
本文整理自 2023 年 9 月 5 日百度云智大会 – 智能计算&大模型技术分论坛,百度智能云 AI &大数据平台总经理忻舟的主题演讲《百度智能云千帆大模型平台 2.0 产品技术解析》。
这是关于技术主题的论坛,我首先问大家三个开发者的小问题。
第一个问题:蒸汽机的发明者是谁?
是 18 世纪著名的开发者瓦特?其实是比瓦特更早 60 年的纽可门。瓦特在纽可门蒸汽机的基础上做了大量改进,大幅提升了效率,开启了第一次工业革命。
再继续提问,大家知道发电机是谁发明的吗?
法拉第在 1831 年发明了世界上第一台直流电发电机,而 50 多年后的 1887 年特斯拉发明了交流电发电机。交流电发电机使得电力传输的效率更高,因此能够被传输的更远,随着交流电的普及,大大加速了第二次工业革命的进程。
最后一个问题,世界上第一台计算机叫什么?
ENAIC,1946 年在美国宾夕法尼亚大学诞生。而在 10 多年后的 1959 年,随着仙童公司的诺伊斯发明了集成电路之后,计算机开始大规模普及,成为第三次工业革命的重要基石。
大家一定都猜到为什么会有这三个问题。当一个技术被发明出来,到它真正被大规模应用,中间一定会经历一个效率提升、成本降低、大规模普及的过程。
在大模型时代,百度智能云千帆大模型平台就致力于推进这个过程,大幅提升大模型开发应用的效率降低成本,推进产业应用与创新。

今年 3 月 27 日的时候,我们发布了千帆大模型平台 1.0 版本,有非常多的各行业企业开发者找到我们,希望双方一起探讨大模型的应用及落地。
截止到目前,我们的千帆大模型平台已经拥有 1 万多个企业和用户在上面做尝试和探索。我们测试了 400 多个场景,沉淀出了政务、金融、工业、交通等多行业解决方案,同时也根据企业实际训和用大模型中出现的问题,在各个环节都提供了更易用的产品工具和更稳定的技术性能。
所以今天非常高兴的在这里为大家介绍千帆大模型平台 2.0 的最新升级。
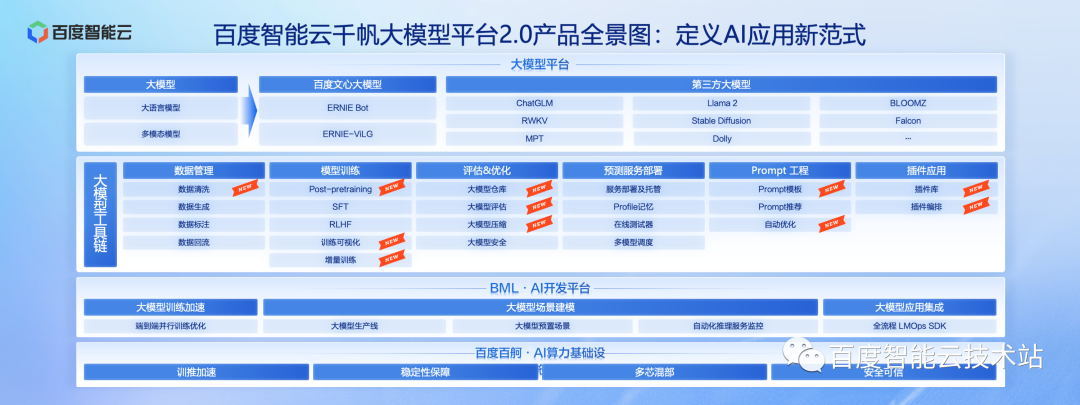
在 MaaS 层,包括文心大模型,我们总共接入了 42 个各具特色的大模型,满足产业应用方方面面的场景对大模型多样化的需求。我们对大模型全生命周期工具链进行了完善和增强——在这个平台上一步一步跟着走,就能快速搭建一个你想要的应用或者重构你现在的产品。
除了用大模型,很多行业的龙头企业都会用我们的平台训练大模型。在 PaaS层,我们结合 AI 开发平台的能力,可以实现训练加速、场景建模、应用集成等功能,为训练大模型的企业提供了最佳实践。
在 IaaS 层,百度百舸提供了高性能、稳定的 AI 基础设施。
下面我将逐一对我们的能力升级,为大家进行讲解。
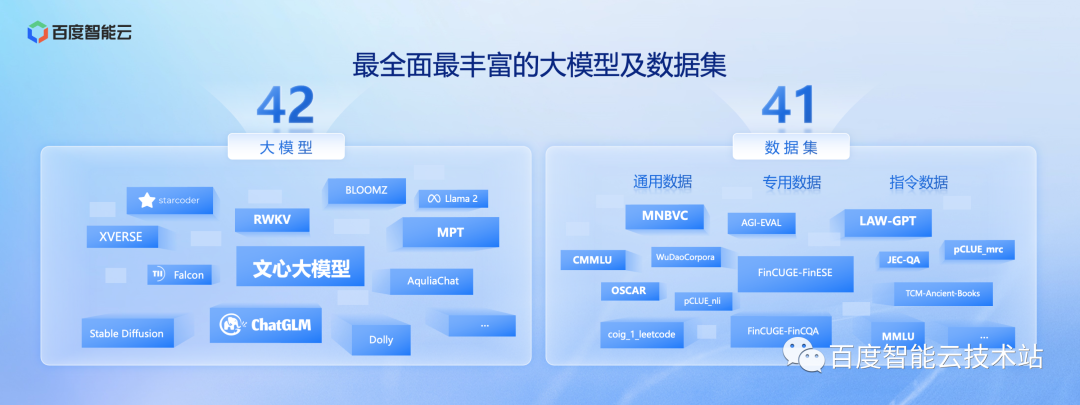
目前,千帆大模型平台提供了 42 个各具特色的大模型,除了文心大模型以外,还有市场上国内非常优秀的智谱华章的 ChatGLM,也有能够支持非常大的上文窗口的 RWKV,还有国外优秀的模型比如 BLOOMZ、Llama 2 等。
除此之外,我们提供了 41 个数据集,包含通用数据、专用数据、指令数据,涵盖教育、金融、法律等。开发者通过使用预置在千帆大模型平台的数据集,可以大幅降低训练时的数据成本,尤其是在冷启动阶段,快速的建立自己的行业模型。
除此之外,我们根据企业的实际需求,对各类第三方模型进行了很多增强,其中一个是中文增强。像 BLOOMZ、LIama 2 这样优秀的开源模型,他们来到国内以后,大家会发现它有点水土不服,听不懂中文,百度利用自己多年中文数据积累和中文的知识对这些模型进行中文增强。
我们可以看到,不管是在 7B 还是 13B 参数量下面,经过中服务器托管网文增强后的 Llama 2,在中文数据级上的效果,各个评价标准上,相比原版有大于 10% 的效果提升。
同时,模型的应用是非常消耗资源的。我们对于模型的体积进行了压缩,对模型的推理速度进行了增强。千帆大模型平台对于开源模型体积平均可以降低 60% 以上,推理速度最高可以提高 5 倍,这对于我们模型的实际应用来说是非常大的福利。
除此之外,我们还提供了指令增强、性能增强、32K 上下文扩展、安全增强等增强的能力,满足企业日常和长尾的各类场景需求。

刚才讲到百度百舸为上层的模型平台和模型应用提供高性能、稳定的异构计算平台。
百舸平台在训练稳定性,故障感知和容错等三个层面做了很多优化。
在训练稳定性方面,百舸的万卡任务有效训练时间占比达 95%。
在故障感知层面,针对任务退出,任务假死和运行慢几种常见故障场景建设感知能力。尤其是后两种故障,有比较大的隐蔽性。百舸平台基于百度内部大量的最佳实践制定了指标体系,可以秒级发现问题,分钟级进行故障定位,30分钟内就能完成故障恢复。
容错是做好稳定性建设的最后一道关卡。百舸平台提供了自动容错能力,百 GB Checkpoint 秒级写入,有效训练时间提升 10%。

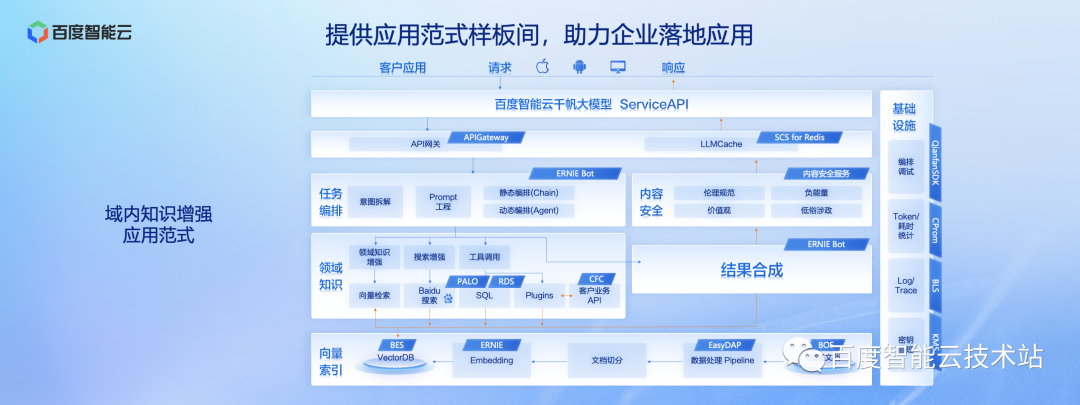
此外,针对大模型应用的高频场景,千帆平台提供了应用范式的样板间,能够降低企业应用落地的门槛。以域内知识增强的场景为例,我们介绍下整个过程。
首先,看图的最左边,用户输入的 query 经过 API 网关后传递到大模型,大模型对 query 进行意图拆解,拆分成不同的子任务。在这个环节,我们可以通过静态编排 Chain 的方式,或者动态编排 Agent 的方式,提前设定或学习相关的意图拆解能力。另外,对于拆解后的子任务,也可以进一步进行自动 prompt 优化,更加精准地传递到下游。
在这个场景,用户的 query 可能会被拆解成域内知识检索、搜索增强及一系列的工具调用和查询。在这一步分别执行不同的子任务,完成相关的工具调用及查询,获得子任务的返回结果。
图的最下方展示了在域内知识增强会被子任务调用的系统。比如:我们提前将领域相关的知识库、文档通过向量化,存储到百度智能云的数据库 BES 中。作为检索分析引擎,BES (Baidu Elasticsearch)在大模型时代全面升级了向量能力,为大模型提供知识和记忆,在提升业务表现的同时,也能有效保护企业私域数据安全服务器托管网。
在上一步,各子任务通过向量数据库查询,工具调用等,都获得了返回结果,再将这些结构都输入到大模型,进行内容加工、整合。最后再将大模型整合后的结果经过我们的内容安全模块过滤后,返回出去。
图的右侧是我们搭建整套系统所依赖的各类基础设施,比如:密钥管理、日志管理等。
整个应用样板间具备两个非常鲜明的特点:第一个特点就是内容非常全,向量索引包括搜索增强、SQL 增强,这些所有都需要用到域内知识检索的工具,我们都提供了。第二个点是支持快速构建应用,API 网关、LLM 高速的缓存以及密钥管理等企业级的应用所必需的功能,用户可以通过这个样板间直接使用这些功能,基于自己的应用和数据快速地构建自己企业级大模型应用。
类似这样的样板间,千帆大模型平台上已经提供了十多个,帮助企业和用户快速构建自己的生成式 AI 应用。
百闻不如一见,刚才讲了那么多,还是希望能够给大家演示一下千帆平台的使用。我们来看一段视频,看看一个工程师如何在 7 个小时内重构企业的数据分析产品。
我们团队有一位暑假实习生同学,视频中记录了请他是如何使用千帆大模型平台快速构建一个生成式 AI 的应用。
对于大模型的开发和应用非常熟悉的朋友们,一定都能看出来他做的实际上是对于数据的交互式探查的功能。视频中他做了两件事:第一件事是对于自然语言处理到 SQL 语句的查询做了指令微调;第二个事情是利用域内的知识检索对于这个领域专业知识做了问答,最后在 DEMO 里面调试了这两个功能。

在今天上午的主论坛,沈抖博士重磅发布了我们的 AI 原生应用 Family,其中,服务营销、办公提效、生产优化,都预置了千帆组件版。在这个能力的背后,是我们整体的全站 API 计划,让大模型应用的企业和厂商,都可以通过全站 API 更灵活地将千帆大模型及工具链集成到自己的应用中,构建自己的 AI 原生应用。
以 BI 与数据可视化产品 Sugar BI 为例,通过调用千帆上文心大模型的接口,在传统 BI 基础上,支持对话式数据探索,快速获取数据图表和数据结论,并能应用到报表和大屏制作中。Sugar BI 上线一个月就收到了几十位客户的 POC 需求,可见市场对 AI 原生应用的热情。

AI 算力的发展非常快,更新换代是家常便饭。同时,市场上也已经有非常丰富的 AI 算力选择。
然而,这么多 AI 算力对大模型的开发应用而言是个噩梦。对于各种硬件的适配,是一件技术难度很高的工作,需要有同时熟悉硬件、框架、算法,同时在计算、存储、网络等领域有丰富经验的工程师来完成。
千帆大模型平台,已经为适配了主流的算力和模型的组合,并且可以纳管和调度不同的算力,使得企业的开发效率和资源利用率都能大幅提高。

当前,大模型正处在产业落地前期,高质量的数据,是大模型实现大模型产业化的关键要素。
海量的数据训练,指令微调,基于人类反馈的强化学习,可以让大模型与人类价值观、思维方式不断对齐,使大模型更加可用。
百度智能云自主研发了业内领先的大模型数据标注平台,提供了数据服务和运营,能够打通大模型落地的最后一公里。该平台支持了从数据采集与清洗、指令微调标注与强化学习标注,到模型评估的数据生产闭环。
为保障数据标注质量,我们还搭建了全流程数据服务人才梯队,在百度智能云海口数据标注基地培养数百名专职大模型数据标注师,本科率达到 100%。
数据安全始终是重中之重,百度智能云可提供高安全性的端到端数据服务,标注平台支持私有部署,通过与基地资源联动,为客户提供多样化的数据安全方案。

目前,我们已经与众多的企业一起实践,沉淀了 400 多个场景。包含泛科技、金融、能源、政务、等等,未来我们将与更多的行业进行深度合作,让大模型赋能千行百业。

在今天的内容中,我们介绍了百度智能云千帆大模型平台最新的升级,包括:模型与数据集、工具链与应用范式、AI 基础设施百度百舸、全站 API、多芯适配等功能或者特性。也推出了满足大模型产业化应用的关键要素——大模型数据标注平台。
我们希望在未来,这些产品能够帮助企业伙伴进一步降低大模型的开发和应用成本,共同推进大模型的行业落地,共同推进产业创新,加速产业的智能化。
千帆竞发,共创辉煌!
—— END ——
推荐阅读
代码理解技术应用实践介绍
百度交易中台之内容分润结算系统架构浅析
小程序编译器性能优化之路
百度APP iOS端包体积50M优化实践(六)无用方法清理
基于异常上线场景的实时拦截与问题分发策略
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 准「AI 时代」下,如何衡量程序员的工作效率和生产力?
从数据到大模型应用,11 月 25 日,杭州源创会,共享开发小技巧 近 20 家科技、金融和制药公司实施了新的研发效能管理方法,并取得了令人鼓舞的初步结果。 客户报告的产品缺陷减少 20%-30%; 员工体验分数提高 20%; 客户满意度评分提高 60 个百分…
