
访问【WRITE-BUG数字空间】_[内附完整源码和文档]至此“淘宝双 11 数据分析与预测课程案例”所需要的环境配置完成。另外实际操作中发现在案例教程中存在一些小问题,比如教程中 Eclipse 版本为 3.8,但是在配置 Tomcat Server 时又要求配置 v8.0 版本,然而 3.8 版本的 Eclipse 最多仅支持到 v7.0 版本的 Tomcat,所以实际操作时使用了更新的 Eclipse 版本。一、运行环境实际配置环境结合了实际情况,没有和实验案例完全一致,不过整个功能正常实现。实际运行环境及版本如下所示。Linux:
Ubuntu14.04
JDK:
Openjdk-1.7.0_181
Hadoop: 2.7.6
MySQL: 5.7.24
Hive: 1.2.2
Sqoop: 1.4.7
Spark: 2.1.0
Eclipse: 4.5.0
Echarts: 3.8.4
配置过程中截图如下所示,由于步骤较多,仅截取部分关键步骤。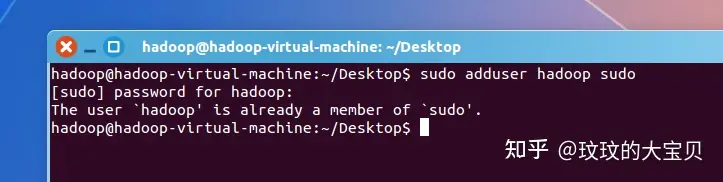
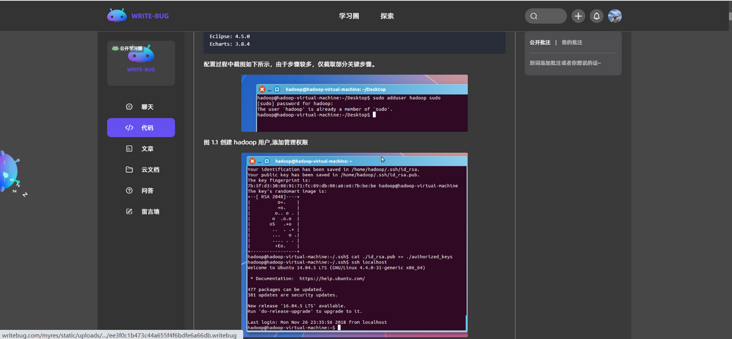
图 1.1 创建 hadoop 用户,添加管理权限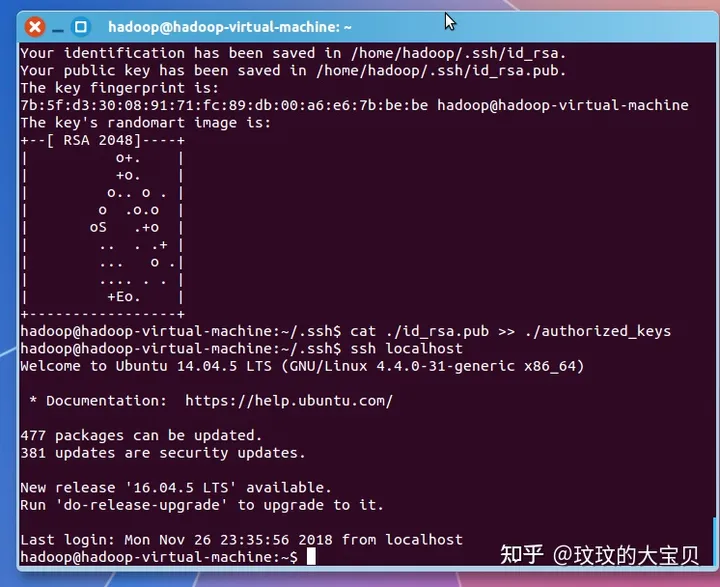
图 1.2 安装配置 SSH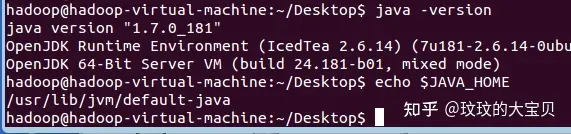
图 1.3 配置 Java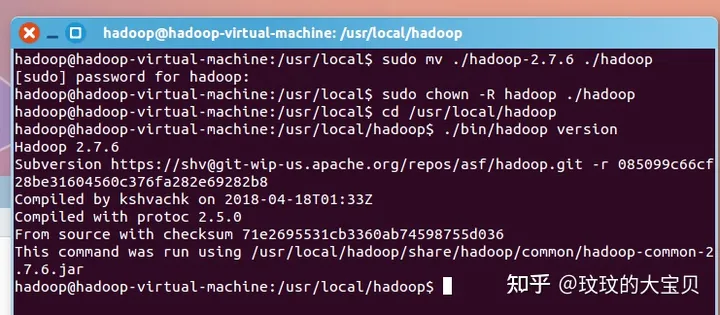
图 1.4 配置 Hadoop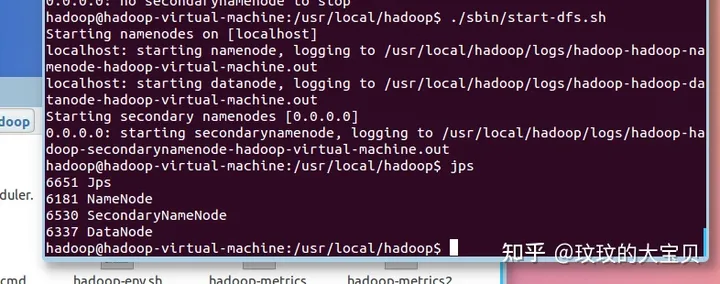
图 1.5 运行 Hadoop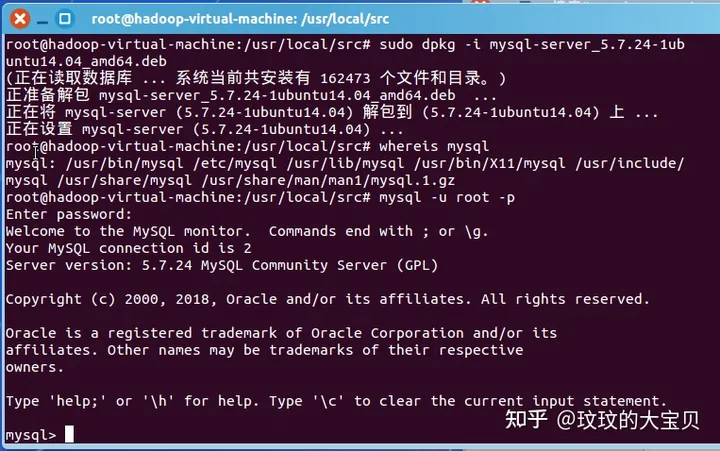
图 1.6 配置运行 MySQL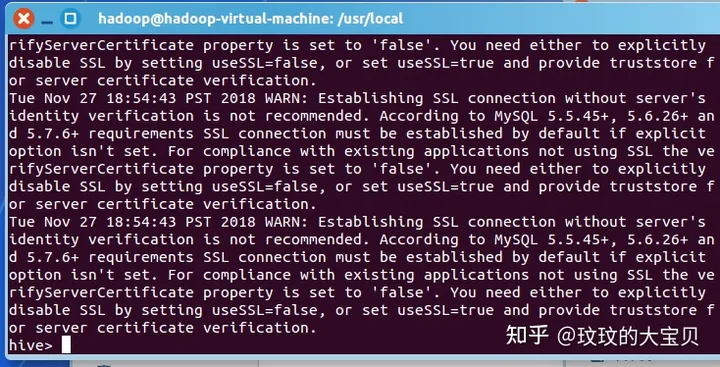
图 1.7 配置运行 Hive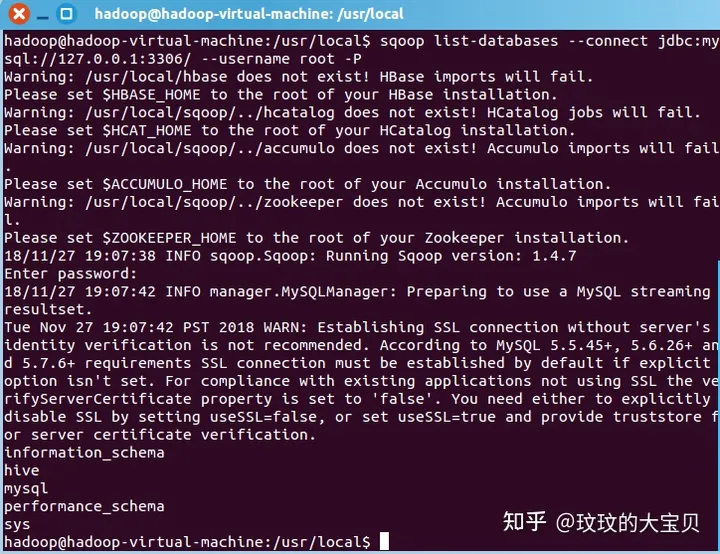
图 1.8 配置运行 Sqoop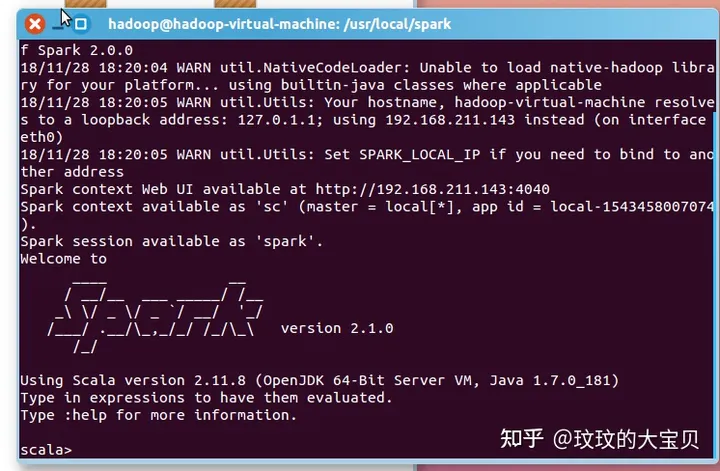
图 1.9 配置运行 Spark至此“淘宝双 11 数据分析与预测课程案例”所需要的环境配置完成。另外实际操作中发现在案例教程中存在一些小问题,比如教程中 Eclipse 版本为 3.8,但是在配置 Tomcat Server 时又要求配置 v8.0 版本,然而 3.8 版本的 Eclipse 最多仅支持到 v7.0 版本的 Tomcat,所以实际操作时使用了更新的 Eclipse 版本。二、本地数据集上传到数据仓库 Hive实验数据集有 3 个文件,分别是用户行为日志文件 user_log.csv、回头客训练集 train.csv、回头客测试集 test.csv,以下是三个文件的数据格式及说明。表 2.1 user_log 字段定义字段名字段含义user_id买家 iditem_id商品 idcat_id商品类别 idmerchant_id卖家 idbrand_id品牌 idmonth交易时间:月day交易事件:日action行为,取值范围{0,1,2,3},0 表示点击,1 表示加入购物车,2 表示购买,3 表示关注商品age_range买家年龄分段:1 表示年龄 =50,0 和 NULL 则表示未知gender性别:0 表示女性,1 表示男性,2 和 NULL 表示未知province收获地址省份回头客训练集 train.csv 和回头客测试集 test.csv,训练集和测试集拥有相同的字段。表 2.2 user_log 字段定义字段名字段含义user_id买家 idage_range买家年龄分段:1 表示年龄 =50,0 和 NULL 则表示未知gender性别:0 表示女性,1 表示男性,2 和 NULL 表示未知merchant_id卖家 idlabel是否是回头客,0 值表示不是回头客,1 值表示回头客,-1 值表示该用户已经超出我们所需要考虑的预测范围。NULL 值只存在测试集,在测试集中表示需要预测的值。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
