (C_8) | (A[1dots8]) |
那么如何通过计算机确定 (C_x) 的管辖区间呢?
前面提到过树状数组的思想是基于二进制的
树状数组中,规定 (C_x) 所管辖的区间长度为 (2^k),其中:
- 设二进制最低位为第 (0) 位,则 (k) 恰好为 (x) 的二进制表示中,最低位的 (1) 所在的二进制位数;
- (2^k)((C_x) 的管辖区间长度)恰好为 (x) 二进制表示中,最低位的 (1) 以及后面所有 (0) 组成的数。
以 (C_{88}) 所管辖的区间为例
因为 ((88)_{10}=(1011000)_2),其二进制最低位的 (1) 及后面的 (0) 组成的二进制是 ((1000)_2=(8)_{10}),所以,(C_{88}) 管理 (8) 个 (A) 数组中的元素。
因此,(C_{88}) 代表 (A[81dots88]) 的区间信息。
我们记 (x) 二进制最低位 (1) 以及后面的 (0) 组成的数为 (lowbit(x)),则 (C_x) 管辖的区间就是 (A[x-lowbit(x)+1,x])
其中 lowbit(x) = x & (~x + 1) = x & -x
树状数组树的性质
性质比较多,下面列出重要的几个性质,更多性质请参见OI Wiki,下面表述忽略二进制前导零
-
节点 (u) 的父节点为 (u+lowbit(u))
-
设节点 (u=stimes 2^{k+1}+2^k),则其儿子数量为 (k=log_2lowbit(u))(即 (u) 的二进制表示中尾随 (0) 的个数),这 (k) 个儿子的编号分别为 (u-2^t(0le t
如 (k=3),(u) 的二进制表示为
1000,则 (u) 有三个儿子,这三个儿子的二进制编号分别为111、110、100 -
节点 (u) 的所有儿子对应 (C_u) 的管辖区间恰好拼接成 ([lowbit(u),u-1])
-
如 (k=3),(u) 的二进制表示为
1000,(u) 的三个儿子的二进制编号分别为111、110、100C[100]表示A[001~100],C[110]表示A[101~110],C[111]表示A[111~111]上述三个儿子管辖区间的并集恰好是
A[001~111],即 ([lowbit(u),u-1])
-
单点修改
根据管辖区间,逐层维护管辖区间包含这个节点的父节点(节点 (u) 的父节点为 (u+lowbit(u)))
void add(int x, int val) { // A[x] 加上 val
for (; x 区间查询
区间查询问题可以转化为前缀查询问题(前缀和思想),也就是查询区间 ([l,r]) 的和,可以转化为 (A[1dots r])与(A[1dots l-1])的差集
如计算 (A[4dots7]) 的值,可以转化为求 (A[1dots7]) 和 (A[1dots3]) 再相减
前缀查询的过程是:根据管辖区间,不断拆分区间,查找上一个前缀区间
对于 (A[1dots x]) 的前缀查询过程如下:
- 从 (x) 开始向前拆分,有 (C_x) 管辖 (A[x-lowbit(x)+1dots x])
- 令 (xgets x-lowbit(x))
- 重复上述过程,直至 (x=0)
由于 (x-lowbit(x)) 的算术意义是去除二进制最后一个 (1),因此也可以写为 (x&(x-1))
// 查询前缀 A[1...x] 的和
int getSum(int x) {
int ans = 0;
for (; x != 0; x &= x - 1) ans += C[x];
//for (; x != 0; x -= x & -x) ans += C[x];
return ans;
}
// 查询区间 A[l...r] 的和
int queryRange(int l, int r) {
return getSum(r) - getSum(l - 1);
}
上述过程进行了两次前缀查询,实际上,对于 (l-1) 和 (r) 的前缀区间是相同的,我们不需要计算
// 查询区间 A[l...r] 的和
int queryRange(int l, int r) {
// return getSum(r) - getSum(l - 1);
int ans = 0;
--l;
while (l 单点查询
单点查询可以转化为区间查询,需要两次前缀查询,但有更好的方法
(x) 所管辖的区间为 (C_x=A[x-lowbit(x)+1dots x]),而节点 (x) 的所有子节点的并集恰好为 (A[x-lowbit(x)+1dots x-1])
则 (A[x]=C_x-A[x-lowbit(x)+1dots x-1])
对于 (A[x]) 的更好的查询过程如下:
- 查询 (x) 所管辖的区间 (C_x)
- 减去 (x) 的所有子节点的数据
//int queryOne(int x) {
// return queryRange(x, x);
//}
int queryOne(int x) {
int ans = c[x];
int lca = x & x - 1; // x - lowbit(x)
for (int i = x - 1; i > lca; i &= i - 1) {
ans -= C[i];
}
return ans;
}
建树
可以通过调用单调修改方法进行建树,时间复杂度 (O(nlog n))
时间复杂度为 (O(n)) 的建树方法有如下两种:
方法一:
每一个节点的值是由所有与自己直接相连的儿子的值求和得到的。因此可以倒着考虑贡献,即每次确定完儿子的值后,用自己的值更新自己的直接父亲。
void init() {
for (int i = 1; i 方法二:
由于 (C_x) 所管辖的区间是 ([x-lowbit(x)+1,x]),则可以预处理 (sum) 前缀和数组,再通过 (sum[x]-sum[x-lowbit(x)]) 计算 (C_x)
我们也可以先用 (C) 数组计算前缀和,再倒着计算 (C_x)(因为正着计算会导致前面的值被修改,与 (01) 背包优化相同)
同样的 (x-lowbit(x)) 可以写为 (x&(x-1))
void init() {
for (int i = 1; i 0; --i) {
C[i] -= C[i & i - 1];
}
}
复杂度分析
空间复杂度为 (O(n))
单点修改、单点查询、区间查询操作的时间复杂度均为 (O(log{n}))
建树的时间复杂度为 (O(nlog n)) 或 (O(n))
Code
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
static int n;
static int[] c, a;
static void add(int x, int val) {
for (; x lca; i &= i - 1) {
ans -= c[i];
}
return ans;
}
static int queryRange(int l, int r) {
int ans = 0;
--l;
while (l 要点总结
-
注意树状数组的树型特征
-
(x) 的管辖元素个数为(lowbit(x)),管辖区间为 ([x-lowbit(x)+1,x])
-
树状数组中,(x) 的父节点编号为 (x+lowbit(x))
-
树状数组的二叉查找树中,(x) 的父节点(也即前缀区间)编号为 (x-lowbit(x))
-
树状数组是一个维护前缀信息的树型数据结构
-
树状数组维护的信息需要满足结合律以及可差分(因为一些数据需要通过其他数据的差集获得)两个性质,如加法,乘法,异或等
结合律:((xcirc y)circ z=xcirc(ycirc z)),其中 (circ) 是一个二元运算符。
可差分:具有逆运算的运算,即已知 (xcirc y) 和 (x) 可以求出 (y)
-
有时树状数组在其他辅助数组(如差分数组)的帮助下,可以解决更多的问题
-
由于树状数组需要逆运算抵消掉原运算(如加和减),而线段树只需要逐层拆分区间,在合并区间信息,并不需要抵消部分数值,所以说树状数组能解决的问题是线段树能解决的问题的子集
-
树状数组下标也可以从 (0) 开始,此时 (x) 的父节点编号为 (x|(x+1)),(x) 的管辖元素个数为 (x-(x&(x+1))+1),管辖区间为 ([x&(x+1),x])
树状数组封装类
一个 (Java) 的树状数组封装类
class BIT {
int n;
int[] c;
// 请保证 a 的数据从下标 1 开始
public void init(int[] a) {
// assert(a.length > n);
for (int i = 1; i n) return;
for (; i lca; j &= j - 1) {
ans -= c[j];
}
return ans;
}
public int range(int l, int r) {
int ans = 0;
--l;
while (l 进阶
区间修改+单点查询
P3368 【模板】树状数组 2 – 洛谷
一些操作映射到前缀数组或者差分数组上可能会变得很简单
考虑序列 (a) 的差分数组 (d),其中 (d_i=a_i-a_{i-1})。
则对于序列 (a) 的区间 ([l,r]) 加 (value) 可以转化为 (d_l+value) 和 (d_{r+1}-value),也就是差分数组上的两次单点操作。
因此 (a_x=sum_{i=1}^xd_i) 选择通过树状数组维护差分数组
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
static int n;
static int[] d, a;
static void add(int x, int val) {
for (; x 区间修改+区间查询
P3372 【模板】线段树 1 – 洛谷
对于区间查询 (a[ldots r]),同样选择转化为前缀查询 (a[1dots r]) 及 (a[1dots l-1]) 的差集
考虑序列 (a) 的差分数组 (d),其中 (d_i=a_i-a_{i-1})。由于差分数组的前缀和就是原数组,则 (a_i=sum_{j=1}^id_j)
所以,前缀查询变为 (sum_{i=1}^x a_i=sum_{i=1}^x sum_{j=1}^id_j)
上式可表述为下图蓝色部分面积
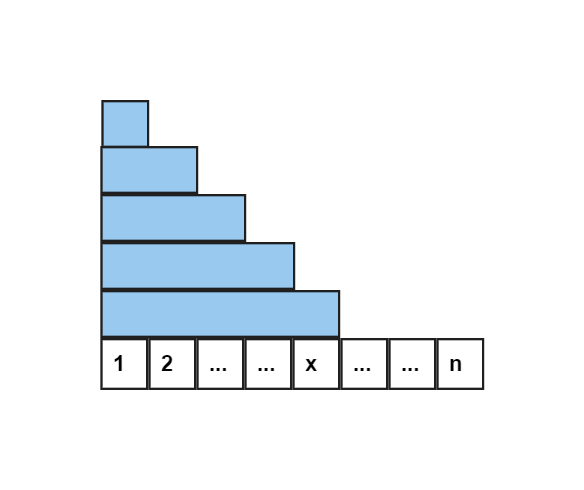
横着看看不出什么,但竖着看会发现每个数据加的个数与 (x) 有关
(d_x) 会加 (1) 次,(d_{x-1}) 会加 (2) 次,(dots) ,(d_2) 会加 (x-1) 次,(d_1) 会加 (x) 次
也就是 (d_i) 会加 (x-i+1),加法转化为乘法可得
sum_{i=1}^x a_i&=sum_{i=1}^x sum_{j=1}^id_j\
&=sum_{i=1}^{x}d_itimes(x-i+1)\
&=sum_{i=1}^xd_itimes(x+1)-sum_{i=1}^{x}d_itimes i\
&=(x+1)timessum_{i=1}^xd_i-sum_{i=1}^{x}d_itimes i
end{aligned}
]
又因为 (sum_{i=1}^xd_i) 与 (sum_{i=1}^{x}d_itimes i) 不能推导推导出另一个
因此需要用两个树状数组分别维护 (d_i) 与 (d_itimes i)
-
用于维护 (d_i) 的树状数组,对于每次对 ([l,r]) 加 (k) 转化为 (d[l]+k) 与 (d[r+1]-k)
-
用于维护 (d_itimes i) 的树状数组,对于每次对 ([l,r]) 加 (k) 转化为
((d[l]+k)times l=d[l]times l+ltimes k) 与
((d[r+1]-k)times (r+1)=d[r+1]times (r+1)-(r+1)times k)
即在原来的基础上加上 (ltimes k) 与减去 ((r+1)times k)
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
public static void main(String[] args) throws IOException {
PrintWriter out = new PrintWriter(System.out);
int n = get(), m = get();
int[] a = new int[n + 1];
for (int i = 1; i n);
for (int i = 1; i n) return;
for (; i lca; j &= j - 1) {
ans -= c[j];
}
return ans;
}
public long range(int l, int r) {
long ans = 0;
--l;
while (l 也可以写成封装类的形式
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
public static void main(String[] args) throws IOException {
PrintWriter out = new PrintWriter(System.out);
int n = get(), m = get();
int[] a = new int[n + 1];
for (int i = 1; i n);
for (int i = 1; i n) return;
for (; i lca; j &= j - 1) {
ans -= c[j];
}
return ans;
}
public long range(int l, int r) {
long ans = 0;
--l;
while (l 题目
P4939 Agent2 – 洛谷
题目链接
题意简述:有两个操作
- 对区间 ([l,r]) 的数均加 (1)
- 查询第 (x) 个数的值
进阶中的 区间修改+单点查询
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
static int n;
static int[] d;
static void add(int x, int val) {
for (; x P5057 简单题 – 洛谷
题目链接
题目简述:有两个操作
- 对区间 ([l,r]) 的数进行反转(1变0,0变1)
- 单点查询
反转等同于与 (1) 异或,于是题目变成了维护区间异或和单点查询,同样选择差分序列,只不过是异或的差分。
而异或也满足树状数组的两个要求,因此使用树状数组解决该题
import java.io.*;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
static int n, m;
static int[] c;
static void change(int x) {
for (; x P1908 逆序对 – 洛谷
题目链接
题意简述:求数组中的逆序对
求解逆序对可以用归并排序求解,此处不做讨论
从前向后遍历数组,同时将其加入到桶中,记录每个数出现的个数,并加上该位置之前且比当前数大的数的个数(有点绕,看例子可能会清晰点)
桶:用 (cnt[i]) 表示目前 (i) 出现的个数,初始化均为 (0)
(ans):表示目前逆序对的个数,初始化为 (0)
数组: 1 3 5 4 2 1 桶的下标: 0 1 2 3 4 5 6
一: 加入 1 到桶中 ans+=cnt[2...max] ans=0 桶: 0 1 0 0 0 0 0
二: 加入 3 到桶中 ans+=cnt[4...max] ans=0 桶: 0 1 0 1 0 0 0
三: 加入 5 到桶中 ans+=cnt[6...max] ans=0 桶: 0 1 0 1 0 1 0
四: 加入 4 到桶中 ans+=cnt[5...max] ans=1 桶: 0 1 0 1 1 1 0
五: 加入 2 到桶中 ans+=cnt[3...max] ans=4 桶: 0 1 1 1 1 1 0
六: 加入 1 到桶中 ans+=cnt[2...max] ans=8 桶: 0 2 1 1 1 1 0
也就是需要求 (i) 时刻,桶中 ([a_i+1,max]) 的和,其中 (max) 为所有数据中的最大值
也即实现 单点加 与 区间查询,使用树状数组求解
但是题目中 (maxle 10^9),树状数组的长度开不了那么大
可以发现,该题中我们只关心数据间的相对大小关系,而不关心数据本身大小,采用离散化的方式,将数据缩小(一种映射关系)
举个例子:
原数据: 1 100 200 500 50
新数据: 1 3 4 5 2
这样最大的数据就缩小到了 5
代码如下:
import java.io.*;
import java.util.Arrays;
public class Main {
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws IOException {
in.nextToken();
return (int) in.nval;
}
static int n;
static int[] d;
static void add(int x, int val) {
for (; x 参考资料
树状数组 – OI Wiki
