
Kafka作为一款高性能、分布式的消息队列系统,在大数据领域被广泛应用。然而,在使用Kafka时,重复消费问题是一个常见的挑战,可能会对系统的数据一致性和业务逻辑造成影响。我知道Kafka这个名词时还是在2019年刚工作的时候,但那时候公司使用的消息队列体量很小,所以只用了activeMq,我没再继续深入研究kafka相关;2021年下半年时,去了新公司,新公司规模大,数量量也巨大,许多系统之间要进行数据传输,我们用的消息中间件就是Kafka,于是拜读了一些Kafka介绍,看了一两个视频,看了下前辈们在代码中怎么使用的Kafka,装模做样的用起来了,也倒也没有发生什么问题,23年3月份某天晚上,我们上线了一个呕心沥血做了半年的项目,那个项目从服务构建、数据库设计、核心功能开发、与上下游系统的沟通交互我都深深的参与其中,结果上线当晚倒也没啥,第二天下午时,我们的下游系统同事打来电话了,问我们系统被攻击了么,怎么有个叫“田由甲”的用户信息一直在抛送呢。此刻问题丢我这了,毕竟和下游系统交互这块一直是我负责的,我立马打开了服务日志,却发现从凌晨3点到下午之间的日志一直被田由甲霸屏了,整个日志消息都是“用户田由甲修改了个人信息,value:{……},partition:{……},offset=XXXXX”。

我知道,现在这个问题丢给如今的我来看肯定很快能解决掉的,但对于当时的我来讲确实有一点懵,因为确实没遇到过Kafka重复消费的问题,我看遍日志也没发现打印异常的地方,而且每次修改完信息后,数据也同步给下游系统了,这个功能上线前测了无数次,怎么一上线偏偏一直在这打印数据呢。当时的脑子闪过一个念头,该不会我们的用户系统真的被攻击了,有人在定时刷我们的接口,一直修改这个田由甲的数据吧。当时的我们立刻找个田大哥的手机号,打过去询问了下,结果田大哥告诉我们他确实凌晨登了一次系统,只不过就修改了下昵称,之后没再登过了。看来还得回到问题本身,想想为什么测试环境没有重复消费,而生产一直消费个没完了呢。在分析问题之前,先给大家简单介绍下我们的数据流向:
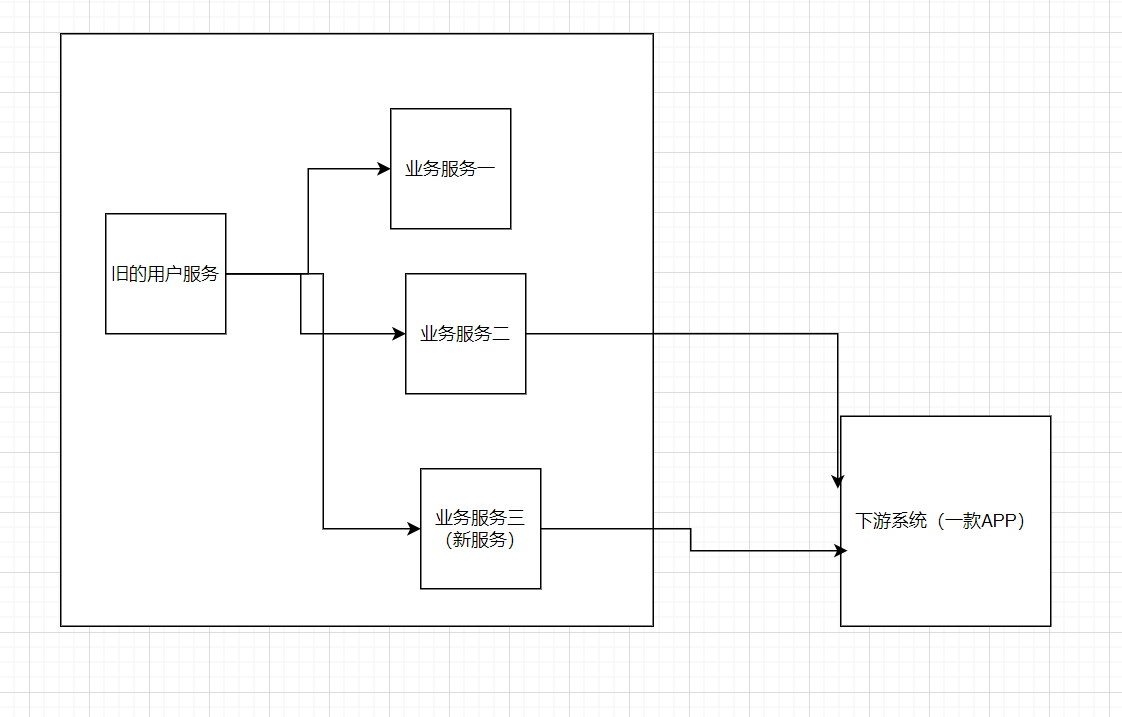
我们的系统很大,里面有几十个微服务,有一个用户中心,它对应的是一个单独的用户服务,所有全量的用户数据在这里都能找的到,每个业务服务呢都是处理不同的业务场景的,服务自己面对的客户群体也不一样,可以说每个业务服务这里也需要用到一份属于自己客户群体的客户数据,在自己的数据库中留存以方便逻辑处理和使用,每当用户在用户中心增加修改删除时,用户服务会把数据丢到一个公共的topic中,我们权且叫做topicA,三个业务服务去订阅这个topicA,根据type的不同选择来消费数据进行落库更新处理,我新上线的这个叫做服务三吧,它和下游系统的APP有数据上的交互,我从用户系统接到数据变化后,进行落库,然后数据业务加工后会推送到topicB中,下游系统订阅了这个topicB,接收到数据再更新自己的用户信息。
问题回到田由甲身上,首先用户说只修改了一次,而且我们公司有自己的安全部门,被服务器托管网这样攻击近10个小时不太现实,而且业务系统一监听田由甲也没发生问题,那问题肯定不在用户服务的数据跑送上,必然是我们新上线的服务出现了问题。我静下心来仔细观察了下日志,发现日志上的offset都是同一个值,说明程序执行完之后,偏移量没有被正确的提交,导致一直在消费同一条数据,但是另一个问题来了,既然下游APP接到了数据,说明方法逻辑肯定都走完了,排除发生异常的可能,那为何偏移量还是提交不上呢,于是又排查了下我写的Kafka消费和别人写的区别,我发现新服务的Kafka配置我开启了自动提交,而老服务别人是使用的手动提交方法,突然有了想法,手动提交是逻辑执行完之后执行ack.acknowledeg(),而自动提交则和配置的提交时间有关,如果方法执行超过了配置的时间阈值,那么偏移量将提交不上去。想到这,抓紧先把偏移量自动提交修改为了手动提交,将代码重新部署下。
其实这里还有个问题没有根本解决,为什么配置自动提交测试环境一直没有出现重复消费的问题呢,那段处理逻辑代码并不复杂,怎么会执行时间超出阈值设置的几十秒呢?我仔细想了下,一般代码慢都会和数据库交互有关,大多情况发生在查询上,而我写的这段逻辑只有一个地方通过手机号查用户信息和DB进行查询方面的交互了,想到这,我立马意识到一个问题,这张表并不是我新建的,我只是在这张用户表加了几个字段以便于我新业务新服务的使用,这个表生产一直有,所以说它和测试环境最大区别那就是数据量,虽然我参与的这部分用户群体只是整个系统总的用户群体的一个子集,只占很小的一部分,那在生产环境上,也肯定是有几十万条数据的,突然有个大胆的想法,该不会这张user表前辈们没有加索引吧!我立马登上生产库查看,好家伙,这张用户表,果然一个索引都没建,一个mysql表,几十万条数据,没有索引,直接用手机号查,那肯定是全表扫描,不慢才怪。。。测试环境没有那么大的数据量,必然测不出来啊,于是立马给用户表的手机号字段建了索引。
当时的我由于对Kafka重复消费问题第一次遇到,确实解决它废了点心思,最近这一年里,参与的项目几乎都使用到了Kafka,又遇到了好多次Kafka消费慢等优化的需求,愈加熟练的去解决了,接下来我将言归正传,官方的陈述下Kafka重复消费问题的根本原因、常见场景以及解决方法,希望能够帮助读者更好地理解和应对这一问题。
1. 重复消费问题的根本原因
Kafka的消费者组模型是保证高吞吐量和水平扩展性的关键,但也为重复消费问题埋下了隐患。消费者组中的每个消费者会负责消费特定分区的消息,并维护自身的消费偏移量(offset),用于记录已经消费的消息位置。然而,如果消费者在处理消息时发生故障或者处理时间过长,可能会导致消费偏移量未能及时提交,从而造成消息被重复消费的情况。
此外,Kafka本身并不保证消息的顺序性,如果消息在生产者端重试发送或者在网络传输过程中发生重复,也会导致消息被重复消费的情况发生。因此,要解决重复消费问题,需要从多个方面进行考虑和处理。
2. 常见场景下的重复消费问题
2.1. 消费者故障重启
当消费者由于故障而重启时,可能会导致消费偏移量丢失或者未能及时提交,从而造成消息被重复消费。
2.2. 消费者处理时间过长
如果消费者处理消息的时间过长,可能会导致在消息处理完成前发生故障或重启,从而引发重复消费问题。
2.3. 消息重试或网络传输问题
在消息生产和传输过程中,如果消息发生重试发送或者在网络传输过程中发生重复,也会导致消息被重复消费的情况发生。
3. 解决方法
3.1. 使用幂等性处理
在消费者端实现幂等性处理是解决重复消费问题的有效方法。通过在消费端记录已经处理过的消息ID或者通过消息去重的方式,可以保证同一消息不会被重复处理。
3.2. 提交消费偏移量
及时提交消费偏移量是避免重复消费的关键。可以通过服务器托管网设置适当的提交频率或者在消息处理完成后手动提交偏移量来确保消费偏移量的准确性。
3.3. 使用Exactly-Once语义
Kafka提供了Exactly-Once语义来解决重复消费和消息丢失的问题,可以通过配置事务或者幂等性生产者来实现Exactly-Once语义。
4. 结语
在使用Kafka时,重复消费问题是一个需要重视的挑战,但通过合理的设计和实施解决方案,可以有效地避免和解决重复消费带来的影响。希望本文的内容能够帮助读者更好地理解Kafka重复消费问题并采取相应的措施,确保系统的数据一致性和稳定性。
5. 参考资料
- Kafka官方文档:https://kafka.apache.org/documentation/
- Confluent官方文档:https://docs.confluent.io/
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: ASCII编码的影响与作用:数字化时代的不可或缺之物
一、ASCII编码的起源 ASCII(American Standard Code for Information Interchange)编码是一种最早用于将字符转换为数字的编码系统。它诞生于20世纪60年代,旨在解决计算机系统之间的字符传输和存储问题。在A…
